






基本概念
Dogs vs. Cats(猫狗大战)来源于Kaggle上的一个竞赛题,任务为给定一个数据集,其中训练集有25000张,猫狗各占一半,测试集12500张,没有标定是猫还是狗。要求设计一种算法对测试集中的猫狗图片进行判别,猫狗大战实际上是一个传统的二分类问题。
项目架构
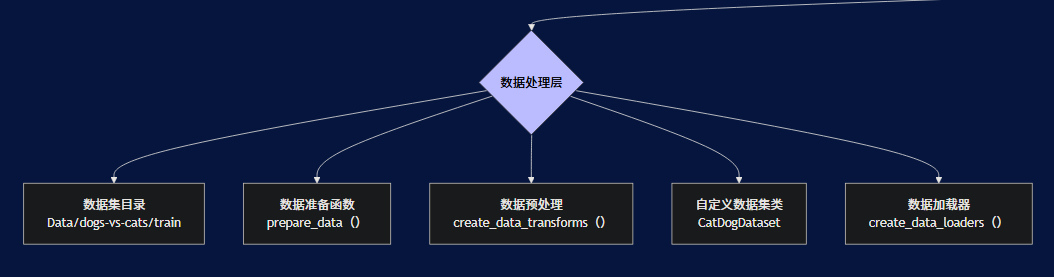
1. 数据处理层
负责数据的加载、预处理和增强:
-
数据集目录:包含猫狗图片的文件夹
-
数据准备函数:将数据划分为训练集和验证集
-
数据预处理:定义训练和验证阶段的数据转换操作
-
自定义数据集类:继承PyTorch Dataset类,处理图像加载和标签分配
-
数据加载器:批量加载数据,支持多线程和数据打乱
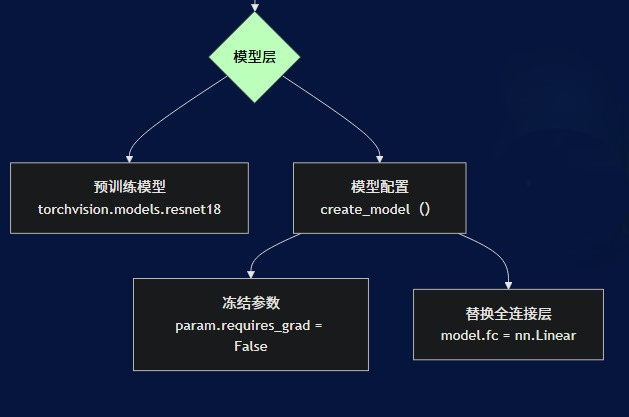
2. 模型层
负责模型的定义和配置:
- 预训练模型:使用在ImageNet上预训练的ResNet18模型
- 模型配置:冻结预训练层参数,替换全连接层以适应二分类任务
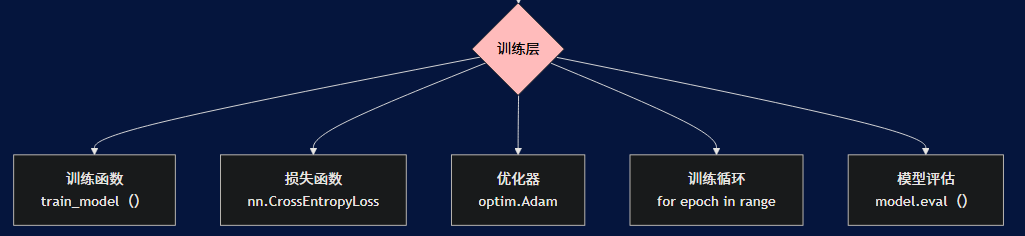
3. 训练层
负责模型的训练过程:
- 训练函数:包含完整的训练和验证循环
- 损失函数:使用交叉熵损失函数进行分类
- 优化器:使用Adam优化器更新模型参数
- 训练循环:控制训练轮数和每个epoch的训练过程
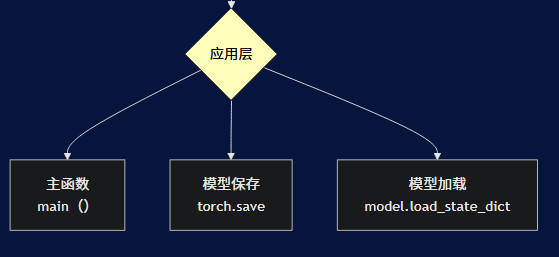
4. 应用层
负责程序的执行和模型管理:
- 主函数:程序入口点,协调各组件工作
- 模型保存:保存验证集上表现最好的模型
- 模型加载:加载最佳模型权重
数据流
- 程序启动后,首先通过数据处理层加载和预处理数据
- 模型层创建并配置预训练模型
- 训练层使用处理好的数据和配置好的模型进行训练
- 训练过程中评估模型性能,并保存最佳模型
- 训练完成后返回最终模型
技术特点
- 迁移学习:使用在ImageNet上预训练的ResNet18模型
- 数据增强:在训练阶段使用随机水平翻转增强数据
- GPU加速:自动检测并使用GPU进行训练(如果可用)
- 模型保存:自动保存验证集上表现最好的模型
效果验证
补充了测试模块,从kaggle官方提供的test测试集中随机抽取十张图片并输出预测结果。
测试效果图:

测试函数代码
def test_random_images(model, test_dir='Data/dogs-vs-cats/test', num_images=10):
"""
从测试文件夹中随机选择图片并使用模型进行预测
参数:
model (nn.Module): 训练好的模型
test_dir (str): 测试图片文件夹路径
num_images (int): 要测试的图片数量
"""
# 设置模型为评估模式
model.eval()
# 获取所有测试图片文件
image_files = [f for f in os.listdir(test_dir) if f.lower().endswith(('.png', '.jpg', '.jpeg'))]
# 随机选择指定数量的图片
selected_files = random.sample(image_files, min(num_images, len(image_files)))
# 获取测试数据转换
data_transforms = create_data_transforms()
test_transform = data_transforms['val']
# 创建图形窗口
fig, axes = plt.subplots(2, 5, figsize=(15, 8))
fig.suptitle('猫狗分类预测结果', fontsize=16)
# 对每张图片进行预测
for i, filename in enumerate(selected_files):
# 计算子图位置
row = i // 5
col = i % 5
ax = axes[row, col]
# 图片完整路径
img_path = os.path.join(test_dir, filename)
# 读取原始图片用于显示
original_img = cv2.imread(img_path)
original_img = cv2.cvtColor(original_img, cv2.COLOR_BGR2RGB)
# 加载并预处理图片用于预测
img = Image.open(img_path).convert('RGB')
input_tensor = test_transform(img)
input_batch = input_tensor.unsqueeze(0) # 添加批次维度
input_batch = input_batch.to(device)
# 进行预测
with torch.no_grad():
output = model(input_batch)
probabilities = torch.nn.functional.softmax(output[0], dim=0)
cat_prob = probabilities[0].item() # 猫的概率
dog_prob = probabilities[1].item() # 狗的概率
# 显示图片
ax.imshow(original_img)
ax.set_title(f'cat: {cat_prob:.2%}\ndog: {dog_prob:.2%}', fontsize=10)
ax.axis('off')
plt.tight_layout()
plt.show()
拓展笔记
ResNet18模型
1.为什么选择ResNet18模型?
1. 解决深度网络训练难题
通过残差连接,ResNet18能够训练非常深的网络而不会出现梯度消失问题,使得模型可以学习到更加复杂的特征。
2. 优秀的特征提取能力和便于迁移学习的优势
ResNet18在ImageNet数据集上进行了预训练,学习到了丰富的图像特征,底层的卷积层已经学会了识别边缘、纹理等基础特征,这些特征对于大多数图像分类任务都非常有用。因此,使用ResNet18模型只需要替换最后的全连接层并进行微调,就能适应猫狗分类任务。
3.计算效率高
相比于更深的ResNet模型(如ResNet50、ResNet101),ResNet18参数量较少,计算效率高,适合在资源有限的环境下使用。
2.ResNet18的特点
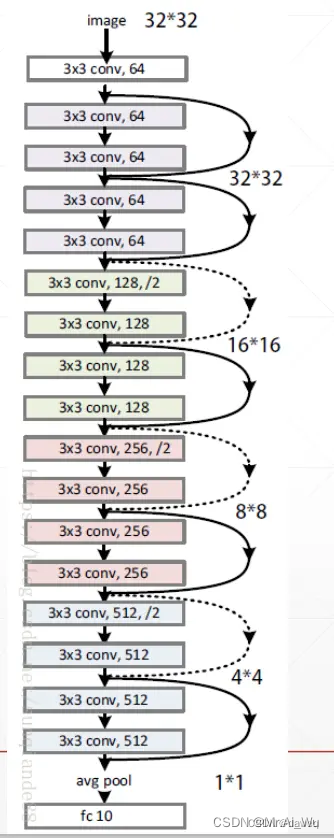
引入了残差块(Residual Block)的概念,解决了深度神经网络训练中的梯度消失和梯度爆炸问题。
传统的深度网络在训练时,随着网络层数加深,梯度在反向传播过程中会逐渐消失或爆炸,导致网络难以训练。ResNet通过引入"跳跃连接"(Shortcut Connection)解决了这个问题:
输出 = F(x) + x
其中F(x)是经过若干层网络层后的输出,x是输入,通过将输入直接加到输出上,形成了残差学习的结构。
下图就是一个ResNet18的基本网络架构
Adam优化算法
Adam(Adaptive Moment Estimation)是一种广泛使用的深度学习优化算法,由 Diederik P. Kingma 和 Jimmy Ba 在 2014 年提出。它结合了动量法(Momentum)和 RMSProp 的思想,旨在通过计算梯度的一阶矩估计和二阶矩估计来调整每个参数的学习率,从而实现更高效的网络训练。
Adam优化器的优点
-
对超参数不敏感:Adam对初始学习率相对不敏感,减少了调参的难度
-
快速收敛:在微调预训练模型时,Adam通常能快速收敛到较好的结果
-
鲁棒性强:对于小数据集和梯度稀疏的情况,Adam表现稳定
-
噪声容忍度高:对梯度中的噪声具有较好的鲁棒性
-
默认参数效果好:即使使用默认的超参数(β1=0.9, β2=0.999, ε=1e-8),通常也能获得不错的结果
-
无需复杂的调参:对于大多数深度学习任务,Adam是很好的默认选择
-
内存效率高:Adam优化器所需的额外内存相对较少,适合在各种硬件环境下使用。
交叉熵损失函数
交叉熵损失函数(Cross-Entropy Loss)是机器学习和深度学习中常用的一种损失函数,特别适用于分类问题。它源自信息论中的交叉熵概念,用于衡量两个概率分布之间的差异。
数学原理
在信息论中,熵是用来衡量一个随机变量不确定性的度量。对于一个离散随机变量X,其概率分布为p(x),则熵定义为:
H(X) = -Σ p(x) log p(x)
交叉熵是衡量真实分布p和预测分布q之间差异的指标:
H(p, q) = -Σ p(x) log q(x)
其中:
-
p(x)是真实标签分布(通常是one-hot编码)
-
q(x)是模型预测的概率分布
为什么选择交叉熵损失函数?
-
数值稳定性:PyTorch的实现考虑了数值稳定性,避免了直接计算softmax可能引起的数值溢出问题
-
计算高效:交叉熵损失函数计算简单,效率高
-
直观解释:
-
损失值越小,表示模型预测越准确
-
当模型完全正确时,损失为0
-
当模型完全错误时,损失趋向无穷大
-
-
适用于多分类:
-
虽然项目是二分类,但交叉熵损失函数同样适用于多分类任务
-
为项目扩展提供了便利
-
与其他损失函数的比较
相比于均方误差(MSE)
-
MSE更适合回归任务,而交叉熵更适合分类任务
-
在分类任务中,MSE可能会导致梯度消失问题,而交叉熵不会
相比于合页损失(Hinge Loss)
-
合页损失主要用于支持向量机
-
交叉熵损失在深度学习中更常用,特别是在神经网络中
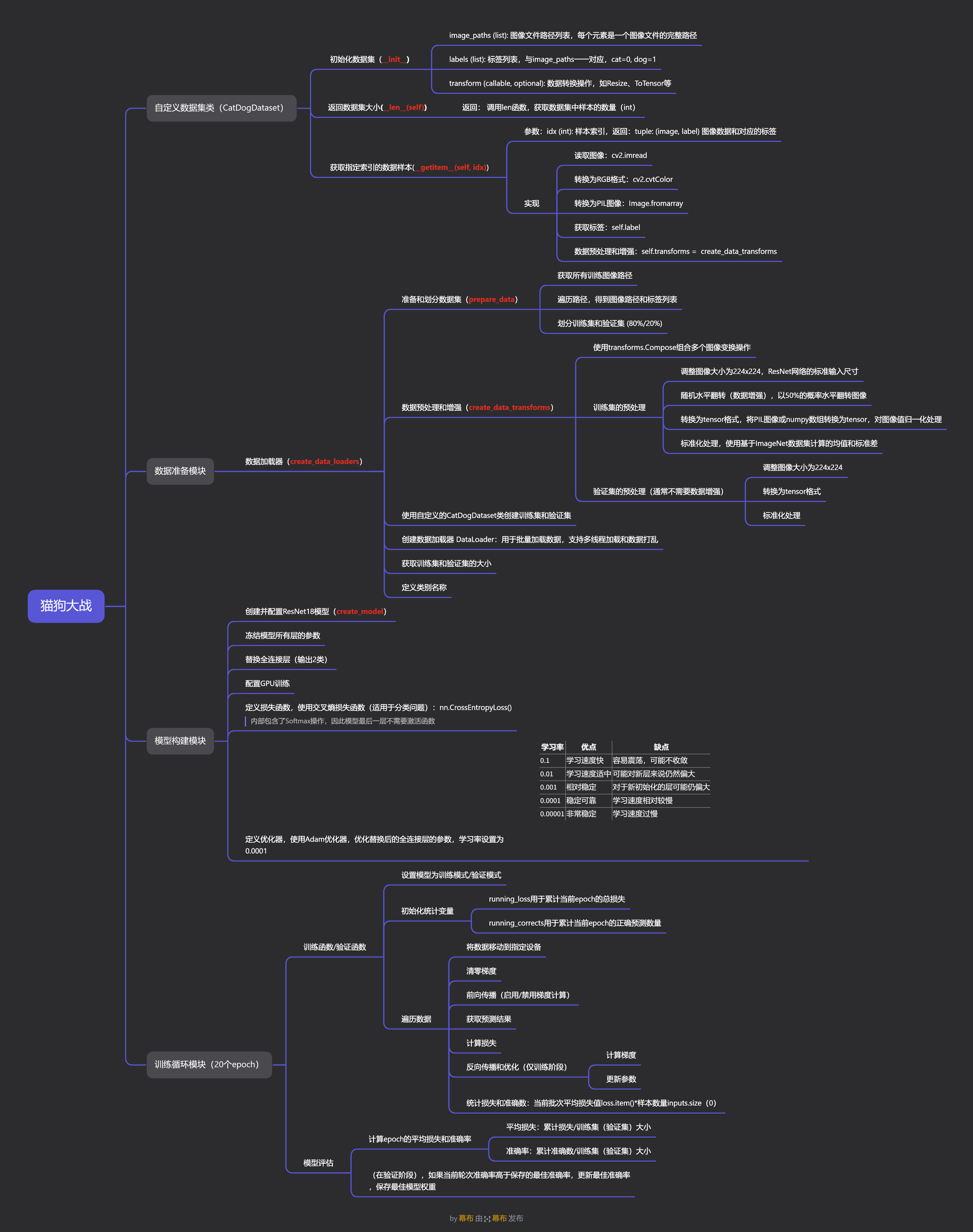
思维导图
项目代码
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
import os
import cv2
from sklearn.model_selection import train_test_split
import numpy as np
from torch.utils.data import Dataset, DataLoader
from PIL import Image
import random
import matplotlib.pyplot as plt
# 检查是否有可用的GPU,如果有则使用GPU,否则使用CPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 自定义数据集类
class CatDogDataset(Dataset):
"""
自定义猫狗数据集类,继承自PyTorch的Dataset基类
用于加载和处理猫狗分类数据集
"""
def __init__(self, image_paths, labels, transform=None):
"""
初始化数据集
参数:
image_paths (list): 图像文件路径列表,每个元素是一个图像文件的完整路径
labels (list): 标签列表,与image_paths一一对应,cat=0, dog=1
transform (callable, optional): 数据转换操作,如Resize、ToTensor等
"""
self.image_paths = image_paths
self.labels = labels
self.transform = transform
def __len__(self):
"""
返回数据集大小,即数据集中样本的总数
返回:
int: 数据集中样本的数量
"""
return len(self.image_paths)
def __getitem__(self, idx):
"""
获取指定索引的数据样本
参数:
idx (int): 样本索引
返回:
tuple: (image, label) 图像数据和对应的标签
"""
# 读取图像,cv2.imread读取BGR格式图像
image = cv2.imread(self.image_paths[idx])
# 转换为RGB格式,因为cv2读取的是BGR格式
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 转换为PIL图像,便于使用torchvision的transforms
image = Image.fromarray(image)
# 获取标签
label = self.labels[idx]
# 应用转换:数据预处理和增强
if self.transform:
image = self.transform(image)
return image, label
# 划分训练集/验证集(80%/20%)
def prepare_data(data_dir='Data/dogs-vs-cats'):
"""
准备训练和验证数据,将数据集划分为训练集和验证集
参数:
data_dir (str): 数据目录路径,包含训练数据的文件夹
返回:
tuple: (train_paths, val_paths, train_labels, val_labels)
训练和验证数据的路径和标签列表
"""
# 获取所有训练图像路径
train_dir = os.path.join(data_dir, 'train')
image_files = os.listdir(train_dir)
# 创建图像路径和标签列表
image_paths = []
labels = []
for file in image_files:
image_paths.append(os.path.join(train_dir, file))
# 根据文件名确定标签(cat=0, dog=1)
if file.startswith('cat'):
labels.append(0)
else: # dog
labels.append(1)
# 划分训练集和验证集 (80%/20%)
# test_size=0.2 表示20%作为验证集,80%作为训练集
# random_state=42 确保每次运行得到相同的结果,便于复现
# stratify=labels 保持训练集和验证集中各类别样本的比例一致
train_paths, val_paths, train_labels, val_labels = train_test_split(
image_paths, labels, test_size=0.2, random_state=42, stratify=labels
)
return train_paths, val_paths, train_labels, val_labels
def create_data_transforms():
"""
创建数据预处理和增强的转换操作
返回:
dict: 包含训练和验证数据转换操作的字典
"""
# transforms.Compose用于组合多个图像变换操作
data_transforms = {
# 训练集的预处理
'train': transforms.Compose([
# 调整图像大小为224x224,ResNet网络的标准输入尺寸
transforms.Resize((224, 224)),
# 随机水平翻转(数据增强),以50%的概率水平翻转图像
transforms.RandomHorizontalFlip(),
# 转换为tensor格式,将PIL图像或numpy数组转换为tensor,并将像素值从[0,255]缩放到[0,1]
transforms.ToTensor(),
# 标准化处理,均值和标准差都是基于ImageNet数据集计算的
# 项目使用的ResNet18模型是在ImageNet数据集上预训练的
# 为了保持一致性并充分利用预训练模型的特征提取能力,需要使用相同的标准化参数
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
# 验证集的预处理(通常不需要数据增强)
'val': transforms.Compose([
# 调整图像大小为224x224
transforms.Resize((224, 224)),
# 转换为tensor格式
transforms.ToTensor(),
# 标准化处理
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
return data_transforms
def create_data_loaders():
"""
创建训练和验证数据加载器
返回:
tuple: (dataloaders, dataset_sizes, class_names) 数据加载器、数据集大小和类别名称
"""
# 准备数据
train_paths, val_paths, train_labels, val_labels = prepare_data()
# 创建数据预处理转换
data_transforms = create_data_transforms()
# 创建数据集
# 使用自定义的CatDogDataset类创建训练集和验证集
train_dataset = CatDogDataset(train_paths, train_labels, transform=data_transforms['train'])
val_dataset = CatDogDataset(val_paths, val_labels, transform=data_transforms['val'])
# 创建数据加载器
# DataLoader用于批量加载数据,支持多线程加载和数据打乱
dataloaders = {
# 训练集数据加载器,batch_size=32表示每批处理32张图片
# shuffle=True表示每个epoch打乱数据顺序,有助于提高模型泛化能力
# num_workers=0表示不使用额外的子进程加载数据(Windows兼容)
'train': DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=0),
# 验证集数据加载器,通常不需要打乱数据,保持数据顺序
'val': DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=0)
}
# 获取训练集和验证集的大小
dataset_sizes = {
'train': len(train_dataset),
'val': len(val_dataset)
}
# 类别名称
class_names = ['cat', 'dog']
print(f"类别: {class_names}")
print(f"训练集大小: {dataset_sizes['train']}")
print(f"验证集大小: {dataset_sizes['val']}")
return dataloaders, dataset_sizes, class_names
def create_model():
"""
创建并配置模型
返回:
tuple: (model, criterion, optimizer) 模型、损失函数和优化器
"""
# 加载经过预训练ResNet18模型
# 使用torchvision.models加载预训练的ResNet18模型
# pretrained=True表示加载在ImageNet上预训练的权重
model = torchvision.models.resnet18(pretrained=True)
# 冻结模型所有层的参数
# 遍历模型的所有参数,并将其requires_grad属性设置为False,这样在训练过程中不会更新这些参数
# 这是迁移学习的典型做法,保留预训练模型的特征提取能力
for param in model.parameters():
param.requires_grad = False
# 替换全连接层(输出2类)
# 获取全连接层的输入特征数,ResNet18的fc层输入维度是512
num_ftrs = model.fc.in_features
# 替换全连接层,使其输出2类(猫和狗)
# 新的线性层默认requires_grad=True,即会训练这些参数
model.fc = nn.Linear(num_ftrs, 2)
# 配置GPU训练
# 将模型移动到指定设备(GPU或CPU)
model = model.to(device)
# 编写训练循环(损失函数:CrossEntropyLoss,优化器:Adam)
# 定义损失函数,使用交叉熵损失函数(适用于分类问题)
# CrossEntropyLoss内部包含了Softmax操作,因此模型最后一层不需要激活函数
criterion = nn.CrossEntropyLoss()
# 定义优化器,使用Adam优化器,优化替换后的全连接层的参数(因为前面的层已经被冻结)
# 只优化model.fc.parameters(),即只训练新添加的全连接层参数
optimizer = optim.Adam(model.fc.parameters(), lr=0.0001) # 调整学习率(建议0.0001)
return model, criterion, optimizer
# 训练函数
def train_model(model, criterion, optimizer, dataloaders, dataset_sizes, num_epochs=20):
"""
训练模型的主要函数,包含完整的训练和验证过程
参数:
model (nn.Module): 要训练的模型
criterion (nn.Module): 损失函数
optimizer (optim.Optimizer): 优化器
dataloaders (dict): 数据加载器字典,包含训练和验证加载器
dataset_sizes (dict): 数据集大小字典
num_epochs (int): 训练轮数,默认为20轮
返回:
nn.Module: 训练好的模型
"""
# 记录最佳模型权重和最佳准确率
# best_model_wts用于保存验证集上表现最好的模型权重
best_model_wts = model.state_dict()
best_acc = 0.0
# 开始训练循环(20个epoch)
for epoch in range(num_epochs):
print(f'Epoch {epoch+1}/{num_epochs}')
print('-' * 10)
# 每个epoch都有训练和验证阶段
for phase in ['train', 'val']:
if phase == 'train':
# 设置模型为训练模式,启用Batch Normalization和Dropout
model.train()
else:
# 设置模型为评估模式,禁用Batch Normalization和Dropout
model.eval()
# 初始化统计变量
# running_loss用于累计当前epoch的总损失
running_loss = 0.0
# running_corrects用于累计当前epoch的正确预测数量
running_corrects = 0
# 遍历数据
# dataloaders[phase]根据phase选择训练集或验证集的数据加载器
for inputs, labels in dataloaders[phase]:
# 将数据移动到指定设备(GPU或CPU)
inputs = inputs.to(device)
labels = labels.to(device)
# 清零梯度
# 每次迭代前清空优化器中累积的梯度
optimizer.zero_grad()
# 前向传播
# 在验证阶段,梯度计算在 with 语句中被临时禁用,执行完代码块后会自动恢复为原来的状态(默认是启用状态)。
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
# 获取预测结果
# dim = 1 表示逐行取最大值所在的索引(0代表猫,1代表狗)
_, preds = torch.max(outputs, 1)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播和优化(仅在训练阶段)
if phase == 'train':
# 计算梯度
loss.backward()
# 更新参数
optimizer.step()
# 统计损失和准确数量
# loss.item()获取损失的标量值
# inputs.size(0)获取当前批次的样本数量
# 乘以样本数量得到该批次的总损失,而不是平均损失
running_loss += loss.item() * inputs.size(0)
# 计算当前批次正确预测的数量
running_corrects += torch.sum(preds == labels.data)
# 计算epoch的平均损失和准确率
# dataset_sizes[phase]是当前阶段(训练或验证)的数据集大小
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f}')
# 深拷贝模型(在验证集上表现最好的模型)
# 只在验证阶段更新最佳模型
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
# 保存当前最佳模型的权重
best_model_wts = model.state_dict()
# 保存最佳模型权重
torch.save(model.state_dict(), 'best_model.pth')
print()
# 打印训练结果
print(f'最佳验证集准确率: {best_acc:.4f}')
# 加载最佳模型权重
model.load_state_dict(best_model_wts)
return model
# ... existing code ...
def test_random_images(model, test_dir='Data/dogs-vs-cats/test', num_images=10):
"""
从测试文件夹中随机选择图片并使用模型进行预测
参数:
model (nn.Module): 训练好的模型
test_dir (str): 测试图片文件夹路径
num_images (int): 要测试的图片数量
"""
# 设置模型为评估模式
model.eval()
# 获取所有测试图片文件
image_files = [f for f in os.listdir(test_dir) if f.lower().endswith(('.png', '.jpg', '.jpeg'))]
# 随机选择指定数量的图片
selected_files = random.sample(image_files, min(num_images, len(image_files)))
# 获取测试数据转换
data_transforms = create_data_transforms()
test_transform = data_transforms['val']
# 创建图形窗口
fig, axes = plt.subplots(2, 5, figsize=(15, 8))
fig.suptitle('猫狗分类预测结果', fontsize=16)
# 对每张图片进行预测
for i, filename in enumerate(selected_files):
# 计算子图位置
row = i // 5
col = i % 5
ax = axes[row, col]
# 图片完整路径
img_path = os.path.join(test_dir, filename)
# 读取原始图片用于显示
original_img = cv2.imread(img_path)
original_img = cv2.cvtColor(original_img, cv2.COLOR_BGR2RGB)
# 加载并预处理图片用于预测
img = Image.open(img_path).convert('RGB')
input_tensor = test_transform(img)
input_batch = input_tensor.unsqueeze(0) # 添加批次维度
input_batch = input_batch.to(device)
# 进行预测
with torch.no_grad():
output = model(input_batch)
probabilities = torch.nn.functional.softmax(output[0], dim=0)
cat_prob = probabilities[0].item() # 猫的概率
dog_prob = probabilities[1].item() # 狗的概率
# 显示图片
ax.imshow(original_img)
ax.set_title(f'cat: {cat_prob:.2%}\ndog: {dog_prob:.2%}', fontsize=10)
ax.axis('off')
plt.tight_layout()
plt.show()
def main():
"""
主函数,程序入口点
"""
# 创建数据加载器
dataloaders, dataset_sizes, class_names = create_data_loaders()
# 创建模型、损失函数和优化器
model, criterion, optimizer = create_model()
# 完整训练ResNet模型(20个epoch)
# 开始训练模型
model = train_model(model, criterion, optimizer, dataloaders, dataset_sizes, num_epochs=20)
print("训练完成!")
return model
def main_with_test():
"""
主函数,包括测试功能
"""
# 创建模型
model, _, _ = create_model()
# 加载训练好的模型权重
model.load_state_dict(torch.load('best_model.pth'))
print("已加载训练好的模型权重")
# 对随机图片进行测试
print("开始测试随机图片...")
test_random_images(model)
print("测试完成!")
if __name__ == "__main__":
# 程序入口点 - 可以选择是否进行训练
import sys
if len(sys.argv) > 1 and sys.argv[1] == 'test':
# 只进行测试
main_with_test()
else:
# 进行训练
model = main()

















 1039
1039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









