







关于monodepth2自建数据集再训练实验的项目源码分享在公众号里面啦~
Monodepth2整体基于Unet架构,这种网络架构能够实现更精确的分割,Unet网络架构的收缩路径和扩展路径对称,Unet网络在文末创新点章节有具体介绍,这里简述网络结构联系。
Unet架构分为左编码器和右解码器结构,在架构中使用残差网络Resnet18作为深度编码器,残差网络可以实现跳跃连接,可以将上层网络的信息引入到下层网络,这样来解决深层网络梯度消失问题,并且残差网络的网络层数加深可以提升网络的性能,增强训练网络的鲁棒性,同时降低训练误差和测试误差。但是网络层次越多,训练速度越慢,所以Resnet18与Resnet50模型相比速度更快。
编码器网络的输入为单目相机所拍摄的彩色RGB图像,编码器网络结构如下图所示

图2.6 编码器网络结构
如图,彩色图像首先进入卷积层和BN层进行处理,BN层可以将输入图像进行归一化处理,防止梯度消失或爆炸现象的出现,并且可以加快训练速度。然后进入ReLU激活函数和最大池化层,最大池化层对提取特征压缩,简化网络复杂度。然后进入Layer1,Layer1由两个残差块组成,残差块内部使用的激活函数为ELU激活函数,Layer2、Layer3、Layer4与Layer1是相同的结构,跨越不同层次之间,采用加大步长的卷积核进行卷积操作来替代下采样的过程,特征图的尺寸也逐倍缩小,编码器网络完成任务。
关于resnet-encoder中的前向传播函数设置如下
def forward(self, input_image):
self.features = []
x = (input_image - 0.45) / 0.225
x = self.encoder.conv1(x)
x = self.encoder.bn1(x)
self.features.append(self.encoder.relu(x))
self.features.append(self.encoder.layer1(self.encoder.maxpool(self.features[-1])))
self.features.append(self.encoder.layer2(self.features[-1]))
self.features.append(self.encoder.layer3(self.features[-1]))
self.features.append(self.encoder.layer4(self.features[-1]))
return self.features
而解码器需要对编码器输出图像进行整合解析,深度估计网络中使用上采样层和卷积层结合的方法作为深度解码器,解码器的结构如下图所示
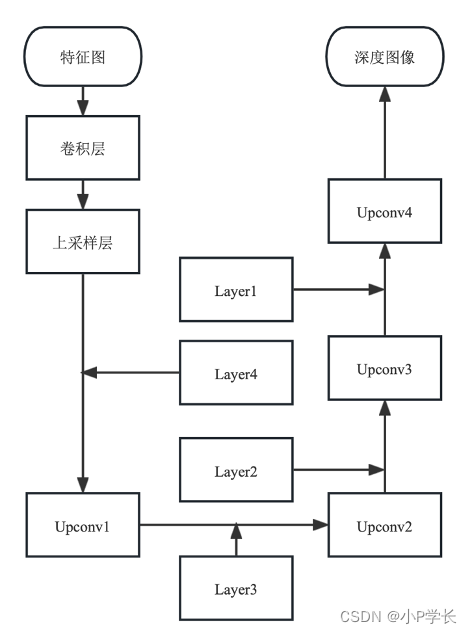
图2.7 解码器网络结构
解码器网络中包括4个相同的Upconv结构,Upconv中包括特征图融合、多个卷积层和上采样过程,每个Upconv的输入为上一层网络的输出和编码器网络中相同尺度的特征图,将相同尺寸的特征图融合后,进行卷积操作、上采样操作,最后Upconv4所输出的图像尺寸与输入图像尺寸相同。在解码器中,使用反射填充来替代零填充,当需要对输入矩阵进行扩充时,扩充值使用附近的像素值,这样可以减少边界处模糊的情况,提高特征图的清晰度。
在每个Upconv的输出端使用Sigmoid函数,使用下式将最后一个Sigmoid函数输出结果转换为深度,选择和将约束在0.1到100个单位之间。
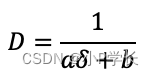
最后是位姿网络。因为单张彩色图片是无法获取场景下的三维信息的,所以使用单目相机所拍摄视频的连续前后帧才可以获得相机相对于场景中角度和位置的变化。位姿网络的输入为上一帧图像和当前帧图像,是一对彩色图像,所以位姿网络接收6通道作为输入。位姿网络与深度网络整体流程类似,网络也包含编码过程和解码过程,编码器也是resnet-encoder,只是解码器变成了pose-decoder,网络最终输出轴角变化矩阵和平移变化矩阵。
Resnet18结构在位姿编码中使用预训练权重模型,预训练权重模型是在较大的数据集上进行训练所得到的参数模型,可以直接用于解决相似的问题。这里引入预训练残差网络模型进行初始化,可以大大节省训练时间,降低训练过程中欠拟合和过拟合的风险。将预训练模型中第一个卷积核的维度进行扩展,使网络可以接收6通道作为输入,将扩展后的卷积核中的权重除以2,保证卷积操作结束后与单张图像进入残差网络的数值范围相同。编码器网络中最终输出图像特征。
解码器网络将编码器中所提取的图像特征进行整合。首先使用Squeeze对图像特征进行降维操作,然后将图像特征按照行并排起来,然后进行多次卷积操作,将矩阵缩放0.01,最终输出轴角矩阵和平移矩阵。使用矩阵预测出相机位置变化的平移运动和旋转运动。
关于pose-decoder的前向传播函数如下
def forward(self, input_features):
last_features = [f[-1] for f in input_features]
cat_features = [self.relu(self.convs["squeeze"](f)) for f in last_features]
cat_features = torch.cat(cat_features, 1)
out = cat_features
for i in range(3):
out = self.convs[("pose", i)](out)
if i != 2:
out = self.relu(out)
out = out.mean(3).mean(2)
out = 0.01 * out.view(-1, self.num_frames_to_predict_for, 1, 6)
axisangle = out[..., :3]
translation = out[..., 3:]
return axisangle, translation 项目原文中关于Depth network和Pose network可视化配图如下。
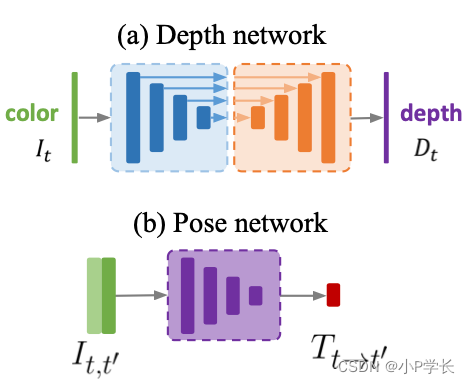
图2.8 monodepth2原文Depth/Pose network配图
本节最后,再归纳一下网络中使用到的上采样过程(Upconv),并与常见的下采样过程进行对比。
常见的下采样层有卷积层和汇聚层,它们一般有两个作用:一是减少计算量,防止过拟合;而是增大感受野,使得后面的卷积核能够学到更加全局的信息。而在卷积神经网络中,由于输入图像通过CNN提取特征后,输出的尺寸往往会变小,而有时需要将图像恢复到原来的尺寸以便进行进一步的计算,比如图像的语义分割,而这个使图像由小分辨率映射到大分辨率的操作,叫作上采样,它的实现方式一般有如下三种:
- 插值,一般使用的是双线性插值,因为效果最好,虽然计算上比其它插值方式复杂,但是相对于卷积计算还是简单许多,其它插值方式还有最近邻插值、三线性插值等;
- 转置卷积或反卷积,通过对输入特征图间隔填充0,再进行标准的卷积计算,可以使得输出特征图的尺寸比输入更大,这是一种可以对参数进行学习优化的向上采样的方式,这也是前述Unet解码器中所使用的;
- 上汇聚/池化,即在对称最大汇聚层位置记录最大值的索引位置,然后在上采样阶段将对应的值放置到原先记录的最大值位置,其余位置补0,这种方法没有参数学习,速度更快,采取给定策略上采样。
关于自建数据集实验的源码分享在公众号了~

















 5795
5795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











