







🚀 提升你的编程、科研学习体验! 🚀
大家好,我是小P学长!我分享了一个PyTorch与TensorFlow介绍 。
🌟 如何获取学习资料?
- 支持我的博客
 https://studentp.cloud/p/search.html?text=,输入关键词查找项目(比如“注意力机制”、“cifar”等)。
https://studentp.cloud/p/search.html?text=,输入关键词查找项目(比如“注意力机制”、“cifar”等)。 - 获取宝藏内容。
🎉 感谢你的支持! 🎉
NeRF与三维生成、重建相关
Adaptive Shells for Efficient Neural Radiance Field Rendering
https://arxiv.org/abs/2311.10091
Zian Wang, Tianchang Shen, Merlin Nimier-David, Nicholas Sharp, Jun Gao, Alexander Keller, Sanja Fidler, Thomas Müller, Zan Gojcic
nVidia、多伦多大学
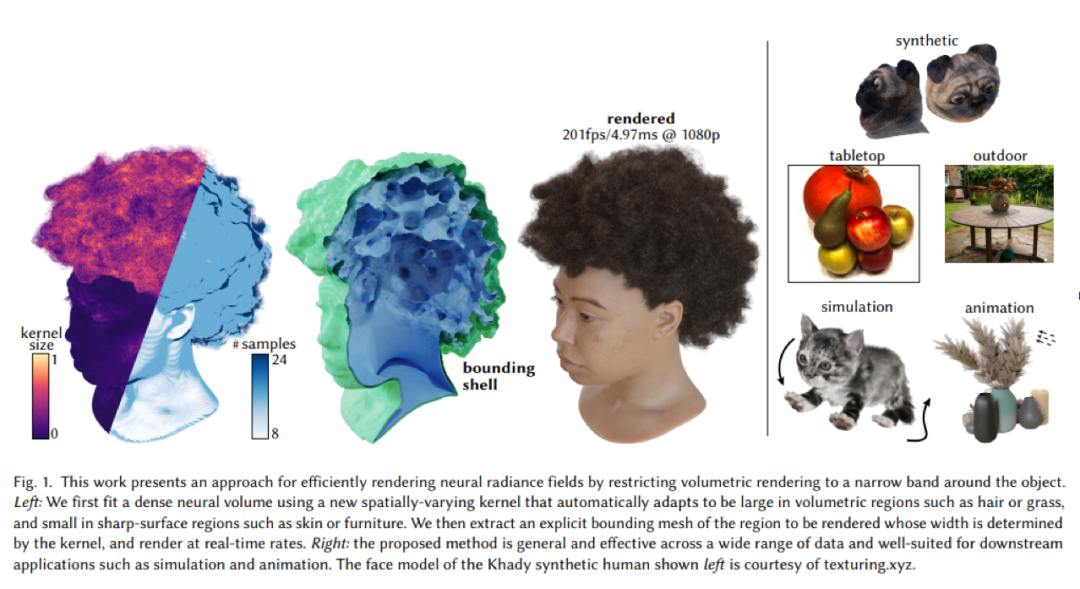
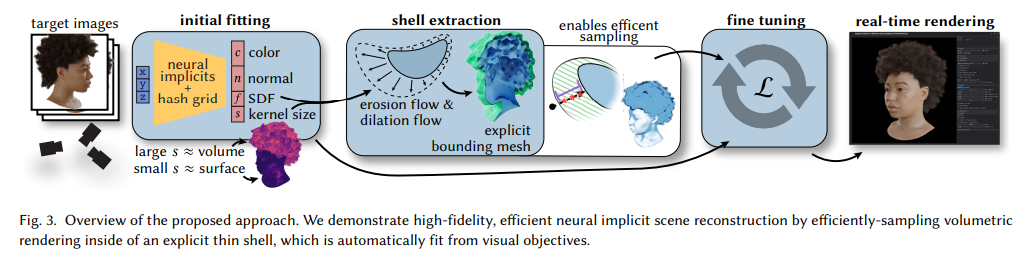
神经辐射场为新颖的视图合成实现了前所未有的质量,但其体积公式仍然昂贵,需要大量样本才能渲染高分辨率图像。体积编码对于表示模糊几何形状(例如树叶和头发)至关重要,并且非常适合随机优化。然而,许多场景最终主要由固体表面组成,可以通过每个像素的单个样本来准确渲染。基于这一见解,我们提出了一种神经辐射公式,可以在基于体积的渲染和基于表面的渲染之间平滑过渡,大大加快渲染速度,甚至提高视觉保真度。我们的方法构建了一个显式的网格包络,它在空间上限制了神经体积表示。在实体区域中,包络几乎会聚到一个表面,并且通常可以使用单个样本进行渲染。为此,我们用学习的空间变化核大小来概括 NeuS 公式,该核大小编码密度的分布,将宽核拟合到类似体积的区域,将紧密的核拟合到类似表面的区域。然后,我们提取表面周围窄带的显式网格,宽度由内核大小决定,并微调该带内的辐射场。在推理时,我们将光线投射到网格上,并仅在封闭区域内评估辐射场,从而大大减少了所需的样本数量。实验表明,我们的方法能够以非常高的保真度实现高效渲染。我们还证明提取的包络可以实现动画和模拟等下游应用。
NeRF与3D视觉
,赞5

EvaSurf: Efficient View-Aware Implicit Textured Surface Reconstruction on Mobile Devices
https://arxiv.org/abs/2311.09806
Jingnan Gao, Zhuo Chen, Yichao Yan, Bowen Pan, Zhe Wang, Jiangjing Lyu, Xiaokang Yang
上海交通大学、阿里
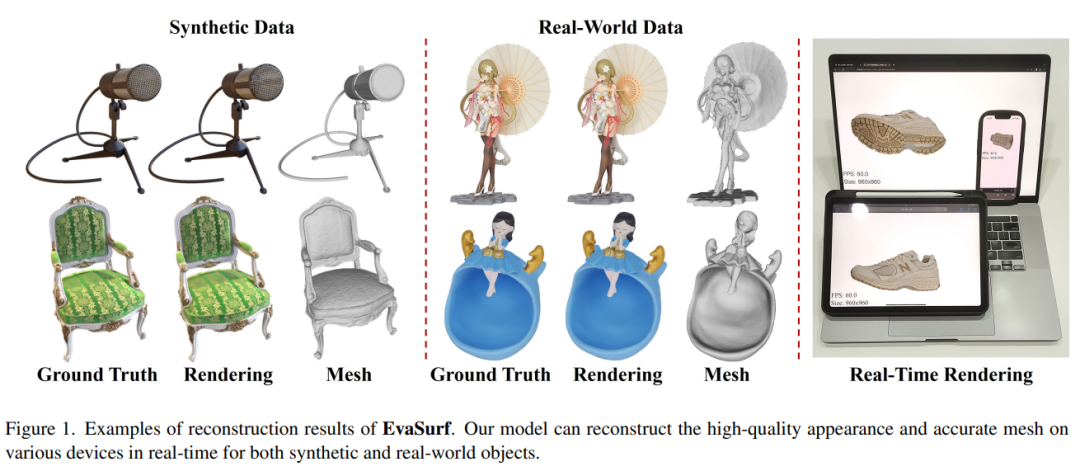
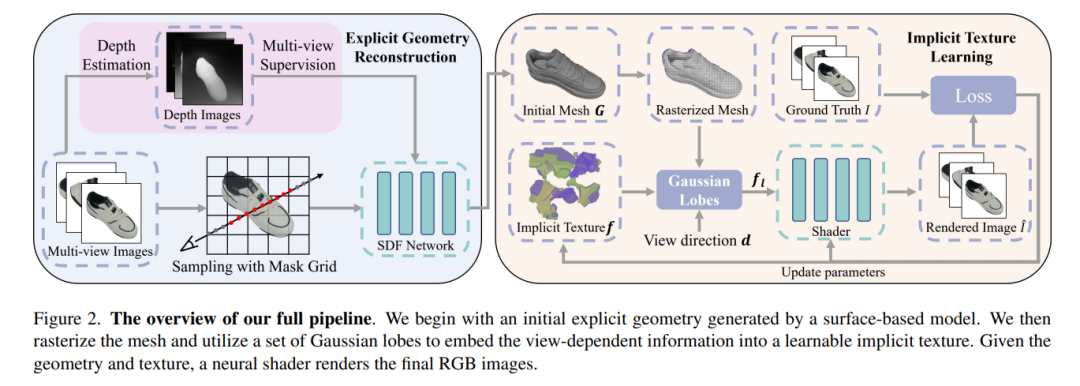
重建现实世界的 3D 对象在计算机视觉中有许多应用,例如虚拟现实、视频游戏和动画。理想情况下,3D 重建方法应实时生成具有 3D 一致性的高保真结果。传统方法使用照片一致性约束或学习特征来匹配图像之间的像素,而神经辐射场 (NeRF) 等可微渲染方法则使用基于表面的表示或可微体积渲染来生成高保真场景。然而,这些方法需要过多的运行时间来进行渲染,这使得它们对于日常应用程序来说不切实际。为了应对这些挑战,我们提出了 EvaSurf,一种移动设备上的高效视图感知隐式纹理表面重建方法。在我们的方法中,我们首先采用带有多视图监督模块的高效基于表面的模型,以确保准确的网格创建。为了实现高保真渲染,我们学习嵌入一组高斯波瓣的隐式纹理来捕获与视图相关的信息。此外,通过显式几何和隐式纹理,我们可以采用轻量级神经着色器来减少计算开销,并进一步支持常见移动设备上的实时渲染。大量的实验表明,我们的方法可以在合成数据集和真实数据集上重建高质量的外观和精确的网格。此外,我们的方法可以使用单个 GPU 在短短 1-2 小时内完成训练,并以超过 40FPS(每秒帧数)的速度在移动设备上运行,渲染所需的最终包仅占用 40-50 MB。

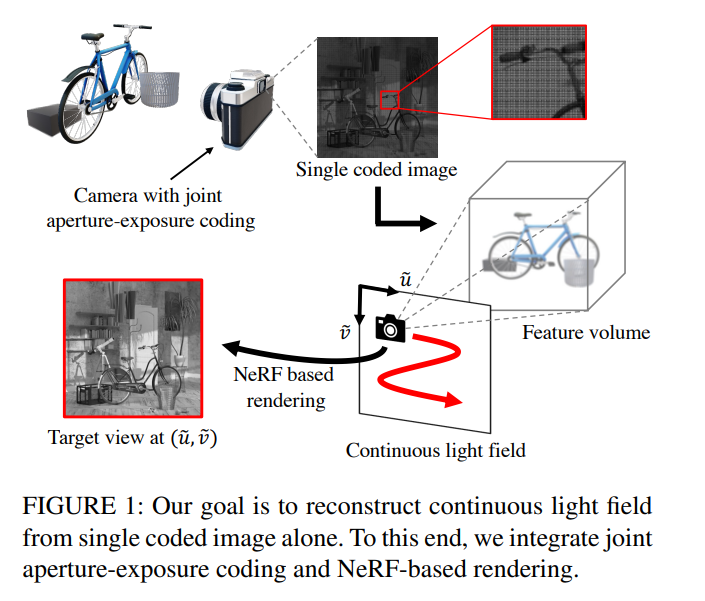
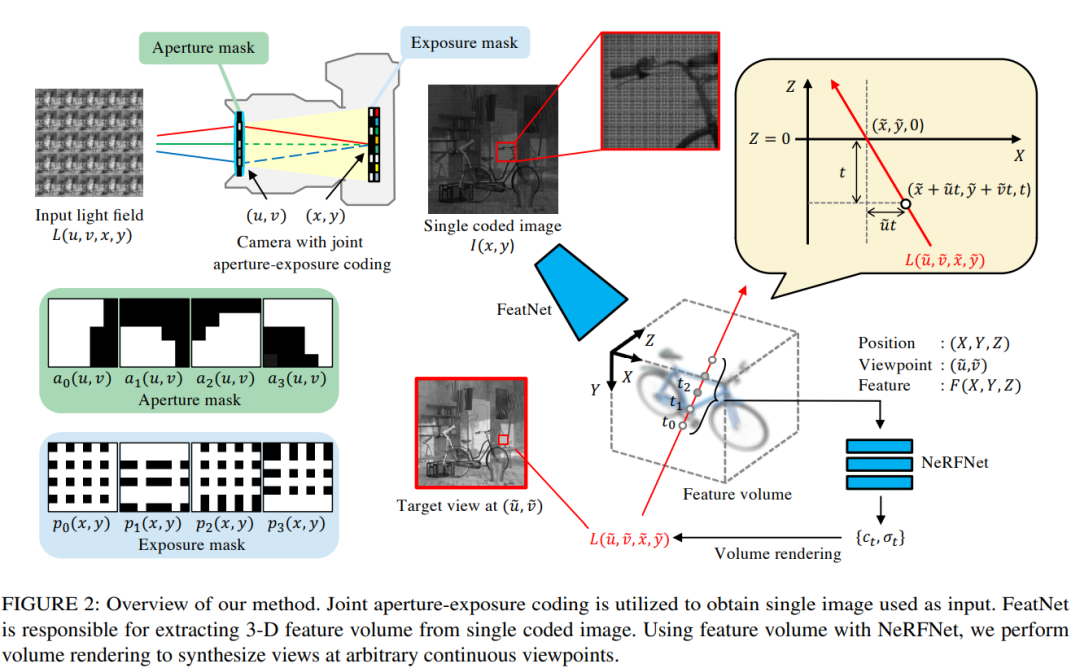
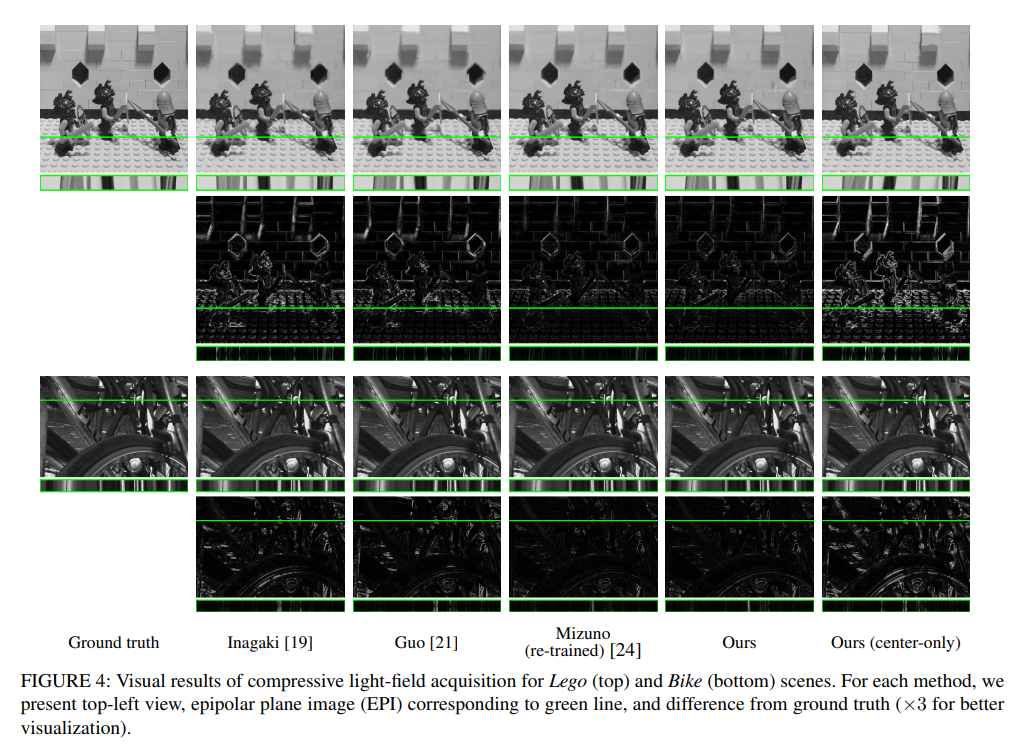
Reconstructing Continuous Light Field From Single Coded Image
https://arxiv.org/abs/2311.09646
Yuya Ishikawa, Keita Takahashi, Chihiro Tsutake, Toshiaki Fujii
Nagoya University
我们提出了一种从单个观察到的图像重建目标场景的连续光场的方法。我们的方法结合了两个方面的优势:用于压缩光场采集的联合孔径曝光编码和用于视图合成的神经辐射场(NeRF)。相机中实现的联合孔径曝光编码可以将 3D 场景信息有效嵌入到观察到的图像中,但在之前的工作中,它仅用于重建离散光场视图。基于 NeRF 的神经渲染可以从连续视点进行 3D 场景的高质量视图合成,但当仅给出单个图像作为输入时,它很难达到令人满意的质量。我们的方法将这两种技术集成到一个高效的端到端可训练管道中。经过对各种场景的训练,我们的方法可以准确有效地重建连续光场,而无需任何测试时间优化。据我们所知,这是第一个连接两个世界的工作:有效获取 3D 信息的相机设计和神经渲染。
3DGS相关
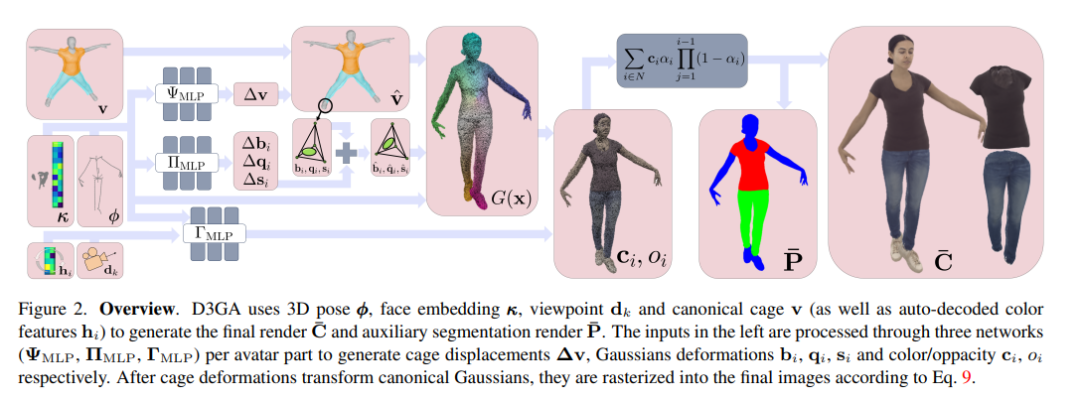
Drivable 3D Gaussian Avatars
https://arxiv.org/abs/2311.08581
Wojciech Zielonka, Timur Bagautdinov, Shunsuke Saito, Michael Zollhöfer, Justus Thies, Javier Romero
Meta Reality Labs Research、Technical University of Darmstadt、Max Planck Institute for Intelligent Systems
我们推出了可驾驶 3D 高斯化身 (D3GA),这是第一个用高斯图形渲染的人体 3D 可控模型。 当前逼真的可驾驶化身需要训练期间准确的 3D 配准、测试期间的密集输入图像,或两者兼而有之。 基于神经辐射场的那些对于远程呈现应用来说也往往慢得令人望而却步。 这项工作使用最近提出的 3D 高斯泼溅 (3DGS) 技术,使用密集校准的多视图视频作为输入,以实时帧速率渲染逼真的人体。 为了使这些基元变形,我们放弃了常用的线性混合蒙皮 (LBS) 点变形方法,并使用经典的体积变形方法:笼形变形。 考虑到它们的尺寸较小,我们用关节角度和关键点驱动这些变形,这更适合通信应用。 当使用相同的训练和测试数据时,我们对九个具有不同体型、衣服和动作的受试者进行的实验获得了比最先进的方法更高质量的结果。
NeRF与3D视觉
,赞20





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











