







节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对大模型& AIGC 技术趋势、大模型& AIGC 落地项目经验分享、新手如何入门算法岗、该如何准备面试攻略、面试常考点等热门话题进行了深入的讨论。
总结链接如下:
喜欢记得点赞、收藏、关注。更多技术交流&面经学习,可以文末加入我们。
一、背景
本文中我们介绍新的视频多模态模型 MiniGPT4-Video,它是专门针对视频理解而设计的大型多模态模型(LMM)。MiniGPT4-Video 基于 MiniGPT-v2(主要针对图文多模态)升级而来,并扩展到支持处理视频帧。该模型能够同时处理时序视频帧和文本数据,使其能够更有效地回答涉及视觉和文本相关的问题。提出的模型优于现有的方法,在 MSVD、MSRVTT、TGIF 和 TVQA 基准上分别获得 4.22%、1.13%、20.82%和 13.1% 的提升。
对应的论文为:[2404.03413] MiniGPT4-Video: Advancing Multimodal LLMs for Video Understanding with Interleaved Visual-Textual Tokens
对应的代码库为:https://github.com/Vision-CAIR/MiniGPT4-video/tree/main
需要说明的是:MiniGPT4-Video 中视觉 Token 比较多,由于 LLM 最大序列长度的限制,导致其无法很好的支持比较长的视频。比如当前 2s 对应 1 帧,90 帧对应 3 分钟左右,这已经是相应的上限。另一方面,当前的这几个视频多模态模型都采用了比较小的图像分辨率,可能影响其细粒度理解能力,比如对视频中的场景文本的理解。
二、引言
2.1. Video-LLaVA
在 [2311.10122] Video-LLaVA: Learning United Visual Representation by Alignment Before Projection 中,作者对 LLaVA 模型进行了扩展,使其能支持视频输入。方案也很简单:
-
直接把视频看成多帧图片,每帧都提取视觉 Token,然后拼接到一起作为视觉输入,然后接文本指令。
-
对应的视频帧分辨率为 224x224,每个帧提取 256 个视觉 Token,每个视频使用 8 帧,总的视觉 Token 为 2048。
-
其中的视觉投影层为两层 MLP。

Video-LLaVA 的训练分为两阶段:
-
Stage 1:预训练,对齐投影层
-
Stage 2:指令微调

2.2. LLaMA-VID
在 [2311.17043] LLaMA-VID: An Image is Worth 2 Tokens in Large Language Models 中,作者针对长视频处理提出了 LLaMA-VID。LLaMA-VID 和之前的 LMM 差不多:采用 Visual Encoder来产生视觉 Token,采用 Text Decoder 来产生文本引导 Token,之后将文本 Token 和视觉 Token 交叉融合生成上下文 Token,而视觉 Token 经转换、投影生成内容 Token,最后将两种 Token 和文本 Token 一起输入 LLM 用于答案生成。
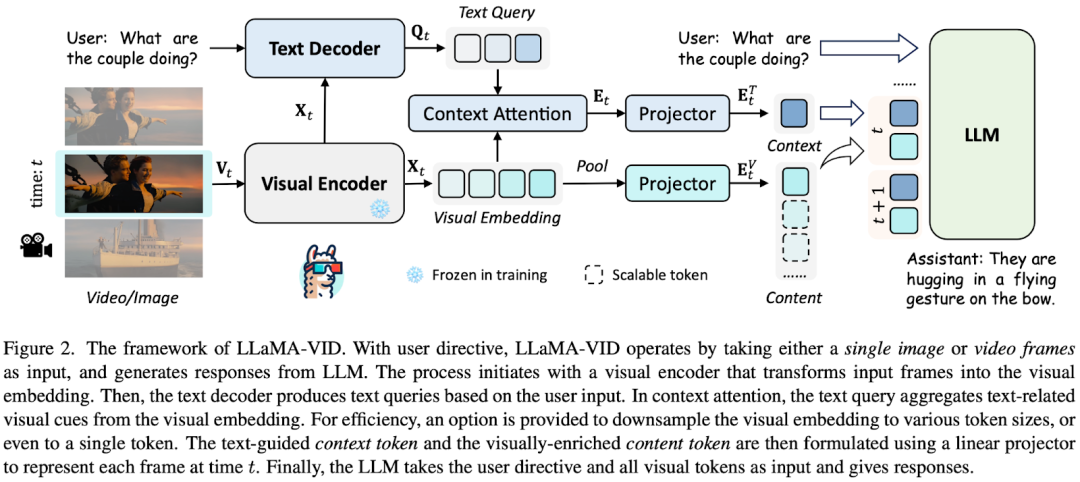
对于视觉 Token,作者添加了一个自适应 Pooling 策略来压缩 Token 数,具体来说:
-
对于单图片场景:Visual Encoder 生成 16 x 16 个 Token,使用 grid 超参数控制缩放,比如 grid 为 4,则意味着缩放后包含 (16/4)x (16/4)= 16 个 Token。
-
对于视频场景:Visual Encoder 生成 16 x 16 个 Token,直接将其压缩到 1 个 Token,大幅降低 Token 数,这也就是为什么 LLaMA-VID 能支持长视频。
如下图 Figure 3 所示,整个训练过程分为三个阶段:
-
Stage 1:模态对齐,此阶段主要优化 Figure 2 中的上下文注意力层和投影层,也就是冻结所有预训练模块,比如文本 Decoder,视觉 Encoder 和 LLM。
-
Stage 2:指令微调,使模型获得指令遵循能力。
-
Stage 3:长视频微调,使模型更好的支持长达 1 小时的视频。

2.3. MiniGPT-v2
在 [2310.09478] MiniGPT-v2: large language model as a unified interface for vision-language multi-task learning 中作者提出了 MiniGPT-v2,结构如下图 Figure 2 所示,与 LLaVA 的主要不同是其的视觉投影层会将 4 个相邻的视觉 Token 压缩为 1 个。
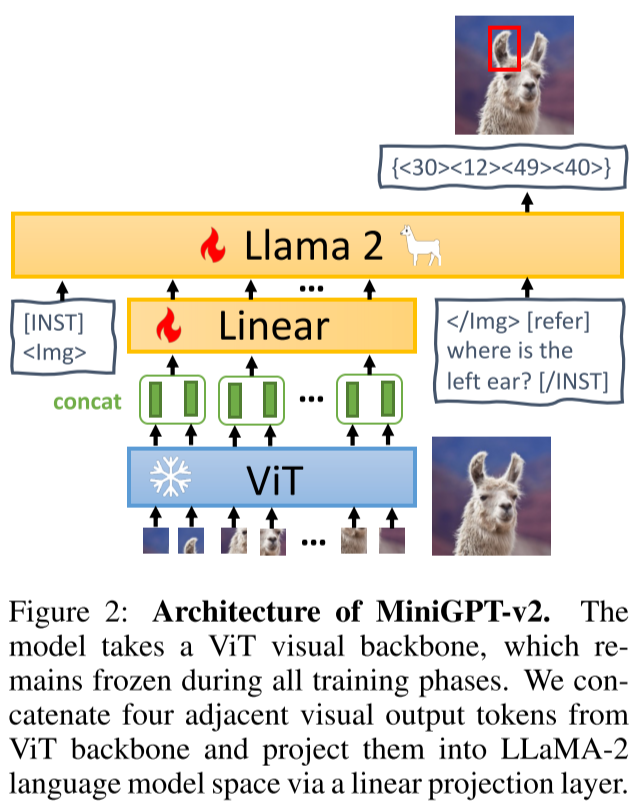
三、本文方法
3.1. 概述
如下图 Figure 2 所示,本文方法的思路也很简单,也是将视频分割为不同的视频帧分别处理:
-
每个视频帧都是用 Vision Encoder 提取视觉 Token,不过会采用 MiniGPT-v2 的方案,每 4 个 视觉 Token 会压缩为 1 个 Token。
-
视频帧的分辨率为 224x224,采用 EVA-CLIP 作为 Vision Encoder,输出 256 个 Token,压缩后为 64 个 Token。
-
相比之前的 Video-LLaVA 和 LLaMA-VID 的最大不同为:MiniGPT4-Video 中会为每个视频帧增加一个 subtitle 的文本,并生成文本 Token。
-
每个视频帧的 Token 最终都包含视觉 Token + 文本 Token,之后再与文本指令 Token 一起输入 LLM(当然,对于没有 Subtitle 的场景,比如视频中没有音频的情况,也可以不用 Subtitle)。
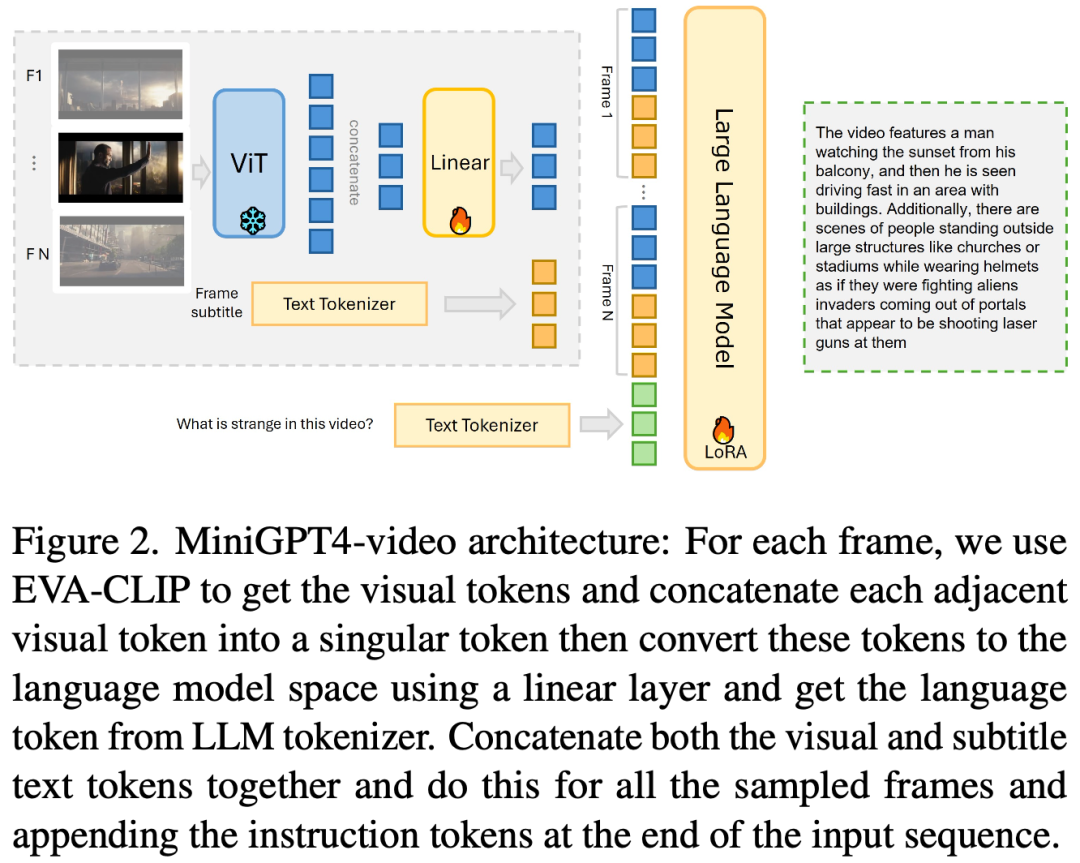
对应的 Token 排列模板如下图所示:

由于每帧视频有 64 个视觉 Token,也就意味着对于常规的 LLM 无法支持非常多的帧,比如:
-
对于 LLaMA-2,对应的最大序列长度为 4096,因此作者选择支持 45 帧,总共 2880 个视觉 Token,此外为 Subtitle 分配了 1000 个 Token,因此为响应留下的 Token 空间就很小,只有 200 左右。
-
对于 Mistral-7B,对应的最大序列长度为 8192,因此作者将相应的帧数扩大了一倍,支持 90 帧,其他 Token 也都同样扩大一倍。
3.2. Subtitle
事实上当前数据集中并没有针对每个视频帧提供 Subtitle,作者是采用 OpenAI 的 Whisper 模型将视频中的音频数据转换为文本,如下所示:
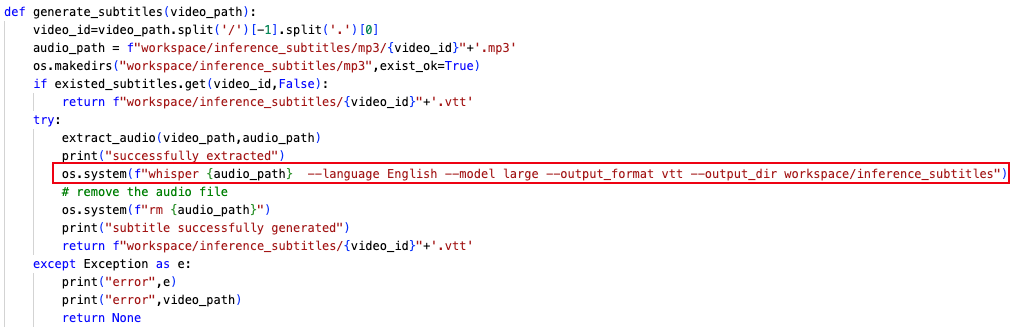
因为每个视频都是 2s 提取 1 个视频帧,因此需要将提取的文本再按照视频帧数进行切分,每 2s 对应一个 Subtitle,如下所示:
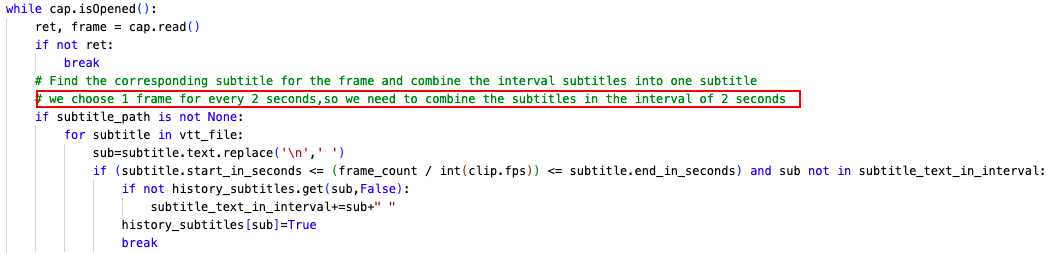
3.3. 训练
整个模型训练也是分为 3 个阶段:
-
Stage 1:大规模图像-文本对预训练,作者使用了 LAION、Conceptual Captions 和 SBU 数据集。
-
Stage 2:大规模视频-文本对预训练,作者使用了 CMD(Condensed Movies Video Cap- tions Dataset,15938 个视频,平均每个描述 14 个单词) 和 WebVid 数据集。
-
Stage 3:视频问答指令微调,主要使用 Video-ChatGPT 数据集(13224 个视频,大约 100,000 个问答对)。
训练过程中 Vision Encoder 使用 EVA-CLIP,并且始终保持冻结。而微调 LLM 时会采用 LoRA 微调方案,其中 Wq 和 Wv 对应的 Rank 都为 64,LoRA-alpha 值为 16。
四、评估
4.1. 定量评估
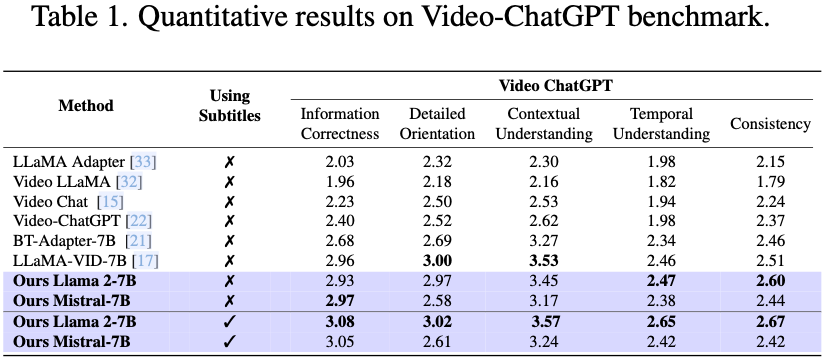
基于 Video ChatGPT 的评估结果如下图 Table 1 所示,可以看出,在不使用 Subtitle 的时候,本文的模型(包括 LLaMA-2 版本和 Mistral 版本)性能和 LLaVA-VID 相当,而使用 Subtitle 后,各项指标有一些比较明显的提升:
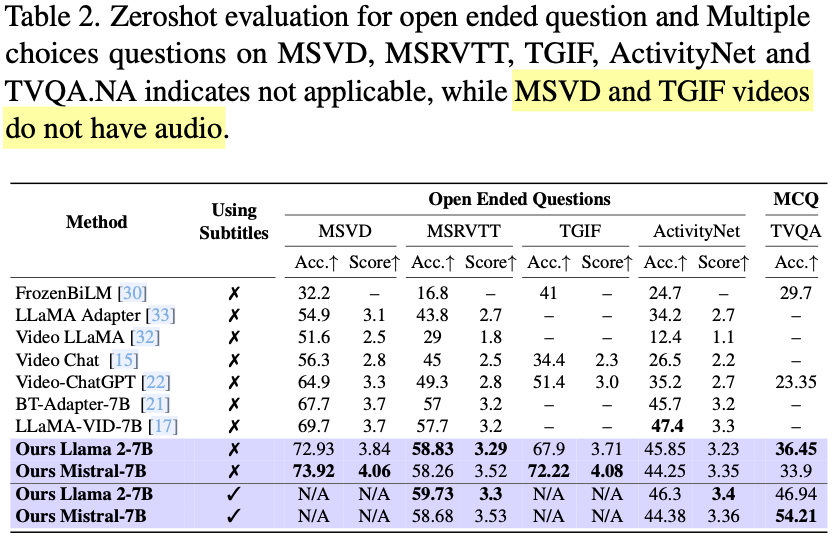
作者进一步在 Open-Ended 问答评估集上进行了评估,如下图 Table 2 所示,MSVD 和 TGIF 的视频没有音频数据,所以没有 Subtitle,可以看出,本文的模型在 MSVD、MSRVTT、TGIF 和 TVQA 基准上分别获得 4.22%、1.13%、20.82%和 13.1% 的提升。
4.2. 定性评估
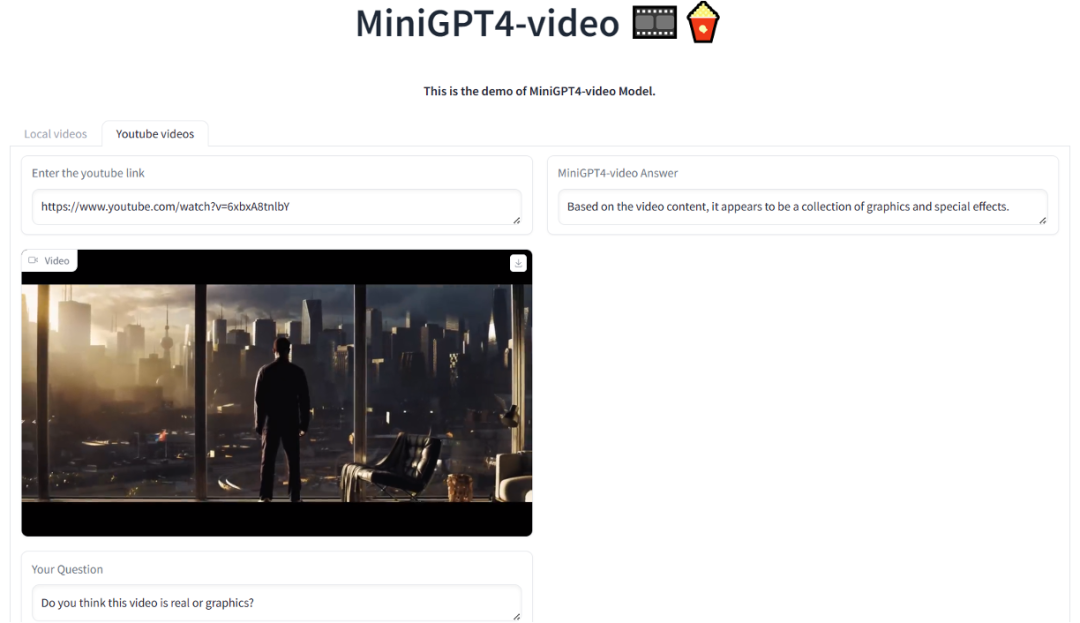
如下图所示,MiniGPT4-Video 可以识别视频是否是通过渲染生成的,视频内容滑稽的地方,以及根据视频生成广告语等:
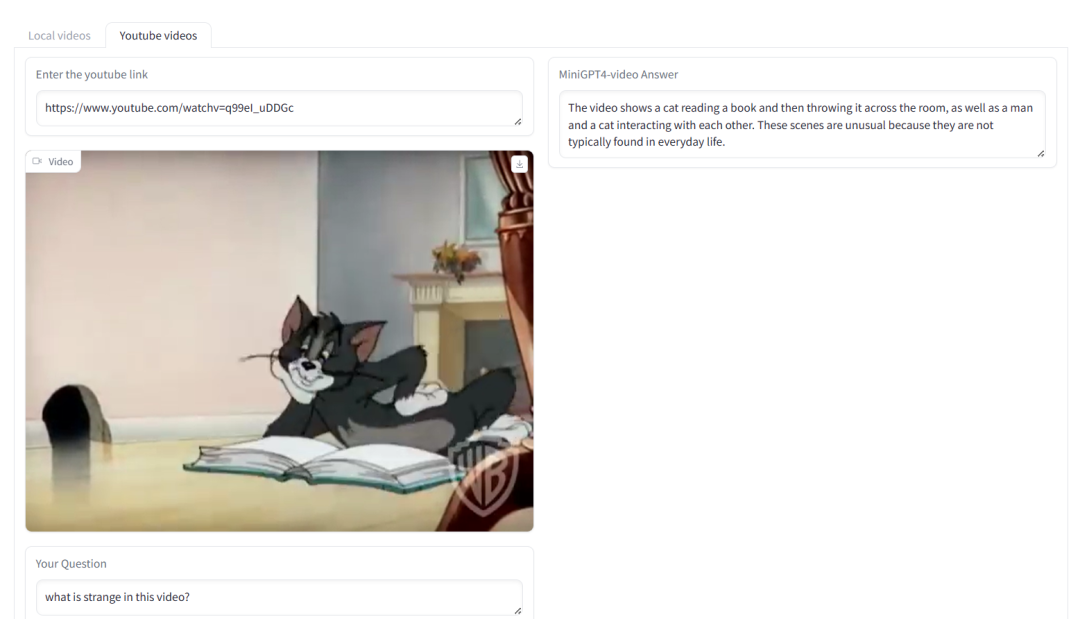
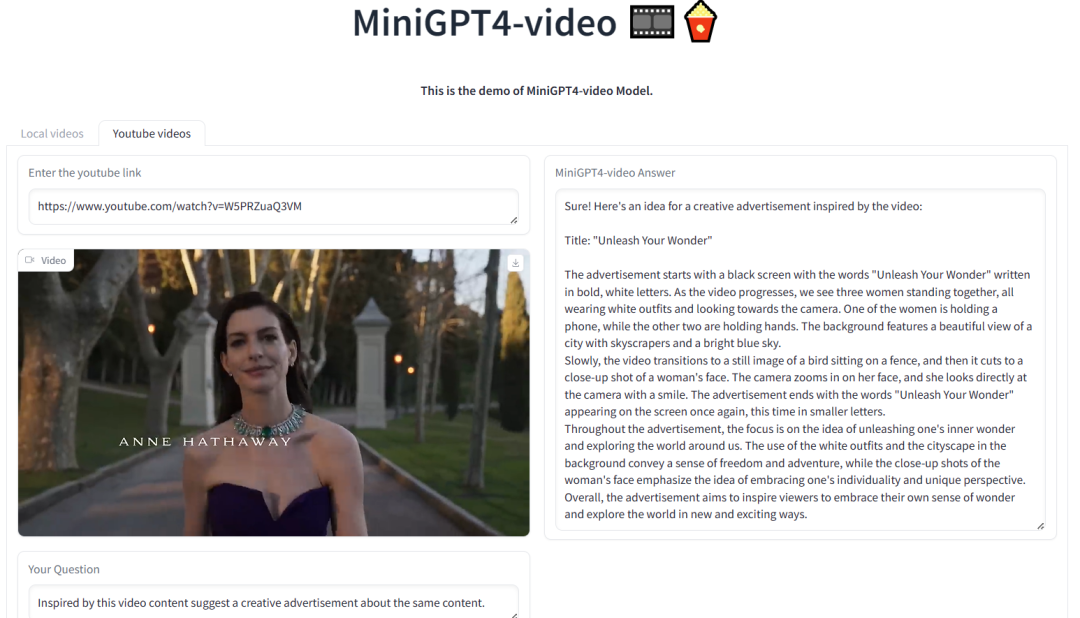
五、参考链接
-
https://arxiv.org/abs/2404.03413
-
https://github.com/Vision-CAIR/MiniGPT4-video/tree/main
-
https://arxiv.org/abs/2311.10122
-
https://arxiv.org/abs/2311.17043
-
https://arxiv.org/abs/2310.09478


















 483
483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









