






YOLOv10 通过消除非最大抑制和优化模型架构来提高实时物体识别率,从而以更低的延迟和计算开销实现最先进的性能。


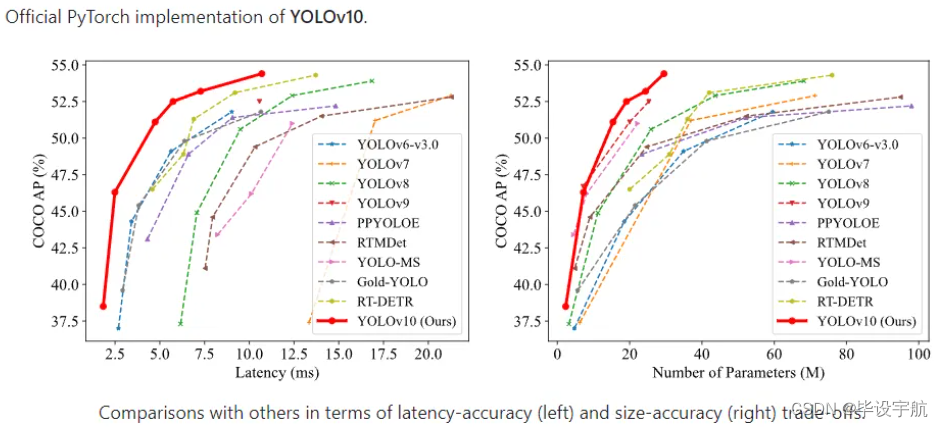
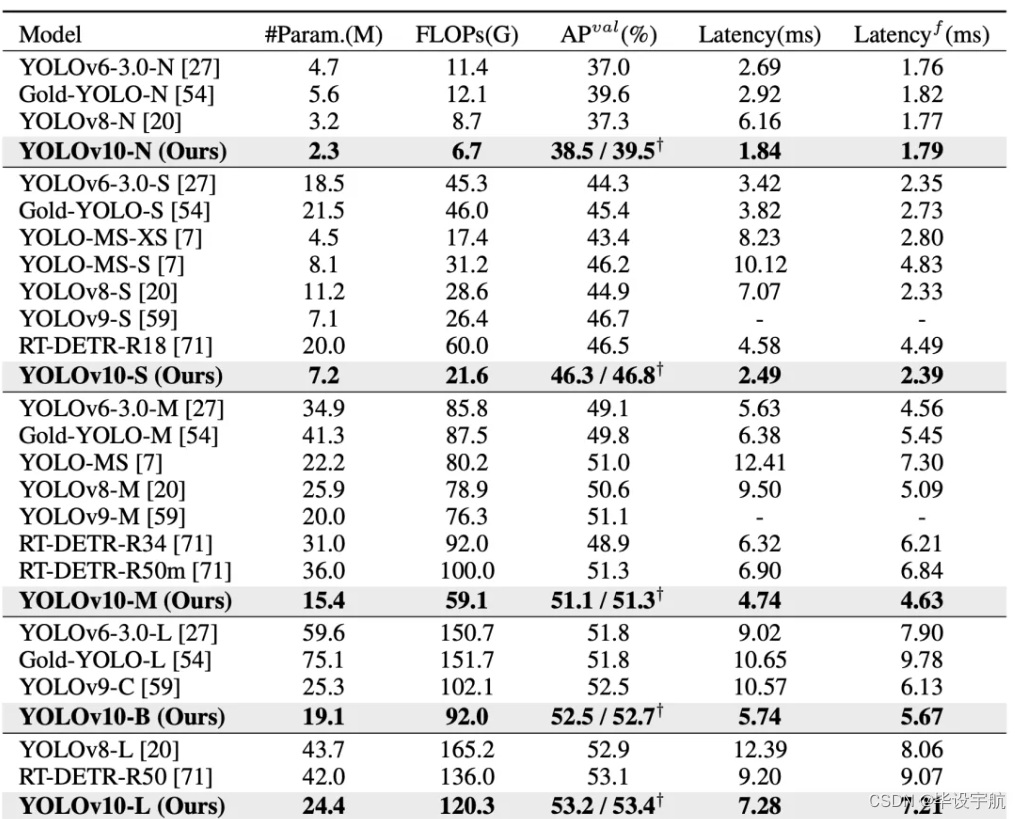
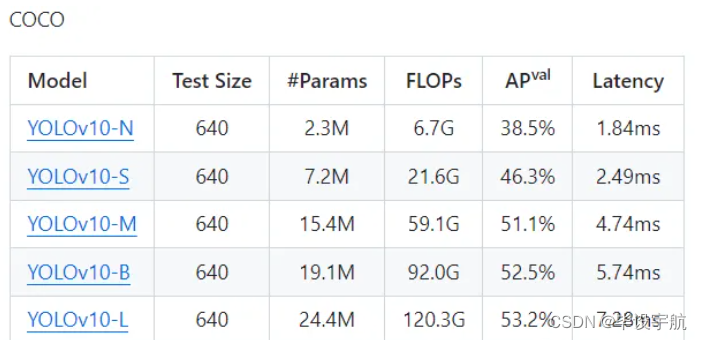
在过去的几年中,YOLO 因其在计算成本和检测性能之间的有效平衡而成为实时物体检测领域的主导范式。研究人员已经探索了 YOLO 的架构设计、优化目标、数据增强策略等,取得了显著进展。然而,对非最大抑制 (NMS) 进行后处理的依赖阻碍了 YOLO 的端到端部署,并对推理延迟产生不利影响。此外,YOLO 中各个组件的设计缺乏全面彻底的检查,导致明显的计算冗余并限制了模型的能力。它导致效率不理想,同时具有相当大的性能改进潜力。在这项工作中,我们旨在从后处理和模型架构两个方面进一步推进 YOLO 的性能效率边界。为此,我们首先提出了用于 YOLO 无 NMS 训练的一致对偶分配,这同时带来了具有竞争力的性能和较低的推理延迟。此外,我们引入了整体效率-准确度驱动的 YOLO 模型设计策略。我们从效率和准确度的角度全面优化了 YOLO 的各个组件,大大降低了计算开销并提高了性能。我们的努力成果是新一代用于实时端到端物体检测的 YOLO 系列,称为 YOLOv10。大量实验表明,YOLOv10 在各种模型规模上都实现了最先进的性能和效率。例如,我们的 YOLOv10-S 为 1.8×在 COCO 上相似的 AP 下比 RT-DETR-R18 更快,同时享受 2.8×参数和 FLOP 数量更少。与 YOLOv9-C 相比,在相同性能下,YOLOv10-B 的延迟减少了 46%,参数减少了 25%。

测试代码:
【1】安装:
pip install supervision 【2】预测:
from ultralytics import YOLOv10
import supervision as sv
import cv2
MODEL_PATH = 'yolov10n.pt'
IMAGE_PATH = 'dog.jpeg'
model = YOLOv10(MODEL_PATH)
image = cv2.imread(IMAGE_PATH)
results = model(source=image, conf=0.25, verbose=False)[0]
detections = sv.Detections.from_ultralytics(results)
box_annotator = sv.BoxAnnotator()
category_dict = {
0: 'person', 1: 'bicycle', 2: 'car', 3: 'motorcycle', 4: 'airplane', 5: 'bus',
6: 'train', 7: 'truck', 8: 'boat', 9: 'traffic light', 10: 'fire hydrant',
11: 'stop sign', 12: 'parking meter', 13: 'bench', 14: 'bird', 15: 'cat',
16: 'dog', 17: 'horse', 18: 'sheep', 19: 'cow', 20: 'elephant', 21: 'bear',
22: 'zebra', 23: 'giraffe', 24: 'backpack', 25: 'umbrella', 26: 'handbag',
27: 'tie', 28: 'suitcase', 29: 'frisbee', 30: 'skis', 31: 'snowboard',
32: 'sports ball', 33: 'kite', 34: 'baseball bat', 35: 'baseball glove',
36: 'skateboard', 37: 'surfboard', 38: 'tennis racket', 39: 'bottle',
40: 'wine glass', 41: 'cup', 42: 'fork', 43: 'knife', 44: 'spoon', 45: 'bowl',
46: 'banana', 47: 'apple', 48: 'sandwich', 49: 'orange', 50: 'broccoli',
51: 'carrot', 52: 'hot dog', 53: 'pizza', 54: 'donut', 55: 'cake',
56: 'chair', 57: 'couch', 58: 'potted plant', 59: 'bed', 60: 'dining table',
61: 'toilet', 62: 'tv', 63: 'laptop', 64: 'mouse', 65: 'remote', 66: 'keyboard',
67: 'cell phone', 68: 'microwave', 69: 'oven', 70: 'toaster', 71: 'sink',
72: 'refrigerator', 73: 'book', 74: 'clock', 75: 'vase', 76: 'scissors',
77: 'teddy bear', 78: 'hair drier', 79: 'toothbrush'
}
labels = [
f"{category_dict[class_id]} {confidence:.2f}"
for class_id, confidence in zip(detections.class_id, detections.confidence)
]
annotated_image = box_annotator.annotate(
image.copy(), detections=detections, labels=labels
)
cv2.imwrite('annotated_dog.jpeg', annotated_image)在线Demo(curated by @kadirnar):
https://huggingface.co/spaces/kadirnar/Yolov10















 303
303

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









