







简述
对于视觉大模型的应用,我认为是一个大火的方向,方法有很多,我们这次先讨论基础的方法,第一次写,有不对的地方或者不懂的地方大家在评论区多多交流,一定都会去回复
1 Linear Probing(线性探测)
定义:线性探测是一种用于评估预训练模型性能的方法,通过替换模型的最后一层为线性层并保持其余部分不变。在此过程中,仅训练这个线性层,以测试模型的表征学习能力。该技术常用于自监督学习模型的评测。
优点:计算效率高,仅训练线性分类器,计算资源消耗较少。
缺点:线性分类器可能无法捕捉到预训练模型中的复杂线性关系。
原理图: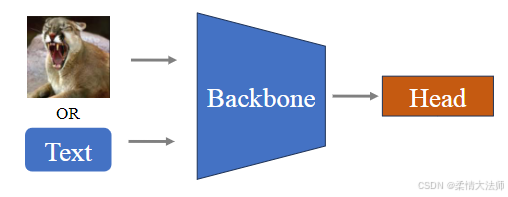
首先,选择一个在大规模图像数据集(例如ImageNet)上预训练的Backbone模型,该模型已经学习到了丰富的图像特征表示。接着,将目标图像输入到这个预训练的Backbone中,提取图像的高级抽象特征,这些特征包含了图像的内容和结构信息。
然后,在Backbone之后添加一个线性变换层(Head),这个层通常是一个简单的全连接层,用于将高维的特征向量映射到新的任务输出空间。在新的任务数据集上,仅对这个线性层进行微调,而不需要重新训练整个Backbone,这样可以节省计算资源,同时利用预训练模型的强大特征提取能力。
最后,训练完成后,将新的图像输入到模型中,通过Backbone提取特征,再通过训练好的线性层进行任务预测,如分类、检测等。
代码
import torch
import torch.nn as nn
import timm
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
import torchvision.transforms as transforms
class LinearProbing(nn.Module):
def __init__(self, num_classes):
super(LinearProbing, self).__init__()
self.vit = timm.create_model('vit_small_patch16_224', pretrained=True)
#冻结每一层训练参数
for param in self.vit.parameters():
param.requires_grad = False
#更换线性层头
self.vit.head = nn.Linear(self.vit.head.in_features, num_classes)
def forward(self, x):
return self.vit(x)
def load_cifar10_dataset():
transform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])
train_dataset = CIFAR10(root='./cifar10', train=True, download=True, transform=transform)
loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
return loader
def main():
# 加载数据集
dataset = load_cifar10_dataset()
model = LinearProbing(num_classes=10)
for images, labels in dataset:
logits = model(images)
loss = torch.nn.CrossEntropyLoss()(logits, labels)
print(loss)
if __name__ == "__main__":
main()
2 Finetune(微调)
定义:微调是指在目标任务上对预训练模型进行进一步训练,以调整模型的权重和参数,使其更好地适应新的数据集和任务。
优点:微调能够充分利用预训练模型的特征表示,并快速适应新的任务;通过调整模型参数,微调通常能够显著提升模型在目标任务上的性能。
缺点:微调需要较大的计算资源,特别是对于大型预训练模型;如果目标任务的数据集较小,微调可能会导致过拟合。
原理图: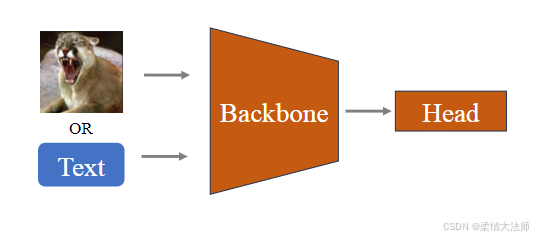
视觉基础迁移模型的Fine-tuning原理如图所示,其核心在于利用预训练模型(Backbone)和特定任务的头(Head)模型。首先,一个在大规模数据集上预训练的模型作为Backbone,该模型已学习到众多通用的视觉特征,适用于各种视觉任务。接着,输入数据(通常是图像)通过Backbone进行特征提取,这些高层特征对后续任务至关重要。提取的特征随后被送入Head模型,该模型专为特定任务(如图像分类、目标检测等)设计。
代码:
import torch
import torch.nn as nn
import timm
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
import torchvision.transforms as transforms
class FineTuning(nn.Module):
def __init__(self, num_classes):
super(FineTuning, self).__init__()
self.vit = timm.create_model('vit_small_patch16_224', pretrained=True)
self.vit.head = nn.Linear(self.vit.head.in_features, num_classes)
def forward(self, x):
return self.vit(x)
def load_cifar10_dataset():
transform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])
train_dataset = CIFAR10(root='./cifar10', train=True, download=True, transform=transform)
loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
return loader
def main():
# 加载数据集
dataset = load_cifar10_dataset()
model = FineTuning(num_classes=10)
for images, labels in dataset:
logits = model(images)
loss = torch.nn.CrossEntropyLoss()(logits, labels)
print(loss)
if __name__ == "__main__":
main()
3 Adapter(适配器)
定义:Adapter是一种参数高效的迁移学习方法,通过在预训练模型的特定层中插入轻量级的适配器模块来适应新任务。
优点:Adapter方法仅调整少量的参数,降低了计算和存储需求;每个任务都可以使用独立的Adapter模块进行微调,避免了任务间的干扰。
缺点:随着任务数量的增加,模型的整体复杂度也会相应增加。
原理图: 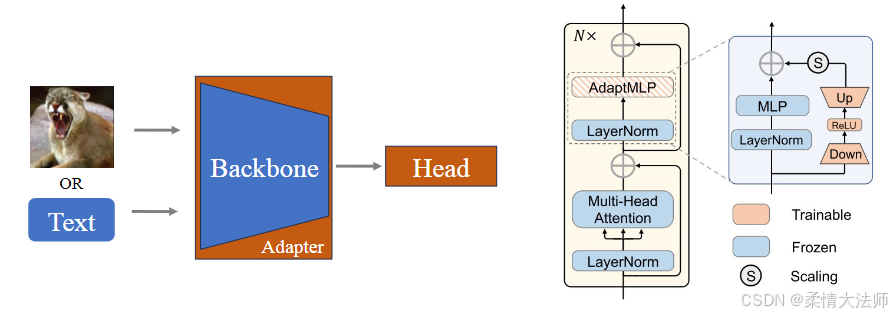
模型首先接收图像或文本输入,通过预训练的Backbone网络提取输入数据的特征。随后,特征进入Adapter模块。这个模块由多个组件构成,如AdaptMLP(适应多层感知器)、LayerNorm(层归一化)以及Multi-Head Attention(多头注意力机制)。Adapter的主要作用是对Backbone提取的特征进行调整,以适应新的任务或领域。在迁移过程中,Adapter模块内的部分参数(如MLP部分)是可训练的,以便在新的任务中进行微调。而其他部分(如LayerNorm)则保持冻结,使用预训练模型中的参数。经过Adapter调整后的特征进入Head模块,该模块包含特定任务相关的层,用于最终的预测或分类。
代码:
import torch
import torch.nn as nn
import timm
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
import torchvision.transforms as transforms
class AdaptMLP(nn.Module):
def __init__(self, input_dim, hidden_dim):
super(AdaptMLP, self).__init__()
self.down_proj = nn.Linear(input_dim, hidden_dim)
self.relu = nn.ReLU(inplace=True)
self.up_proj = nn.Linear(hidden_dim, input_dim)
def forward(self, x):
down = self.down_proj(x)
relu = self.relu(down)
up = self.up_proj(relu)
return up
class Adapter(nn.Module):
def __init__(self, num_classes, hidden_dim):
super(Adapter, self).__init__()
self.vit = timm.create_model('vit_small_patch16_224', pretrained=True)
# 先冻结所有的参数
for param in self.vit.parameters():
param.requires_grad = False
self.adapt_mlps = []
for i, block in enumerate(self.vit.blocks): #每个Block包括self attention layernorm以及这个mlp
# 冻结所有子block的参数
for param in block.parameters():
param.requires_grad = False
self.adapt_mlps.append(AdaptMLP(input_dim=self.vit.blocks[i].mlp.fc1.in_features, hidden_dim=hidden_dim))
self.vit.head = nn.Linear(self.vit.head.in_features, num_classes)
def forward(self, x):
#这一过程维度的变换在CLIP那篇文章详细讲解了
x = self.vit.patch_embed(x) # vit第一步将图像压平,(B,3,224,224)->(B,196,384)
if self.vit.cls_token is not None:
cls_token = self.vit.cls_token.expand(x.shape[0], -1, -1) # (1,1,384) -> (B,1,384)
x = torch.cat((cls_token, x), dim=1) # (B,197,384)
if self.vit.pos_embed is not None:
x = x + self.vit.pos_embed.expand(x.shape[0], -1, -1) # (1,197,184) -> (B,197,384)
#将部分位置随机drop掉,提高模型的泛化能力
x = self.vit.pos_drop(x) # Apply dropout if present
for i, block in enumerate(self.vit.blocks):
block_input = x
#红色方框部分
x = block.norm1(x) # (B,197,384)
x = block.attn(x)
x = block_input + x
#绿色方框部分
original_mlp_output = block.norm2(x)
original_mlp_output = block.mlp(original_mlp_output) # (B,197,384)
adapt_mlp_output = self.adapt_mlps[i](x) # (B,197,384)
x = original_mlp_output + adapt_mlp_output
x = self.vit.norm(x)
if self.vit.cls_token is not None:
#部分人感觉这一步有点绕,下面给出形象解释
x = x[:, 0] # (B,197,384) -> (B,384)
return self.vit.head(x)
def load_cifar10_dataset():
transform = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])
train_dataset = CIFAR10(root='./cifar10', train=True, download=True, transform=transform)
loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
return loader
def main():
dataset = load_cifar10_dataset()
model = Adapter(num_classes=10, hidden_dim=64)
for images, labels in dataset:
logits = model(images)
loss = torch.nn.CrossEntropyLoss()(logits, labels)
print(loss)
if __name__ == "__main__":
main()
注:
(1)nn.ReLU(inplace=True)中的inplace参数决定了操作是否在原地进行。如果设置为True,那么操作会直接修改输入的数据,而不是创建一个新的数据副本来存储结果。这样做的好处是可以节省内存,因为它避免了额外的内存分配来存储修改后的数据。然而,这也意味着输入数据的原始版本会被覆盖,这可能会在某些情况下引起问题,特别是在你需要保留原始数据的情况下。在训练深度学习模型时,特别是在使用反向传播(backpropagation)时,通常不建议修改原始数据,因为这可能会影响梯度的计算和传播。然而,在一些特殊情况下,比如当你确定不需要再访问原始数据时,或者在推理(inference)阶段,使用inplace=True可以帮助减少内存使用。
(2)对于刚才切片的理解
想象你有一个书架,这个书架上有100层(代表100个样本),每层都放满了196本不同的书(代表196个时间步或序列元素),而每本书都有384页(代表384个特征)。这个书架就是一个三维的数组,形状为(100, 196, 384)。
现在,你决定只从书架的每一层中拿出第一本书,并且你想要保留这些书的所有页(即所有特征)。你并不关心这些书在书架上的具体位置,你只关心每本书的内容(即特征)。
当你这样做的时候,你实际上是在“压缩”书架的维度。原本书架有三个维度:层数(样本数)、每层的书数和每本书的页数(特征数)。但现在,你只保留了层数(样本数)和每本书的页数(特征数),而不再关心每层的书数(因为你只拿了每层的第一本书)。
所以,你现在手中的书堆成了一个新的二维结构:100层(样本数)和每层一本书的所有页(384个特征)。这个新的二维结构就是形状为(100, 384)的数组。
在Python的NumPy库或类似的库中,这个过程可以通过索引来实现。比如,如果你有一个形状为(100, 196, 384)的数组x,你可以通过x[:, 0, :]来获取这个新的二维数组。这里的:表示选择该维度的所有元素,0表示选择第二维的第一个元素。
4 Prompt(提示)
**定义:**Prompt工程是一种技术,通过向预训练模型提供任务特定的提示(如自然语言指令或向量表示),来引导模型生成与任务相关的输出。视觉提示(Visual Prompt)分为两种,一种是基于标注的Prompt,另一种是基于学习的Prompt。
**优点:**Prompt方法无需更新预训练模型的参数,降低了计算和存储需求;:Prompt可以设计为离散的自然语言指令或连续的向量表示,适用于不同的任务和场景。
**缺点:**设计有效的Prompt需要专业知识和经验;Prompt的性能可能受到预训练模型本身能力和限制的影响。
原理图: 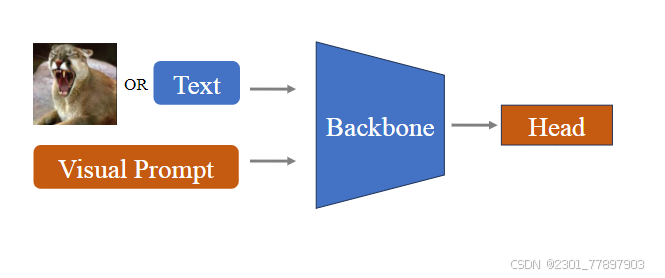
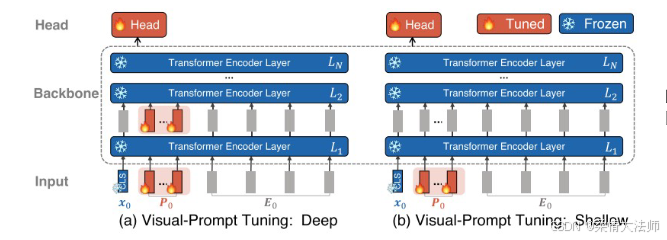
在视觉基础模型迁移中,视觉提示微调(Visual-Prompt Tuning)技术以其独特的Deep和Shallow两种方式,为模型适应不同视觉任务提供了有效路径。下面将分别详细讲解这两种方式。
Deep方式
核心特点:
深度融合:在Deep方式中,视觉提示被嵌入到模型的每一层Transformer编码器层中。这意味着视觉提示与输入数据在模型的每一层都会进行深度融合,从而使模型能够更全面地捕捉到任务特定的视觉特征。
复杂任务适应性:由于Deep方式实现了深度视觉信息的融合与抽象,它更适用于那些需要复杂视觉理解和处理的任务。通过每一层的精细调整,模型能够更好地适应任务的多样性。
实现机制:
在每一层Transformer编码器层中,都会插入对应的视觉提示。这些提示可以是可学习的参数向量,它们与输入数据的嵌入表示一起经过自注意力机制、前馈网络等组件进行计算。
在训练过程中,视觉提示的参数会与其他模型参数一起进行优化,以实现对特定任务的最佳适应。
Shallow方式
核心特点:
简洁高效:与Deep方式相比,Shallow方式更为简洁。它仅在模型的表层(通常是第一层Transformer编码器层)引入视觉提示。这种方式减少了计算量,提高了迁移效率。
资源受限场景适用性:由于Shallow方式的计算量较小,它更适用于那些计算资源受限或任务相对简单的场景。
实现机制:
在模型的表层(第一层Transformer编码器层)中,输入数据的嵌入表示与视觉提示进行加权求和或点积等计算,以生成融合后的特征表示。
这些融合后的特征表示随后经过后续的Transformer编码器层进行计算,最终生成任务特定的输出。
在训练过程中,主要优化的是表层视觉提示的参数以及后续编码器层的参数(如果需要的话),以保持模型的简洁性和高效性。
总结
Deep和Shallow两种方式各有优势,适用于不同的场景和任务需求。Deep方式通过深度融合视觉信息,更适用于复杂视觉任务;而Shallow方式则以其简洁高效的特点,适用于资源受限或简单任务场景。在实际应用中,可以根据具体任务需求和计算资源情况选择合适的方式来实现视觉基础模型的迁移与优化。
代码:
import torch
import torch.nn as nn
import timm
from torchvision import transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader
class VisualPromptTuning(nn.Module):
def __init__(self, num_classes, hidden_dim, num_learnable_tokens=1, mode='shallow'):
super(VisualPromptTuning, self).__init__()
self.vit = timm.create_model('vit_small_patch16_224', pretrained=True, num_classes=num_classes)
self.num_learnable_tokens = num_learnable_tokens
self.mode = mode
self.vit.head = nn.Linear(self.vit.head.in_features, num_classes)
# 假设一个批次有10个可学习参数,没有在self.vit.parameters中,所以下面步骤冻结冻结不了它
self.learnable_tokens = nn.Parameter(torch.randn(1, num_learnable_tokens, self.vit.embed_dim)) # (1,10,384)
if mode == 'deep':
self.deep_learnable_tokens = nn.ParameterList([
nn.Parameter(torch.randn(1, num_learnable_tokens, self.vit.embed_dim)) # (1,10,384)
for _ in self.vit.blocks
])
#冻结参数
for param in self.vit.parameters():
param.requires_grad = False
for param in self.vit.head.parameters():
param.requires_grad = True
def forward(self, x):
x = self.vit.patch_embed(x)
if self.vit.cls_token is not None:
# -1代表维度不变,expand可以在不增加内存使用量的情况下调整张量形状
cls_tokens = self.vit.cls_token.expand(x.size(0), -1, -1)
x = torch.cat((cls_tokens, x), dim=1) # (B,197,384)
if self.vit.pos_embed is not None:
x = x + self.vit.pos_embed
x = self.vit.pos_drop(x)
if self.mode == 'shallow':
x = torch.cat((self.learnable_tokens.expand(x.size(0), -1, -1), x), dim=1) # expand: (1,10,384)->(B,10,384), cat:(B,197,384)->(B,207,384)
for i, block in enumerate(self.vit.blocks):
if self.mode == 'deep':
x[:, 1:self.num_learnable_tokens + 1] = self.deep_learnable_tokens[i] #(1,10,384)
x = block(x)
x = self.vit.norm(x) # (B,197,384)
if self.vit.cls_token is not None:
x = x[:, 0]
return self.vit.head(x)
def load_cifar10_dataset():
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
train_dataset = CIFAR10(root='./cifar10', train=True, download=True, transform=transform)
loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
return loader
def main():
dataset = load_cifar10_dataset()
model = VisualPromptTuning(num_classes=10, hidden_dim=64, num_learnable_tokens=10, mode='deep')
for images, labels in dataset:
logits = model(images)
loss = torch.nn.CrossEntropyLoss()(logits, labels)
print(f'Loss: {loss.item()}')
if __name__ == "__main__":
main()
注:
一些人对位置编码相加不了解,下面我将展示如何在Vision Transformer(ViT)中将位置嵌入与patch嵌入相加。在这个例子中,我将简化问题,以便于理解。
假设:
- 我们有一个很小的图像,它只被分割成2个patch(在实际应用中,图像通常会被分割成数百甚至数千个patch)。
- 每个patch通过嵌入层被映射到一个5维的向量空间(在实际应用中,嵌入维度通常更高,比如768维)。
- 我们使用2维的位置嵌入来表示每个patch的位置。
注意:在实际应用中,位置嵌入的维度通常与patch嵌入的维度相同。但在这个例子中,为了简化计算,我将它们设为不同的维度。在真实的ViT模型中,你应该将位置嵌入的维度调整为与patch嵌入的维度一致。
现在,让我们进行具体的计算:
- 初始化patch嵌入和位置嵌入:
- 假设两个patch的嵌入向量分别为:[1.0, 2.0, 3.0, 4.0, 5.0] 和 [6.0, 7.0, 8.0, 9.0, 10.0]。
- 假设两个patch的位置嵌入向量分别为:[0.1, 0.2](表示第一个patch的位置)和 [0.3, 0.4](表示第二个patch的位置)。
- 将位置嵌入与patch嵌入相加:
- 对于第一个patch:
- 原始patch嵌入:[1.0, 2.0, 3.0, 4.0, 5.0]
- 位置嵌入:[0.1, 0.2, 0.0, 0.0, 0.0](注意:我添加了三个0来匹配patch嵌入的维度。在实际应用中,位置嵌入的维度应与patch嵌入相同,这里仅为了说明计算过程。)
- 相加后的嵌入:[1.1, 2.2, 3.0, 4.0, 5.0]
- 对于第二个patch:
- 原始patch嵌入:[6.0, 7.0, 8.0, 9.0, 10.0]
- 位置嵌入:[0.3, 0.4, 0.0, 0.0, 0.0](同样添加了三个0来匹配维度。)
- 相加后的嵌入:[6.3, 7.4, 8.0, 9.0, 10.0]
- 对于第一个patch:
在实际应用中,位置嵌入的每一维都可能是通过学习得到的,并且它们的维度与patch嵌入的维度相同。相加操作是逐元素进行的,即位置嵌入的每个元素分别与patch嵌入的对应元素相加。
5 总结
当需要快速评估预训练模型表征能力时,可以选择Linear probing;当目标任务与预训练任务相似且数据集较大时,可以选择Finetune;当需要参数高效且任务独立的迁移学习方法时,可以选择Adapter;而当希望避免微调模型参数且任务灵活性要求较高时,可以选择Prompt。


















 1642
1642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









