







每天分析一个开源项目:MiniMind 从0开始训练属于自己的迷你版 GPT
3 块钱,2 小时,你也能训练属于自己的迷你版 GPT?MiniMind 开源项目深度解析
大家好,我是 申非,一名 AI 爱好者,今天给大家带来一个超有意思的开源项目——MiniMind!
最近,大模型的热度持续高涨,但动辄几百上千亿的参数,让很多小伙伴望而却步。想要深入了解 LLM 的底层原理,却苦于没有合适的“玩具”?MiniMind 的出现,简直是雪中送炭!
什么是 MiniMind?
简单来说,MiniMind 是一个致力于打造超轻量级语言模型的开源项目。它最大的特点是:
- 极致精简:最小模型仅 25.8M,是 GPT-3 的 1/7000!这意味着你甚至可以在普通的个人 GPU 上快速训练。
- 从零开始:所有核心算法代码都使用 PyTorch 原生重构,不依赖第三方库提供的抽象接口。这不仅是一个 LLM 的开源复现,更是一份绝佳的 LLM 入门教程。
- 成本极低:官方宣称最低只需 3 块钱不到的服务器成本,就能体验从 0 到 1 构建语言模型的全过程。
- 功能全面:项目不仅开源了 MiniMind-LLM 结构的全部代码(Dense + MoE 模型),还包含了 Tokenizer 训练、Pretrain、SFT、LoRA、RLHF-DPO、模型蒸馏等全过程的代码。
一句概括:MiniMind 就是要让你用最低的成本,最简单的方式,亲手打造属于自己的迷你版 GPT!
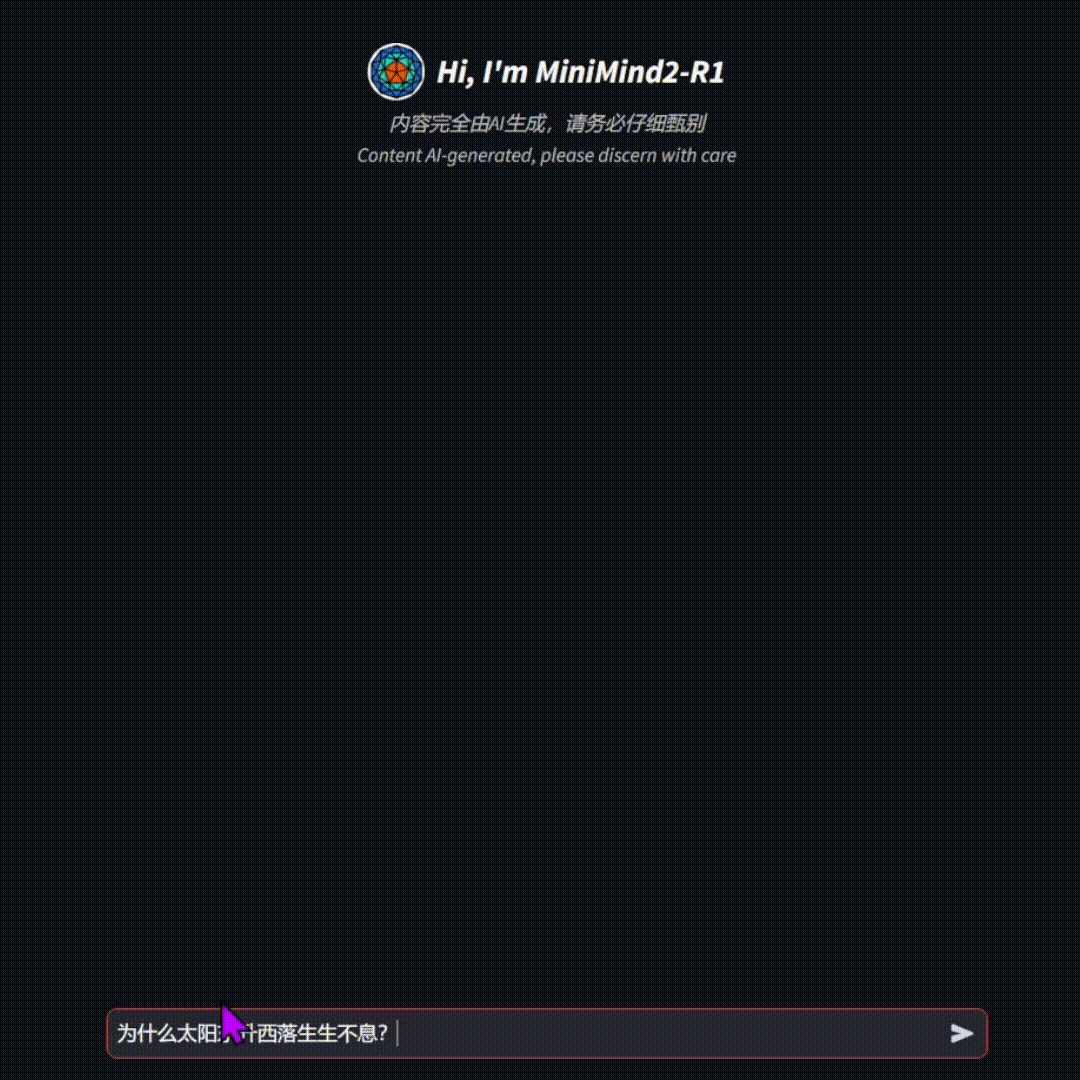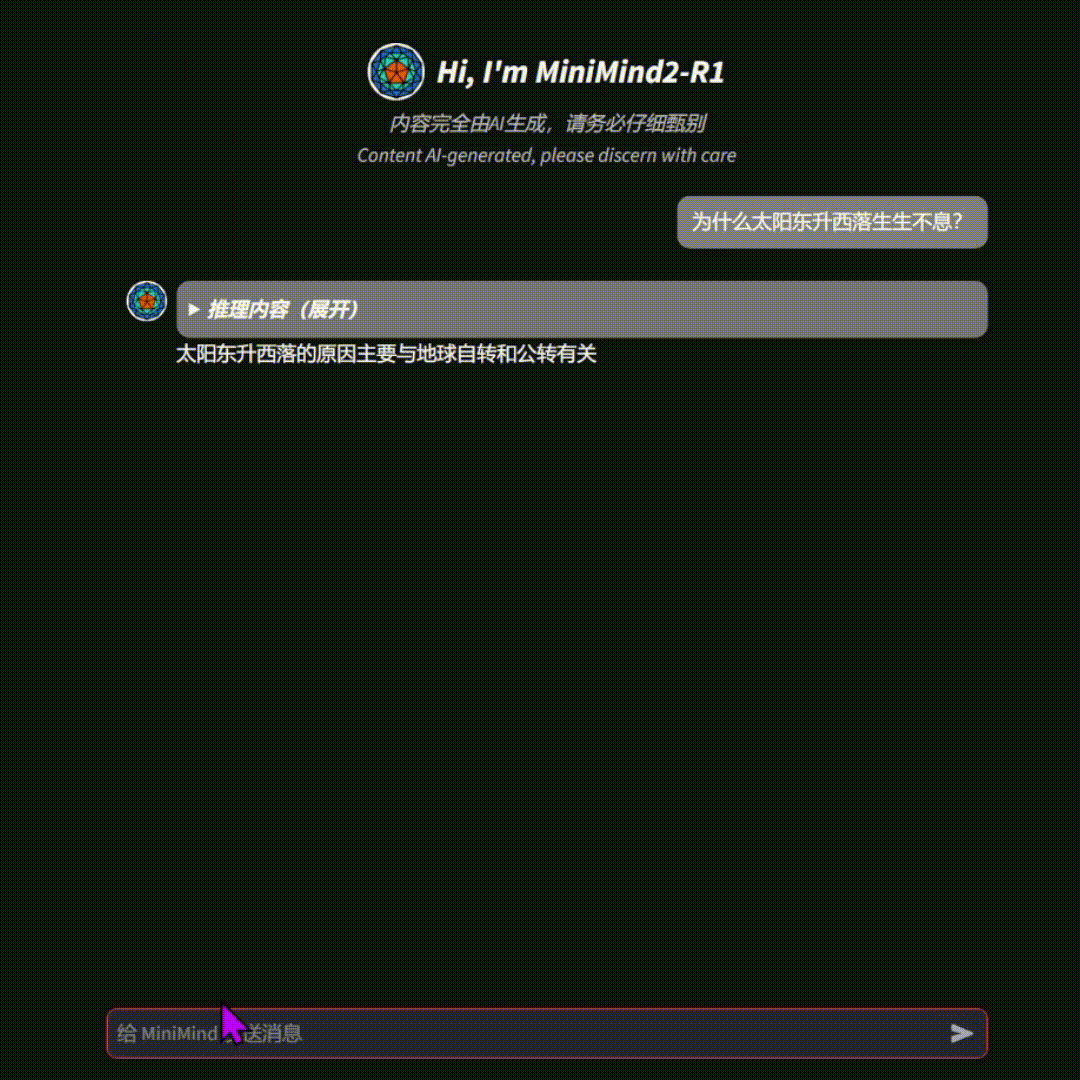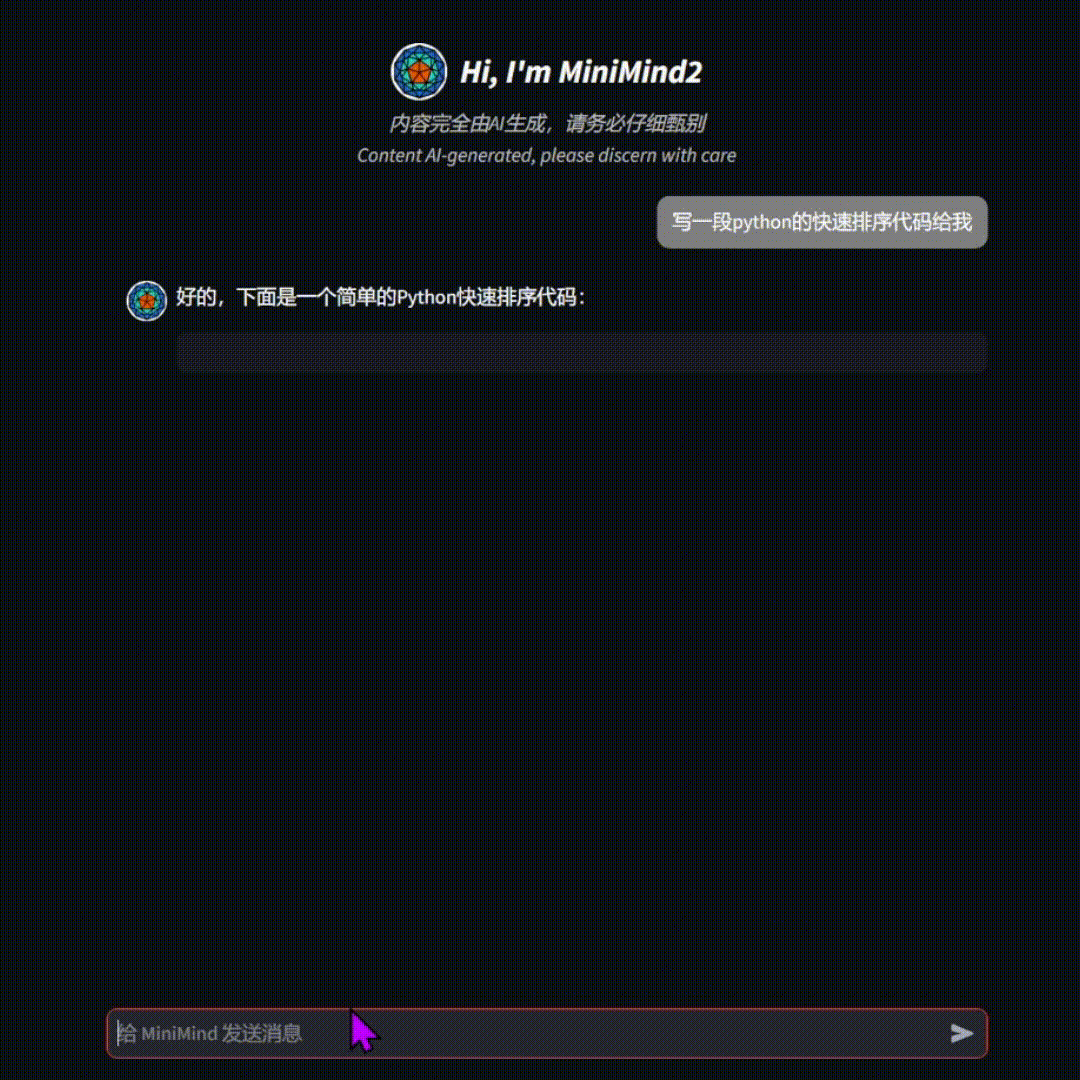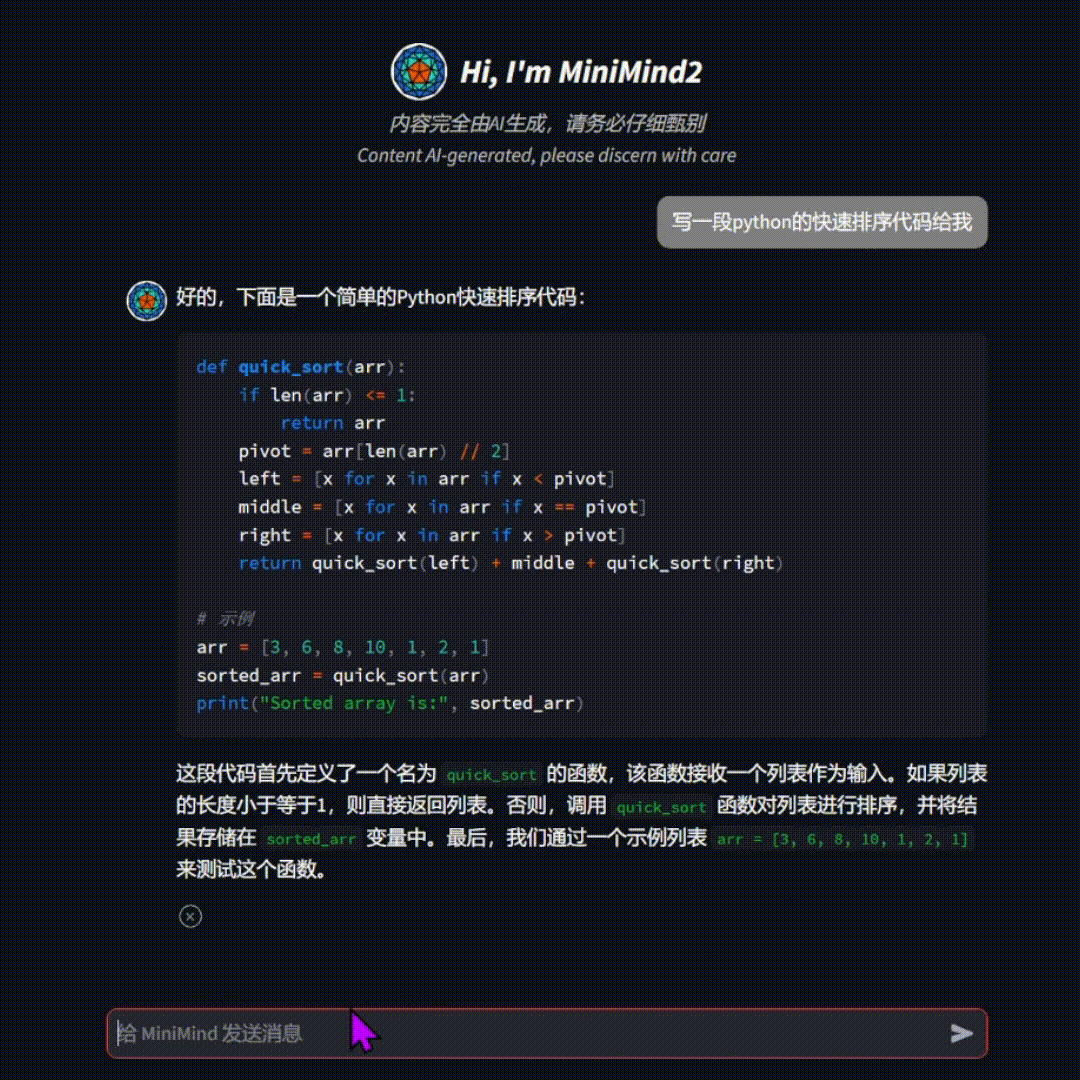
MiniMind 的核心亮点
-
全链路开源复现,降低 LLM 学习门槛
市面上很多 LLM 教程,要么只停留在 LoRA 微调层面,要么过度依赖第三方框架,让人难以窥探 LLM 的内部运作机制。MiniMind 却反其道而行之,所有核心算法代码均从 0 使用 PyTorch 原生重构,最大程度地降低了学习门槛。
-
极简架构 + 精心设计的数据集
MiniMind 在模型结构上进行了大胆的精简,同时又兼顾了模型的性能。项目开源了 Dense 和 MoE 两种模型结构,并针对小模型 Scaling Law 进行了深入研究。此外,项目还开源了高质量的数据集,覆盖了 Pretrain、SFT、RLHF 等多个阶段,避免了重复性的数据处理工作。
-
紧跟前沿,快速迭代
MiniMind 项目的更新非常活跃,紧跟 LLM 领域的前沿技术。例如,最近发布的 MiniMind2 系列,就对代码进行了几乎全部的重构,使用了更简洁明了的统一结构,并且模型效果相比 MiniMind-V1 显著提升。
-
多种训练方式支持
MiniMind 支持单机单卡、单机多卡 (DDP、DeepSpeed) 训练,还支持 wandb 可视化训练流程,方便开发者根据自身硬件条件进行选择。
如何玩转 MiniMind?
-
克隆项目代码
git clone https://github.com/jingyaogong/minimind.git -
安装依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple -
下载数据集
从 ModelScope 或 Hugging Face 下载需要的数据文件,并放到
./dataset 目录下。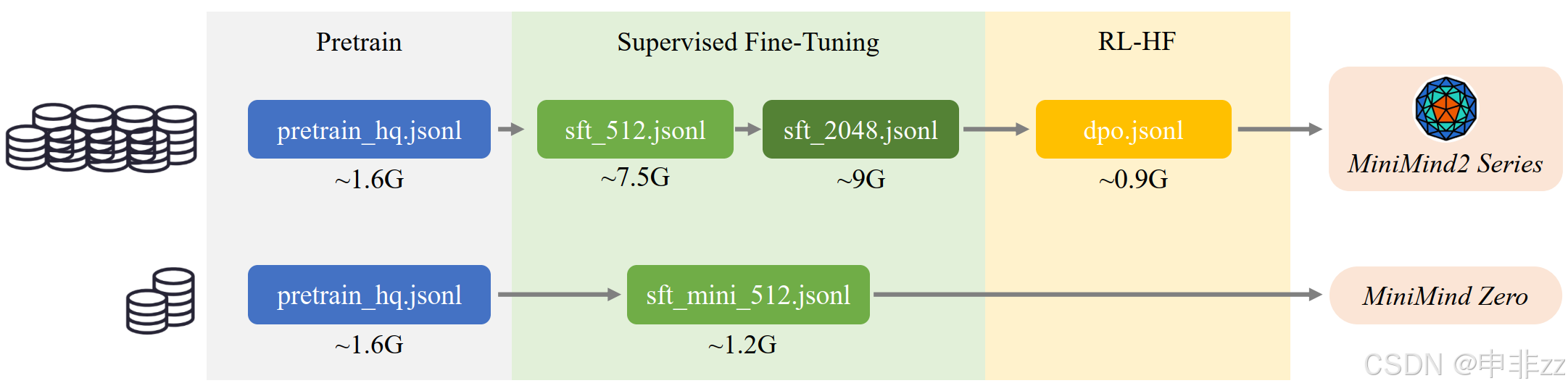
-
开始训练
- 预训练 (Pretrain)
python train_pretrain.py- 监督微调 (Supervised Fine-Tuning)
python train_full_sft.py当然,你还可以尝试 LoRA 微调、模型蒸馏、强化学习等更高级的玩法。
-
测试模型效果
python eval_model.py --model_mode 1 # 设置为1:测试full_sft模型效果
MiniMind 模型的性能表现
当然,对于 LLM 来说,最终还是要看实际的效果。MiniMind 的作者在 README 中给出了详细的实验数据,包括训练开销、训练损失走势、主观样例测评以及客观 Benchmark 跑分。
从数据来看,MiniMind 在模型参数量、训练数据量以及最终性能之间取得了不错的平衡。虽然不能和那些动辄几百 B 的大模型相提并论,但麻雀虽小,五脏俱全,MiniMind 已经具备了流畅的对话能力,并且仍然有很大的优化空间。
提问
我该如何选择训练的模型,配置其参数?
选择训练的 MiniMind 模型并配置其参数,需要根据你的具体需求(例如,希望模型具备什么样的能力、对模型大小的限制、训练资源的限制等)来进行综合考虑。 以下是一些详细的步骤和建议,帮助你做出最佳选择:
1. 确定目标和约束
-
想要模型具备什么能力?
- 通用对话能力: 如果你的目标是让模型能够进行流畅的日常对话,那么 SFT (Supervised Fine-Tuning) 阶段的模型就足够了。
- 推理能力: 如果你希望模型具备一定的推理能力(例如,解决数学题、进行逻辑推理等),那么可能需要训练 Reason 模型(例如,MiniMind2-R1) 或者尝试 RLHF (Reinforcement Learning from Human Feedback) 算法。
- 特定领域能力: 如果你希望模型在特定领域(例如,医疗、法律等)表现出色,那么需要在通用模型的基础上,使用 LoRA 或者 Full SFT 等方法进行微调,并使用领域相关的数据集。
-
对模型大小有什么限制?
- 显存限制: 显存大小直接决定了你可以使用的模型大小和 Batch Size。如果你的显卡显存较小,那么只能选择参数量较小的模型,并适当减小 Batch Size。
- 推理速度要求: 模型越大,推理速度越慢。如果对推理速度有较高要求,那么需要选择参数量较小的模型。
-
有什么训练资源限制?
- GPU 数量: 如果你有多个 GPU,可以选择使用 DDP (Distributed Data Parallel) 或者 DeepSpeed 等方式进行多卡训练,加快训练速度。
- 训练时间限制: 训练时间直接影响了模型的性能。如果训练时间有限,那么需要选择更高效的训练方法和数据集。
2. 选择合适的 MiniMind 模型
| 模型名称 | 参数量 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| MiniMind2-Small | 26M | * 体积小,训练速度快,资源占用少。 | * 相对其他模型,理解能力和生成质量稍逊。 | * 快速原型验证,低资源设备部署,LLM 入门学习。 |
| MiniMind2-MoE | 145M | * MoE (Mixture of Experts) 结构,理论上在参数量相近的情况下,性能优于 Dense 模型。 | * MoE 训练相对复杂,对数据和调参要求较高。 | * 对性能有一定要求,但资源有限,希望尝试 MoE 结构的 LLM。 |
| MiniMind2 | 104M | * 参数量适中,在性能和资源占用之间取得较好的平衡。 | * 相对于 Small 模型,训练速度较慢,资源占用较多。 | * 对性能有一定要求,且有一定的训练资源。 |
| MiniMind2-R1 系列 | ~100M | * 针对推理任务进行了优化,在推理能力方面表现更好。 | * 通用对话能力可能不如通用 Chat 模型。 | * 主要目标是让模型具备一定的推理能力,例如解决数学题、进行逻辑推理等。 |
| MiniMind-V1 系列 | ~100M | * V1 系列是 MiniMind 的早期版本,结构简单,训练成本低。 | * V1 系列模型在数据质量和训练方法上存在一些局限,性能不如 MiniMind2 系列。 | * 仅作为学习 LLM 基本原理的示例,或者在极低资源的场景下使用。 |
3. 配置模型参数
在选择了合适的 MiniMind 模型之后,需要根据你的具体需求和硬件条件,配置模型的参数。以下是一些常用的参数及其含义:
-
dim : 模型的 hidden size。这个参数直接影响了模型的参数量和表达能力。通常来说,dim 越大,模型性能越好,但同时也会增加资源消耗。 -
n_layers : 模型的层数。增加层数可以提高模型的学习能力,但也容易导致梯度消失等问题。 -
n_heads : Multi-head attention 的 head 数量。 -
n_kv_heads : Key 和 Value 的 head 数量。在 MQA (Multi-Query Attention) 和 GQA (Grouped-Query Attention) 中,n_kv_heads 可以小于n_heads,从而减少计算量。 -
max_seq_len : 模型支持的最大序列长度。这个参数决定了模型可以处理的最长文本长度。通常来说,max_seq_len 越大,模型能够记住的信息越多,但也需要更多的显存。 -
use_moe : 是否使用 MoE (Mixture of Experts) 结构。MoE 结构可以提高模型的容量,但也会增加训练的复杂性。 -
batch_size : 训练时的 batch size。Batch Size 越大,训练速度越快,但对显存的要求也越高。 -
learning_rate : 学习率。学习率过高可能会导致训练不稳定,学习率过低可能会导致收敛速度过慢。 -
epochs : 训练轮数。训练轮数越多,模型性能越好,但同时也需要更多的时间。 -
accumulation_steps : Gradient accumulation 的步数。当 Batch Size 无法设置太大时,可以使用 Gradient accumulation 来模拟更大的 Batch Size。 -
grad_clip : Gradient clipping 的阈值。Gradient clipping 可以防止梯度爆炸,提高训练的稳定性。 -
warmup_iters : Learning Rate Warmup 的 iteration 数量。Warmup 可以在训练初期提高训练的稳定性。
4. 配置训练脚本
在 train_pretrain.py、train_full_sft.py 等训练脚本中,可以通过命令行参数或者修改代码的方式来配置模型的参数。 例如:
parser = argparse.ArgumentParser(description="MiniMind Pretraining")
parser.add_argument("--out_dir", type=str, default="out")
parser.add_argument("--epochs", type=int, default=1)
parser.add_argument("--batch_size", type=int, default=32)
parser.add_argument("--learning_rate", type=float, default=5e-4)
parser.add_argument("--device", type=str, default="cuda:0" if torch.cuda.is_available() else "cpu")
# ... 其他参数
args = parser.parse_args()
5. 理论指导实践,实践验证理论
完成参数配置后,就可以开始训练模型了。在训练过程中,需要密切关注模型的 Loss 曲线、验证集指标等,以便及时调整参数。此外,还可以参考 MiniMind 项目作者的经验分享和社区讨论,以便更好地理解和使用 MiniMind。
分析minimind的两种模型结构?
一、 Dense 模型结构分析
-
核心结构:Decoder-Only Transformer
MiniMind-Dense 采用了和 GPT-3 以及 LLaMA 类似的 Decoder-Only Transformer 结构。这意味着它只使用 Transformer 的 Decoder 部分,擅长生成文本。
-
关键改进:
- Pre-normalization: 采用了 GPT-3 的预标准化方法,在每个 Transformer 子层的输入上进行归一化,而不是在输出上。具体来说,使用的是 RMSNorm 归一化函数。相比于传统的 Post-normalization,Pre-normalization 更容易训练,可以提高训练的稳定性。
- SwiGLU 激活函数: 用 SwiGLU 激活函数替代了 ReLU,这样做是为了提高性能。SwiGLU 是一种门控线性单元 (Gated Linear Unit),相比 ReLU,它具有更好的非线性表达能力,可以提高模型的性能。
- 旋转位置嵌入(RoPE): 去掉了绝对位置嵌入,改用了旋转位置嵌入(RoPE),这样在处理超出训练长度的推理时效果更好。RoPE 是一种相对位置编码方式,可以有效地处理长文本,并且具有良好的外推性。
-
结构示意图
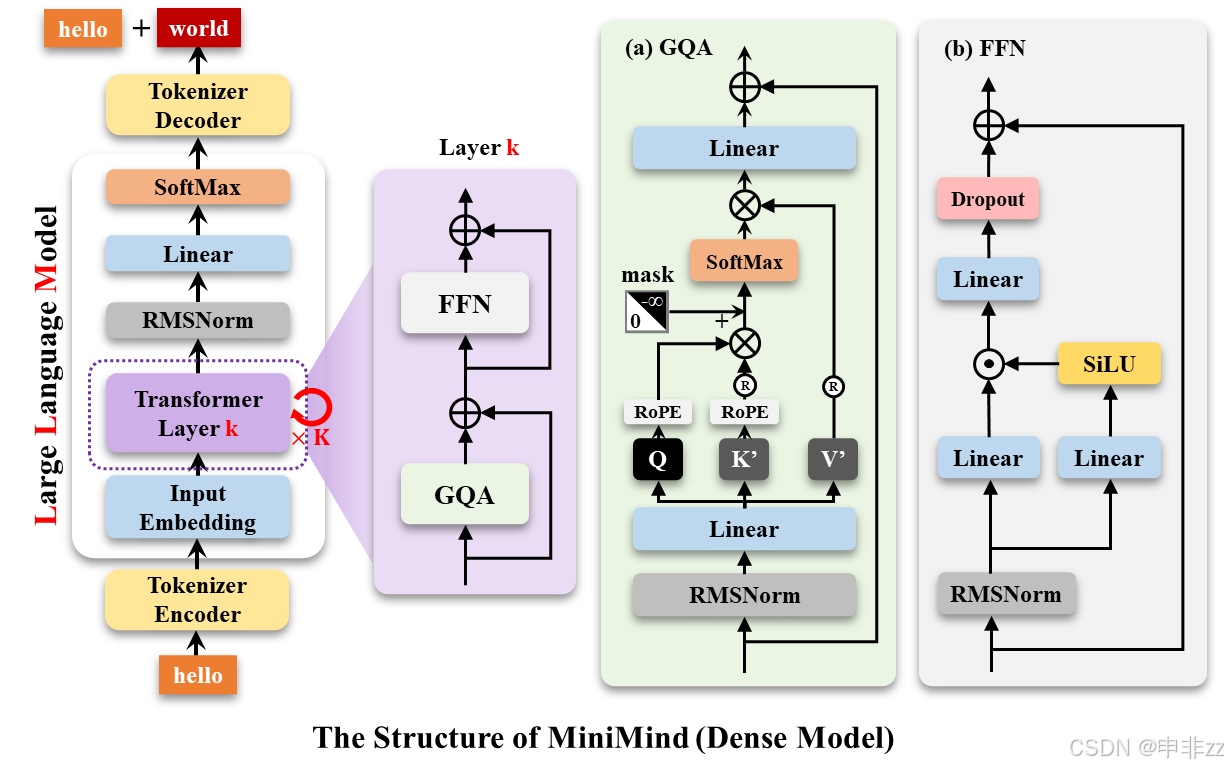
-
优势:
- 结构简单,易于理解和实现。
- 训练稳定,对数据和调参要求相对较低。
- 参数利用率高,可以在较小的参数量下取得不错的性能。
-
劣势:
- 模型容量有限,难以处理复杂的任务。
- 随着模型规模增大,性能提升会逐渐放缓。
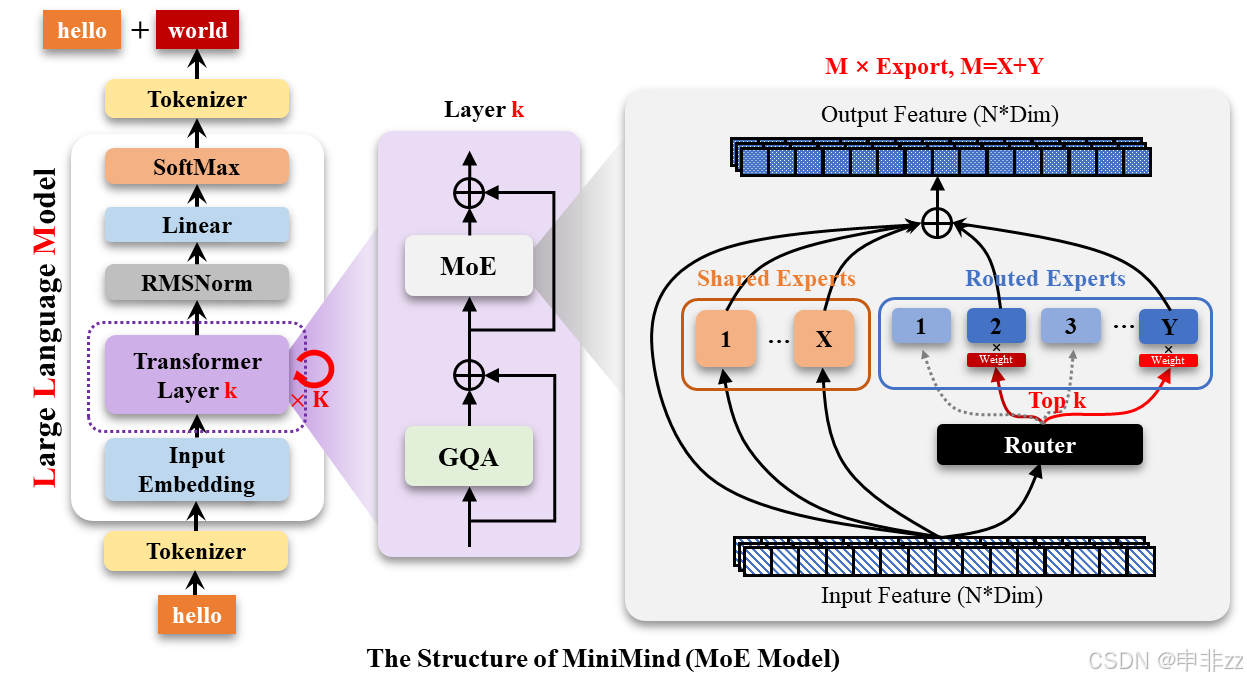
二、 MoE 模型结构分析
-
核心结构:Mixture of Experts (MoE)
MiniMind-MoE 模型在 Dense 模型的基础上,引入了 MoE 结构。MoE 是一种条件计算技术,可以根据输入动态地选择不同的专家 (Expert) 进行处理,从而提高模型的容量和表达能力。MiniMind 的 MoE 结构参考了 Llama3 和 Deepseek-V2/3 中的 MixFFN 混合专家模块。
-
MixFFN 混合专家模块:
DeepSeek-V2 在前馈网络(FFN)方面,采用了更细粒度的专家分割和共享的专家隔离技术,以提高 Experts 的效果。
-
关键组件:
- Experts: MoE 结构的核心是多个 Feed Forward 网络,每个 FF 网络都称为一个 Expert。
- Gate Network: Gate Network 负责根据输入选择合适的 Expert。MiniMind 使用 MoEGate 模块来实现 Gate Network,MoEGate 包含一个线性层和一个 Softmax 函数,用于计算每个 Expert 的权重。
- Shared Experts(可选): 一些 Expert 可以被共享,从而减少参数量。
- Auxiliary Loss: 为了平衡各个 Expert 的负载,MoE 结构通常会引入一个辅助损失函数。
-
结构示意图
可以通过项目 README 中的图来理解:
./images/LLM-structure-moe.png -
优势:
- 模型容量大,可以处理复杂的任务。
- 参数效率高,可以在相同的参数量下取得更好的性能。
-
劣势:
- 训练复杂,对数据和调参要求较高。
- 负载均衡是一个挑战,需要精心设计辅助损失函数。
- 推理速度可能较慢,因为需要动态地选择 Expert。
三、 两种模型结构对比
| 特性 | Dense 模型 | MoE 模型 |
|---|---|---|
| 核心结构 | Decoder-Only Transformer | Mixture of Experts (MoE) |
| 模型容量 | 相对较小 | 较大 |
| 参数效率 | 较高 | 很高 |
| 训练难度 | 较低 | 较高 |
| 推理速度 | 较快 | 相对较慢 |
| 适用场景 | 快速原型验证,低资源设备部署,LLM 入门学习,对模型大小有严格限制,但需要一定的性能时。 | 对性能有较高要求,但资源有限,需要处理较为复杂的任务。 |
| 关键技术点 | Pre-normalization, SwiGLU 激活函数, RoPE | MoE, Gate Network, 负载均衡, 动态路由。 |
| 潜在挑战 | 随着模型规模增大,性能提升逐渐放缓。 | 训练复杂,负载均衡是一个挑战,推理速度可能较慢。 |
四、 如何选择?
- 如果你的目标是快速入门 LLM,或者需要在低资源设备上部署模型,那么 Dense 模型是一个不错的选择。 它结构简单,易于训练,并且可以在较小的参数量下取得不错的性能。
- 如果你的目标是提高模型的容量和表达能力,并且有一定的训练资源,那么可以考虑 MoE 模型。 但需要注意的是,MoE 模型的训练和调参都比较复杂,需要一定的经验。
- 也可以先从 Dense 模型入手,熟悉 LLM 的基本原理,然后再尝试 MoE 模型。 这样可以降低学习曲线,更容易理解 MoE 的工作机制。
最后,请记住,没有最好的模型结构,只有最合适的模型结构。 在选择模型结构时,需要根据你的具体需求和资源限制,进行权衡和取舍。
总结
MiniMind 绝对是一个值得推荐的 LLM 入门项目。它不仅降低了 LLM 的学习门槛,让更多人有机会了解 LLM 的底层原理,也为 AI 社区贡献了一个极具价值的开源项目。如果你也对 LLM 感兴趣,不妨动手尝试一下 MiniMind,相信你一定会收获满满!
更多详情请在github项目项目地址中查看

















 2151
2151

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









