







在2014年,除了对抗学习这一重大的进步之外,图像生成领域还诞生了著名的“从图像到图像”的生成模型:变分自动编码器(Variational Autoencoders,VAE)。这一架构是从自动编码器(Autoencoders)衍生而来,它与线性层所构成的GAN在能力上较为相似,经过适当训练之后它可以生成难辨真假的手写数字与人脸数据。
然而,变分自动编码器的“声势”却不像生成对抗网络那样浩大,其一是因为生成对抗网络有巨大的研究潜力,其二是由于研究者们早已对于类似于变分自动编码器的各类编码器架构非常熟悉了。自动编码器(Autoencoders)是深度学习领域经典的无监督网络之一,因其作为生成模型的种种表现而闻名,但其诞生最初的目的并不是为了“图像生成”,而是为了实现各种目的下的“数据表示”。
数据表示(Data Representation)是使用另一种形式呈现原始数据的方法,这一技术也被称为隐式表示(latent Representation)或者转码(coding)。举例说明:
- 原始数据[2,4,6,8,10]
我们可以使用文字以2开头、以10结尾的偶数列来表示该原始数据,也可以使用**[x,2x,3x,4x,5x]且x=2**来表示该原始数据。此时,文字“以2开头、以10结尾的偶数列”和“[x,2x,3x,4x,5x]且x=2”就是原始数据的2种数据表示。
- 原始数据为[“苹果”,“梨”,“百香果”]
我们可以使用序列 [0,1,2] 来表示该原始数据,也可以使用水果这一概括性的词汇来表示原始数据。此时,[0,1,2]和“水果”都是原始数据的数据表示。
很显然,一个数据的数据表示不是唯一的,且这种表示可以是精确的、也可以是有些模糊的,甚至可以看起来与原始数据毫不相关,但无论如何,数据表示的结果必须携带原始数据上大部分的信息。广义地来说,只要数据B是以另一种形式呈现数据A、并且数据B上携带数据A大部分的信息,我们就可以说B是A的数据表示。同时,“另一种形式”既可以是文字-数字这样不同类别的数据之间的形式差异,也可以是数字-数字这样相同类别、但不同大小、不同数量的数据之间的形式差异。在实际计算当中,当数据B是数据A的数据表示时,数据B常常是从数据A总结出的规律、或直接在数据A上计算得出的新数据。
不难发现,根据数据表示的广义定义,我们非常熟悉的数据编码(独热编码、顺序编码等操作)、特征提取、升维降维、Embedding等方法都可以被囊括到数据表示领域当中。在这一领域当中,使用机器学习或深度学习手段令算法自己求解出数据表示结果的领域被称之为表征学习(Representation Learning)。自动编码器正是表征学习领域极具特色的代表架构,因此自动编码器常常被用于降维、特征提取这些“将原始数据转化、提炼为另外的表现形式”的领域。毫无疑问的,为了实现数据表示的功能,自动编码器能够“接收数据A,并输出另一种形式的数据B”,因此自动编码器是为“生产新数据”而生的架构。
那自动编码器是一种怎样的架构呢?首先,最为简单的自动编码器是由线性层构成的,它看起来就像是一个普通的深度神经网络DNN,只不过包含两大其他架构不具备的特征:
- 输出层的神经元数量往往与输入层的神经元数量一致
在有监督神经网络当中,输出层上的神经元数量必须根据标签的类别来决定,但对于自动编码器这样的无监督算法而言,输出层上的神经元数量理论上是可以自由定义的。在惯例当中,输出层的神经元数量往往与输入层的神经元数量一致,这样的结构能够保证输出与原始数据结构一致、但具体数值不同的数据表示,也有利于检验输出数据是否携带了原始数据大量甚至全部的信息。例如,当输入数据和输出数据为尺寸一致的图像时,只要将图像进行可视化,肉眼也可辨别出输出图像是否携带了足够的原始图像的信息。
- 网络架构往往呈对称性,且中间结构简单、两边结构复杂
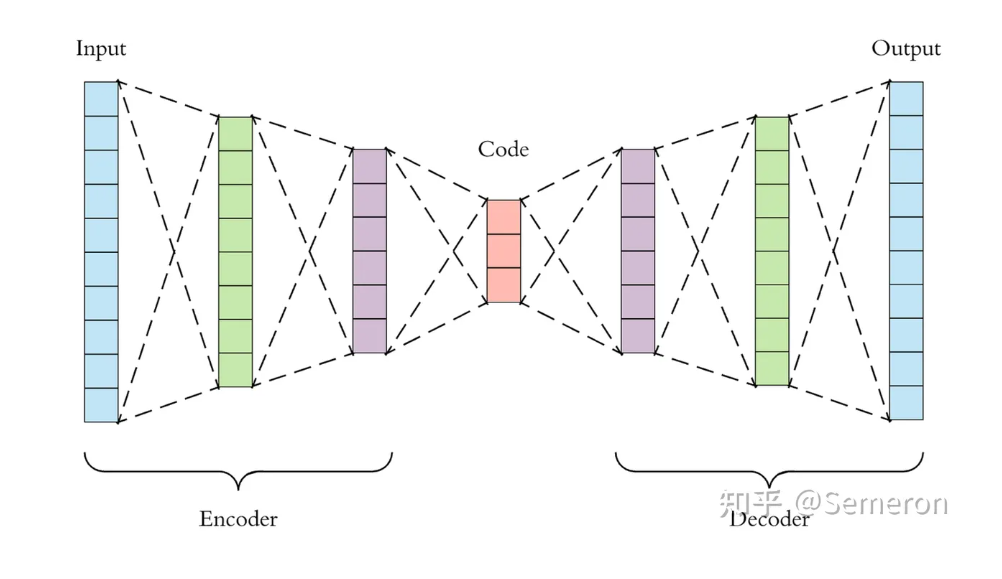
由于输入数据与输出数据结构基本一致,因此自动编码器的网络结构不会呈现出与深度神经网络或卷积神经网络相似的“由大到小”形态,反而会呈现出“大-小-大”的对称性。以下面的架构为例,网络最左侧为输入层,最右侧为输出层,输入层与输出层上的神经元个数都为10个,而输入层与输出层之间是先将神经元数量压缩、再将神经元数量提升的结构。这类先压缩、再提升的结构被称为“瓶颈结构”,与残差网络中的瓶颈结构有较大区别。
对比之下,其他架构一般是从左至右由大到小:
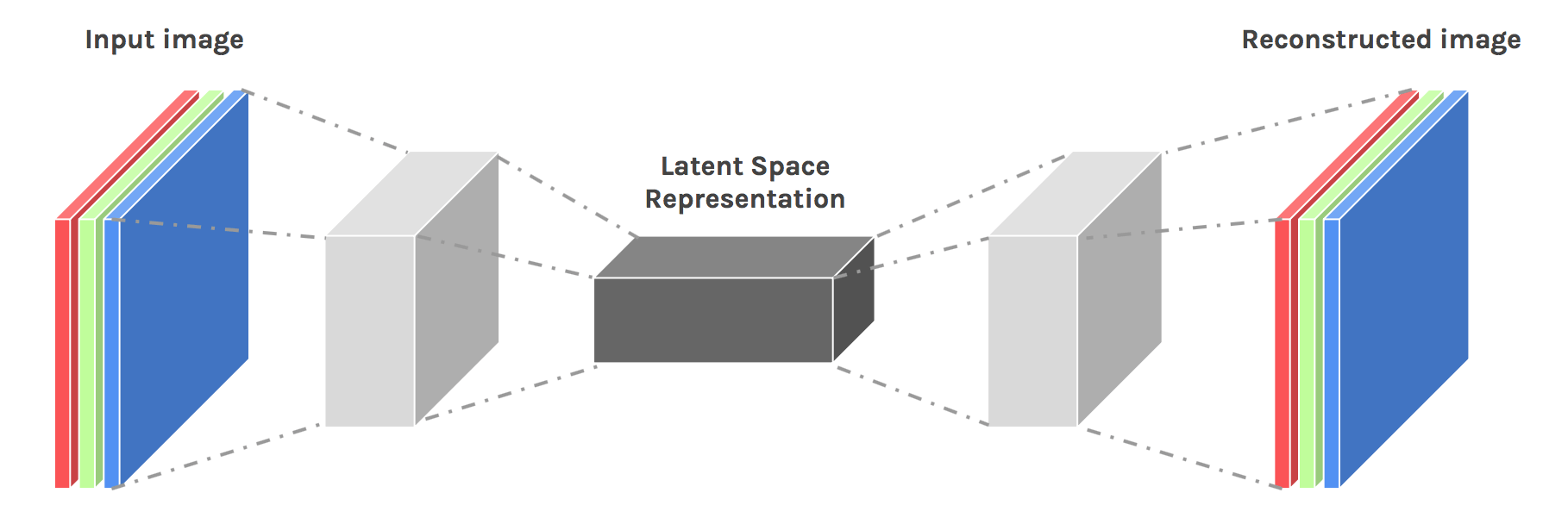
无论是在DNN还是CNN架构当中,将数据量逐渐压缩的过程都是在进行“信息提纯”(特征提取),对自动编码器而言也是如此。在上面的架构图中,从输入层开始压缩数据、直至架构中心的部分被称为编码器Encoder,从原始数据中提纯出的信息被称之为编码Code或隐式表示Latent Representation,从编码开始拓展数据、直至输出层的部分被称为解码器Decoder,解码器的输出一般被称为重构数据Reconstructions。值得注意的是,编码器的最后一层被称为编码层Coding Layer,编码层的结构被称为隐式空间Latent Space,当编码层上的神经元数量越多,隐式空间就越大,编码结果Code上所携带的原始数据的信息也会越多。
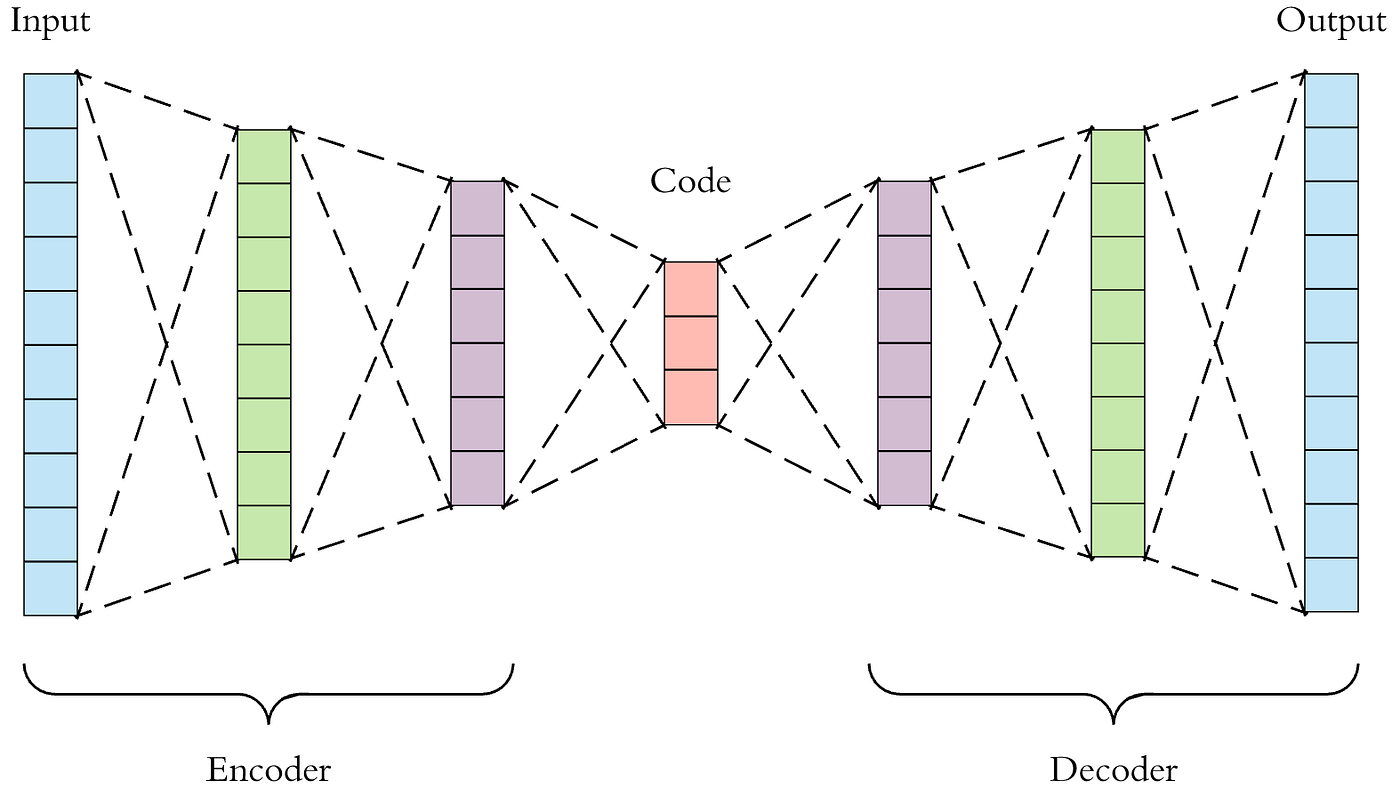
任意自动编码器都是由编码器和解码器共同构成的,在这一架构中,编码器的职责是从原始数据中提取必要的信息,而解码器的职责是将提取出的信息还原为原来的结构,二者共同工作,便能够将原始数据表示成相同结构、但不同数值的另一组数据。值得注意的是,在自动编码器的架构中,编码器的结果Code是原始数据的数据表示,而解码器输出的结果也是原始数据的数据表示。
很显然,如果你对深度神经网络足够熟悉,那自动编码器的架构很容易理解。同时,只需要将编码器中的线性层替换成卷积层、解码器中的线性层替换成转置卷积层,我们就可以轻易地实现深度卷积自动编码器的架构:
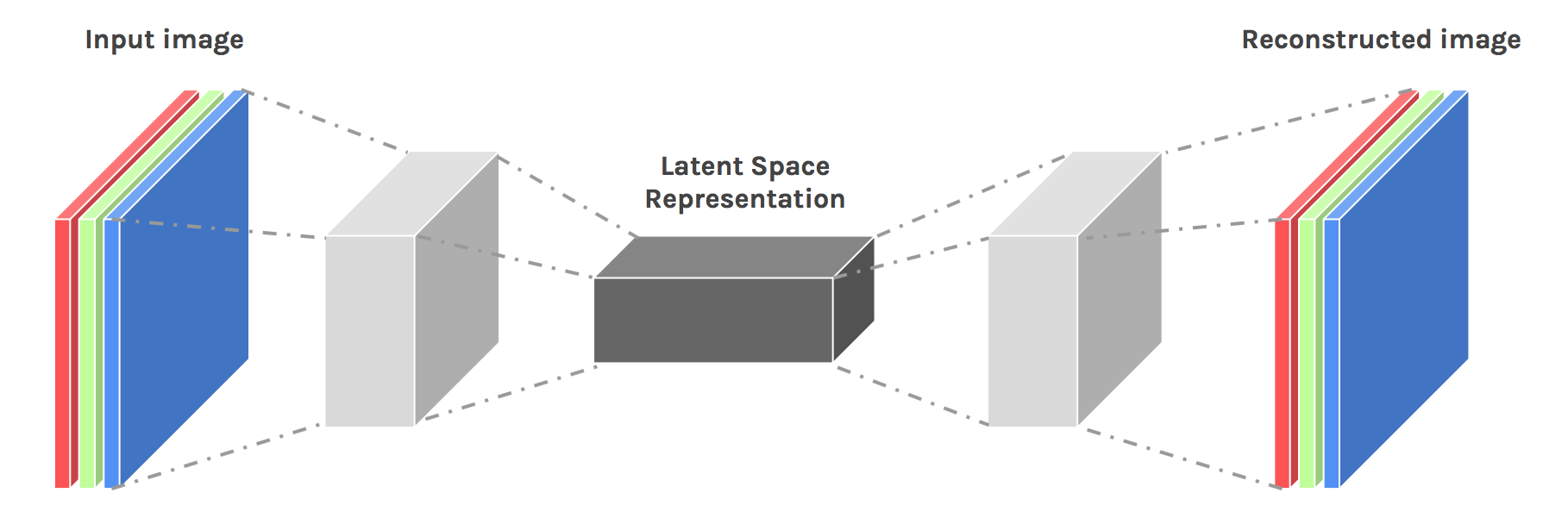
这一架构也非常简单,只要了解卷积神经网络及其拓展网络,就可以很快速地实现上述架构。然而,看似简单的架构却让人满腹困惑,甚至有许多“细思极恐”的问题没能解决,比如说:
- 作为一个无监督架构,自动编码器如何训练?
就像任意有监督网络一样地训练。自动编码器的各个层上拥有需要求解的参数 w w w(权重),它也拥有损失函数,它的训练目标是最小化损失函数以求解全部的参数 w w w。它可以正向传播、反向传播,可以使用一切我们在有监督网络中学过的技巧进行优化和训练。
- 自动编码器没有使用标签,那它的损失函数是什么?
神经网络架构的损失函数总是与该架构存在的目的息息相关。自动编码器的根本目标是实现有效的数据表示,即根据原始数据A、产出与原始数据A形式不一致、但携带大量原始数据信息的新数据B。在新生成数据B的数据量等于或小于原始数据A的数据量的情况下,B与A携带的信息相似性越高,代表数据表示的程度越深、数据表示的效率越高。因此,A与B之间的信息差异越小,自动编码器的效果就越好,相反,A与B之间的信息差异越大,就说明自动编码器越糟糕。因此,自动编码器追求的是原始数据A与新生成数据B之间的信息相似性,自动编码器的迭代方向就是令A与B的信息差异更小的方向。
那如何衡量数据A与B之间的差异呢?最常使用的当然是MAE或MSE这些距离类衡量指标,除此之外,在统计学上专门用于衡量不同数据的分布差异的指标,如KL散度、交叉熵等也可以被使用。这些指标可以轻易地衡量两组数据之间的差异,只不过在大多数有监督场景下他们衡量的是真实值与预测值之间的差异,而在自动编码器的场景下他们衡量的是原始数据A与输出数据B之间的差异。
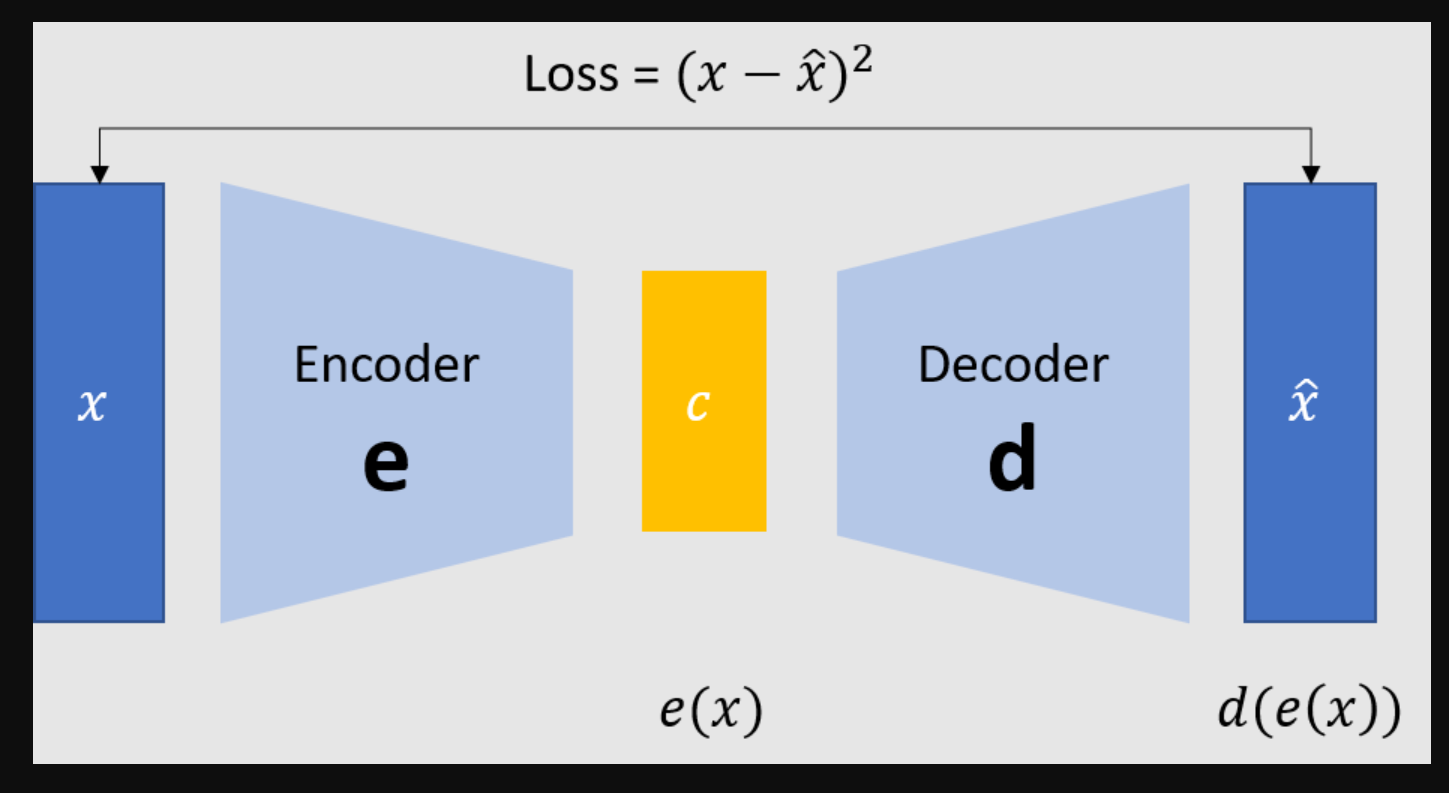
在自动编码器的整个损失函数中,这一部分被称为重构损失 Reconstruction Loss,它用以衡量自动编码器在将数据转变为另一种形态过程时产生的信息损失。通常来说,自动编码器会在重构损失的基础上,再根据具体架构的需要添加一些惩罚项,共同构成损失函数。
- 如果衡量指标是原始数据A与新生成数据B之间的信息差,神经网络难道不会直接复制原始数据吗?
大部分时候,自动编码器的输入就是原始数据A,因此如果不对自动编码器设置任何的阻碍,它有可能会直接复制原始数据,因为这样得到的信息差(损失函数值)是最小的。但实际操作起来却不是那么容易——毕竟神经网络中含有加和、激活函数、卷积、拉平等复杂数学运算,要保证所有的样本在同一套参数 w w w下都能够将原始数据直接复制到输出层,不是那么容易的一件事。同时,所有自动编码器中的数据必须被压缩到很小的维度后再放大,这要求网络必须舍弃一些信息,这样网络要想直接把信息复制到输出层就更困难了。
当然,只要网络足够深、训练次数足够多,神经网络也是可能实现“忽略中间复杂数学运算、直接把输入结果复制到输出层”这样的神迹的,因此我们在实际构建自动编码器的时候,我们需要人为地为算法增加一些“干扰”,以逼迫算法去学习高于当前具体数据的规律,而不同的干扰方式构成了不同的自动编码器。
- 都有什么样的干扰方法?都有哪些典型的自动编码器?
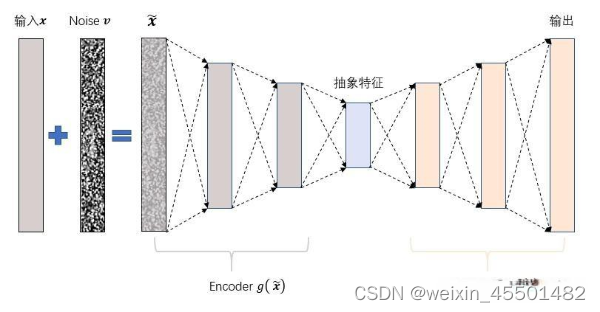
- 降噪自动编码器(Denoising Autoencoder)
为了给模型增加“难度”,降噪自动编码器在输入数据中添加噪音以干扰架构学习,同时也考虑对网络添加Dropout等结构来阻断信息的直接传播。这种情况下,自动编码器的输入就不再是原始数据A了,而是原始数据A与噪音融合后的结果。
s%2F5100d26b-63c5-4c69-93cd-4fb8df5ddcb2.png&pos_id=img-LF7B6HtB-1711447825607)
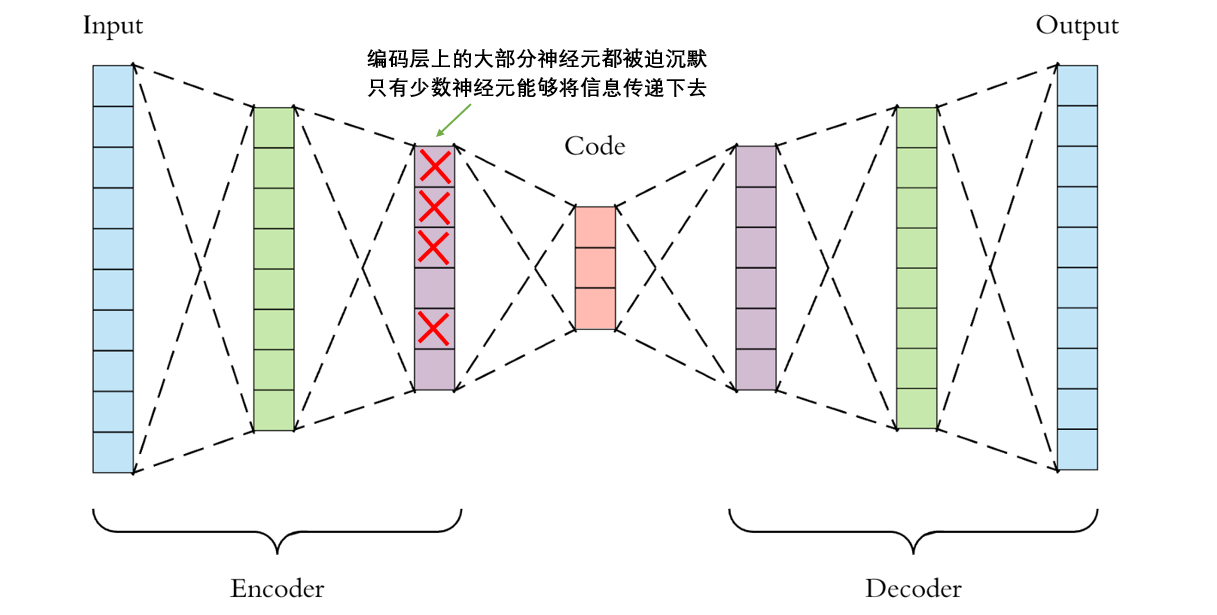
- 稀疏自动编码器(Sparse Autoencoder)
稀疏自动编码器通过控制稀疏性来提升编码器“提纯数据”的能力,逼迫编码器舍弃一些信息。例如,在编码层的100个神经元中,如果只有10个神经元上能够输出非0数字,而其他神经元上都是0或者非常接近于0的数字,那编码器必将会尽全力将最有用的信息集中在10个能够表达信息的神经元上,而舍弃一切不必要的信息。
怎么实现这一效果呢?只要编码层上不够稀疏,我们就可以在损失函数中施加惩罚,以此来逼迫架构向着稀疏的方向学习。在稀疏自动编码器中,有两种手段可以实现上述效果:
(1) 先使用sigmoid函数将编码层上所有神经元上的输出控制在(0,1)之内,再人为设定阈值 α \alpha α(往往是0.1或更小的数字),并规定输出值大于 α \alpha α的神经元为活跃神经元(active neurons),然后将所有活跃神经元上的输出绝对值加和后放入损失函数作为惩罚项。即,网络中输出大数字的神经元越多,网络受到的惩罚越大,以此逼迫网络将数字聚集在少量的神经元上。
(2) 同样使用sigmoid函数将神经元的输出值控制在(0,1)之间,再规定编码层的目标稀疏程度为 p p p(往往是0.1或更小的数字),计算编码层上所有神经元的输出值的均值与p之间的MSE,放入损失函数;或使用编码层上所有神经元的输出与p计算KL散度,并将KL散度值放入损失函数。即,编码层上输出值与p之间的差异越大,网络受到的惩罚就越大,以此逼迫编码层输出接近目标稀疏程度 p p p的值。
- 变分自动编码器(Variational Autoencoder,VAE)
不同于其他自动编码器、也不同于任意的其他深度网络架构,变分自动编码器斩断了神经网络中惯例的“从输入到输出”的数据流,以此杜绝了信息直接被复制到输出层的可能性。对任何真实样本 i i i而言,变分自动编码器的编码-解码步骤如下:
- 首先,变分自动编码器中的编码器会尽量将样本 i i i所携带的所有特征信息 X i X_i Xi的分布转码成类高斯分布 d i d_i di,该类高斯分布虽然是以高斯分布为目标来编码的,但它一般无法被编码成完美的高斯分布,这一分布被称之为实际分布
Actual Distribution或隐式分布Latent Distribution- 编码器需要输出该类高斯分布的均值 μ i \mu_i μi与标准差 σ i \sigma_i σi作为编码结果Code
- 以均值 μ i \mu_i μi与标准差 σ i \sigma_i σi为基础构建完美的高斯分布 D i D_i Di,这一分布被称之为目标分布
Target Distribution- 从完美的高斯分布 D i D_i Di中随机抽取出一个数值 z i z_i zi,将该数值输入解码器
- 解码器基于 z i z_i zi进行解码,并最终输出与样本 i i i的原始特征结构一致的数据,作为变分自动编码器的输出
不难发现,由于变分自动编码器根本不会将原始数据的编码结果Code直接传给解码器,因此输入数据被直接复制到输出的可能性几乎已经不存在了。同时值得注意的是,一个样本只会指向一个 z i z_i zi,因此解码器的输入的结构应该是n_samples个 z i z_i zi,这与生成对抗网络当中直接输入随机数的做法类似。
- 自动编码器能够输出与原始数据结构一致、数值不一致、但又携带原始数据信息的新数据,但这有什么用呢?
在大部分机器学习/深度学习落地应用场景当中(例如,图像识别、用户流失等),我们会直接使用有监督架构输出的预测标签,但无监督算法输出的并不是标签,因此其具体落地方式要灵活很多、甚至还可以将网络架构拆开应用。对于自动编码器而言,一旦完成训练,则可以在下列场景中实现落地应用:
- 通用降维:
舍弃解码器、只将编码器部分拆出来用于降维,在这种情况下,编码器的输出Code就是应用时的唯一输出。由于训练的时候要求解码器的输出B与原始数据A高度相似,因此训练完毕之后我们就能够保证编码结果一定是包含大量原始数据信息的。这样得出的降维结果一定能够最大程度保证信息不丢失。数据被降维之后,如果用于数据储存,就可以大大减少储存空间,如果用于算法训练,就可以大大提升算法效率,甚至可能提升算法的预测结果。
但需要注意的是,虽然特征衍生、升维属于数据表示的范围,但我们却很少使用自动编码器去对陌生数据进行升维,因为自动编码器的训练方向是“先提炼信息,再将提炼后的信息复原”,而不是“从较少的信息中解读出较多信息、提升数据质量”。如果你对特征工程有所了解,相信你能够理解其中的区别。
- 提升数据储存效率:
使用编码器将数据降维后进行储存/展示,需要使用数据时再使用解码器对数据进行复原,这一流程已经在谷歌云盘的轻量储存模块下进行实验。当我们将图像上传云盘时,编码器会瞬间对图像进行压缩,并只保存原始图像1/4的像素量,当我们在本地获取云盘图像时,解码器又会瞬间将图像还原会原本的像素量,以此节约云盘中的储存空间。
相似的技术还可以被用于查看原图功能,当在社交软件上收到图像时,用户只会收到经过编码器压缩后的1/8或1/10略缩图,只有当用户要求查看原图时,我们才会再使用解码器将图像复原。当然,在某些场景下也可能是直接将原始图像传输到本地。

- 数据生成:
在自动编码器家族当中,大部分架构都只能够实现“数据改良”,即在输入数据上进行修改,真正能够实现数据生成的其实只有变分自动编码器这一类,因此在整个自动编码器家族中,只有变分自动编码器可以被称之为“生成模型”。
在变分自动编码器中,编码器的输入是原始数据 X X X,但解码器的输入的却是随机抽样出的 z z z,因此当变分自动编码器被训练好之后,我们可以只取架构中的解码器来使用:只要对解码器输入任意的随机数 z z z,解码器就可以生成仿佛从原始数据 X X X中抽样出来的数据,如此就能够实现图像生成。许多论文已经证明,变分自动编码器的生成能力足以与一些生成对抗网络分庭抗礼,但这一架构在生成领域的局限也很明显:与GAN一样,变分自动编码器能够获得的信息只有随机数 z z z,因此在面临复杂数据时架构会显得有些弱小。同时,由于该架构在训练和预测过程中都有随机性,也不太适合于想要生成指定数据的场景。但无论如何,变分自动编码器的数据生成能力是不可忽视的。
- 数据修复/通用图像处理(降噪、图像复原、上色、智能抠图、去水印等):
在降噪自动编码器中,架构接收带有噪音的图像,但却输出不带噪音的图像,说明在输入数据中加入“噪音”的行为赋予了架构降噪的能力。这一能力可以被用于视频、图像、语音或其他普通数据的降噪场景。同理,如果我们在图像数据中随机挖掉一块(为这些像素点都填上0像素、或255像素值),在经过适当训练之后,自动编码器也可以为我们将图像复原。因此我们可以根据自己的需求训练各种各样能够处理“残缺”数据的自动编码器,因此自动编码器也可以被用于各式各样图像的修复和补全了。

到这里,我相信你已经了解自动编码器这一族算法了,相信在自动编码器的众多应用当中,图像修复和补全的部分是最令人印象深刻的。遗憾的是,大部分时候自动编码器做出的图像修复和补全无法做到特别完美,常常会有“毛边”和明显的痕迹存在。下图是基于生成对抗网络的复杂架构在图像修复方面的成果,我们可以看出明显的对比:
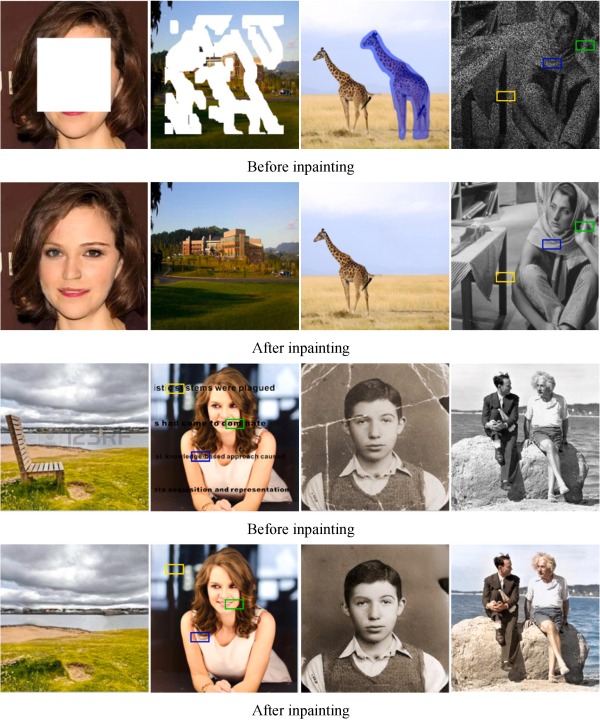
很显然,与当前已经非常成熟的SOTA模型们比起来,自动编码器在图像处理方面的能量比较有限,只要更换输入数据就可以训练自动编码器来达成迥然不同的目的(例如,图像上色和图像降噪),这是一个非常振奋人心、并且非常有启发性的消息,这一点使得自动编码器拥有了巨大的应用潜力,并且可以作为输出数据、生成数据的架构存在于各类顶级模型当中。
为什么自动编码器的潜力如此之大呢?举例说明,在降噪自动编码器中,我们实际上准备了真实数据A和带噪音的数据A’两组数据,在训练过程中,我们让架构从A’生成数据B,并且一直致力于缩小B与A之间的差异。在适当训练后,我们得到了能够通过A’生成B,且令B与A高度相似的架构。这一过程看似平常,但其实等同于一个有监督的过程。
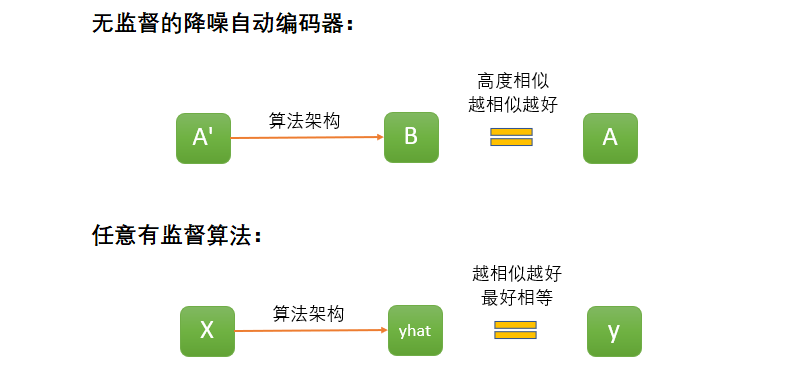
不难发现,自动编码器中损失函数衡量A与B之间的差异,而有监督算法当中损失函数衡量预测标签yhat与真实标签y之间的差异,无论我们面对的任务是给图像上色、还是给图像补全、还是其他任务,只要认为A是真实标签、A’是特征矩阵,那自动编码器就可以被当成一个有监督算法使用。如果想要为黑白图像上色,你应该准备彩色图像作为原始数据A,黑白图像作为输入数据A’,如果你想要将冬天的照片变成夏天,那你应该准备夏天的照片作为原始数据A,冬天的照片作为原始数据A’。至此,专用于“数据表示”的无监督算法就成为了可以“依葫芦画瓢”的有监督算法了,真是妙哉。
在所有把自动编码器当做有监督算法使用的场景中,图像分割(Image Segmentation)是最受关注也最为重要的场景之一,而在这一场景中最负盛名的架构之一就是基于自动编码器改进而来的有监督方法Unet。下一节,我们来认识一下经典图像分割架构Unet。
4.5.2 变分自动编码器 Variational Autoencoder (VAE)
变分自动编码器是Encoder-Decoder家族最负盛名、也最受关注的编码器类型,这不仅仅是因为变分自动编码器是整个Encoder-Decoder家族中为数不多的生成模型,也因为这一类架构背后有及其复杂的数学原理与实现代码,这令研究者们欢呼雀跃,同时让众多深度学习新手苦不堪言。变分自动编码器背后的数学原理十分艰深,在课程有限的时间内难以完全展开描述,因此在今天的课程当中,我们的目标是让大家深度了解变分自动编码器的实际运行过程。
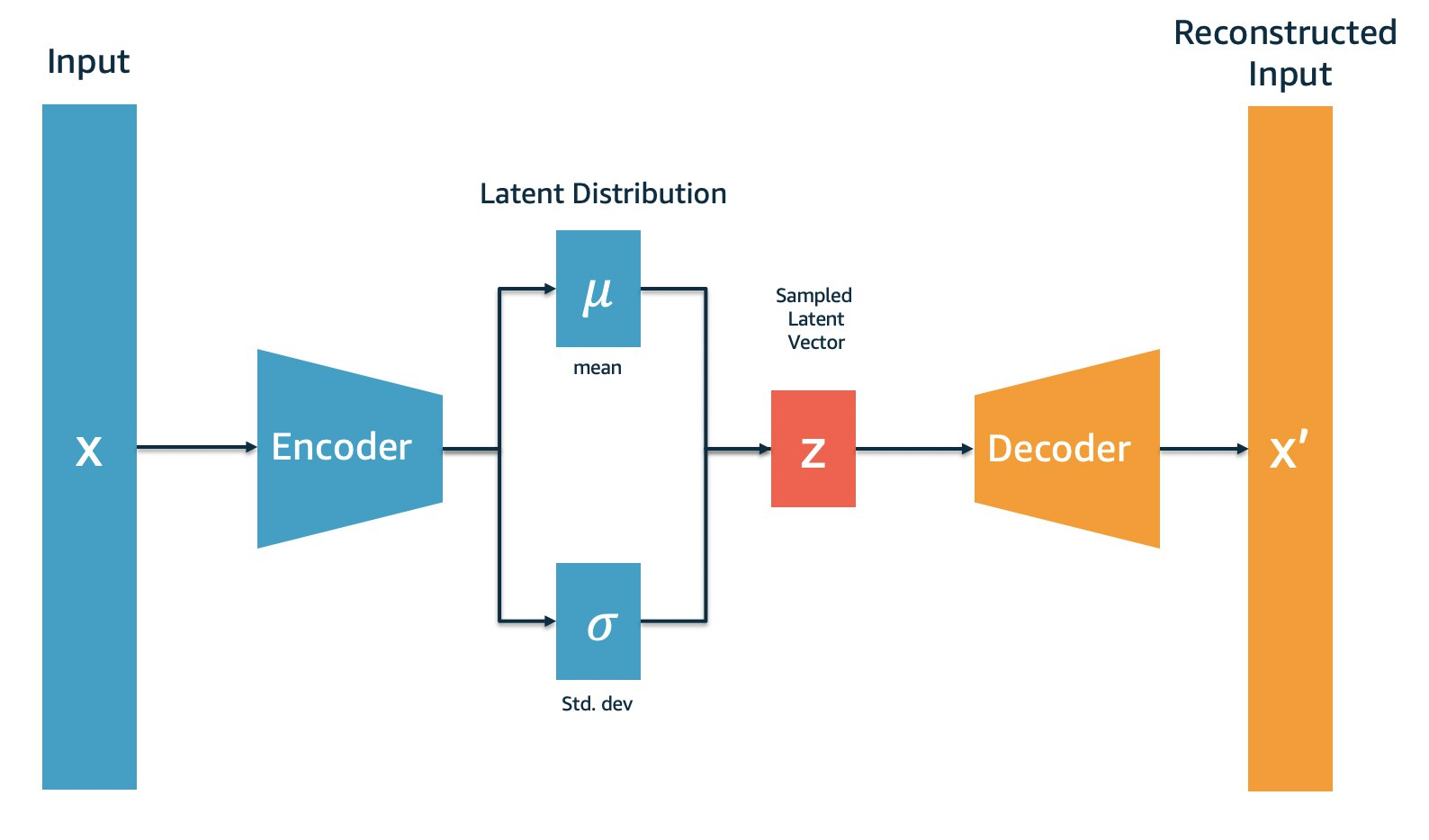
首先,我们可以简单概括一下变分自动编码器的实际架构:与普通自动编码器一样,变分自动编码器有编码器Encoder与解码器Decoder两大部分组成,原始图像从编码器输入,经编码器后形成隐式表示(Latent Representation),之后隐式表示被输入到解码器、再复原回原始输入的结构。然而,与普通Autoencoders不同的是,变分自用编码器的Encoder与Decoder在数据流上并不是相连的,我们不会直接将Encoder编码后的结果传递给Decoder,具体流程如下:
- 首先,变分自动编码器中的编码器会尽量将样本 i i i所携带的所有特征信息 X i X_i Xi的分布转码成类高斯分布 d i d_i di,该类高斯分布虽然是以高斯分布为目标来编码的,但它一般无法被编码成完美的高斯分布,这一分布被称之为实际分布
Actual Distribution或隐式分布Latent Distribution- 编码器需要输出该类高斯分布的均值 μ i \mu_i μi与标准差 σ i \sigma_i σi作为编码结果Code
- 以均值 μ i \mu_i μi与标准差 σ i \sigma_i σi为基础构建完美的高斯分布 D i D_i Di,这一分布被称之为目标分布
Target Distribution- 从完美的高斯分布 D i D_i Di中随机抽取出一个数值 z i z_i zi,将该数值输入解码器
- 解码器基于 z i z_i zi进行解码,并最终输出与样本 i i i的原始特征结构一致的数据,作为变分自动编码器的输出
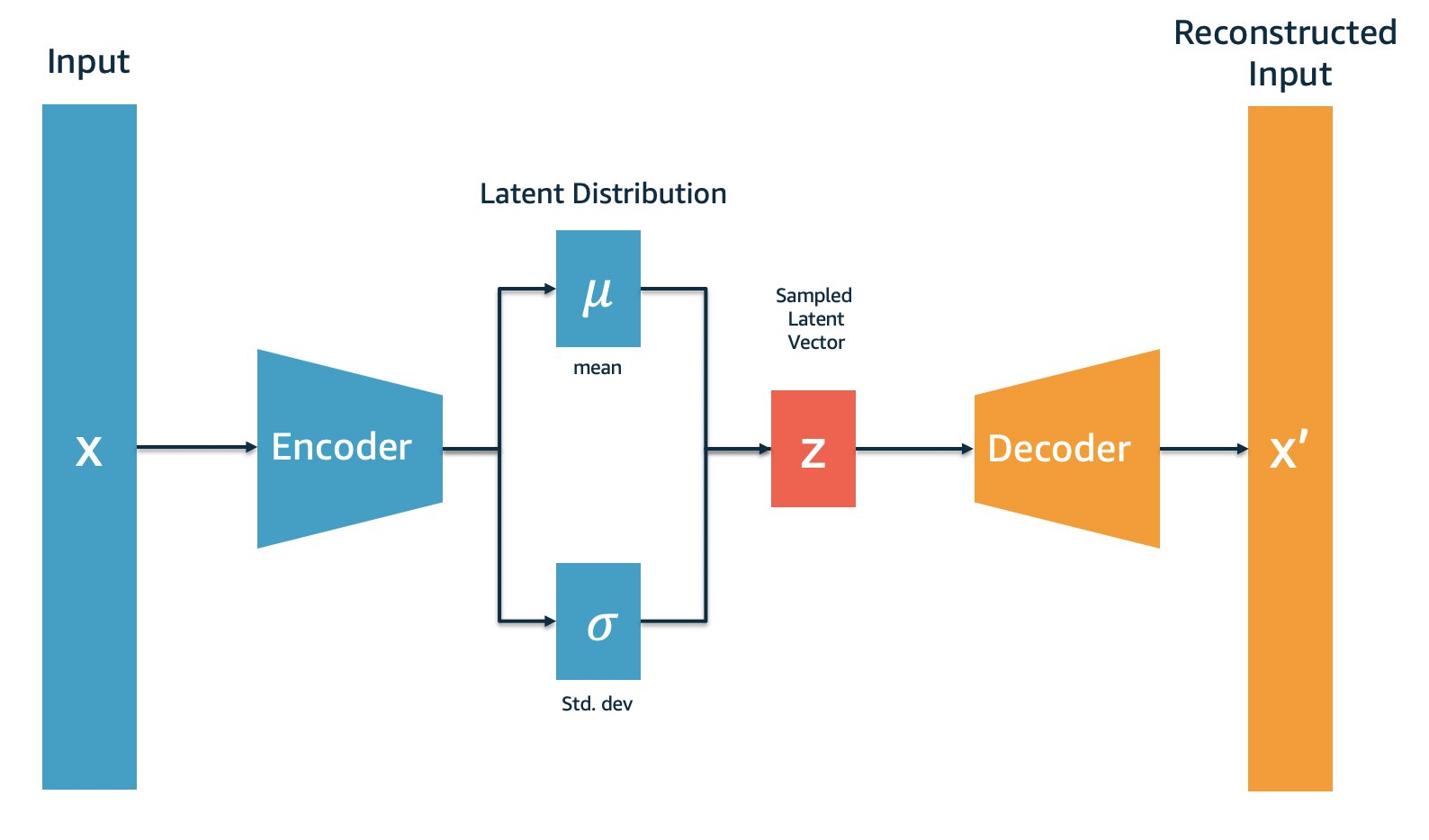
根据以上流程,变分自动编码器的Encoder在输出时,并不会直接输出原始数据的隐式表示,而是会输出从原始数据提炼出的均值 μ \mu μ和标准差 σ \sigma σ。之后,我们需要建立均值为 μ \mu μ、标准差为 σ \sigma σ的正态分布,并从该正态分布中抽样出隐式表示z,再将隐式表示z输入到Decoder中进行解码。对隐式表示z而言,它传递给Decoder的就不是原始数据的信息,而只是与原始数据同均值、同标准差的分布中的信息了。
这个流程描述起来似乎并不复杂,但实际的数据流却没有这么简单。在这里,我为大家梳理了三个需要梳理的重点细节:
1. 在实际运算当中,Encoder不会先输出 d i d_i di、再根据 d i d_i di计算出 μ i \mu_i μi和 σ i \sigma_i σi,而是直接输出满足类正态分布要求的 μ i \mu_i μi和 σ i \sigma_i σi。即,编码过程中产生的均值 μ \mu μ与标准差 σ \sigma σ并不是通过均值或标准差的定义计算出来的,而是直接从Encoder网络中输出的值。
2. 为了保证Encoder输出的均值和标准差满足类正态分布,变分自动编码器在损失函数中设置了惩罚项——一旦均值和标准差所反馈的分布Actual Distribution与完美的正态分布Target Distribution有差异,变分自动编码器就会受到惩罚。故而在实际的算法运行流程中,Encoder负责输出均值和标准差,损失函数保证均值和标准差是符合某种类正态分布的,这就等价于Encoder将原始数据向类正态分布的方向编码、再输出该类正态分布的均值与标准差。
3. 由于存在随机抽样过程,架构中的数据流是断裂的,因此反向传播无法进行,因此我们需要独特的重参数技巧来完成变分自动编码器的反向传播。
这三个细节让整个数据过程变得有些复杂,接下来我们来抽丝剥茧地讲解整个数据过程:
- 变分自动编码器的数据流
让我们以单一样本和最简单的情况为例,详细讲述一下该过程中的各个细节。
首先,假设存在m个样本,5个特征,数据结构为(m,5)。同时,假设Encoder与Decoder中都只有2层带3个神经元的线性层,且每个样本只生成一个均值与一个标准差,则转化流程如下所示:
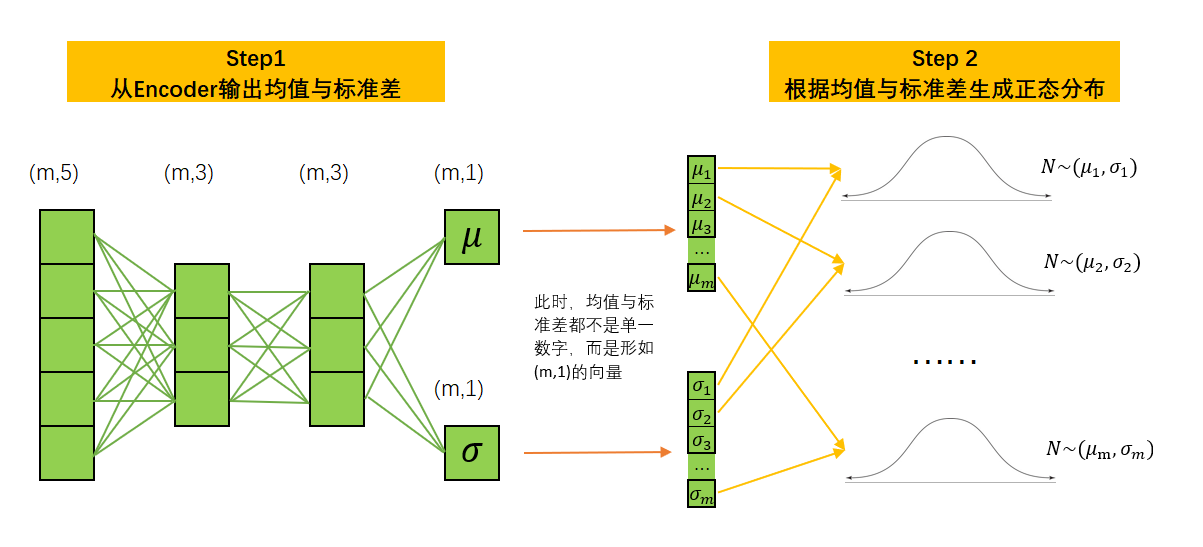
此时,任意样本 i i i经过Encoder后会输出一个均值 μ i \mu_i μi与一个标准差 σ i \sigma_i σi,可以认为样本 i i i上所有的特征信息都被认为属于分布 N ∼ ( μ i , σ i ) N\sim(\mu_i,\sigma_i) N∼(μi,σi),故而此时 μ i \mu_i μi与 σ i \sigma_i σi已经携带了样本 i i i上尽量多的信息。此时,整个Encoder的输出是形如(m,1)的均值向量 μ \boldsymbol{\mu} μ和标准差向量 σ \boldsymbol{\sigma} σ。针对这两个向量中的每一组 ( μ i , σ i ) (\mu_i,\sigma_i) (μi,σi),我们都可以生成相应的完美正态分布。有了完美正态分布之后,我们可以从每个正态分布中随机抽选一个数字,并按样本排列顺序拼凑在一起,构成形如(m,1)的 z \boldsymbol{z} z向量。此时, z \boldsymbol{z} z向量再输入Decoder,Decoder的输入层就只能有1个神经元,因为 z z z只有一列。
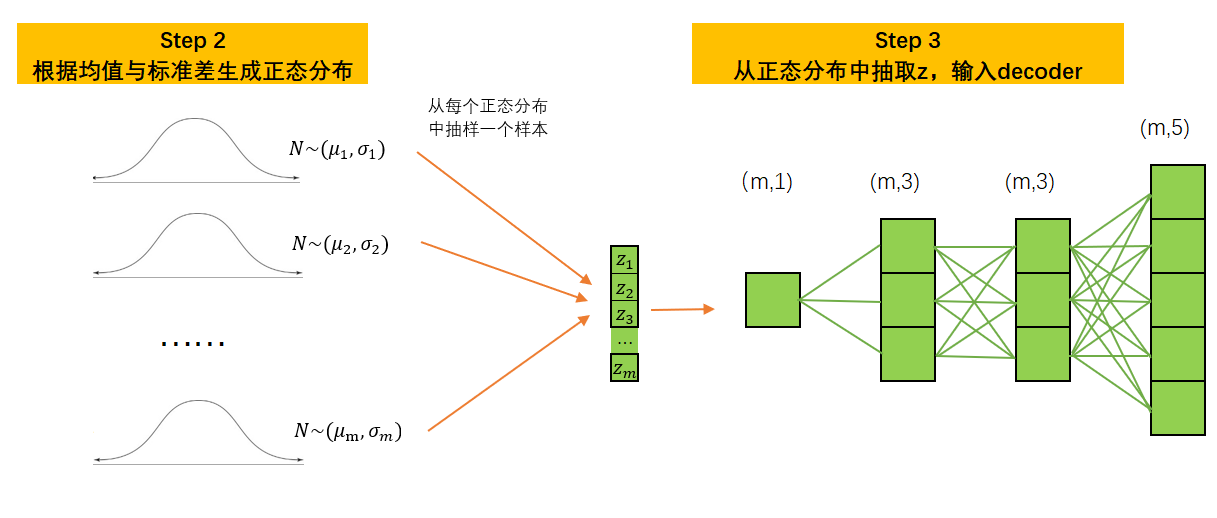
注意,一组均值和标准差只能生成一个正态分布,而一个正态分布中只能抽选一个数字,这是变分自编码器抽样的基本规则。因此,如果每个样本经过Encoder后只输出了一组均值和标准差,那 z \boldsymbol{z} z自然只能有一列,隐式空间的结构只能为(m,1)。此时, z \boldsymbol{z} z就是我们抽出的隐式表示,所以Decoder解码的信息都来源于抽样出的样本向量 z \boldsymbol{z} z。
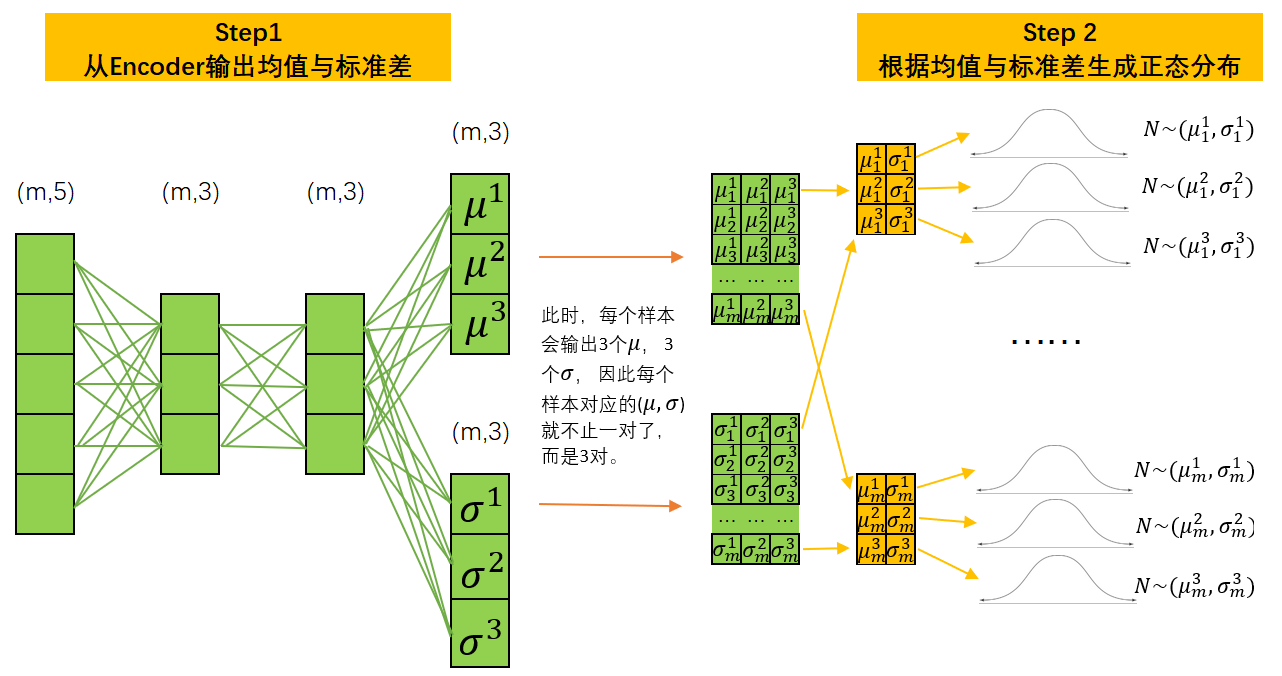
大家或许会感觉到奇怪——难道一个样本还可以有多组均值和标准差吗?当然可以。之前我们强调过,在变分自动编码器的流程当中,均值和标准差都不是通过他们的数学定义计算出来的,而是通过Encoder提炼出来的。这就是说当前的均值和标准差不是真实数据的统计量,而是通过Encoder推断出的、当前样本数据可能服从的任意分布中的属性。我们不可能知道当前样本服从的真实分布的状态,因此这一推断过程自然可以根据不同的规则(Encoder中不同的权重)得出不同的结果。
例如,我们可以令Encoder的输出层存在3个神经元,这样Encoder就会对每一个样本推断出三对不同的均值和标准差。这个行为相当于对样本数据所属的原始分布进行估计,但给出了三个可能的答案。因此现在,在每个样本下,我们就可以基于三个均值和标准差的组合生成三个不同的正态分布了。
每个样本对应了3个正态分布,而3个正态分布中可以分别抽取出三个数字 z z z,此时每个隐式表示 z \boldsymbol{z} z就是一个形如(m,3)的矩阵。将这一矩阵放入Decoder,则Decoder的输入层也需要有三个神经元。此时,我们的隐式空间就是(m,3)。
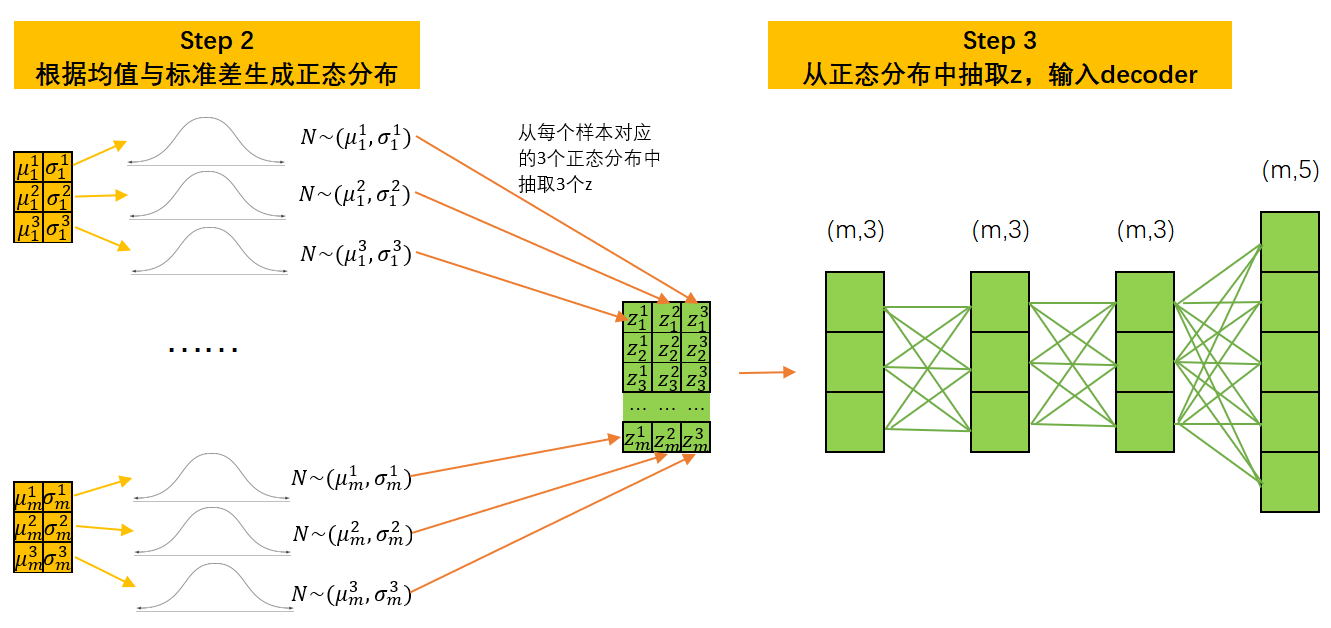
对任意的自动编码器而言,隐式空间越大,隐式表示 z \boldsymbol{z} z所携带的信息自然也会越多,自动编码器的表现就可能变得更好,因此在实际使用变分自动编码器的过程中,一个样本上至少都会生成10~100组均值和标准差,隐式表示 z \boldsymbol{z} z的结构一般也是较高维的矩阵。
现在,回过头来看变分自动编码器的结构,是不是感觉清晰了许多?很明显,在变分自动编码器中,输入层的信息并没有直接传到输出层,而是在中间进行了截断,原始样本的信息被更换成了“与原始样本处于相同分布中的样本的信息”。由于该过程的存在,变分自动编码器有如下的两个特点:
-
无论在训练还是预测过程中,模型都存在随机性,相比之下,大部分带有随机性的算法只会在训练的过程中有随机性,而在测试过程中对模型进行固定。但由于变分自动编码器的“随机性”是与网络架构及输入数据结构都高度相关的随机性,因此当训练数据变化的时候,随机抽样的情况也会跟着变化。
-
可以作为生成模型使用。其他的自动编码器都是在原始图像上进行修改,而变分自动编码器可以从无到有生成与训练集高度相似的数据。由于输入Decoder的信息只是从正态分布中抽选的随机样本,因此其本质与随机数差异不大,当我们训练完变分自动编码器之后,就可以只使用解码器部分,只要对解码器输入结构正确随机数/随机矩阵,就可以生成与训练时所用的真实数据高度类似的数据。
- VAE的损失函数
那这样一个架构的损失函数如何表示呢?变分自动编码器的损失函数是整个架构中的一大难点,其损失函数的推导过程要求我们对概率论、信息论等数学知识有很深的了解,但如果光是解释损失函数本身,其实并没有那么困难。来看,以下是变分自动编码器论文当中所提供的损失函数的公式:
L ( θ , ϕ ; x , z ) = − E z ∼ q ϕ ( z ∣ x ) [ log p θ ( x ∣ z ) ] + D K L ( q ϕ ( z ∣ x ) ∣ ∣ p ( z ) ) L(\theta, \phi;\boldsymbol{x,z}) = \mathbb -E_{z \sim {q_{\phi}\ \boldsymbol{(z|x)}}}\ [\log \color{magenta}{\boldsymbol{p_{\theta}(\boldsymbol{x|z})}}] + D_{KL} \left(\color{blue}{\boldsymbol{q_{\phi}(\boldsymbol{z|x})}} \ || \ \color{red}{\boldsymbol{ p(\boldsymbol{z})}} \right) L(θ,ϕ;x,z)=−Ez∼qϕ (z∣x) [logpθ(x∣z)]+DKL(qϕ(z∣x) ∣∣ p(z))
这一公式符号繁多、眼花缭乱,我们一个个元素来拆解——
公式中的 p p p与 q q q都是分布,一组数据的分布可以由数据本身来表示,也可以由当前数据的均值和标准差来表示。在当前公式当中,两种表示方法我们都有用到。
θ \theta θ, ϕ \phi ϕ是自动编码器要求解的参数,其中 ϕ \phi ϕ是编码器Encoder上各个线性层/卷积层/其它层的参数, θ \theta θ是解码器Decoder上各个线性层/卷积层/其它层的参数。
x x x, z z z是输入架构的数据, x x x是输入编码器Encoder的原始数据, z z z是输入解码器Decoder的原始数据。
了解这些基本信息后,再来看损失函数公式中被重点突出的部分:
-
p ( z ) \color{red}{\boldsymbol{ p(\boldsymbol{z})}} p(z): z z z的分布。在整个变分自动编码器中,所有的 z z z都是从正态分布中抽样出来的,因此 z z z的分布就是完美正态分布,也就是之前我们提到的
Target Distribution目标分布。 -
q ϕ ( z ∣ x ) \color{blue}{\boldsymbol{q_{\phi}(\boldsymbol{z|x})}} qϕ(z∣x):在知晓 x x x的条件下,以 ϕ \phi ϕ为参数推断出的 z z z的分布,即以 x x x为输入,以 ϕ \phi ϕ为参数推断出的 z z z的具体数据。不难发现,这一过程就是Encoder的过程:因此 q ϕ ( z ∣ x ) \color{blue}{\boldsymbol{q_{\phi}(\boldsymbol{z|x})}} qϕ(z∣x)的本质就是Encoder输出层输出的那些均值和标准差,他们代表了我们之前提到的
Actual Distribution。 -
p θ ( x ∣ z ) \color{magenta}{\boldsymbol{p_{\theta}(\boldsymbol{x|z})}} pθ(x∣z):在知晓 z z z的条件下,以 θ \theta θ为参数推断出的 x x x的分布,即以 z z z作为输入,以 θ \theta θ作为参数而推断出的 x x x的具体数据。不难发现,这一过程就是Decoder的过程,所以 p θ ( x ∣ z ) \color{magenta}{\boldsymbol{p_{\theta}(\boldsymbol{x|z})}} pθ(x∣z)实际上是直接指向Decoder的输出。而在公式前的脚标中,特地标注了数据 z z z的来源,不难发现, z ∼ q ϕ ( z ∣ x ) z \sim {q_{\phi}\ \boldsymbol{(z|x)}} z∼qϕ (z∣x)说明 z z z是Encoder部分输出的结果,更加佐证了 p θ ( x ∣ z ) \color{magenta}{\boldsymbol{p_{\theta}(\boldsymbol{x|z})}} pθ(x∣z)是decoder过程的结果。
将这三个元素拆解后,我们的损失函数可以被改写成:
L ( θ , ϕ ; x , z ) = − E q [ log ( D e c o d e r 的输出分布 ) ] + D K L ( E n c o d e r 的输出分布 ∣ ∣ 预设的正态分布 ) L(\theta, \phi;\boldsymbol{x,z}) = \mathbb -E_q[\log (\color{magenta}{Decoder的输出分布})] + D_{KL} \left(\color{blue}{Encoder的输出分布} \ || \ \color{red}{预设的正态分布} \right) L(θ,ϕ;x,z)=−Eq[log(Decoder的输出分布)]+DKL(Encoder的输出分布 ∣∣ 预设的正态分布)
在这样的状态下,再来解读这一损失函数就容易多了。
- 损失函数的后半部分
先来看后半部分,这是一个KL散度的计算公式,在原始论文当中被称之为“隐式损失”(Latent Loss)。KL散度是衡量两组数据分布差异的衡量指标,也是衡量分布A在变化成分布B过程中损失的信息量的指标,因此当两组数据的分布越接近时,KL散度就会越小,反之KL散度会越大。
在我们的损失函数当中,很明显KL散度衡量的是Encoder的输出与预设的正态分布之间的差异,这说明损失函数希望Encoder输出的结果越接近正态分布越好,因此在最初介绍自动变分编码器流程时,我们才会认为“变分自动编码器中的编码器会尽量将样本 i i i所携带的所有特征信息 X i X_i Xi的分布转码成类高斯分布 d i d_i di”。
这一过程其实并不难理解:在变分自动编码器的Encoder中,我们从原始数据上推断出均值与标准差,并且用这些均值和标准差构筑正态分布,再从正态分布中抽取样本输入Decoder。毫无疑问的,当Encoder输出的数据分布越接近正态分布时,我们所构筑的正态分布才会越靠近原始数据中的信息,从这样的正态分布中抽取的样本才会更接近真实的数据样本。因此KL散度是为了逼迫Encoder向着正态分布方向解码原始数据而存在的,损失函数中的惩罚项。
一般来说,当我们将从样本生成的均值与标准差带入后,KL散度可以写作:
K L i = − 1 2 ∑ j = 1 K ( 1 + l o g ( σ j 2 ) − σ j 2 − μ j 2 ) KL_i = -\frac{1}{2}\sum^K_{j=1} \left(1+log(\sigma_j^2) - \sigma_j^2 -\mu_j^2 \right) KLi=−21j=1∑K(1+log(σj2)−σj2−μj2)
这就是我们在实际执行代码时所写的公式。其中 K K K指的是对一个样本生成了 K K K组均值和标准差, j j j指的是当前均值和标准差的具体组数,对任意样本 i i i,我们需要将全部的 K K K组均值和标准差进行加和后计算。
- 损失函数的前半部分
L ( θ , ϕ ; x , z ) = − E q [ log ( D e c o d e r 的输出分布 ) ] + D K L ( E n c o d e r 的输出分布 ∣ ∣ 预设的正态分布 ) L(\theta, \phi;\boldsymbol{x,z}) = \mathbb -E_q[\log (\color{magenta}{Decoder的输出分布})] + D_{KL} \left(\color{blue}{Encoder的输出分布} \ || \ \color{red}{预设的正态分布} \right) L(θ,ϕ;x,z)=−Eq[log(Decoder的输出分布)]+DKL(Encoder的输出分布 ∣∣ 预设的正态分布)
现在我们已经了解了损失函数的后半部分了,那它的前半部分是什么呢?虽然无法从肉眼上明显地看出来对Decoder的输出分布求对数是怎样的含义,但变分自动编码器的终极目标依然是输出与原始数据高度相似的数据,因此变分自动编码器的损失函数中必然包含重构损失Reconstruction Loss这一衡量输入与输出差异的部分。因此很明显,log(Decoder输出的分布)就是重构损失。这一形式有些类似于二分类交叉熵中所表示的 y l o g p ( x ) ylogp(x) ylogp(x),只不过我们现在是无监督算法,并无真实标签罢了。在实际的代码执行过程中,我们一般使用MSE或者二分类交叉熵损失的均值来替代上述公式。
因此,真正在反向传播中使用的损失函数是:
L ( θ , ϕ ) = − 1 m ∑ i = 1 M ( x i − x i ^ ) 2 − 1 2 m ∑ i = 1 M ∑ j = 1 K ( 1 + l o g ( σ j 2 ) − σ j 2 − μ j 2 ) L(\theta, \phi) = -\frac{1}{m}\sum_{i=1}^M(x_i - \hat{x_i})^2 - \frac{1}{2m}\sum_{i=1}^M\sum_{j=1}^K \left(1+log(\sigma_j^2) - \sigma_j^2 -\mu_j^2 \right) L(θ,ϕ)=−m1i=1∑M(xi−xi^)2−2m1i=1∑Mj=1∑K(1+log(σj2)−σj2−μj2)
- 两个正态分布散度的计算
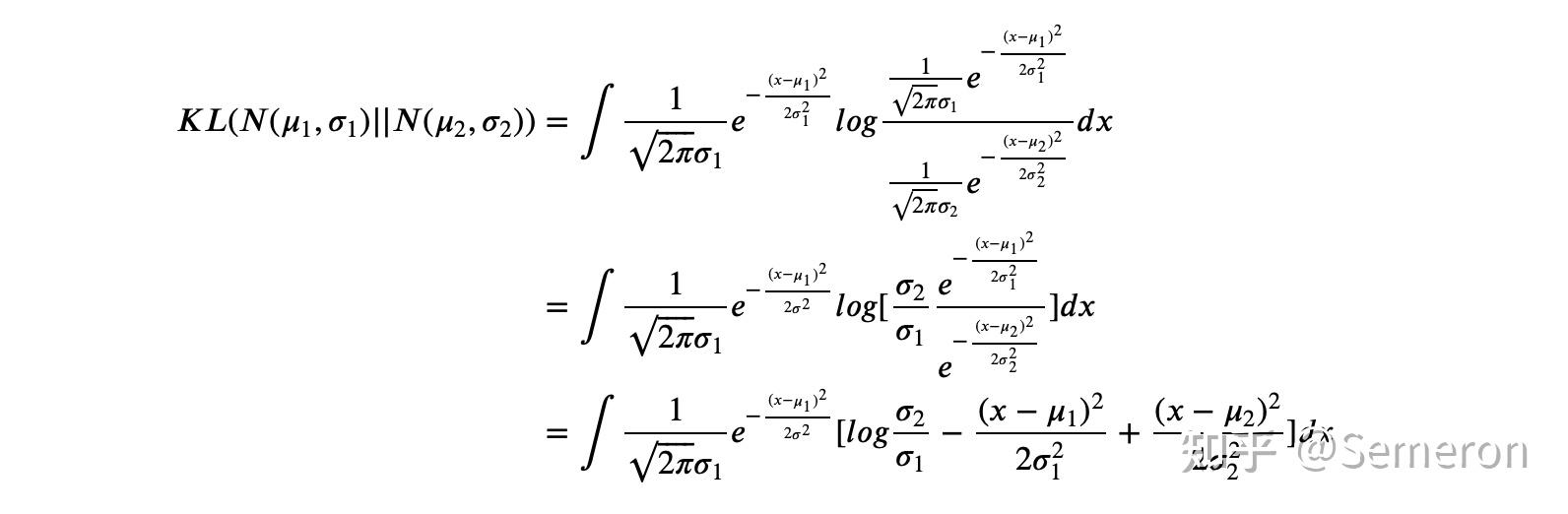
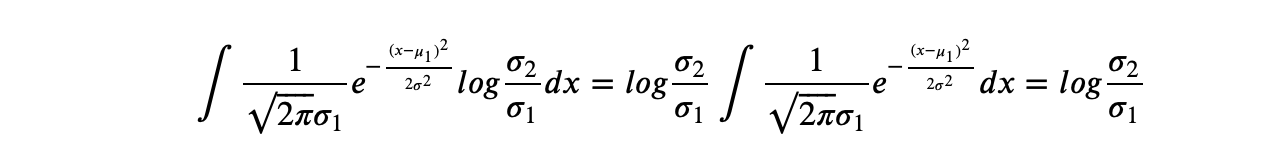
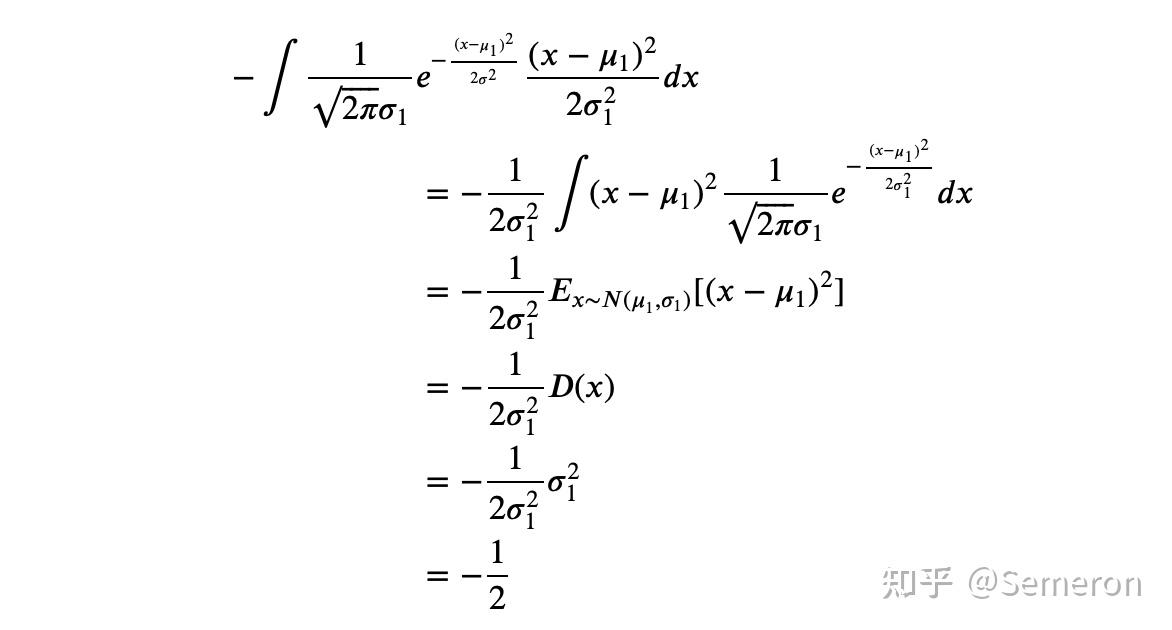

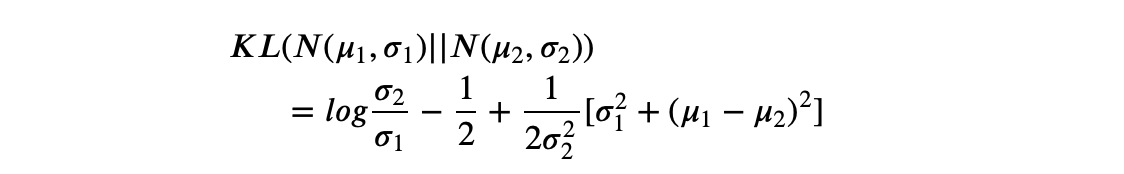

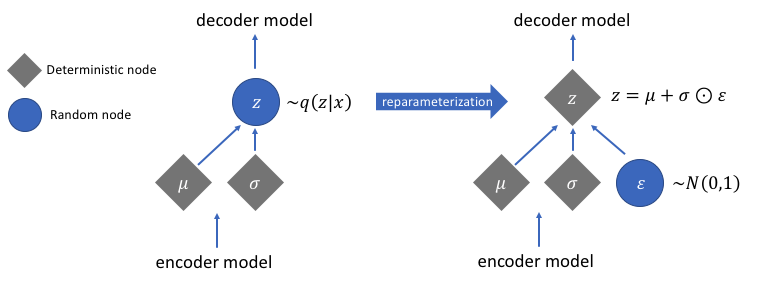
- 重参数化技巧(reparameterization trick)
现在我们已经了解了变分自动编码器的基本流程和训练目标,那我们是否可以尝试着手动去实现变分自动编码器了呢?有一个隐藏的陷阱还没有被我们注意到,那就是由于抽样流程的存在,架构中的数据流是断裂的,因此反向传播无法进行。反向传播要求每一层数据之间必有函数关系,而抽样流程不是一个函数关系,因此无法被反向传播。为了解决这一问题,变分自动编码器的原始论文提出了重参数化技巧,这一技巧可以帮助我们在抽样的同时建立 z z z与 μ \mu μ和 σ \sigma σ之间的函数关系,这样就可以令反向传播顺利进行了。
先来复习一下原本的抽样流程:对任意样本 i i i,我们首先需要从Encoder处获得 ( μ i , σ i ) (\mu_i,\sigma_i) (μi,σi),然后基于这两个元素构建正态分布,之后从构建好的正态分布中进行抽样。如果使用简单的numpy代码来表示这个过程,则有:
import numpy as np
#获取三组mu与sigma
mu = [3,2,5]
sigma = [5,4,7]
#以mu和sigma为基准构建三组正态分布
np.random.seed(420)
d1 = np.random.normal(loc=mu[0],scale=sigma[0],size=(100,))
d2 = np.random.normal(loc=mu[1],scale=sigma[1],size=(100,))
d3 = np.random.normal(loc=mu[2],scale=sigma[2],size=(100,))
#抽样
d1[50]
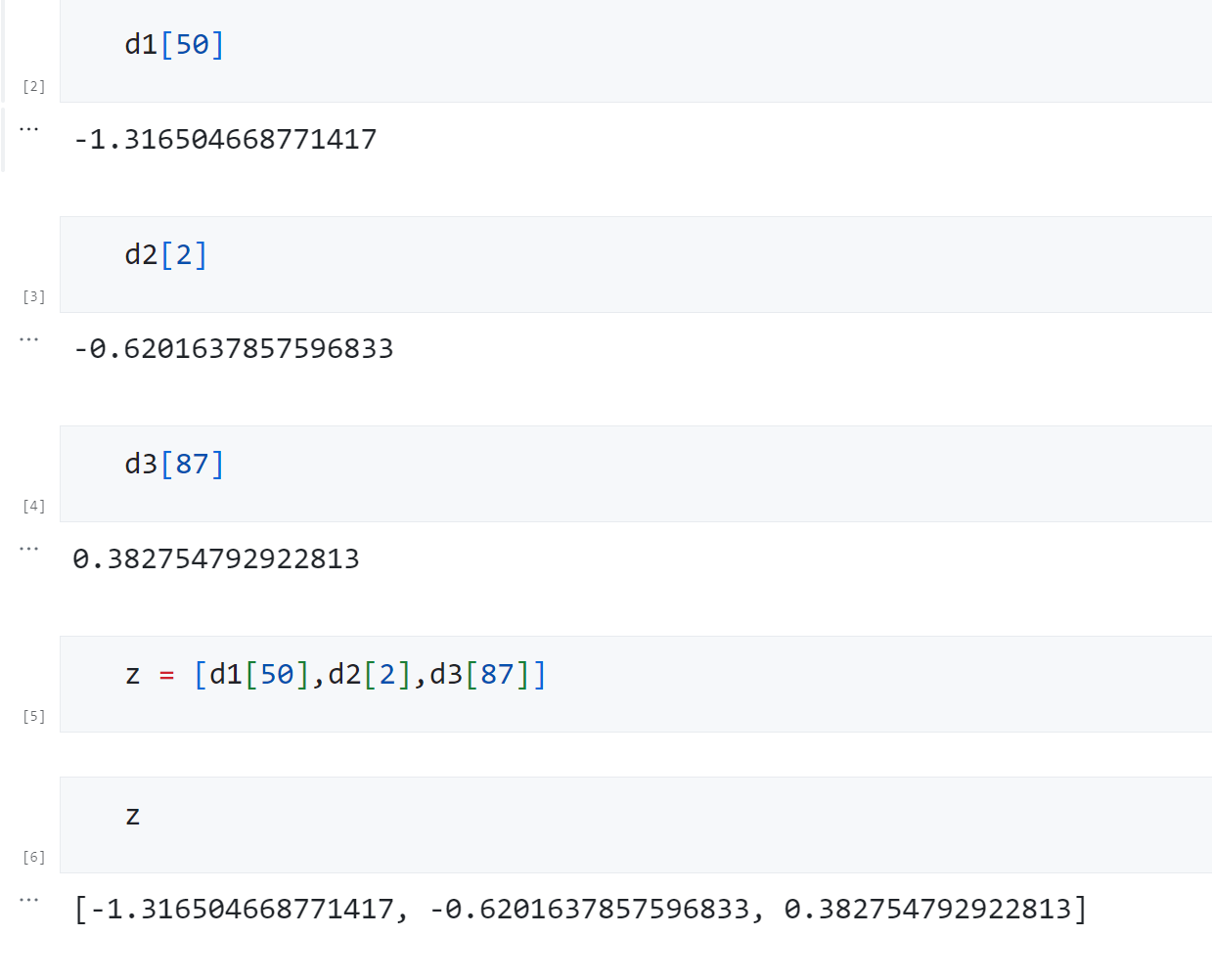
抽出的三个数字最终组合为 z z z被输入Decoder。在这个流程中,我们如何才能够建立 σ \sigma σ、 μ \mu μ、z之间的函数关系呢?答案是利用0-1标准化。0-1标准化是一个非常简单的操作,普通的正态分布 N ∼ ( μ , σ ) N \sim (\mu,\sigma) N∼(μ,σ)被0-1标准化后都可以变为均值为0,标准差为1的标准正态分布 N ∼ ( 0 , 1 ) N \sim (0,1) N∼(0,1)。假设 z z z满足任意正态分布, z ′ z' z′是0-1标准化后的结果,则有:
z ′ = z − μ σ \begin{aligned} z' &= \frac{z - \mu}{\sigma} \end{aligned} z′=σz−μ
不难发现,当我们知道 z z z而求解 z ′ z' z′时,这一等式就是 z ′ z' z′与均值标准差之间的函数关系,因此我们也可以轻松地逆转这个操作(“范标准化”),让上述式子变成 z z z与 σ \sigma σ和 μ \mu μ之间的函数关系:
z ′ = z − μ σ z = z ′ ∗ σ + μ \begin{aligned} z' &= \frac{z - \mu}{\sigma} \\ z &= z' * \sigma + \mu \end{aligned} z′z=σz−μ=z′∗σ+μ
如此,我们就建立了 z z z与 σ \sigma σ和 μ \mu μ之间的关联,并且这个式子与变分自动编码器中的流程十分契合:我们总是先知道 μ \mu μ和 σ \sigma σ,才能够求解出具体的 z z z的。但是,此时这个函数关系中多出了一个在变分自动编码器中不曾存在的分布:标准正态分布 z ′ z' z′,同时抽样过程也不复存在,我们应该如何将之前的流程与该函数关系结合呢?答案是转变思路,先从标准正态分布中抽样出 z i ′ z'_i zi′、再使用抽样出的结果、固定的均值和标准差计算出 z i z_i zi。
在数学上,从 N ∼ ( μ , σ ) N \sim (\mu,\sigma) N∼(μ,σ)直接抽样 z i z_i zi的行为完全等同于从标准正态分布 N ∼ ( 0 , 1 ) N \sim (0,1) N∼(0,1)中抽样 z ′ z' z′后、再对其进行反标准化的行为。我们可以使用代码来验证一下:
#获取mu与sigma
mu = [3,2,5]
sigma = [5,4,7]
#建立三个标准正态分布
np.random.seed(420)
sd1 = np.random.normal(loc=0,scale=1,size=(100,))
sd2 = np.random.normal(loc=0,scale=1,size=(100,))
sd3 = np.random.normal(loc=0,scale=1,size=(100,))
#建立z与mu和sigma之间的函数关系
#求解z
z1 = sd1[50] * sigma[0] + mu[0]
z1
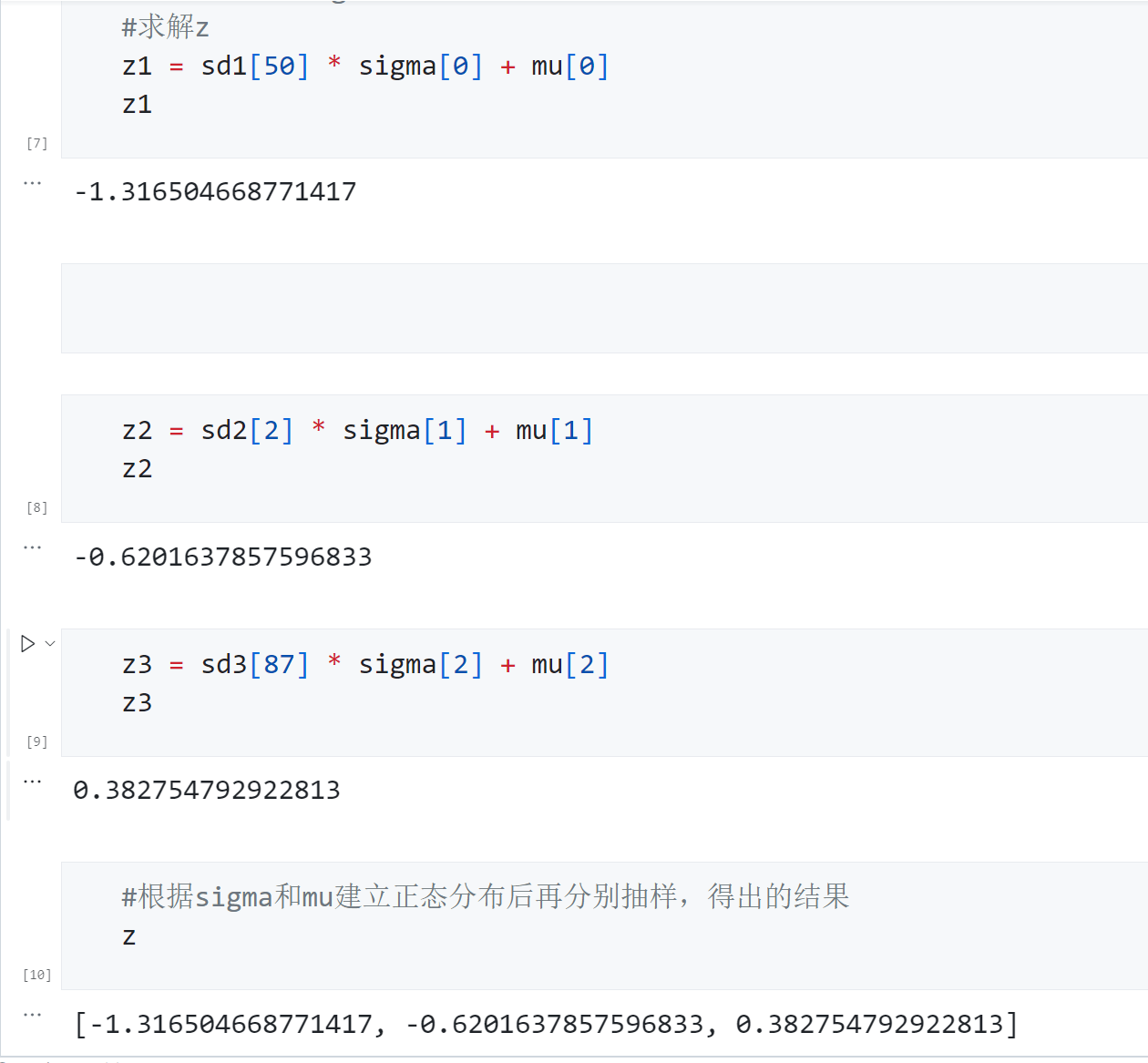
不难发现,两种操作得出的数据完全一致,但在第二种操作当中,对标准正态分布进行抽样后,只需要向函数 z z z提供抽样出的基本数据,就可以让 μ \mu μ和 σ \sigma σ被当做函数z的参数参与到反向传播的计算当中,而对标准正态分布进行抽样的这一无法使用函数表达的行为,就被排除在了计算图之外。如此,就可以对变分自动编码器进行反向传播了。
















 285
285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









