







1 lora介绍
Lora参数微调通常指的是在大型语言模型(LLM)中,使用LoRA(Low-Rank Adaptation)方法进行高效的参数调整。LoRA是一种参数高效微调技术,它通过低秩分解来模拟参数的改变量,从而大大减少了下游任务的可训练参数数量。
2 lora核心思想
LoRA的核心思想是利用矩阵的低秩特性,将原始模型的参数矩阵分解成两个较小的矩阵的乘积。在微调过程中,只训练这两个较小的矩阵的参数,而保持原始模型的大部分参数不变。这种方法显著降低了对显存的需求,同时保持了模型的性能。
个人观点:通俗理解,就是大模型参数量太多了,秩(秩通俗理解为矩阵所携带的信息量)太多了,但是你微调,数据量远远小于参数量,你用不到那么多秩去训练,所以用一点秩训练就可以了,从这一过程中可以看到,当数据量足够大的时候,是没必要做lora微调的。
3 lora数学计算流程
3.1 SVD奇异值分解矩阵
计算公式如下
A
m
×
n
=
U
m
×
m
Σ
m
×
n
V
n
×
n
T
A_{m×n} = U_{m×m} \Sigma_{m×n} V^{\mathrm{T}}_{n×n}
Am×n=Um×mΣm×nVn×nT
其中:
U U U为m行m列,该矩阵的每一个列向量都 A A T AA^T AAT的特征向量。
Σ \Sigma Σ为m行n列,将 A T A A^TA ATA或 A A T AA^T AAT的特征值开根号,得到的就是该矩阵主对角线上的元素。
V V V为n行n列,该矩阵的每一个列向量都是 A T A A^TA ATA的特征向量。
因此,我们如果想取一个秩为1的矩阵,只需要取第一个矩阵的一列,第二个矩阵的一个元素,第三个矩阵的一行即可,最后得出的矩阵仍为m×n,大大减少了参数计算量。
import torch
import numpy as np
torch.manual_seed(0)
# ------------------------------------
# n:输入数据维度
# m:输出数据维度
# ------------------------------------
n = 10
m = 10
# ------------------------------------
# 随机初始化权重W
# 之所以这样初始化,是为了让W不要满秩,
# 这样才有低秩分解的意义
# ------------------------------------
nr = 10
mr = 2
W = torch.randn(nr,mr)@torch.randn(mr,nr)
# ------------------------------------
# 随机初始化输入数据x
# ------------------------------------
x = torch.randn(n)
# ------------------------------------
# 计算Wx
# ------------------------------------
y = W@x
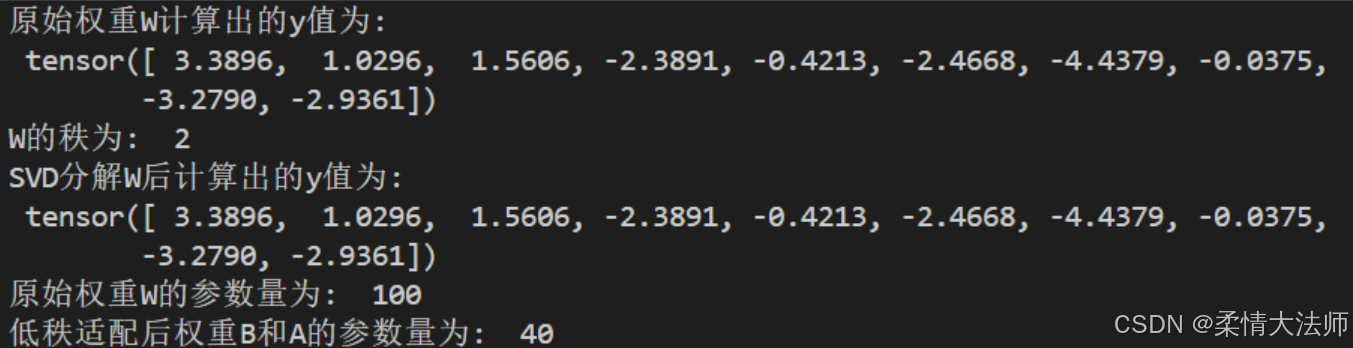
print("原始权重W计算出的y值为:\n", y)
# ------------------------------------
# 计算W的秩
# ------------------------------------
r= np.linalg.matrix_rank(W)
print("W的秩为: ", r)
# ------------------------------------
# 对W做SVD分解
# ------------------------------------
U, S, V = torch.svd(W)
# ------------------------------------
# 根据SVD分解结果,
# 计算低秩矩阵A和B
# ------------------------------------
U_r = U[:, :r]
S_r = torch.diag(S[:r])
V_r = V[:,:r].t()
B = U_r@S_r # shape = (d, r)
A = V_r # shape = (r, d)
# ------------------------------------
# 计算y_prime = BAx
# ------------------------------------
y_prime = B@A@x
print("SVD分解W后计算出的y值为:\n", y)
print("原始权重W的参数量为: ", W.shape[0]*W.shape[1])
print("低秩适配后权重B和A的参数量为: ", A.shape[0]*A.shape[1] + B.shape[0]*B.shape[1])
输出结果
3.2 lora计算流程
如图
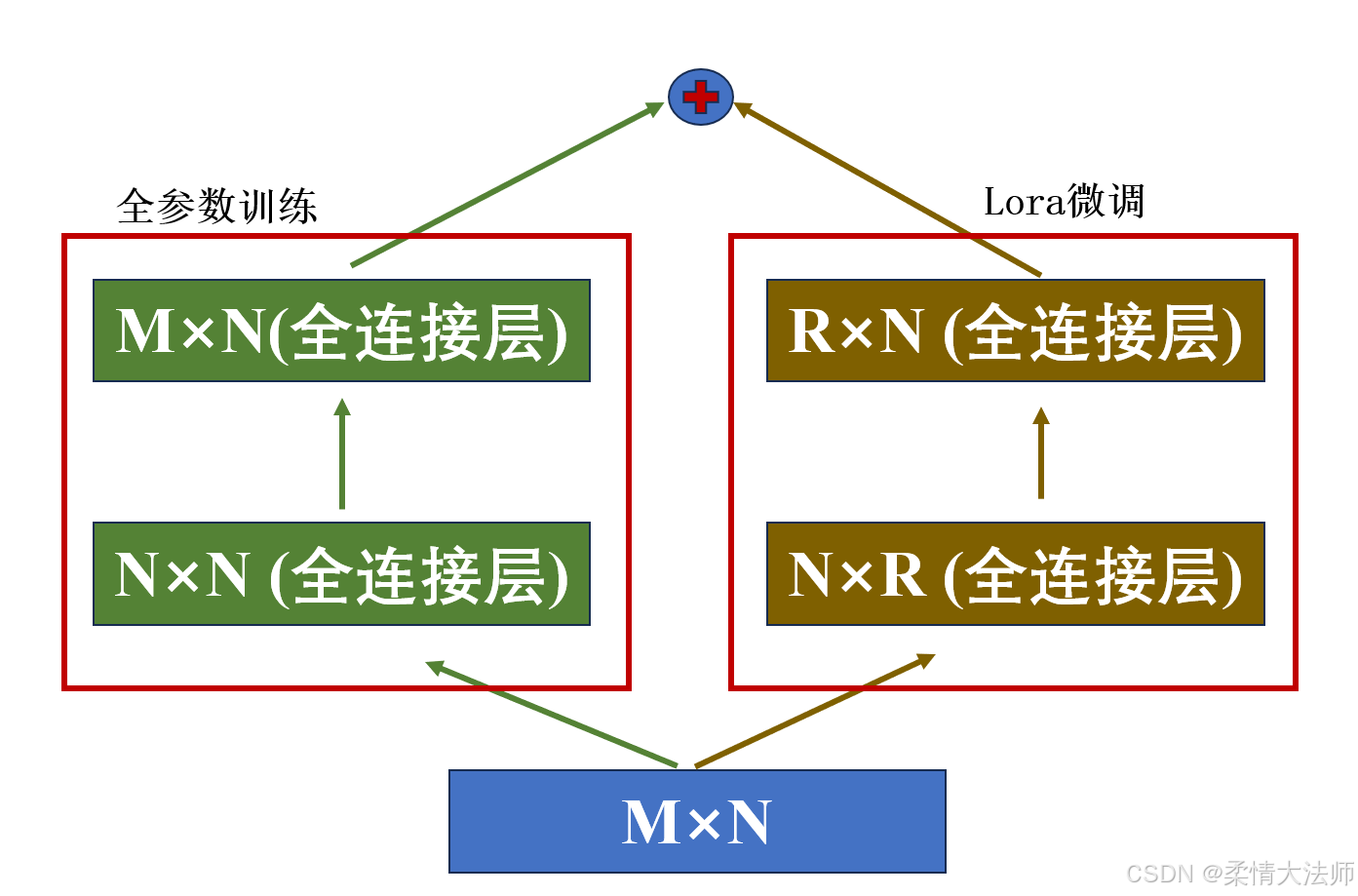
有一个细节需注意,初始阶段,R×N层初始化为0,目的是加入lora后不会对训练好的模型产生扰动。在推理过程中,lora并不会影响到推理速度。
**注:**基础的lora微调只对全连接层能调整,最后为残差连接。
4 lora实战
原简单程序
import torch
from torch import nn
net = nn.Sequential(nn.Linear(10, 20), nn.ReLU(), nn.Linear(20, 2))
print(net)
结果

lora微调
import torch
from torch import nn
from peft import LoraConfig, get_peft_model
net = nn.Sequential(nn.Linear(10, 20), nn.ReLU(), nn.Linear(20, 2))
# print(net)
config = LoraConfig(target_modules=["0"])
net2 = get_peft_model(net, config)
print(net2)
结果
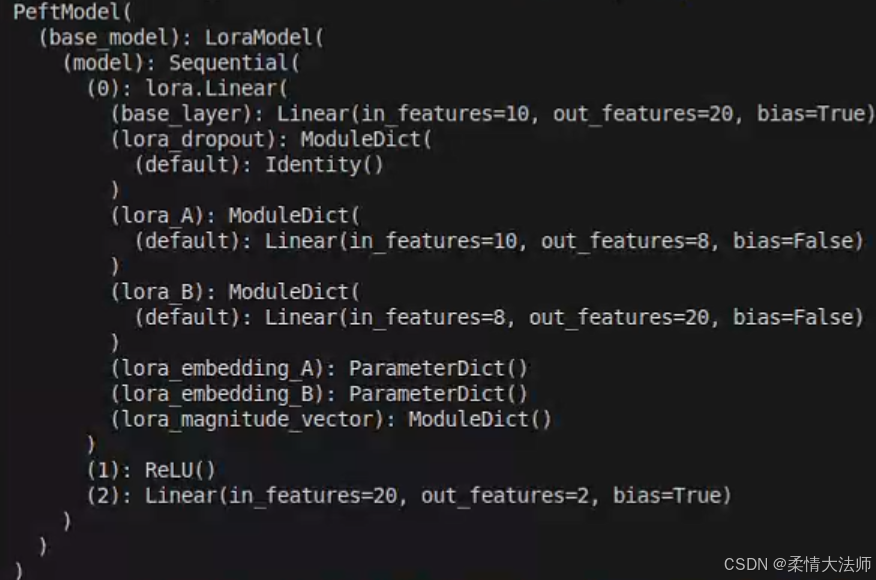
可以看到第0层结构发生了更改。
配置文件参考
from peft import LoraConfig, TaskType, get_peft_model
# 定义 LoRA 的配置参数
config = LoraConfig(
task_type=TaskType.CAUSAL_LM, # 指定任务类型为自回归语言建模任务(Causal Language Modeling),如 GPT 系列的模型
target_modules=["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj"], # 这些是模型中要应用 LoRA 的目标模块
inference_mode=False, # 表示训练模式,设置为 True 时是推理模式;为 False 是训练模式
r=8, # LoRA 的秩 r,代表分解时矩阵的秩,越大越能保留原有的模型信息,但计算复杂度也会增加
lora_alpha=32, # LoRA 的 alpha 超参数,控制了低秩矩阵的缩放因子。一般设置为与 r 成比例的值
lora_dropout=0.1, # 在 LoRA 模块中应用 Dropout,防止过拟合,防止微调时模型过拟合到训练数据
)
# 应用 PEFT(LoRA)到预训练的模型上
model = get_peft_model(model, config) # 使用 get_peft_model 函数,将定义好的 LoRA 配置应用到预训练模型中


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









