






【InternLM 实战营第二期】第四节 笔记
第四节 XTuner 微调 LLM:1.8B、多模态、Agent
参考:
视频教学:https://b23.tv/QUhT6ni
文档链接:https://github.com/InternLM/Tutorial/blob/camp2/xtuner/personal_assistant_document.md
一、Finetune 简介
- 两种Finetune范式
LLM 的下游应用中,增量预训练和指令跟随是经常会用到两种的微调模式
- 增量预训练微调
使用场景:让基座模型学习到一些新知识,如某个垂类领域的常识
训练数据:文章、书籍、代码等 - 指令跟随微调
使用场景:让模型学会对话模板,根据人类指令进行对话
训练数据:高质量的对话、问答数

例子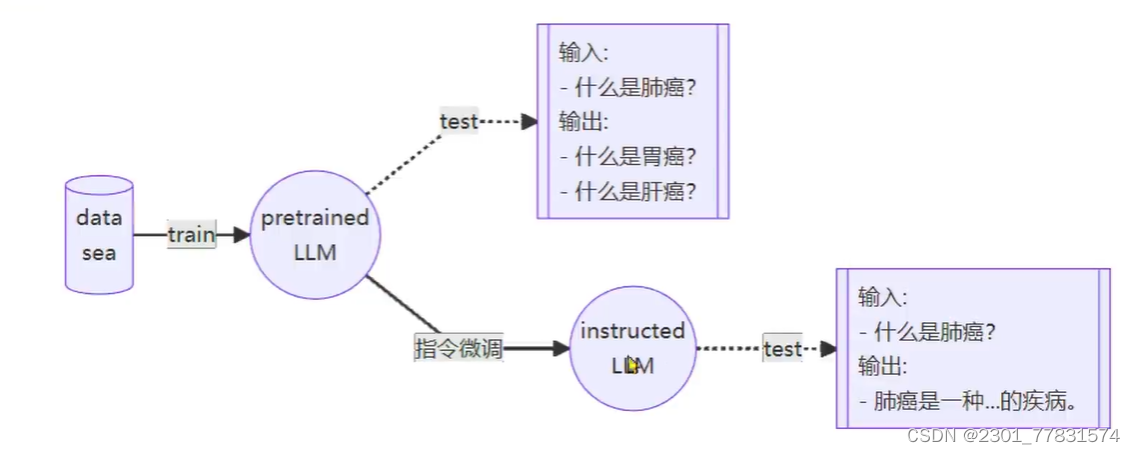
- 一条数据的一生

- 对话模板:
对话模板是为了能够让LLM区分出,System、User和Assistant,不同的模型会有不同的模板。
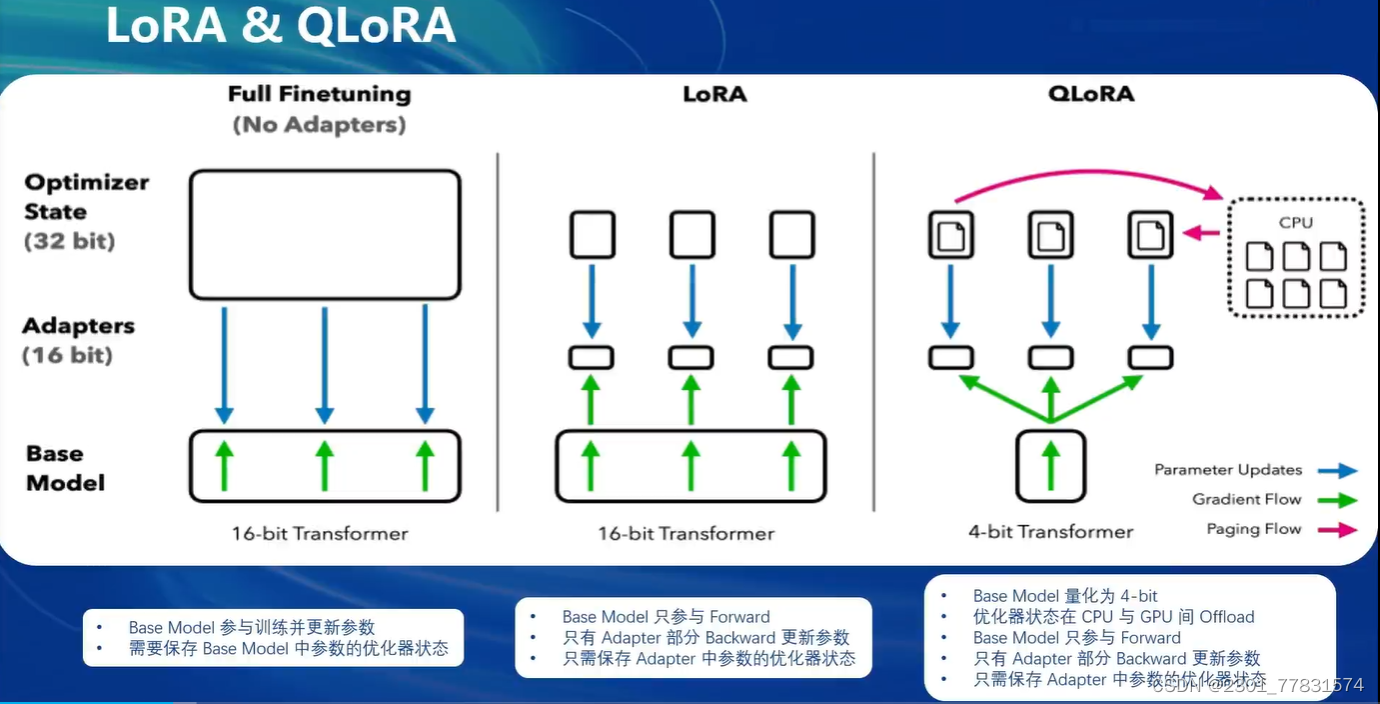
LoRA & QLoRA

二、XTuner 介绍
- 傻瓜化:以配置文件的形式封装了大部分微调场景,0基础的非专业人员也能一键开始微调。
- 轻量级:对于7B参数量的LLM,微调所需的最小显存仅为8GB:消费级显卡、colab

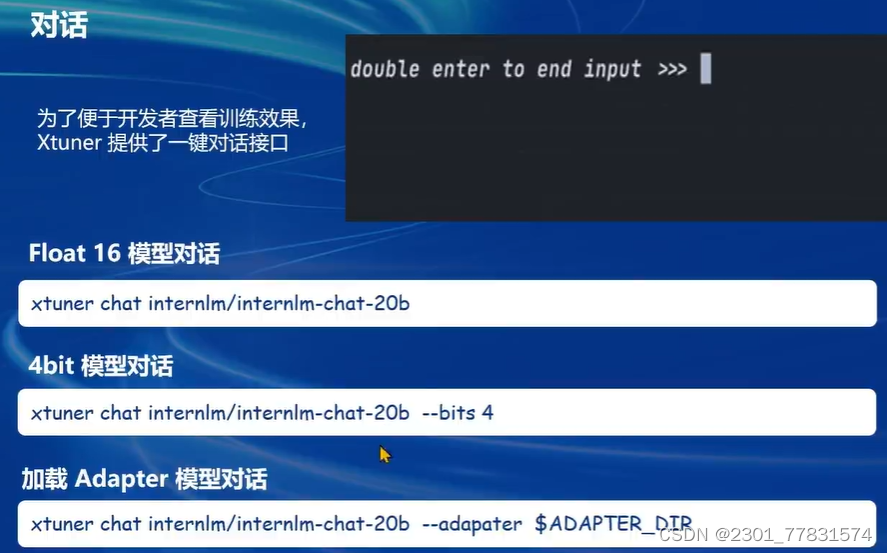
XTuner快速上手: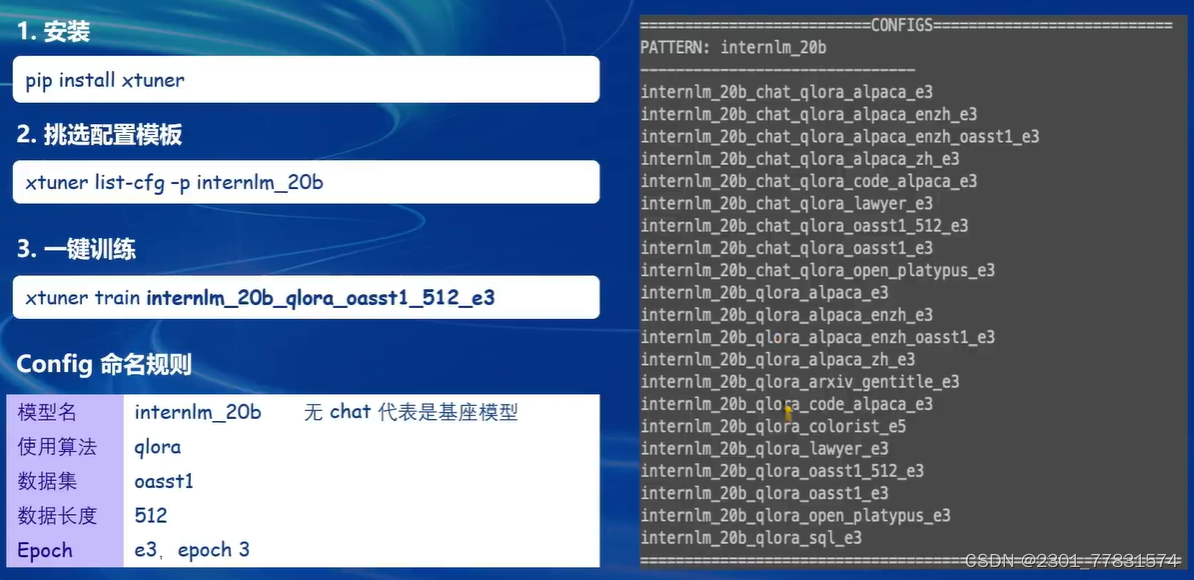

三、8GB显存玩转LLM
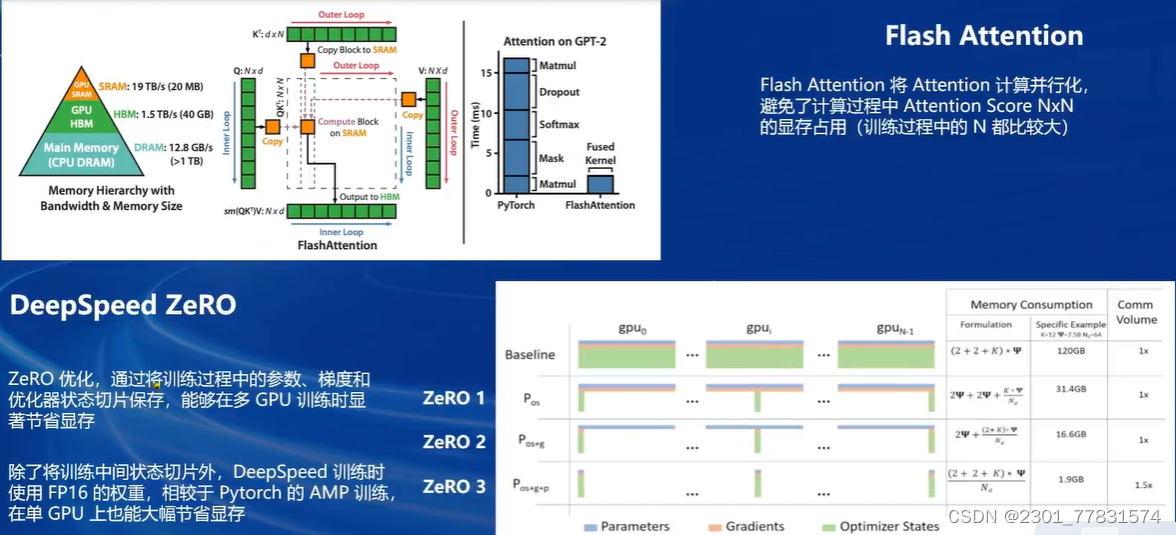
FlashAttention和DeepSpeedZeRO是XTuner最重要的两个优化技巧。
四、InternLM2 1.8B 模型
InternLM2-1.8B提供了三个版本的开源模型,大家可以按需选择。
- InternLM2-1.8B:具有高质量和高适应灵活性的基础模型,为下游深度适应提供了良好的起点。
- InternLM2-Chat-1.8B-SFT:在InternLM2-1.8B上进行监督微调周(SFT)后得到的对话模型。
- InternLM2-Chat-1.8B:通过在线RLHF在InternLM2-Chat-1.8B-SFT之上进一步对齐。InternLM2-Chat-1.8B表现出更好的指令跟随、聊天体验和函数调用推荐下游应用程序使用。(模型大小仅为3.78GB)
在FP16精度模式下,InternLM2-1.8B仅需4GB显存的笔记本显卡即可顺畅运行。拥有8GB显存的消费级显卡,即可轻松进行1.8B模型的微调工作。如此低的硬件门槛非常适合初学者使用,以深入了解和掌握大模型的全链路。
五、多模态LLM微调
- 给LLM装上电子眼:多模态LLM原理简介
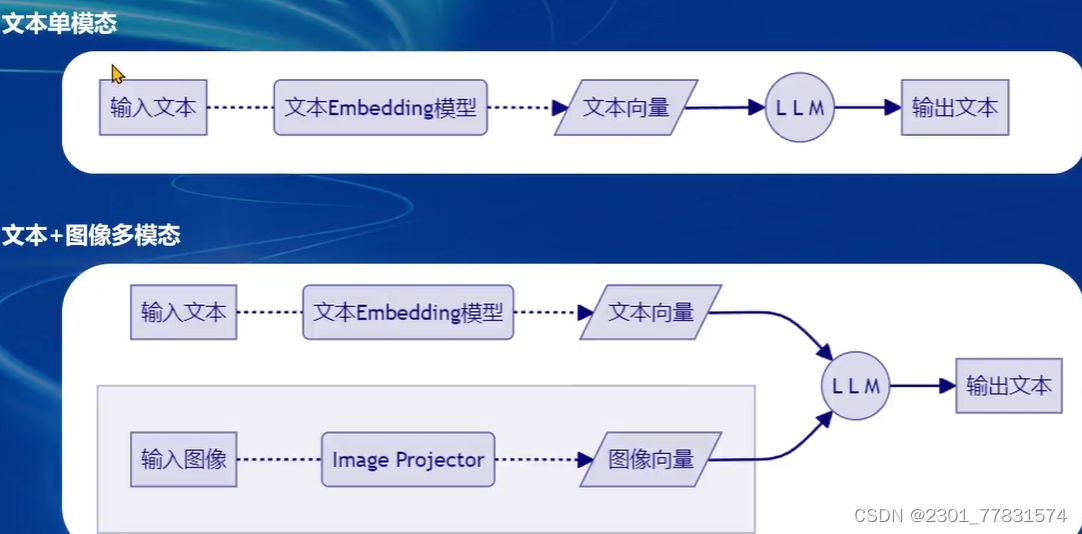
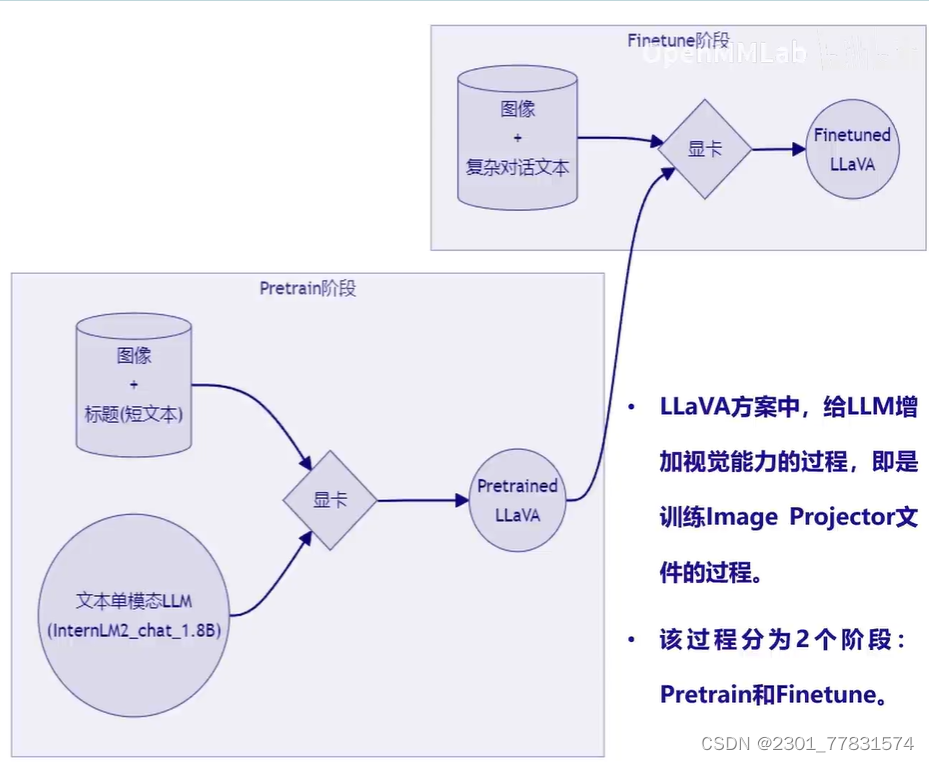
- 什么型号的电子眼:LLaVA方案简介
- Haotian Liu等使用GPT-4V对图像数据生成描述,以此构建出大量< question text > < image > – < answertext >的数据对。
- 利用这些数据对,配合文本单模态LLM,训练出一个Image Projector。
- 所使用的文本单模型LLM和训练出来的ImageProjector,统称为LLaVA模型。
















 200
200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









