







0.序言
作为数据RD,会跟各式的数据库打交道,但对于数据库技术往往是使用应用,一些底层的技术原理并一定十分清晰。本文试图讲解一些常见的技术概念背后的技术原理,希望通过尽可能干货的方式,让大家理解日常工作中使用技术的底层原理,提升大家的技术兴趣,也间接提高性能优化或问题定位的能力。
本文主要回答几下三个问题:
-
什么是列式存储,为什么列式存储在OLAP场景中更加高效?
-
什么是向量化,与向量化解决相同问题的技术还有哪些?
-
查询优化器都做了哪些事情?
1.什么是列式存储,为什么列式存储在OLAP场景中更加高效
| 姓名 | 年龄 | 性别 | 身高 | 体重 | |
|---|---|---|---|---|---|
| 张三 | 18 | 男 | 180 | 80 | |
| 李四 | 20 | 男 | 170 | 70 |
以上面表格为数据表,一般来说,同一行的数据在存储介质中连续存储,称为行式存储。如图

同一列的数据在存储介质中连续存储,称为列式存储。如图

OLAP场景中,首先要存储大量的数据,可能是数十上百亿,其次在查询时经常从数据库中提取相当多的行,但只提取一部分列。
针对OLAP的查询场景,行存储需要一行行的扫描数据,再选取需要的字段进行数据提取。这种方式对于OLAP的多行少列场景,会扫描一行中很多无用的数据,造成磁盘IO和内存的大量浪费。
列存储可以直接选定需要的列,再把列中相应的行数据提取出来,效率自然就高了许多。
实际上在OLAP场景中,列存储除了能够减少无关列的扫描,还有可以带来更高的压缩比来解决海量数据的存储问题。
为什么列式存储能有更高的压缩比?
“因为同一列的数据往往重复度较高,以及字段类型相同可以采用更好的编码压缩算法。”
-
列式存储举例——ORC文件
ORC文件是数据同学每天都在用的文件格式,的全称是(Optimized Record Columnar),是在RCFile的基础上进行了一定的改进。整个文件的结构可以按照下图理解
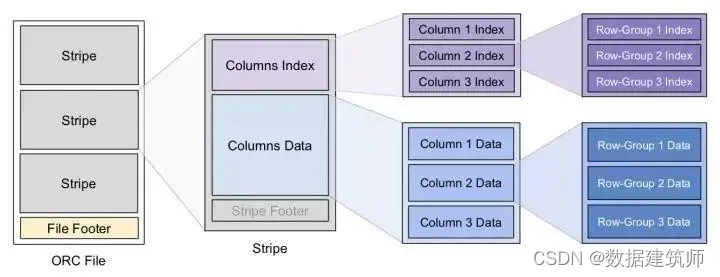
可以看到一个文件首先按照行划分成多个stripe,文件中有一块区域File Footer用来包含了每一个stripe的长度和偏移量,该文件的schema信息和整个文件的统计信息
每个stripe中存储所有列的某些行的数据,可以通过column index来定位每个column的位置和长度。
每个column data把一部分行按照row-group的形式,分组存在一起(默认是10000行一个row-group来)。
为什么如上图的结构是列式存储呢?
“虽然在文件级别是按照行来划分的stripe,但是在最底层是按照列来划分,每个列的数据按照10000条一堆连续的存储”
下面来具体解释下为什么列式存储可以更好的压缩,以delta 时间戳压缩算法举例
时间戳一般采用 long 类型进行存储,需要占用 8byte 存储空间。最直接的优化就是存储时间戳的差值,
相邻两个时间戳差值 Delta(n) = T(n) - T(n-1)

经过压缩后可以大幅降低存储成本,同时降低读取时的I/O开销、提升缓存能力,从而提升查询性能。
在不改变数据量大小和数据表结构的情况下,如何利用ORC文件的结构,降低存储?
“由于ORC是按照row group进行分组压缩,所以把相同或相似的行数据放到一起,更容易提升压缩率,占用更小的存储”
2.什么是向量化,与向量化解决相同问题的技术还有哪些?
向量化是最近几年比较火的概念,很多数据库都开始支持向量化,doris在新的版本中也可以支持向量化技术。这个概念听起来比较高大上,那么实际上到底做了什么?
数据在数据库里被提取和计算的整个过程,我们称为计算执行。计算执行的模型一般有三种,火山模型,向量化执行,动态代码生成。为了讲清楚向量化,我们先从最常见最基础的火山模型讲起,然后讲到向量化,最后讲一下动态代码生成。
2.1 火山模型
火山模型(Volcano-style execution)是最早的查询执行引擎,也叫做迭代模型 (iterator model),这个模型的特点是一次只处理一行(tuple)数据。在这种模型中,查询计划是一个由operator组成的DAG,其中每一个operator 包含三个函数:open,next,close。Open 用于申请资源,比如分配内存,打开文件,close 用于释放资源,next方法递归的调用子operator的 next方法。
以一个实际的例子看一下火山模型的执行过程
select order_id,
mt_user_id,
order_time,
order_amt
from ba_hotel.fact_order_trade
where order_datekey=20220101 and sale_platform='mt'
一般Operator的next() 接口实现分为三步
1.调用子节点Operator的next() 接口获取一行数据(tuple)
2.对tuple进行Operator特定的处理(如select 或project 等)
3.返回处理后的tuple。
火山模型的优点在于:简单,每个 Operator 可以单独抽象实现、不需要关心其他 Operator 的逻辑。
缺点也很明显:
-
大量虚函数调用:火山模型的next方法通常实现为一个虚函数,在编译器中,虚函数调用需要查找虚函数表, 并且虚函数调用是一个非直接跳转 (indirect jump), 会导致一次错误的CPU分支预测 (brance misprediction), 一次错误的分支预测需要十几个周期的开销。火山模型为了返回一个元组,需要调用多次next 方法,导致昂贵的函数调用开销
-
CPU Cache利用效率低:next方法一次只返回一个元组,元组通常采用行存储,如果仅需访问第一列而每次均将一整行填入CPU Cache,将导致Cache Miss;
-
CPU与IO性能不匹配:每次从磁盘读取一个行数据,经过多次调用交给CPU进行处理,显然,大部分时间都是CPU等待数据就绪,导致CPU空转。
2.2 向量化
向量化执行以列存(内存中为列式布局)为前提,主要思想是每次从磁盘上读取同一列的多行数据以数组形式组织。每次next都通过for循环处理数组。这么做可以大幅减少next的调用次数。相应的CPU的利用率得到了提高,另外数据被组织在一起。可以进一步利用CPU硬件的特性,如SIMD(Single Instruction Multiple Data,单指令多数据),将所有数据加载到CPU的缓存当中去,提高缓存命中率,提升效率。在列存储与向量化执行引擎的双重优化下,查询执行的速度会有一个非常巨大的飞跃。
从数据库的角度
1. 将 Next Tuple ,变成 Next Batch 。
2. 内存中 Batch 的数据不是以行的形式存在,而是以列的形式存在,算子都是在列上进行运算。

以doris公众号上描述的doris的例子,左边是火山模型的执行示意图,右边是向量化的执行示意图。
从CPU的角度
现代 CPU 支持将单个指令应用于多个数据(SIMD)的向量运算。例如,具有 128 位寄存器的 CPU可以保存 4 个 32 位数并进行一次计算,比一次执行一条指令快 4 倍。
下图以计算数据*3为例讲述SIMD下的计算过程比传统CPU指令要快

比如我们在内存当中有 4 个 32 位的 int ,进行计算时传统的 CPU 没有 SIMD,或者说没有向量化支持的 CPU 要进行四次从内存中 Load 数据,再进行 4 次乘法计算,然后把结果写回到内存当中同样要进行 4 次。假如我们能够支持 SIMD ,我们可以一次载入多个连续的内存数据,这样我们就只有一次数据的 Load ,一次的计算,然后得到 4 个结果写到 4 个寄存器里面,然后这 4 个寄存器再写回到内存当中,就完成了一次向量化的指令计算操作。这样的操作能够比传统的CPU快 4 倍。
向量化的核心是利用数据局部性原理,一次取一个和取一批的时延基本是同样的。火山模型每次都是取一个处理一个,跳转到别的算子;而向量化是取一批处理一批后再跳转。整个过程中最耗时是算子跳转(虚函数跳转)和数据存取(访问内存比CPU计算慢两个数量级)
2.3 动态代码生成
向量化执行减少CPU等待时间,提高CPU Cache命中率,通过减少next调用次数来缓解虚函数调用效率问题。而动态代码生成,则是进一步解决了虚函数调用问题。
动态代码生成技术直接生成对应的执行语言的代码并执行,不产生虚函数的调用,节省了时间
databricks 的官方博客中提到他们使用一个简单的 benchmark 比较了火山模型与大学新手的手写代码的性能
比如下面的sql
select count(*)
from employees
where salary == 1000火山模型下代码实现可能是
//执行计划是scan——>select——>project
Tuple Select::next() {
Tuple row = plan.child->next(); // 从子节点中获取 next tuple
if (row == EndOfStream) // 是否得到结束标记
return EndOfStream;
if (condition->filter(row)) // 是否满足过滤条件
return row; // 返回 tuple
}
}
Tuple Project::next() {
...
}
Tuple Scan::next() {
...
}如果用java来实现
int count = 0;
for(emp : employees){
if(emp == 1000){
count += 1;
}
}性能差异如下:

Spark SQL就使用了动态代码生成(codegen)的技术,加快计算的速度

动态代码生成本质上是以数据为核心(火山模型是以计算过程为核心)在编译阶段根据任务的计算逻辑,动态的生成整个任务的计算代码,并在代码中就明确了各函数的调用链,完全避免了虚函数的调用开销。
以sparkSQL为例(其余计算引擎也类似),一条sql在执行前经过了以下几个过程,在物理执行计划之后额外的进行动态代码生成并替换掉原先的火山模型执行代码。

2.4 向量化和动态代码生成对比
关于向量化或者codegen,孰优孰劣,论文Everything You Always Wanted to Know About Compiled and Vectorized Queries But Were Afraid to Ask 进行了深入的对比。二者也可以融合,通过codegen生成向量化执行代码,另外也不一定做wholestage codegen,和解释执行也可以一起配合。知乎网友的总结:
1)codegen适合计算密集型场景,如果数据可以都在cpu register里面,更少的指令加速效果明显。
2)向量化则适合在访存密集型场景,避免memory stall,例如aggregation和hash join。(Memory Stall指的是CPU执行指令时,内存取数的等待时间)
3)SIMD理论上可以数倍加速,但是实际TPC-H评测,一些请求大部分受限于memory bound,所以效果并不十分明显。
4)两种实现都可以很好的并行化。
3.查询优化器都做了哪些事情?
查询优化器对对SQL生成高效的执行计划,特别是对于现代大数据系统,执行计划的搜索空间异常庞大,研究人员研究了许多方法对执行计划空间进行裁剪,以减少搜索空间的代价。查询优化器主要分为基于规则的优化(RBO)和基于成本的优化(CBO)
3.1 基于规则优化
通俗来说,基于规则的优化(rule based optimization,RBO)指的是不需要额外的信息,通过用户下发的SQL语句进行的优化,主要通过改下SQL,比如SQL子句的前后执行顺序等。比较常见的优化包括谓词下推、投影下推、聚合下推、join下推、limit下推、sort下推、常量折叠等等。RBO的核心思想就是等价替换,用经验上更优的规则等效替代非优的规则。
各类下推其本质是把计算尽可能的贴近数据源,在较早的阶段就减少数据

谓词下推,即PredicatePushDown,最常见的就是where条件等,简单来说就是把过滤条件尽可能早的推到更接近数据源的地方
join下推与谓词下推类似,主要是on后面的条件的下推。
投影下推,即ProjectionPushDown,比如某个SQL仅需返回表记录中某个列的值,那么在列存模式下,只需读取对应列的数据,在行存模式下,可以选择某个索引进行索引覆盖查询,这也是索引选择优化的一种场景;
聚合下推,主要思想是将聚合操作推到数据源层,这样从数据源里返回的数据就会极大减少。磁盘读写和网络开销都会降低,性能会得到提升。
limit下推、sort下推与上面类似,都是在数据源层面就减少数据,降低后面操作的代价
常量折叠,将SQL语句中的某些常量计算(加减乘除、取整等)在执行计划优化阶段就做掉;比如“where a=3*5”会优化成“where a=15”
3.2 基于代价优化
基于规则的优化器简单,易于实现,通过内置的一组规则来决定如何执行查询计划。与之相对的是基于代价优化(cost based optimization,CBO)。
CBO是根据优化规则对关系表达式进行转换,原有的一个关系表达式经过转换后会生成多个关系表达式,同时原有表达式也会保留,然后CBO会根据统计信息和代价模型(Cost Model)计算每个执行计划的Cost,从中挑选Cost最小的执行计划
CBO的一大用途是在Join场景,决定Join的执行方式和Join的顺序。这里所说的Join我们主要是讨论Hash Join。
Join执行方式:
Hash Join一般可以分为broadcast和partition两种。
广播方式适用于大表与小表进行Join,在并行Join时,将小表广播到大表分区数据所在的各个执行节点,分别与大表分区数据进行Join,最后返回Join结果并汇总。
比如spark中有一个参数:spark.sql.autoBroadcastJoinThreshold,如果小表的文件存储大小(在磁盘上占用的空间大小)小于这个值,那么这次join就可以走broadcast join。每个表在hdfs上占用的磁盘空间就是一个统计信息,比如ORC文件就会记录在footer中,直接从统计信息中或者这个数值就可以判断是否可以广播。
但这里还有一个问题,假设在不考虑AQE的情况下,如果一个表A有100MB大小,spark.sql.autoBroadcastJoinThreshold设置为25MB,但是在关联表A之前有一个子查询,从A表的50列中投影2列数据,那么这个join可以走broadcast join吗?过去平台在实现spark的预估算法时简单粗暴,他会根据统计信息预估子查询之后的大小为100*2/50MB大小。乍一看没有问题,但这里隐藏一个条件,即每一列列的数据是大小均匀,假使2列数据占了整表的80%的存储,那么这次广播就有可能会出问题。后来平台把算法修改为从ORC文件的footer中提取每一列的avgLen,作为列大小的权重,这样就尽可量的避免的广播大表的风险。这是一个典型的应用统计信息选择join方式的例子。
分区方式是最为一般的模式,适用于大表间Join或表大小未知场景。分别将两表进行分区,每个分区分别进行Join,对应spark中的sortmergejoin。这里不做过多的赘述
Join顺序:
如果一个查询的SQL中存在多层Join操作,如何决定Join的顺序对性能有很大影响。这块也已是被数据库大佬们充分研究过的技术。

一个好的CBO应该能够根据SQL 语句的特点,来自动选择使用Left-deep tree(LDT,左图)还是 bushy tree(BYT,右图)执行join。
两种Join顺序没有好坏之分,关键看进行Join的表数据即Join的字段特点。
对于LDT,如果每次Join均能够过滤掉大量数据,那么从资源消耗来看,显然是更优的。
但一般来说,选择BYT可能是效率更高的模式,因为可以把串行Join改为并行的Join,更快的返回数据。
在现代数据库中,RBO与CBO往往是共存的。
最后再以sparkSQL中的执行计划生成过程来说明查询优化器其作用的阶段















 420
420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









