










导言
在听完一些专业讲座和较难的课程后,我们经常会后悔在听课时错过了很多重要的细节;或者在进行一些市场调查后,我们希望能快速将收集到的采访录音转换为文字,这时如果有一种轻松实现语音转文字的方法,会大大减少我们的工作量。
Whisper是OpenAI在2022年9月开源的音频转文本的模型,它的转写精确度非常高。Whisper的好处是开源免费、支持多语种(包括中文),有不同模型可供选择,最终的效果比市面上很多音频转文字的效果都要好。
那么,就让我们进入今天的正题----该怎么使用whisper实现音频转换成文字。
whisper简介
在使用之前,我们先了解一下whisper。Whisper是一个通用的语音识别模型。它是在不同音频的大型数据集上训练的,也是一个多任务模型,可以执行多语言语音识别、语音翻译和语言识别。
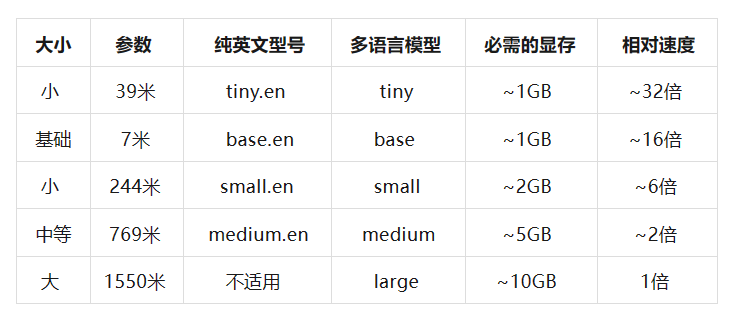
Whisper目前有5个模型,随着参数的变多,转文字的理解性和准确性会提高,但相应速度会变慢:
准备工作--系统环境
Whisper的安装不是简简单单一句命令pip install whisper就完事,它需要一些准备工作。比如ffmpeg、pytorch等。另外,Python的版本建议3.8或3.9。
1、下载ffmpeg并添加环境变量
登陆网址https://github.com/BtbN/FFmpeg-builds/releases下载后,将ffmpeg.exe所在文件夹路径在系统环境变量设置中添加到变量Path中。
2、下载git并添加环境变量
登陆网址registry.npmmirror.com/binary.html,下载git-for-windows,选择最新版本,安装完毕后,在cmd中输入git检查是否加入到系统环境。
3、安装pytorch
登录pytorch.org,选择版本后下载安装(在cmd中操作)。
whisper的安装以上步骤都完成后。按照官方文档,先运行
pip install git+https://github.com/openai/whisper.git然后再运行
pip install --upgrade --no-deps --force-reinstall git+https://github.com/openai/whisper.git完成whisper的安装。
whisper 是一个由 OpenAI 开发的开源库,用于将音频转换为文字(语音识别)。虽然 whisper 格外引人注目,但需要注意的是,它并非 Python 标准库的一部分,因此你需要通过特定的步骤来安装和使用它。
使用 Whisper 将音频转换为文字
以下是一个简单的示例代码,展示如何使用 Whisper 将音频文件转换为文字:
import whisper
import torch
# 加载 Whisper 模型
model_path = 'path/to/your/whisper-model.pt' # 替换为你下载的模型文件路径
model = whisper.load_model(model_path)
# 加载音频文件
audio_path = 'path/to/your/audio-file.wav' # 替换为你的音频文件路径
# 使用 Whisper 模型进行语音识别
results = whisper.transcribe(model, audio_path)
# 打印结果
for result in results:
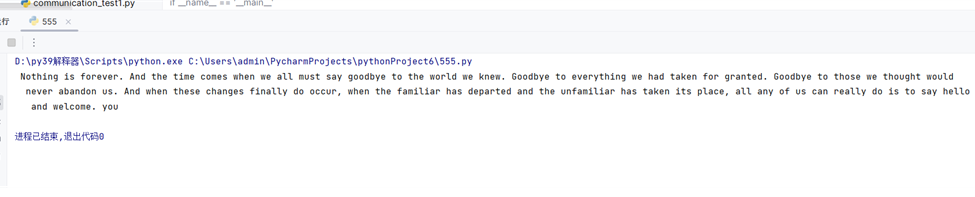
print(result['transcript'])运行结果
以上就是本文对whisper的介绍,希望能帮助大家在工作和学习中更好地利用python来进行音频文字的转换。
全套Python学习资料分享:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
三、python入门资料大全

四、python进阶资料大全

五、python爬虫专栏
六、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
七、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
八、python最新面试题
获取资料:保存二维码,微信扫下方官方二维码即可领取


















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









