







最近已有不少大厂已停止秋招宣讲了。
节前,我们邀请了一些互联网大厂朋友、今年参加社招和校招面试的同学。
针对新手如何入门算法岗、该如何准备面试攻略、面试常考点、大模型技术趋势、算法项目落地经验分享等热门话题进行了深入的讨论。
总结链接如下:
喜欢本文记得收藏、关注、点赞
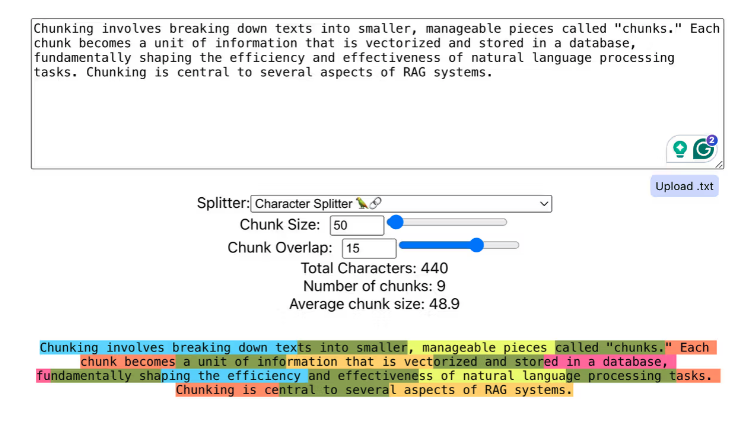
在RAG(Retrieval Augmented Generation)技术中,划分chunk是将长文档或数据集切割成较小的、独立的部分,以便于处理、存储和检索。
划分Chunk的必要性
RAG技术中划分chunk是为了更好地适应大模型的处理能力,提高检索和生成的效率和准确性,以及优化内容的相关性。
- 从大模型输入角度
模型在预训练过程中通常有上下文长度限制,如果输入的文本超过这个长度,超出部分会被丢弃,从而影响模型的性能表现。因此,需要将长文档分割成小块,以适应模型的上下文窗口。
- 从语义表示的差异性角度
长文档中各个片段的语义可能存在较大差异,如果将整个文档作为一个整体进行知识检索,会导致语义杂揉,影响检索效果。 将长文档切分成多个小块,可以使得每个小块内部表意一致,块之间表意存在多样性,从而更充分地发挥知识检索的作用。
如何评价Chunk划分方法?
分块归因(Chunk Attribution)
分块归因用于评估每个检索到的分块是否对模型的响应产生了影响。它使用一个二元指标,将每个分块归类为“有影响”(Attributed)或“无影响”(Not Attributed)。分块归因与分块利用率(Chunk Utilization)密切相关,其中归因确定分块是否对响应产生了影响,而利用率衡量分块文本在影响中所占的程度。 只有被归为“有影响”的分块才能有大于零的利用率得分。
分块利用率(Chunk Utilization)
分块利用率衡量每个检索到的分块中有多少文本对模型的响应产生了影响。这个指标的范围是0到1,其中1表示整个分块影响了响应,而较低的值,如0.5,则表示存在“无关”文本,这部分文本并未对响应产生影响。 分块利用率与分块归因紧密相关,归因确定分块是否影响了响应,而利用率衡量分块文本在影响中所占的部分。只有被归为“有影响”的分块才能有大于零的利用率得分。
划分Chunk的注意事项
在进行chunk划分时,需要保留每个chunk的原始内容来源信息,这包括但不限于:
-
页面编号:记录每个chunk来自文档的哪一页,有助于在需要时快速定位原始信息。
-
文档标识:为每个文档分配一个唯一的标识符,以便在检索时能够准确引用。
-
版本控制:如果文档会更新,记录chunk对应的文档版本,确保内容的一致性和准确性。
随着时间的推移,原始文档可能会更新或修改(可能使用新的文档处理方法重新划分chunk)。因此,在划分chunk时需要考虑:
-
更新策略:制定一个清晰的策略,以确定何时以及如何更新chunk,以保持信息的最新性。
-
版本兼容性:确保新旧版本的chunk能够兼容,或者能够明确区分不同版本的chunk。
此外chunk之间的顺序可能对理解整个文档至关重要:
-
顺序标记:为每个chunk分配顺序编号或时间戳,以保持它们的逻辑顺序。
-
顺序检索:在检索时,确保能够按照正确的顺序检索和展示chunk。
虽然存在不同的chunk划分方法,但文本内容的复杂性和多样性要求我们在划分chunk时采用灵活和多样的方法:
-
多种划分方法:根据文本的特点和需求,可能需要结合固定大小、滑动窗口、语义分块等多种方法。
-
上下文感知:在划分chunk时,考虑上下文的连贯性,避免将语义上紧密相关的信息分割开。
划分Chunk的各种方法
固定大小块分块策略(Fixed Size Chunking)
-
将文本分成固定大小的块,适用于内容格式和大小相似的数据集。
-
示例代码:
chunk_text(text, chunk_size=500),其中chunk_size是每个块的目标大小。

滑动窗口分块策略(Sliding Windows)
-
新的块与前一个块的内容重叠,包含部分内容,以更好地捕捉每个块周围的上下文。
-
可能导致文本被打断,产生无意义的块。
上下文感知分块策略(Context-aware Chunking)
-
包括基于token、句子、正则表达式和Markdown的分块技术。
-
例如,
TokenSplitter使用token划分文档,SentenceSplitter通过句子边界分割文本。
面向主题的分块技术
-
使用句子嵌入来识别文档中主题的变化,确保每个块封装一个单一的、连贯的主题。
-
通过标识主题转移的位置,提高检索性能和响应的准确性。
语义分块(Semantic Chunking)
-
核心目的是把相同语义的token聚集在一起,不同语义的token分开,利于后续的检索和重排。
-
通过计算句子组合的相似度来识别局部极小值,这表明潜在的话题转换,可以用阈值来确定重要的边界。
递归分块(Recursive Chunking)
-
使用一组分隔符,以分层和迭代的方式将文本划分为更小的块。
-
如果最初分割文本的尝试没有产生所需大小的块,则该方法会使用不同的分隔符递归地调用结果块,直到达到所需的块大小。
基于文档类型的分块(Document Based Chunking)
-
根据文档的固有结构对其进行拆分,考虑了内容的流和结构。
-
例如,
MarkdownTextSplitter类,以分隔符的方式分割Markdown文件。
基于大模型的分块(LLM Based Chunking)
-
通过大模型来理解文本,并将文本进行拆分为句子或段落。
-
依赖大模型能力,可以拆分原始文本,也可以从原始文本中生成新的文本
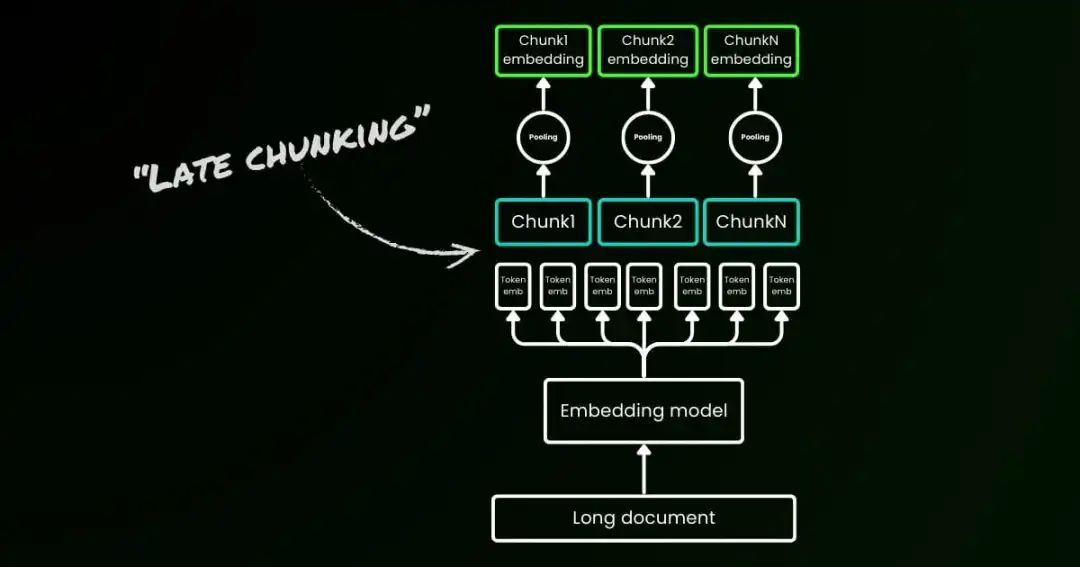
来自jina的Late Chunking
传统的在将长文档分割成多个分块时,可能会丢失重要的上下文信息,导致检索效果不佳。Late Chunking是一种基于语义的分块方法:
-
整体文本处理:Late Chunking 首先将整个文本输入到长上下文嵌入模型中,生成每个token的向量表示。这意味着模型能够捕捉到整个文本的上下文信息,而不仅仅是单个分块的局部上下文。
-
分块处理:在获得整个文本的token级嵌入后,再将文本分割成多个分块。每个分块包含一定数量的token,并且可能存在重叠部分,以保留边界处的上下文信息。
-
条件嵌入生成:对于每个分块,使用mean pooling或其他池化方法,将分块内所有token的向量表示聚合成一个分块嵌入。由于这些分块嵌入是基于整个文本的上下文生成的,因此它们能够保留更多的上下文信息。
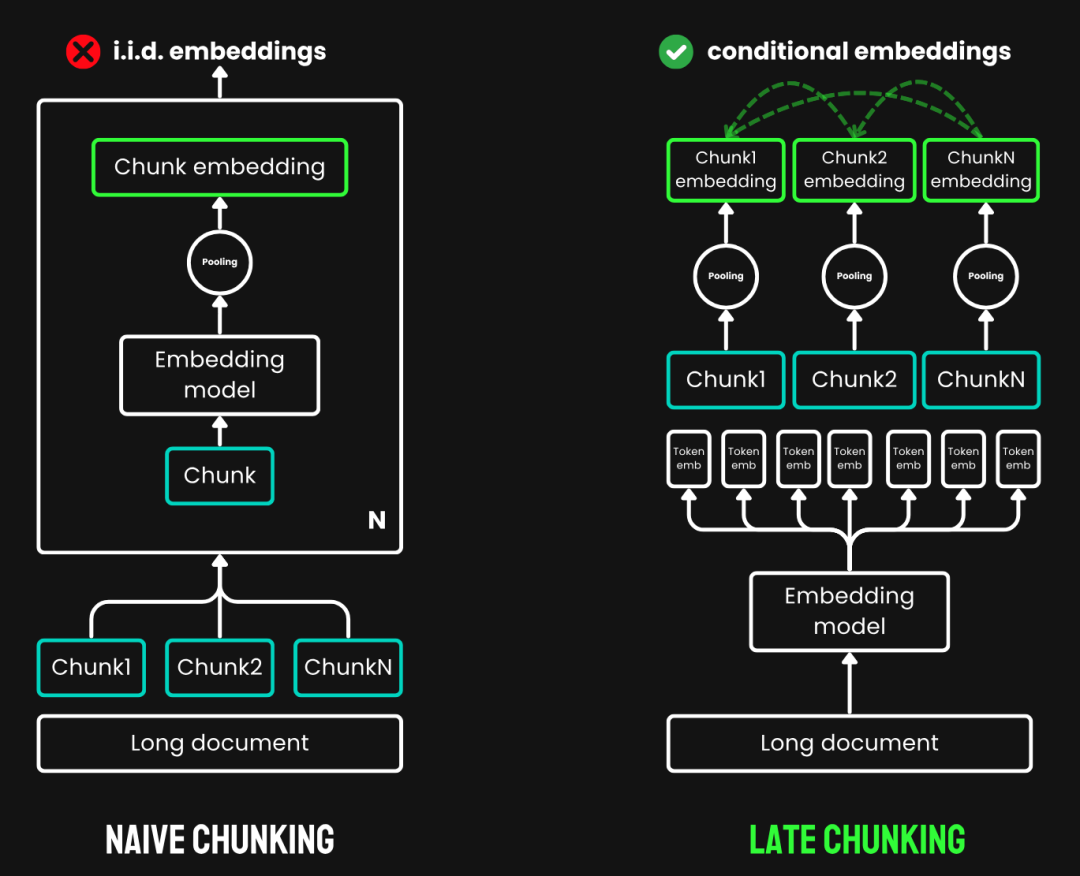
Late Chunking 能够更好地保留长距离的上下文信息,此外减少了对完美语义边界的需求,即使使用简单的固定长度分块,也能与使用语义边界线索的传统分块方法相媲美。
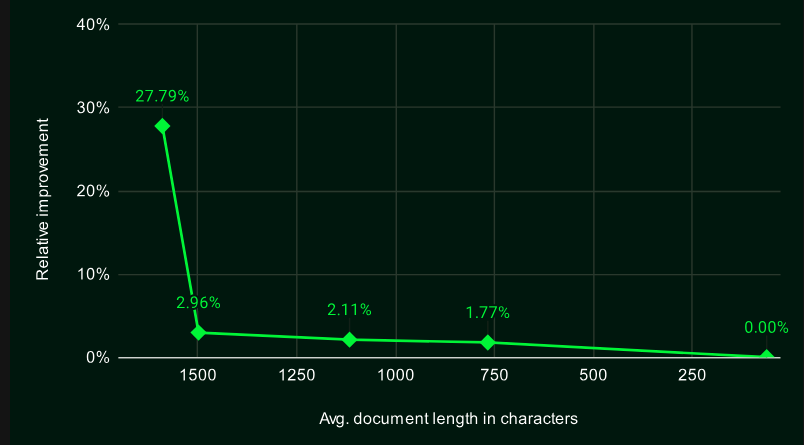
Late Chunking 不需要对嵌入模型进行额外训练,可以直接应用于任何使用均值池化的长上下文嵌入模型。Late Chunking 不仅限于特定的嵌入模型,它可以应用于任何支持长上下文和均值池化的嵌入模型。
来自jina的大模型分块
为了解决传统分块技术的局限性,jina开发了以智能识别和保留有意义的边界,提高RAG系统的检索质量。
jina使用qwen2-0.5b-instruct作为基础模型,训练三种变体的SLM。
-
simple-qwen-0.5:基于文档结构元素识别边界。
-
topic-qwen-0.5:基于文本内的主题来定义分块边界。
-
summary-qwen-0.5:识别文本边界并为每个段落生成摘要。
基于大模型的分块模型擅长处理包含代码、表格和列表的复杂文档,这些通常是传统方法难以处理的。上述三个模型能够在Nvidia 4090 GPU上运行,无需大量的计算资源。
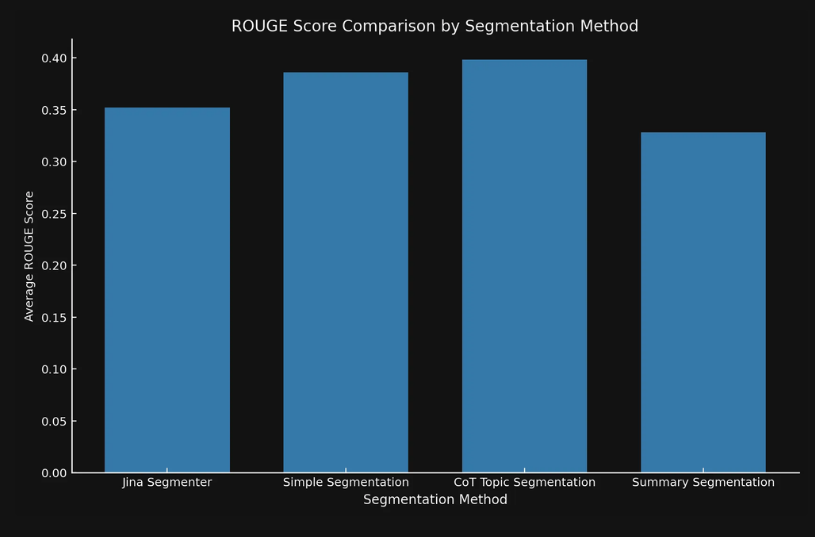
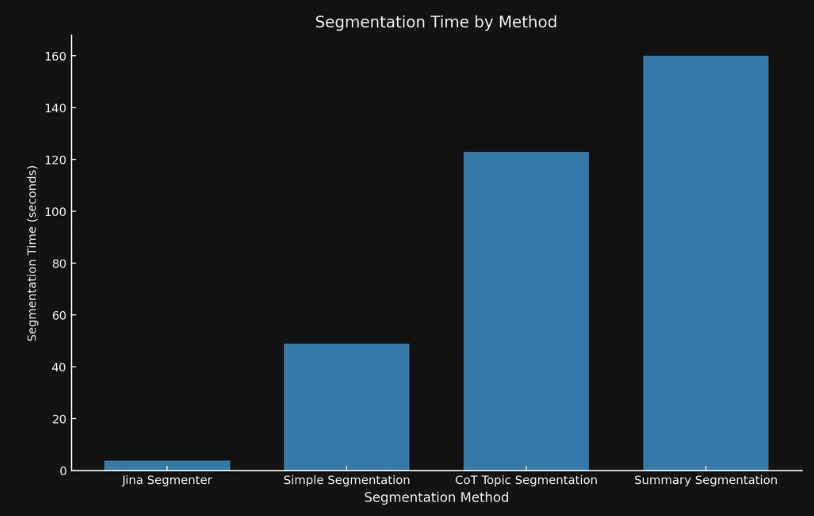
尽管这些模型在处理复杂文档方面表现出色,但对于简单的叙述性内容,像Segmenter API这样的简单方法通常就足够了。
参考文献
-
https://www.galileo.ai/blog/mastering-rag-advanced-chunking-techniques-for-llm-applications
-
https://jina.ai/news/late-chunking-in-long-context-embedding-models/
-
https://jina.ai/news/finding-optimal-breakpoints-in-long-documents-using-small-language-models/

















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









