







1.简述
计算机视觉 ≠ 卷积神经网络
在过去十年,人们常常认为计算机视觉是以深度学习和卷积神经网络(Convolutional Neural Networks, CNN)为核心研究领域。事实上,早在深度学习兴起之前,计算机视觉就是一个理论成熟、内容繁多的跨学科领域。
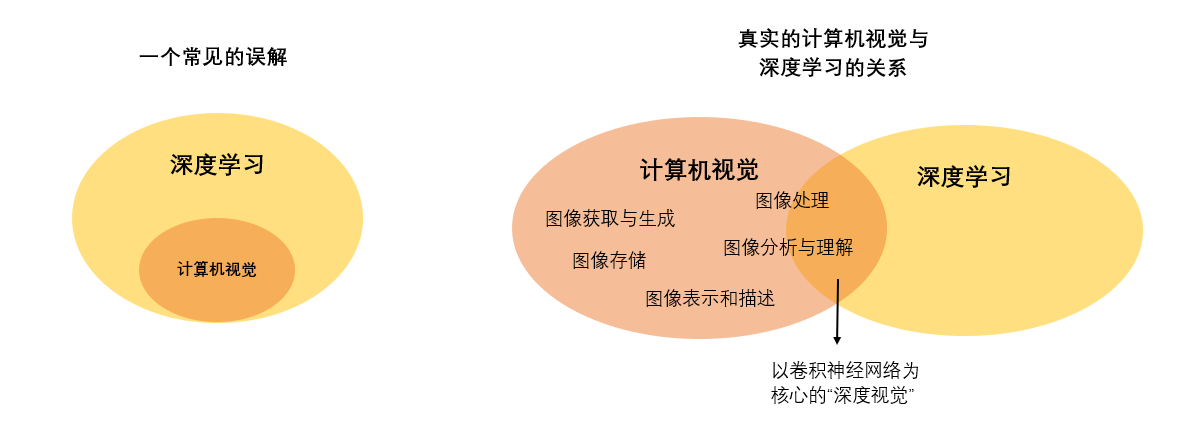
计算机视觉有完备的知识体系,它的内容包括了摄像设备性能、成像原理等图像获取和生成技术、也包括视频特效、3D、图像复原等早就被广泛应用的视频/图像处理技术,同时还包括图像分割、图像识别等让计算机分析、理解图像的技术。其中,图像处理也叫做“图像特征提取”,这项技术高度依赖数学、几何、光学等基础学科,与信号处理等学科有较多交叉,是计算机视觉中非常关键的领域。21世纪初,从事计算几何、计算机图形学、图像处理、普通成像、机器人等工作的研究人员或技术人员都需要学习计算机视觉丰富的经典理论,直到今天,许多视觉项目也是从“硬件自动采集图像”开始。在人工智能兴起之后,人们发现传统计算机视觉中图像处理、图像分析领域的许多工作都可以由神经网络来完成,并且当数据量和计算资源足够时,神经网络往往能比传统方法取得更好的效果。于是人工智能与计算机视觉的交叉学科深度视觉诞生了,它是使用深度学习相关的技术、让计算机从图像或图像序列中获取信息并理解其信息的学科。而其中最令人瞩目的研究成果就是以卷积神
经网络为核心的一系列模型架构。因此,包括我们的课程在内的众多计算机视觉课程,应该被称之为“深度视觉”课程才对。
但令人惊讶的是,在卷积神经网络压倒性的效果和性能下,行业并没有放弃传统计算机视觉,整个行业的人才标准也偏向于视觉人才与人工智能人才的融合,而不是传统视觉人才被“替代”。如今,计算机视觉工程师都必须掌握神经网络,但同时,也还是需要学习传统视觉相关的内容,而只使用深度学习方法、不使用传统计算机视觉方法的企业和研究机构并不太多。

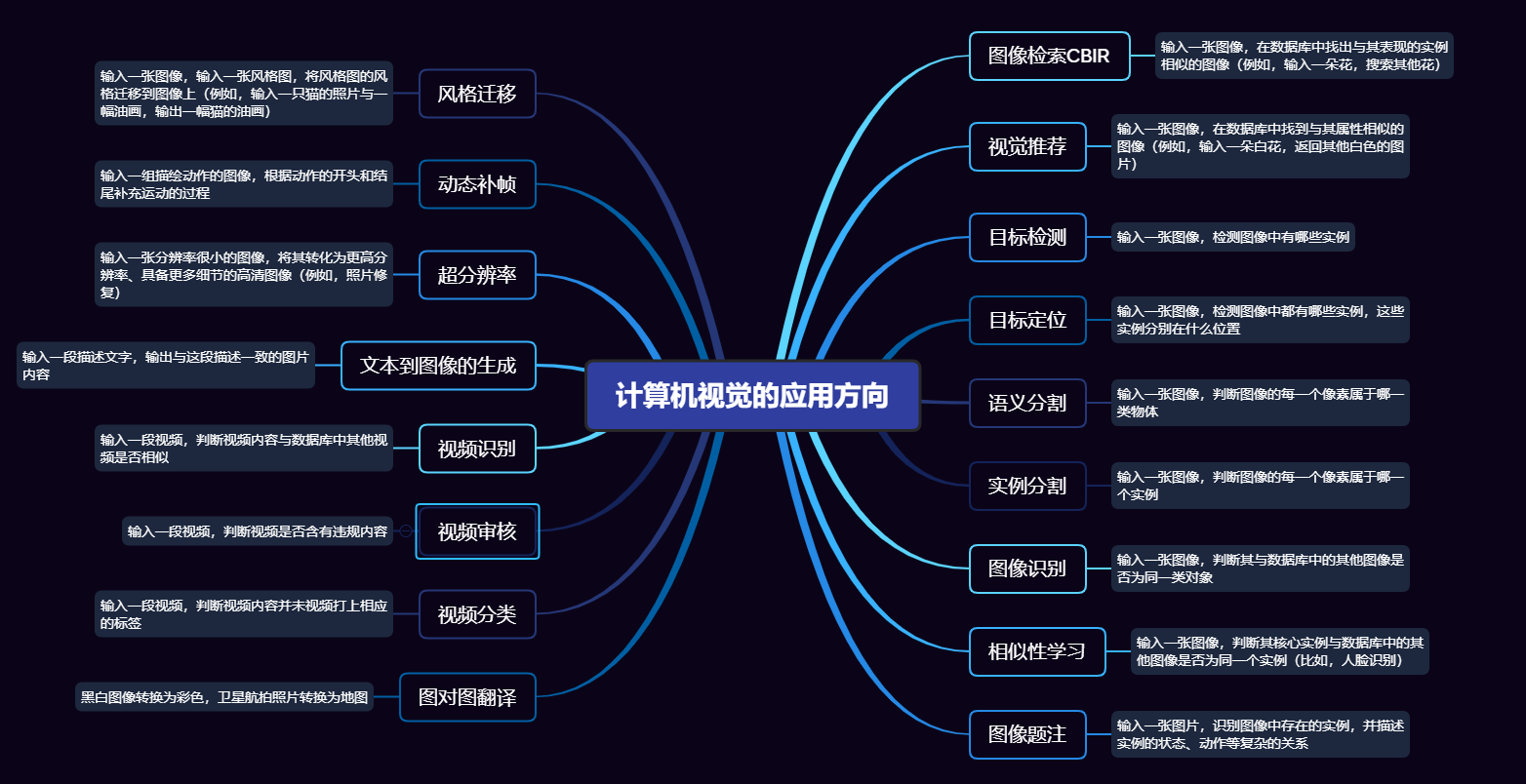
二、从卷积到卷积神经网络
1 图像的基本表示
深度视觉是处理图像的学科,因此我们需要从图像本身开始说起。来看这张孔雀图像。

import numpy as np
import matplotlib.pyplot as plt
import cv2
img = cv2.imread('./data/picture/blue-peacock.jpg')
img
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) #转换方式
# OpenCV在读取图像时会默认图像通道的顺序是BGR
img.shape
#展示图片
plt.figure(dpi=150) #画布,dpi是分辨率
plt.imshow(img)
plt.axis('off'); #不显示坐标轴
在之前的课程中,我为大家展示过图像数据在计算机中的基本结构。首先,每张图像都是以一个三维Tensor或者三维矩阵表示,其三个维度分别是(高度 height,宽度 width,通道 channels)。高度和宽度往往排列在一起,一般是先高后宽的顺序,两者共同决定图像的尺寸大小。如上图,高度1707为则说明图像在竖直方向有1707个像素点(有1707列),同理宽度则代表水平方向的像素点数目(有2560行),因此如上的孔雀图总共有1707*2560 = 4,369,920个像素点。
通道是单独的维度,通常排在高度宽度之后,但也有可能是排在第一位。它决定图像中的轮廓、线条、色彩,基本决定了图像中显示的所有内容,尤其是颜色,因此又叫做色彩空间(color space)。
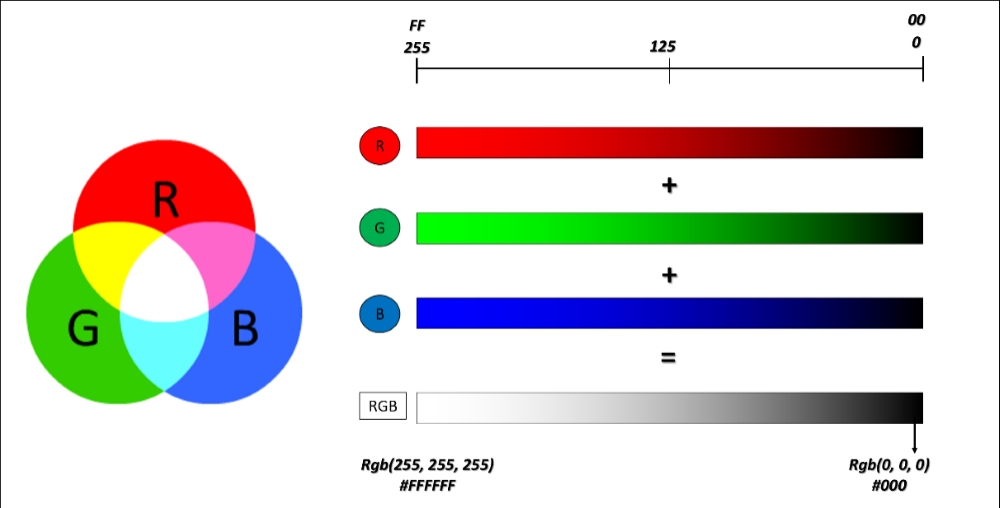
怎么理解通道呢?你可能在很年幼的时候就学过一些基本的色彩知识(感谢九年义务教育中的美术课),例如,自然界中的颜色都是由“三原色”红黄蓝构成的,将红色和蓝色混在一起会得到紫色,将红色和黄色混在一起会得到橙色,白色的阳光可以经由三棱镜分解成七彩的光谱等等。计算机的世界中的颜色也是由基本颜色构成的,在计算机的世界里,用于构成其他颜色的基础色彩,就叫做“通道”。
我们最常用的三种基本颜色是红绿蓝(Red, Green, Blue, 简写为RGB),所以最常用的通道就是RGB通道。我们通过将红绿蓝混在一起,创造丰富的色彩。例如,上面的孔雀图,其实是下面三张红、绿、蓝三色的图像叠加而成。

不难注意到,通道就是和原图尺寸一致、像素点数量一致的、只能够显示其通道颜色的图像。例如,红色通道就只能显示红色,绿色通道就只能显示绿色,蓝色同理。

在通道的每一个像素点上,都有[0,255]之间的整数值,这些整数值代表了“该通道上颜色的灰度”。在图像的语言中,“灰度”就是明亮程度。数字越接近255,就代表颜色明亮程度越高,越接近通道本身的颜色,数字越接近0,就代表颜色的明亮程度越弱,也就是越接近黑色。(仔细观察孔雀脖子的部分,孔雀脖子在图像上是蓝色的,这种蓝色主要由蓝色通道和绿色通道构成,几乎没有任何红色通道的元素,因此在红色通道的图片中,孔雀脖子几乎都是黑的。)
在图像的矩阵中,我们可以使用索引找出任意像素的三个通道上的颜色的明度,例如,对于第0行、第0列的样本而言,可以看到一个三列的矩阵,这三列就分别代表着红色、绿色、蓝色的像素值。当三个值都不为0时,这个像素在三个通道上都有颜色。相对应的,最纯的红色会显示为(255,0,0),最纯的蓝色就会显示为(0,0,255),绿色可以此类推。当像素值为(0,0,0)时,这个像素点就为黑色,当像素值为(255,255,255),像素点就为白色。通道上像素的灰度,也就是矩阵中的值几乎100%决定了图像会呈现出什么样子。

在图像的世界中有许多“通道”类型,就和计算机世界有许多编码类型一样,较为常见的通道有以下几种:
灰度通道:灰度在计算机视觉中是指“明暗程度”,而不是指“灰色”,因而灰度通道也不是指图像是灰色的通道,而是只有一种颜色的通道,同理,灰度图像是只有一个通道的图像。所以RGB通道中的任意一个通道单独拿出来之后,都可以用灰度(明暗)来显示。就像我们在Fashion-MNIST数据集中所见到的,灰度图像的shape最后一列为1,索引出来的值中只有一个数字,这个数字就是这种唯一颜色的明度。当你看见图像的通道数为1,无论可视化之后图像显示什么视觉颜色,它都只是表示单一颜色的明度而已。(没有人怀疑过为什么fashion-MNIST中的图绘制出来是黄绿色的吗?你现在了解,其实蓝绿色也只是明度的一种表示)。

RGB色彩空间:数字世界最常见的彩色通道,分别表示红、绿、蓝三种电子成像的基本颜色。
CMYK色彩空间:用于彩色打印机成像的通道,由青色(Cyan)、品红(Magenta)、黄色(Yellow)和黑色(Black)构成,因此是四维通道,在图像结构中会显示为(高度,宽度,4)。
HSV(或HSL)色彩空间:HSV通道是为人们描述和解释颜色而创建的,H代表色相,S代表饱和度,V代表亮度。
以上三种空间可以自由切换(会产生数据损失),在OpenCV中也有支持切换的函数可以调用。在计算机视觉中,我们可能遇见各种通道类型的图片,当我们需要对图像进行特定操作时,我们必须了解这些通道并了解如何在他们之间进行转换。

另一种非常常见的色彩空间是RGBA,它也拥有四维通道,分别是(红色,绿色,蓝色,透明度alpha)。透明度alpha的取值范围在0-1之间。当一个像素的RGB显示为(0,255,0)时,则说明这个像素里是明度最高的绿色,但加上透明度之后,色彩就会变得“透明”。RGBA可以提供更丰富的色彩样式,让图像的色彩变得更加绚丽。

2 OpenCV令像素变化来改变图像
一张图像显示什么内容是由通道中的像素值决定的,只要能够操作像素,就能够改变图像,这是图像能够被“处理”的基本条件。在这一节,我们就使用OpenCV来对图像进行一些改变。首先,先导入一张自己的图像来看看,大家可以根据自己的喜好导入相应的图像。
import numpy as np
import cv2
import matplotlib.pyplot as plt
#读取计算机中的图像
img = cv2.imread('D:/cv/peacock/blue-peacock.jpg')
#OpenCV默认读取后的图像通道是BGR,因此我们需要将图像的通道顺序转换为RGB
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
#也可以使用步长为-1的逆序索引来进行转换
#img = img[:,:,::-1]
#检查图片的结构
img.shape
#展示图片
plt.figure(dpi=150) #画布,dpi是分辨率
plt.imshow(img)
plt.axis('off'); #不显示坐标轴
#数值类型,uint8是专门为图像像素设置的数值类型,覆盖0-255之间的整数
img.dtype
#uint8类型对图像数据的保护
a = np.array([0,1,255],dtype="uint8")
a
a+10
a-10
#你发现了什么?在unit8数据下,线性变换不是单调的,而是循环的
#但我们不希望图像像素是循环的!当我们对图像进行调整时,我们可以允许它因为太暗所以变黑,因为太亮所
以变白,但不能允许它因为“太亮了超出数字范围,于是变黑”,这不符合我们对图像的认知逻辑。
#因此,在进行任何线性变换之前,都需要将uint8替换掉,我们可以由以下两种操作:
img = img*1.0
#或者
img = img/255
#所有像素值都在0-255范围内,通过除以255,我们将图像归一化,并让像素的范围被压缩到[0,1]之间
img.dtype
'''
这样做会产生几个变化
首先,图像的格式会从uint8变为float64,不再受到uint8类型的限制,可以允许负数、小数、超出255的整
数,这让图像的变化变得单调,我们在进行线性变换时不用“小心翼翼”了
(当然,这并不代表我们不需要把数字控制在[0,255]内了,为了让图像显示正常,我们将会使用np.clip来
控制图像的像素)
其次,图像的计算会变得更快
但需要注意的是,float64将不能够在被OpenCV进行转换或其他处理
因此,只有当我们需要手动操作图像的像素时,我们才会使用归一化
'''
现在我们在图像上做一些改变。之前我们说过,像素值越接近255,就表示图像的“明度”越高,像素值越越接近0,就表示图像会变得越暗,当我们对图像归一化后,像素值越接近1就越亮,越接近0就越暗。所以我们可以通过对像素值做线性变换,来调整图像的“明暗”程度。
#调亮画面
img_ = np.clip(img + 100/255,0,1) #np.clip是一个抹掉范围外值的函数
plt.figure(dpi=100)
plt.imshow(img_)
plt.axis('off');
a = [-2,0.5,1,1.5]
np.clip(a,0,1)
#调暗画面
img_ = np.clip(img - 100/255,0,1)
plt.figure(dpi=100)
plt.imshow(img_)
plt.axis('off');
#让画面更鲜艳
img_ = np.clip(img*2,0,1) #原本就很大的值会增长得更快,因此原本就很鲜艳的颜色会变得更加鲜
艳,增加对比度
plt.figure(dpi=100)
plt.imshow(img_)
plt.axis('off');
我们还可以将图像切换到其他色彩空间,来调整色相和饱和度,比如:
img = cv2.imread('D:/cv/peacock/blue-peacock.jpg')
#OpenCV默认读取后的图像通道是BGR,为了调整饱和度,我们直接将通道转换为HSV
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(img_hsv)
#这里分解出的是uint8,要在uint8上进行数值操作则必须先更换为浮点数
#h += np.clip(s*1.0+100,0,255).astype("uint8") # 色相
#s += np.clip(s*1.0+100,0,255).astype("uint8") # 饱和度
#v += np.clip(s*1.0+100,0,255).astype("uint8") # 亮度
final_hsv = cv2.merge((h, s, v))
#为了绘图,这里是转回RGB,而不是BGR
img_s = cv2.cvtColor(final_hsv, cv2.COLOR_HSV2RGB)
plt.figure(dpi=100)
plt.imshow(img_s)
plt.axis('off');
你发现了吗?在掌握了一些浅层图像原理之后,我们就可以通过改变像素值来改变图像的模样,这再次证明了,通道上像素的灰度,也就是张量中的值几乎100%决定了图像会呈现出什么样子。因此,只要给与[0,255]之间的值,令其结构形似一张图像(高,宽,3),我们甚至可以自己“瞎编”出一张图像来,所以任意矩阵都可以被以图像的方式进行可视化。
pic = np.random.randint(0,255,size=(300,300,3))
plt.figure(dpi=100)
plt.imshow(pic)
plt.axis('off');


3 卷积操作

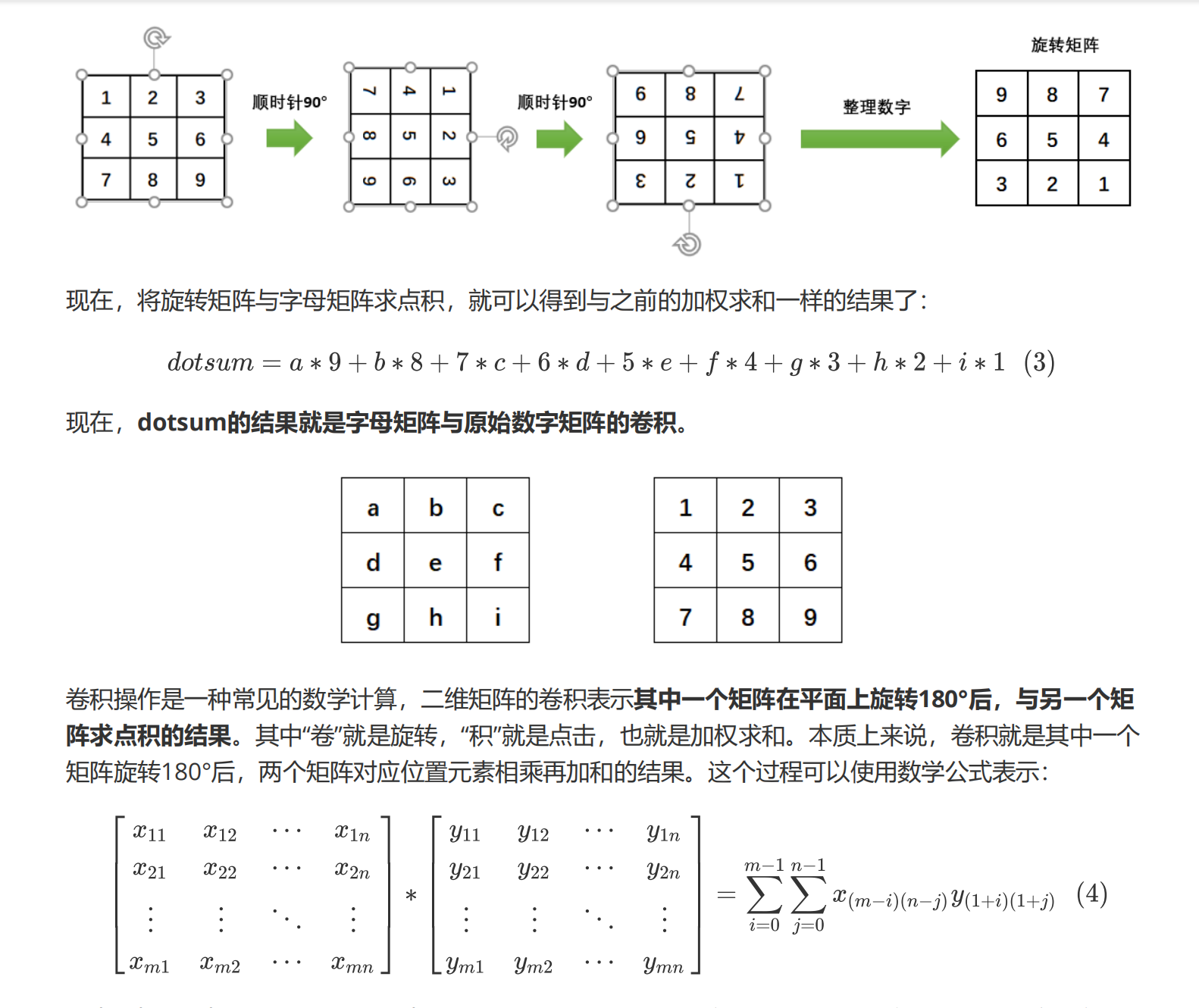

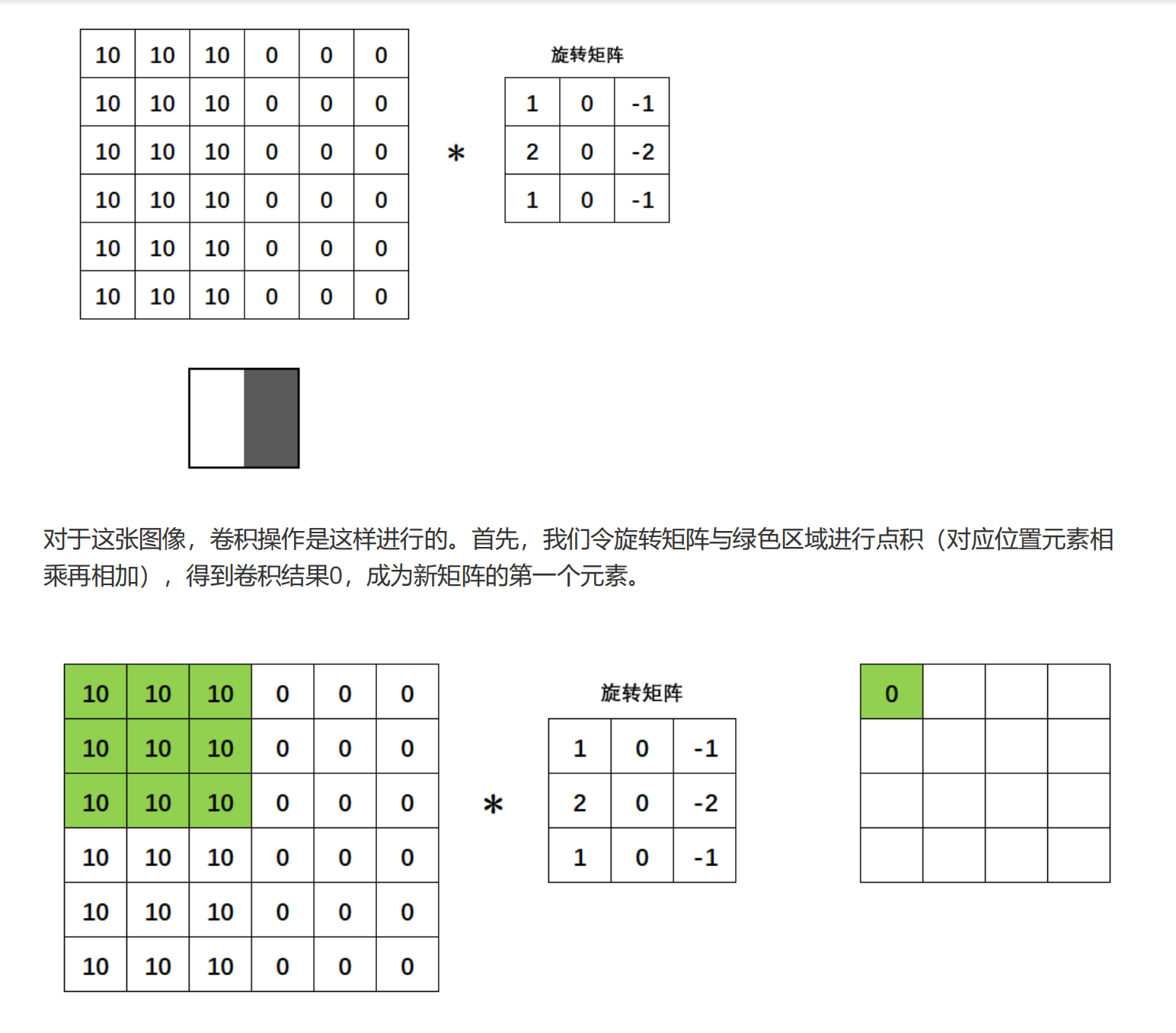
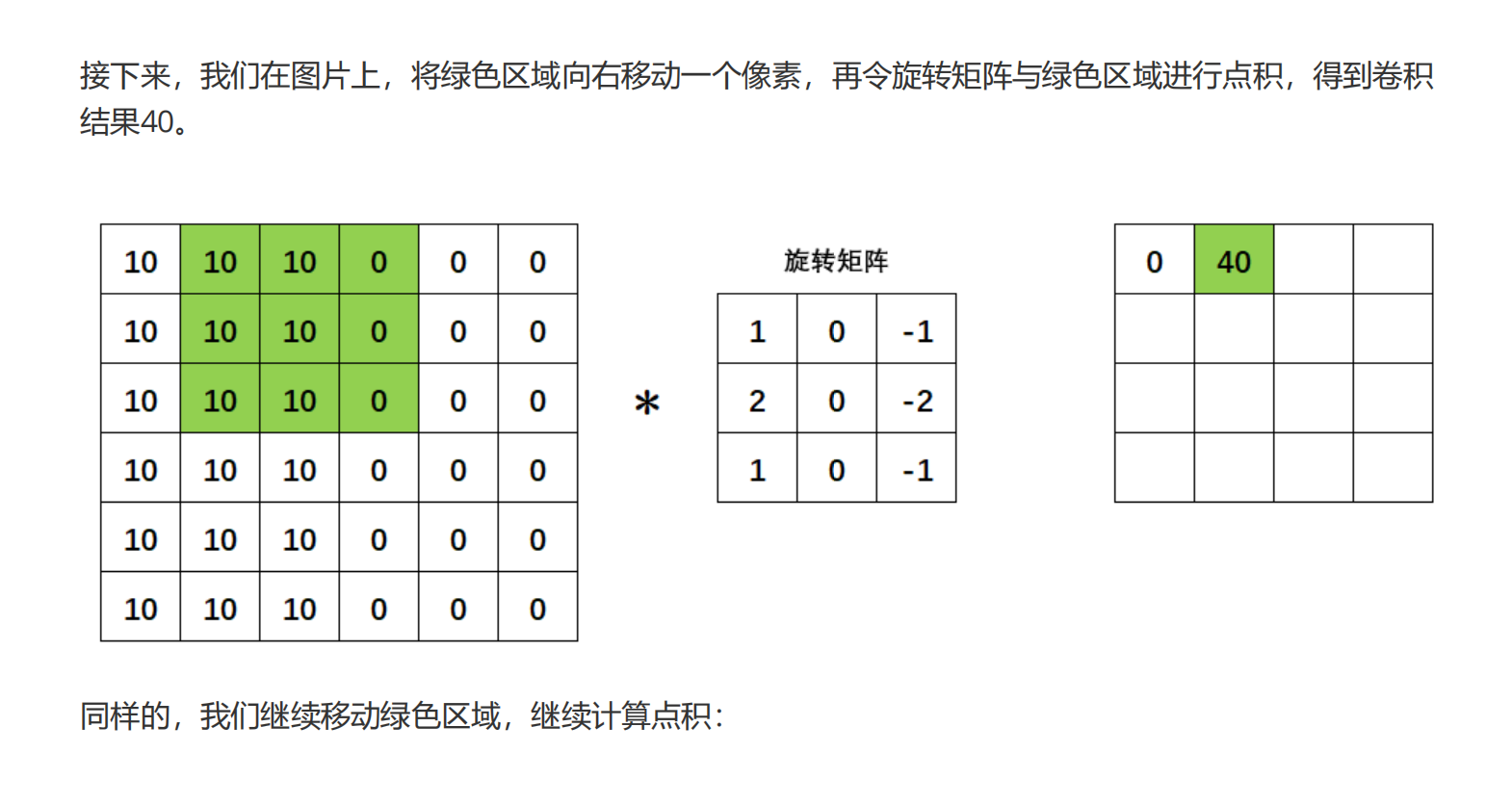
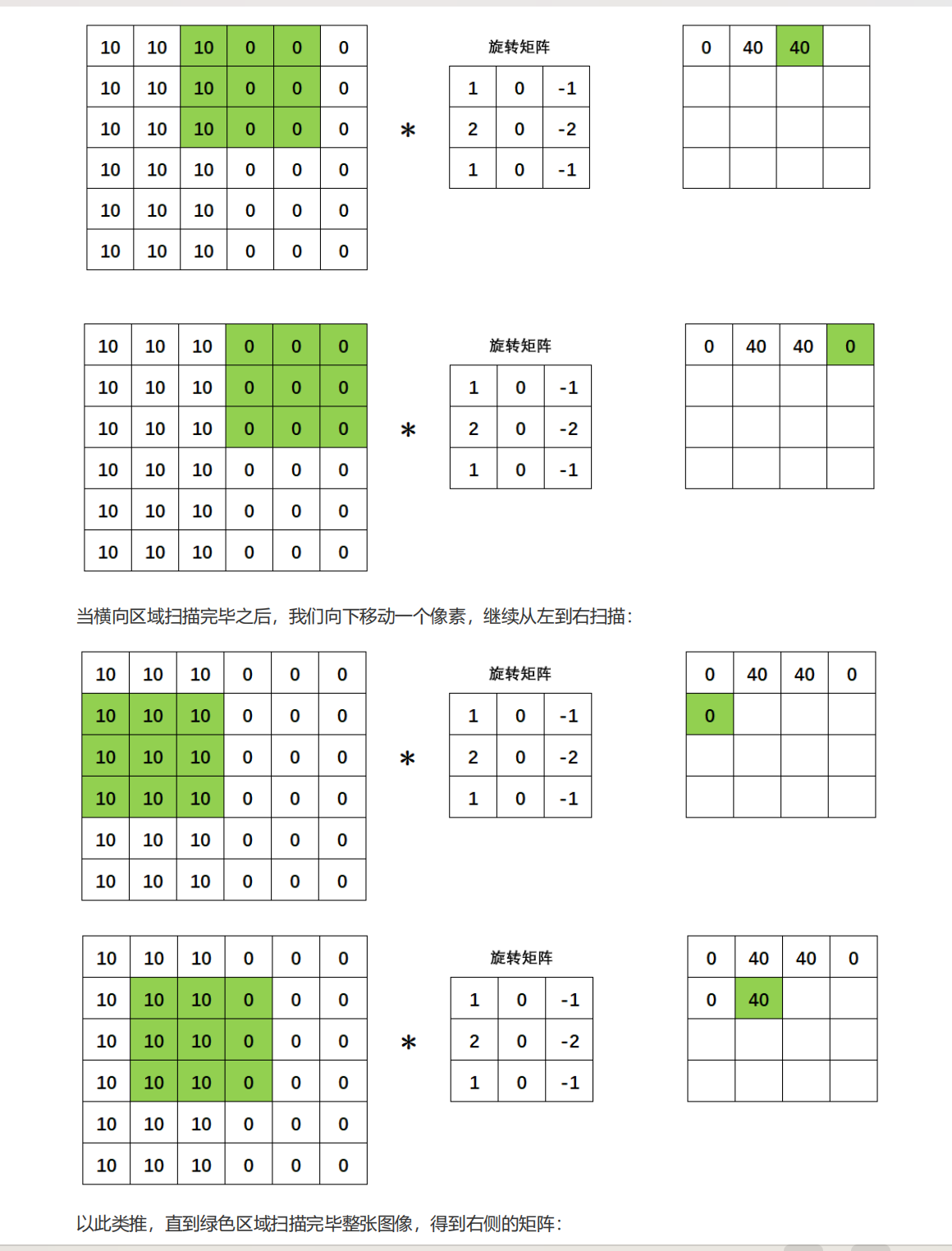
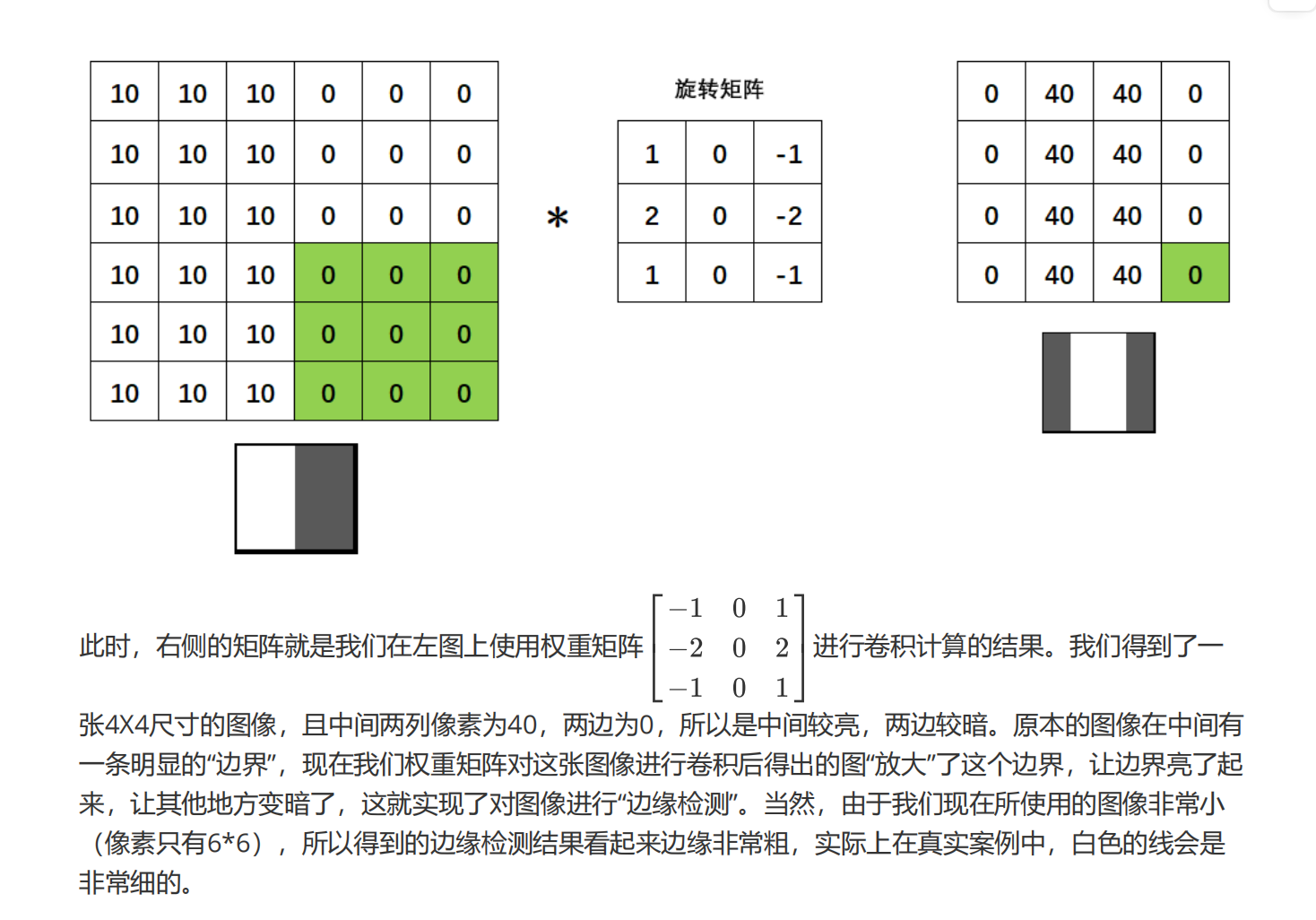
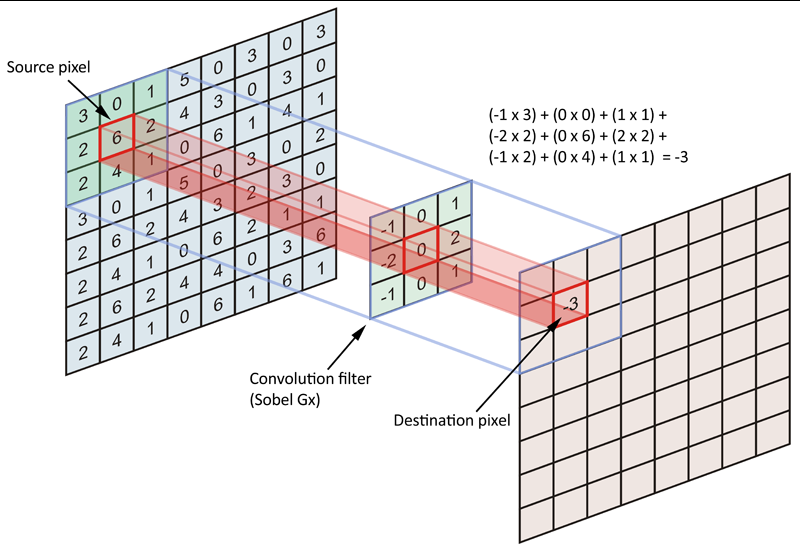
边缘检测是卷积操作的一个常见应用,我们所使用的权重矩阵其实是纵向的索贝尔算子(Sobel Operator),用于检测纵向的边缘,我们也可以使用横向的索贝尔算子,以及拉普拉斯算子来检测边缘。在OpenCV当中我们可以很容易地实现这个操作:
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('D:\cv\edge detection.png')
#索贝尔等经典卷积操作在灰度图像上表现更好,因此我们将图像导入时就转化为灰度图像
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#查看原图
plt.figure(dpi=200)
plt.imshow(img,cmap="gray")
plt.axis('off');
#两种经典算子:拉普拉斯与索贝尔
laplacian = cv2.Laplacian(img,cv2.CV_64F,ksize=5)
#cv2.CV_64F是opencv中常常使用的一种数据格式,在这里输入之后可以保证输出数据是uint8类型
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=5) #横向的索贝尔,旋转矩阵为5X5
sobely = cv2.Sobel(img,cv2.CV_64F,0,1,ksize=5) #纵向的索贝尔,旋转矩阵为5X5
plt.figure(dpi=300)
plt.subplot(2,2,1),plt.imshow(img,cmap = 'gray')
plt.title('Original'),plt.axis('off')
plt.subplot(2,2,2),plt.imshow(laplacian,cmap = 'gray')
plt.title('Laplacian'),plt.axis('off')
plt.subplot(2,2,3),plt.imshow(sobelx,cmap = 'gray')
plt.title('Sobel X'),plt.axis('off')
plt.subplot(2,2,4),plt.imshow(sobely,cmap = 'gray')
plt.title('Sobel Y'),plt.axis('off')

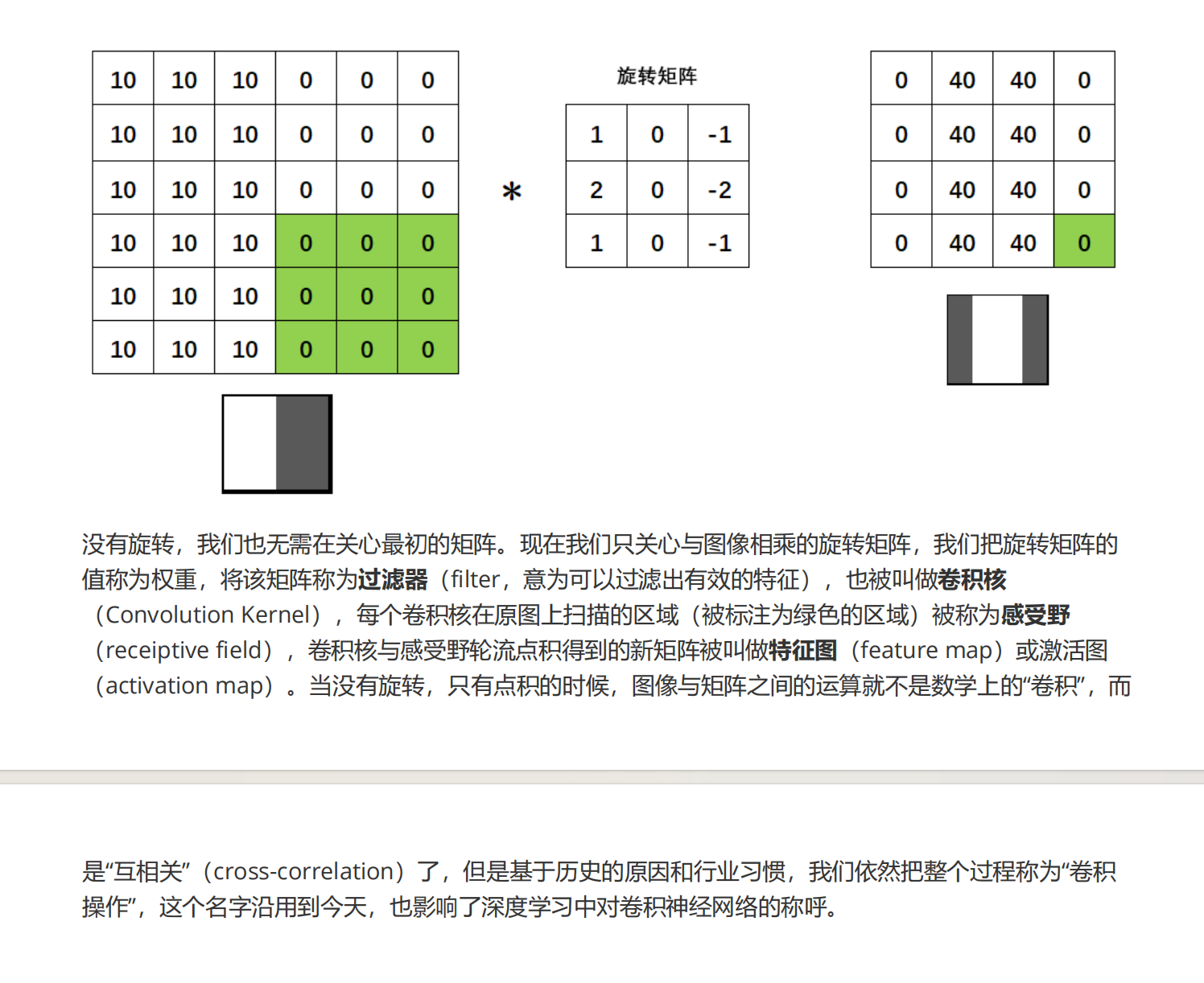
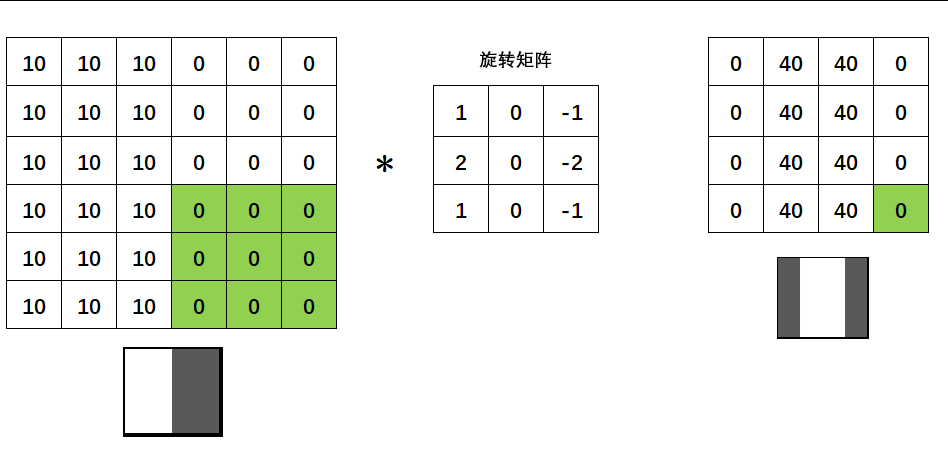
没有旋转,我们也无需在关心最初的矩阵。现在我们只关心与图像相乘的旋转矩阵,我们把旋转矩阵的值称为权重,将该矩阵称为过滤器(filter,意为可以过滤出有效的特征),也被叫做卷积核(Convolution Kernel),每个卷积核在原图上扫描的区域(被标注为绿色的区域)被称为感受野(receiptive field),卷积核与感受野轮流点积得到的新矩阵被叫做特征图(feature map)或激活图(activation map)。当没有旋转,只有点积的时候,图像与矩阵之间的运算就不是数学上的“卷积”,而是“互相关”(cross-correlation)了,但是基于历史的原因和行业习惯,我们依然把整个过程称为“卷积操作”,这个名字沿用到今天,也影响了深度学习中对卷积神经网络的称呼。
4 卷积遇见深度学习
检测边缘、锐化、模糊、图像降噪等卷积相关的操作,在图像处理中都可以被认为是在从图像中提取部分信息,因此这部分图像处理技术也被叫做“特征提取”技术。卷积操作后所产生的图像可以作为特征被输入到分类算法中,在传统计算机视觉领域,这一操作常常被认为可以提升模型表现并增强计算机对图像的识别能力。计算机视觉是研究如何让计算机从图像或图像序列中获取信息并理解其信息的学科,理解就意味着识别、判断甚至是推断,因此识别在计算机视觉中是非常核心的需求,卷积操作在传统计算机视觉中的地位就不言而喻了。数十年来,计算机视觉工程师们使用前人的经验与研究不断提取特征,再送入机器学习算法中进行识别和分类。然而,这样做是有极限的。
在边缘检测的例子中,我们看到拉普拉斯和索贝尔算子的检测是很明显的。但是,如果使用我们之前导入的孔雀图像,就会发现边缘检测的效果有些糟糕。
img = cv2.imread('D:/cv/peacock/blue-peacock.jpg')
img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
laplacian = cv2.Laplacian(img,cv2.CV_64F,ksize=5)
sobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=5)
sobely = cv2.Sobel(img,cv2.CV_64F,0,1,ksize=5)
plt.figure(dpi=300)
plt.subplot(2,2,1),plt.imshow(img,cmap = 'gray')
plt.title('Original'),plt.axis('off')
plt.subplot(2,2,2),plt.imshow(laplacian,cmap = 'gray')
plt.title('Laplacian'),plt.axis('off')
plt.subplot(2,2,3),plt.imshow(sobelx,cmap = 'gray')
plt.title('Sobel X'),plt.axis('off')
plt.subplot(2,2,4),plt.imshow(sobely,cmap = 'gray')
plt.title('Sobel Y'),plt.axis('off')
为什么会这样呢?这是因为,sobel和拉普拉斯算子对边缘抓取的程度较轻(从图像处理的原理上来看,他们只求取了图像上的一维导数,因此效果不够强),这样的抓取对于横平竖直的边缘、以及色彩差异较大的边缘有较好的效果,对于孔雀这样色彩丰富、线条和细节非常多的图像,这两种算子就不太够用了。所以在各种边缘检测的例子中,如果你仔细观察原图,你就会发现原图都是轮廓明显的图像。
这说明,不同的图像必须使用不同的权重进行特征提取,同时,我们还必须加深特征提取的深度。那什么样的图像应该使用什么样的权重呢?如何才能够提取到更深的特征呢?同时,如果过去的研究中提出的算子都不奏效,应该怎么找到探索新权重的方案呢?即便有效地实现了边检检测、锐化、模糊等操作,就能够提升最终分类算法的表现吗?其实不然。这些问题困扰计算机视觉工程师许久,即便在传统视觉中,我们已提出了不少对于这些问题的解决方案,但从一劳永逸的方向来考虑,如果计算机自己能够知道应该使用什么算子、自己知道应该提取到什么程度就好了。此时,深度学习登场了。
4.1 通过学习寻找卷积核
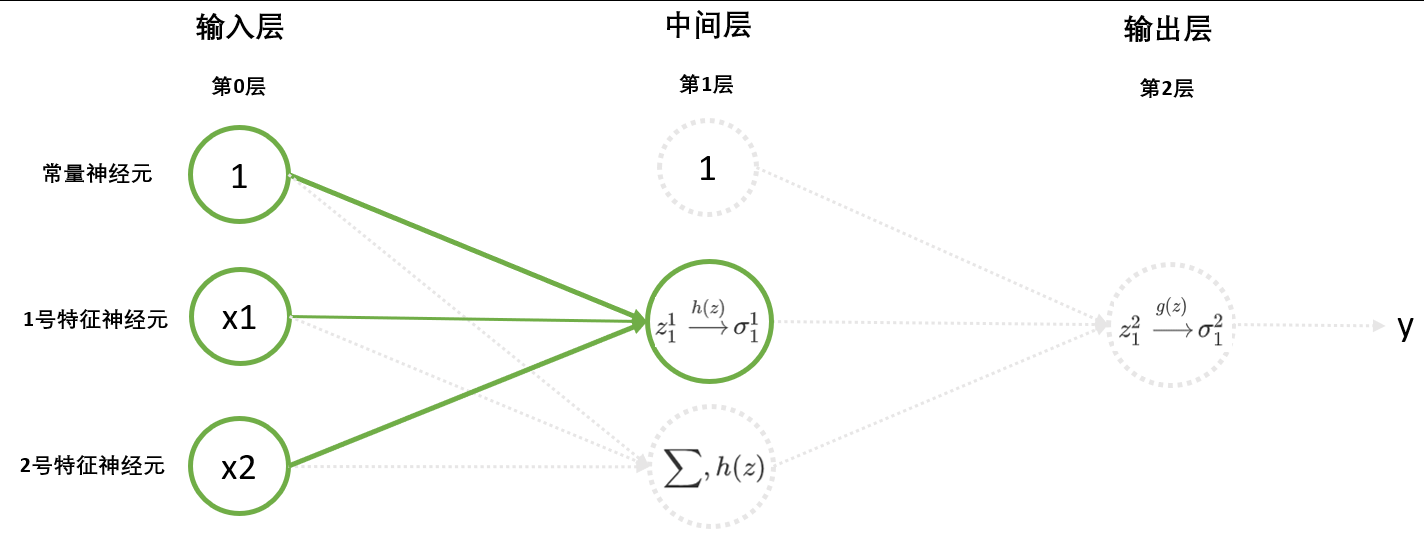
在深度神经网络中,层与层之间存在着链接上层与下层的权重系数 。深度学习的核心思想之一,就是给与算法训练目标,让算法自己朝着目标函数最小化的方向进行学习,并自动求解出权重系数 的最佳组合。在深度网络的在DNN中,我们输入的是特征矩阵,让特征矩阵与权重系数相乘后,传入下一层进行加和与激活,并通过从后向前的方式训练网络自己找出权重。在计算机视觉领域,我们输入的特征变成了一张张图像的一个个通道,我们让通道上的像素值与卷积核进行卷积操作后,得出输入下一层的图像(特征图 feature map)。而卷积操作本质就是感受野与卷积核点积,其操作与DNN中的权重与特征相乘非常相似。
顺着这样的思路,卷积层(Convolutional layer)诞生了,任意使用卷积层的神经网络就被称为是卷积神经网络(Convolution Neural Network),卷积网络一族有相当多的经典模型。每当卷积层被建立时,卷积核中的值就会被随机生成,输入图像的像素点与卷积核点积后,生成的特征图被输入到下一层网络,并最终变成预测标签被放入损失函数中进行计算。在使用优化算法进行迭代、损失足够低后,卷积核中的权重值就被自动学习出来了,这就实现了“自动找出最佳权重,并提取出对分类最有利的特征”。
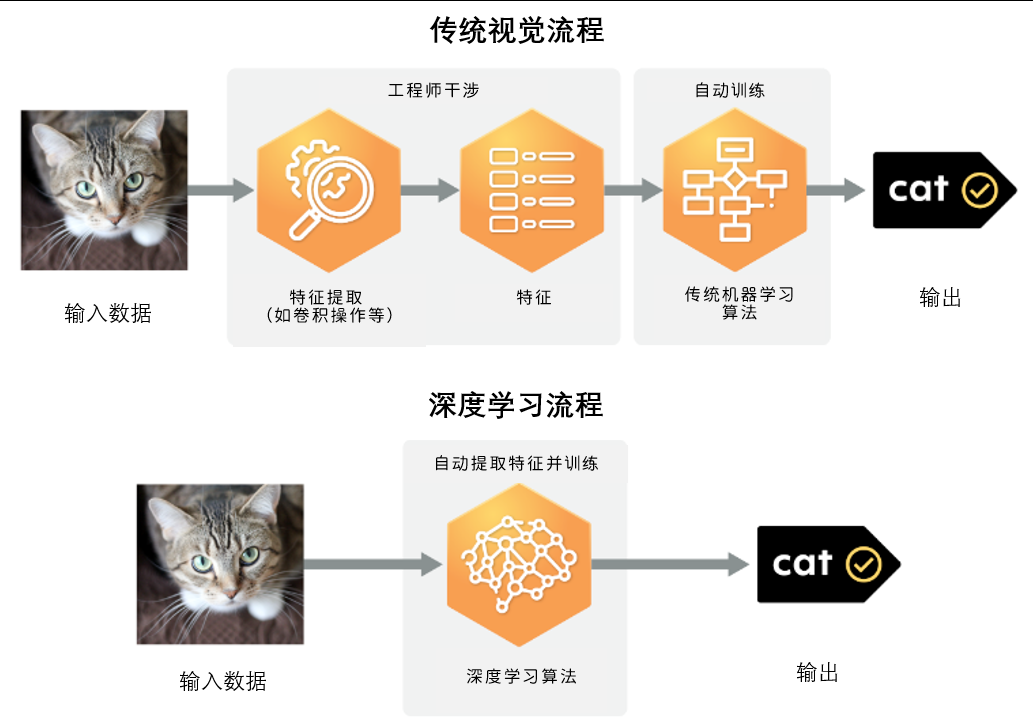
这样学习出的卷积核的值以分类效果为最终目标,可以选择出最恰当的特征,因此理想状况下,可以完美避免人工进行特征提取的这个步骤。剩下的问题就是,通过深度学习自动学习得出的特征,能够比人手提取的特征更好吗?这个问题耗费了学术界数十年的时间,最终被现代神经网络的数个经典架构所验证。但现在,我们暂且不谈这个,继续来看深度学习与卷积的碰撞所带来的改变。
4.2 参数共享:卷积带来参数量骤减

4.3 稀疏交互:获取更深入的特征
卷积操作是为了提取特征而进行的数学计算,它能够根据损失函数的指导而自动提取出对分类或其他目标更有效的特征。然而,卷积神经网络是如何保证提取到的特征比传统方法,如sobel算子等方法“更深”的呢?
这需要从“神经元”的层次来看待。在CNN中,我们都是以“层”或者“图”、“通道”这些术语来描述架构,但其实CNN中也有神经元。在任何神经网络中,一个神经元都只能够储存一个数字。所以在CNN中,一个像素就是一个神经元(实际上就是我们在类似如下的视图中看到的每个正方形小格子)。很容易理解,输入的图像/通道上的每个小格子就是输入神经元,feature map上的每个格子就是输出神经元。在DNN中,上层的任意神经元都必须和下层的每个神经元都相连,所以被称之为“全连接”(fully connected),但在CNN中,下层的一个神经元只和上层中被扫描的那些神经元有关,在图上即表示为,feature map上的绿格子只和原图上绿色覆盖的部分有关。这种神经元之间并不需要全链接的性质
被称为稀疏交互(Sparse Interaction)。人们认为,稀疏交互让CNN获得了提取更深特征的能力。
深度学习中的许多方法来源于对其他学科的借鉴,卷积的结构也不例外。为了研究大脑是如何理解人眼所看到的内容,神经学家们对人眼成像系统进行了丰富的研究。人类的眼球中含有一系列视觉细胞,但这些细胞不是等价的,他们之中的一部分是简单细胞,只能捕捉到简单的线条、颜色等信息,这些简单细胞捕捉到简单信息后,会将信息传导至复杂细胞,复杂细胞会将这些信息重组为轮廓、光泽等更高级的信息,之后再将信息传导至更高级的细胞,形成完整的图像。神经学家认为,人眼的细胞有着“提取浅层特征,合成高级特征”的能力。CNN的“稀疏交互”的属性允许神经元只包含上一层图像“局部”的信息,这就与人眼的简单细胞只提取简单线条的属性很相似。因此我们有理由相信,当图像被输入网络后,前端的卷积神经网络提取到的特征都是浅层的(和sobel算子等方法一样),将这些浅层特征继续输入后续的网络,再次进行提取和学习,就能够将浅层特征逐渐组合成深层特征。而图像天生就可以通过不断变换、被提取出更多的特征(相对的,自然语言就没有这个性质,所以NLP领域的CNN往往没有CV领域的CNN深),因此位于卷积神经网络架构后端的卷积层们,一定是捕捉到了更深层的特征的。
虽然“稀疏交互”是客观的,但是否依赖于这个属性来提取出更深的特征确实有争议的。根据“模拟人眼”的理论,CNN提取出的各层的特征图应该是类似下面这样的:
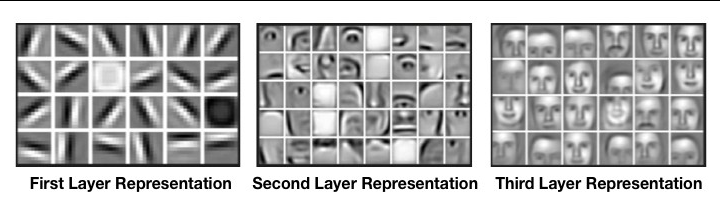
这张图可视化了在人脸识别中各层卷积层所提取到的特征图。从左至右,神经网络越来越深,从最开始的只能提取到一些简单的线条,到最后可以提取出一整张人脸,似乎能够证明CNN的确拥有和人眼细胞一样的能力。然而当我们真正去可视化一些经典卷积神经网络的结构时,随着卷积层的加深,可视化出来的效果往往是这样的:

不难发现,我们很难直接看出“从局部到整体”这样一个特性。从CNN的预测效果来看,我们有理由相信它的确提取到了更深的特征,但绝不是以我们认为的,“先提取细节、再拼接成局部、最后组成图像”的方式。
无论如何,卷积与深度学习碰撞所带来的变革是革命性的。通过学习的方式改进卷积核、再通过深层网络不断提纯特征、以及大幅度降低参数量,卷积神经网络的作用已经不言而喻。接下来,我们就来学习,如何使用PyTorch构筑卷积神经网络。
三、在PyTorch中构筑卷积神经网络
卷积神经网络是使用卷积层的一组神经网络。在一个成熟的CNN中,往往会涉及到卷积层、池化层、线性层(全连接层)以及各类激活函数。因此,在构筑卷积网络时,需从整体全部层的需求来进行考虑。
1 二维卷积层nn.Conv2d

1.1 卷积核尺寸kernel_size
kernel_size是我们第一个需要讲解的参数,但同时也是最简单的参数。
- kernel_size
卷积核的尺寸。无默认值,必填。可输入整数或数组,输入整数则代表卷积核的形状为正方形,输入数组则代表卷积核的形状与数组一致。

卷积核的尺寸应该如何选择呢?如果你在使用经典架构,那经典架构的论文中所使用的尺寸就是最好的尺寸。如果你在写自己的神经网络,那3x3几乎就是最好的选择。对于这个几乎完全基于经验的问题,
我可以提供以下几点提示:
1、卷积核几乎都是正方形。最初是因为在经典图像分类任务中,许多图像都被处理成正方形或者接近正方形的形状(比如Fashion-MNIST,CIFAR,ImageNet)等等。如果你的原始图像尺寸很奇妙(例如,非常长或非常宽),你可以使用与原图尺寸比例一致的卷积核尺寸。
2、卷积核的尺寸最好是奇数,例如3x3,5x5,7x7等。这是一种行业惯例,传统视觉中认为这是为了让被扫描区域能够“中心对称”,无论经历过多少次卷积变换,都能够以正常比例还原图像。
相对的,如果扫描区域不是中心对称的,在多次进行卷积操作之后,像素会“偏移”导致图像失真(由最左侧图像变换为右侧的状况)。然而,这种说法缺乏有效的理论基础,如果你发现你的神经网络的确更适合偶数卷积核(并且你能够证明、或说服你需要说服的人来接受你的决定),那你可以自由使用偶数卷积核。目前为止,还没有卷积核的奇偶会对神经网络的效果造成影响的明确理论。

3、在计算机视觉中,卷积核的尺寸往往都比较小(相对的,在NLP中,许多网络的卷积核尺寸都可以很大)。这主要是因为较小的卷积核所需要的训练参数会更少,之后我们会详细地讨论关于训练参数量的问题。
1.2 卷积的输入与输出:in_channels,out_channels,bias
除了kernel_size之外,还有两个必填参数:in_channels与out_channels。简单来说:in_channels是输入卷积层的图像的通道数或上一层传入特征图的数量,out_channels是指这一层输出的特征图的数量。这两个数量我们都可以自己来确定,但具体扫描流程中的细节还需要理清。
在之前的例子中,我们在一张图像上使用卷积核进行扫描,得到一张特征图。这里的“被扫描图像”是一个通道,而非一张彩色图片。如果卷积核每扫描一个通道,就会得到一张特征图,那多通道的图像应该被怎样扫描呢?会有怎样的输出呢?
在一次扫描中,我们输入了一张拥有三个通道的彩色图像。对于这张图,拥有同样尺寸、但不同具体数值的三个卷积核会分别在三个通道上进行扫描,得出三个相应的“新通道”。由于同一张图片中不同通道的结构一定是一致的,卷积核的尺寸也是一致的,因此卷积操作后得出的“新通道”的尺寸也是一致的。
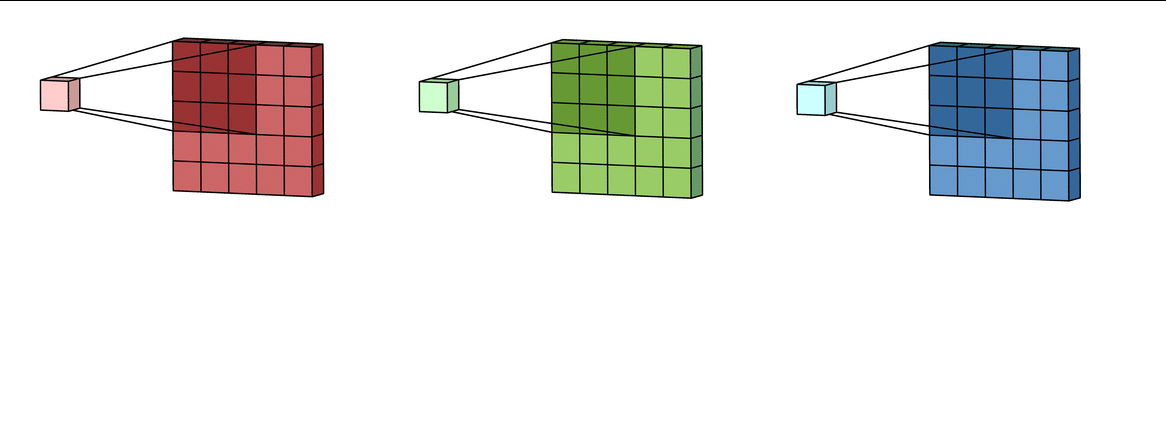
得出三个“新通道”后,我们将对应位置的元素相加,形成一张新图,这就是卷积层输入的三彩色图像的第一个特征图。这个操作对于三通道的RGB图像、四通道的RGBA或者CYMK图像都是一致的。只不过,如果是四通道的图像,则会存在4个同样尺寸、但数值不同的卷积核分别扫描4个通道。

因此,在一次扫描中,无论图像本身有几个通道,卷积核会扫描全部通道之后,将扫描结果加和为一张feature map。所以,一次扫描对应一个feature map,无关原始图像的通道数目是多少,所以out_channels就是扫描次数,这之中卷积核的数量就等于(输入的通道in_channels) 乘(扫描次数 out_channels)。那对于一个通道,我们还有可能多次扫描,得出多个feature map吗?当然有可能!卷积核的作用是捕捉特征,同一个通道上很有可能存在多个需要不同的卷积核进行捕捉的特征,例如,能够捕捉到孔雀脖子轮廓的卷积核,就不一定能够捕捉到色彩绚丽的尾巴。因此,对同一个通道提供多个不同的卷积核来进行多次扫描是很普遍的操作。不过,我们并不能对不同的通道使用不同的卷积核数量。比如,若规定扫描三次,则每次扫描时通道都会分别获得自己的卷积核,我们不能让卷积网络执行类似于“红色通道扫描2次,蓝色通道扫描3次”的操作。
需要注意的是,当feature maps被输入到下一个卷积层时,它也是被当作“通道”来处理的。不太严谨地说,feature map其实也可以是一种“通道”,虽然没有定义到具体的颜色,但它其实也是每个元素都在[0,255]之间的图。这是说,当feature map进入到下一个卷积层时,新卷积层上对所有feature map完成之后,也会将它们的扫描结果加和成一个新feature map。所以,在新卷积层上,依然是一次扫描对应生成一个feature map,无关之前的层上传入的feature map有多少。
- 总结
卷积层的输入是图像时,一次扫描会扫描所有通道的值再加和成一张特征图。当卷积层的输入是上层的特征图时,特征图会被当做“通道”对待,一次扫描会扫描所有输入的特征图,加和成新的feature map。无论在哪一层,生成的feature map的数量都等于这一层的扫描次数,也就是等于out_channels的值。下一层卷积的in_channels就等于上一层卷积的out_channels。
这其实与DNN中的线性层很相似,在线性层中,下一个线性层输入的数目就等于上一个线性层的输出的数目。我们来看一下具体的卷积层的代码:
import torch
from torch import nn
#假设一组数据
#还记得吗?虽然默认图像数据的结构是(samples, height, width, channels)
#但PyTorch中的图像结构为(samples, channels, height, width),channels排在高和宽前面
#PyTorch中的类(卷积)无法读取channels所在位置不正确的图像
data = torch.ones(size=(10,3,28,28)) #10张尺寸为28*28的、拥有3个通道的图像
conv1 = nn.Conv2d(in_channels = 3
,out_channels = 6 #全部通道的扫描值被合并,6个卷积核形成6个feature map
,kernel_size = 3) #这里表示3x3的卷积核
conv2 = nn.Conv2d(in_channels = 6 #对下一层网络来说,输入的是上层生成的6个feature map
,out_channels = 4 #全部特征图的扫描值被合并,4个卷积核形成4个新的feature map
,kernel_size = 3)
#conv3 = nn.Conv2d(in? out?)
#通常在网络中,我们不会把参数都写出来,只会写成:
#conv1 = nn.Conv2d(3,6,3)
#查看一下通过卷积后的数据结构
conv1(data).shape
conv2(conv1(data)).shape
#尝试修改一下conv2的in_channels,看会报什么错?
conv2 = nn.Conv2d(in_channels = 10,out_channels = 4,kernel_size = 3)
conv2(conv1(data))


1.3 特征图的尺寸:stride,padding,padding_mode
- stride
不知你是否注意到,在没有其他操作的前提下,经过卷积操作之后,新生成的特征图的尺寸往往是小于上一层的特征图的。在之前的例子中,我们使用3X3的卷积核在6X6大小的通道上进行卷积,得到的特征图是4X4。如果在4X4的特征图上继续使用3X3的卷积核,我们得到的新特征图将是2X2的尺寸。最极端的情况,我们使用1X1的卷积核,可以得到与原始通道相同的尺寸,但随着卷积神经网络的加深,特征图的尺寸是会越来越小的


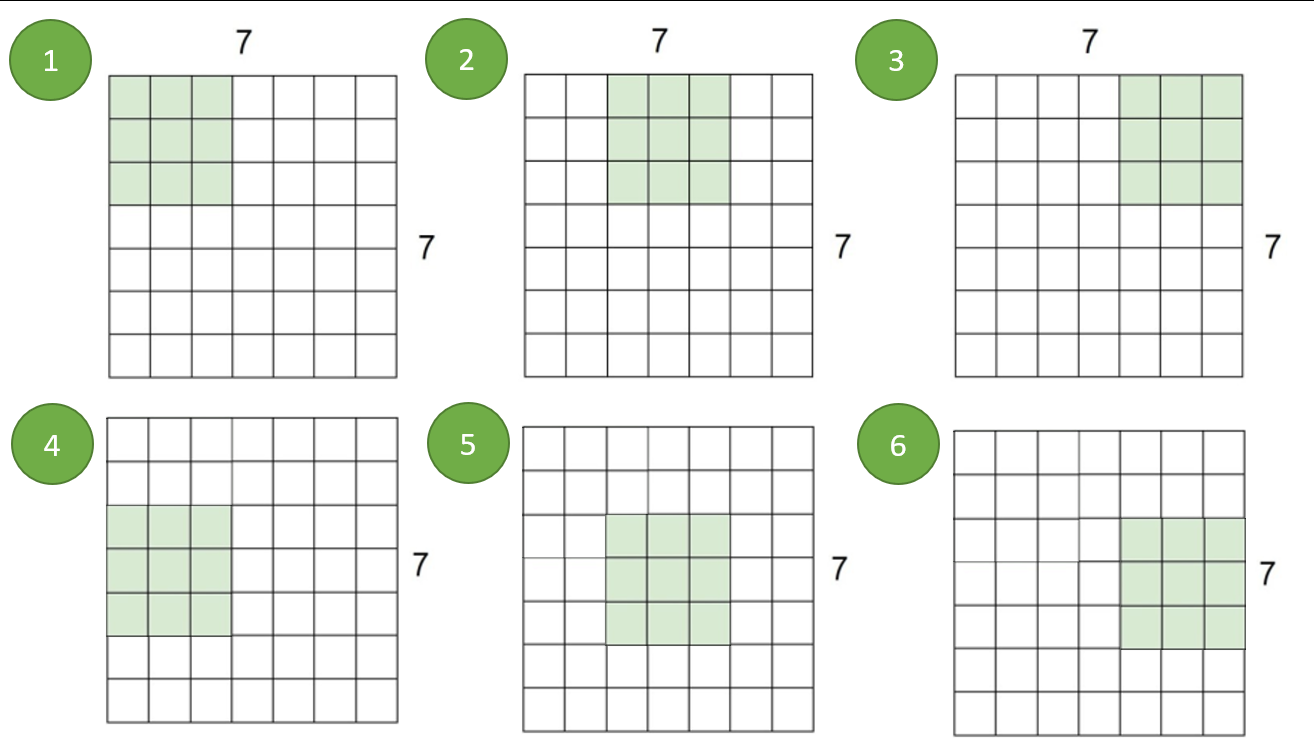
步长可以根据自己的需求进行调整,通常都设置为1-3之间的数字,也可以根据kernel_size来进行设置。在DNN中,我们把形如(sampels, features)结构的表数据中的列,也就是特征也叫做“维度”。对于表数据来说,要输入DNN,则需要让DNN的输入层上拥有和特征数一样数量的神经元,因此“高维”就意味着神经元更多。之前我们提到过,任何神经网络中一个神经元上都只能有一个数字,对图像来说一个像素格子就是一个神经元,因此卷积网络中的“像素”就是最小特征单位,我们在计算机视觉中说“降维”,往往是减少一张图上的像素量。参数步长可以被用于“降维”,也就是可以让输入下一层的特征图像素量降低,特征图的尺寸变得更小。

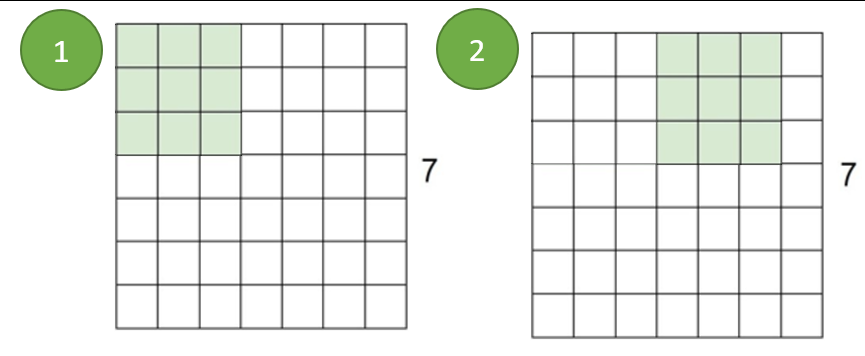
所谓填充法,就是在图像的两侧使用0或其他数字填上一些像素,扩大图像的面积,使得卷积核能将整个图像尽量扫描完整。
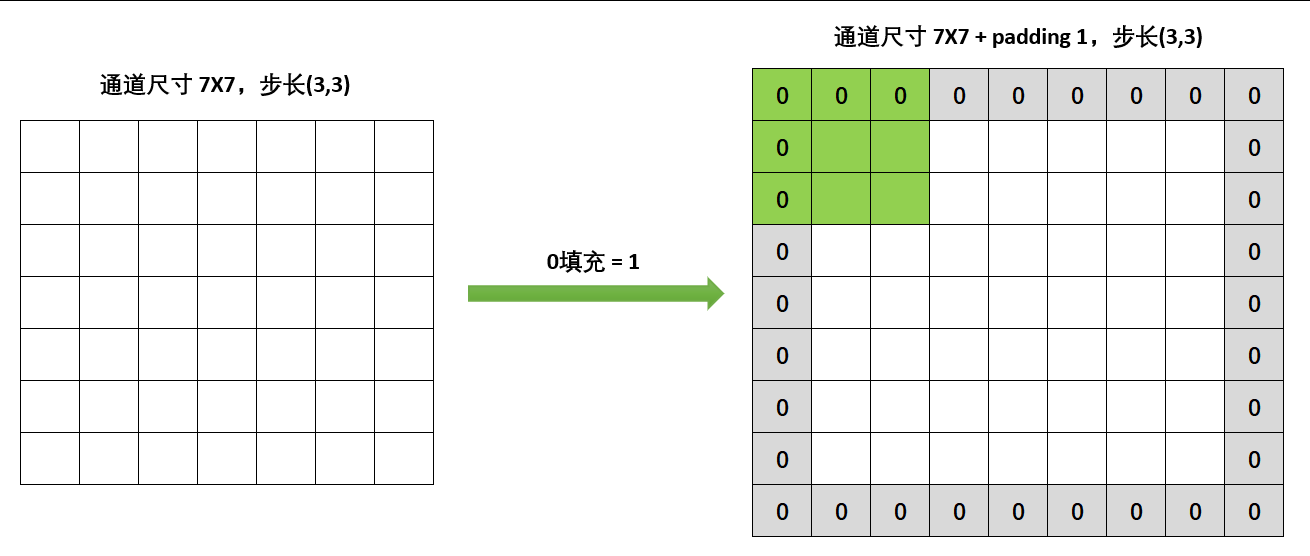
在PyTorch中,填充与否由参数padding控制和padding_mode控制。padding接受大于0的正整数或数组作为参数,但通常我们只使用整数。padding=1则时在原通道的上下左右方向各添上1各像素,所以通道的尺寸实际上会增加2*padding。padding_mode则可以控制填充什么内容。在图上展示的是zero_padding,也就是零填充,但我们也可以使用其他的填充方式。pytorch提供了两种填充方式,0填充与环型填充。在padding_mode中输入“zero”则使用0填充,输入“circular”则使用环型填充。
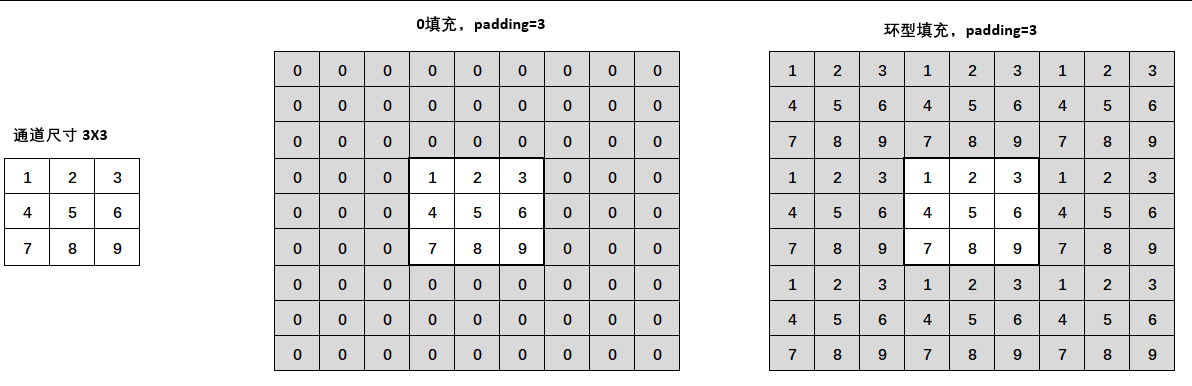

不难发现,如果输入通道的尺寸较小,padding数目又很大,padding就可能极大地扩充通道的尺寸,并让feature map在同样的卷积核下变得更大。我们之前说,在没有其他操作时feature map往往是小于输入通道的尺寸的,而加入padding之后feature map就有可能大于输入通道了,这在经典卷积网络的架构中也曾出现过。通常来说,我们还是会让feature map随着卷积层的深入逐渐变小,这样模型计算才会更快,因此,padding的值也不会很大,基本只在1~3之间。
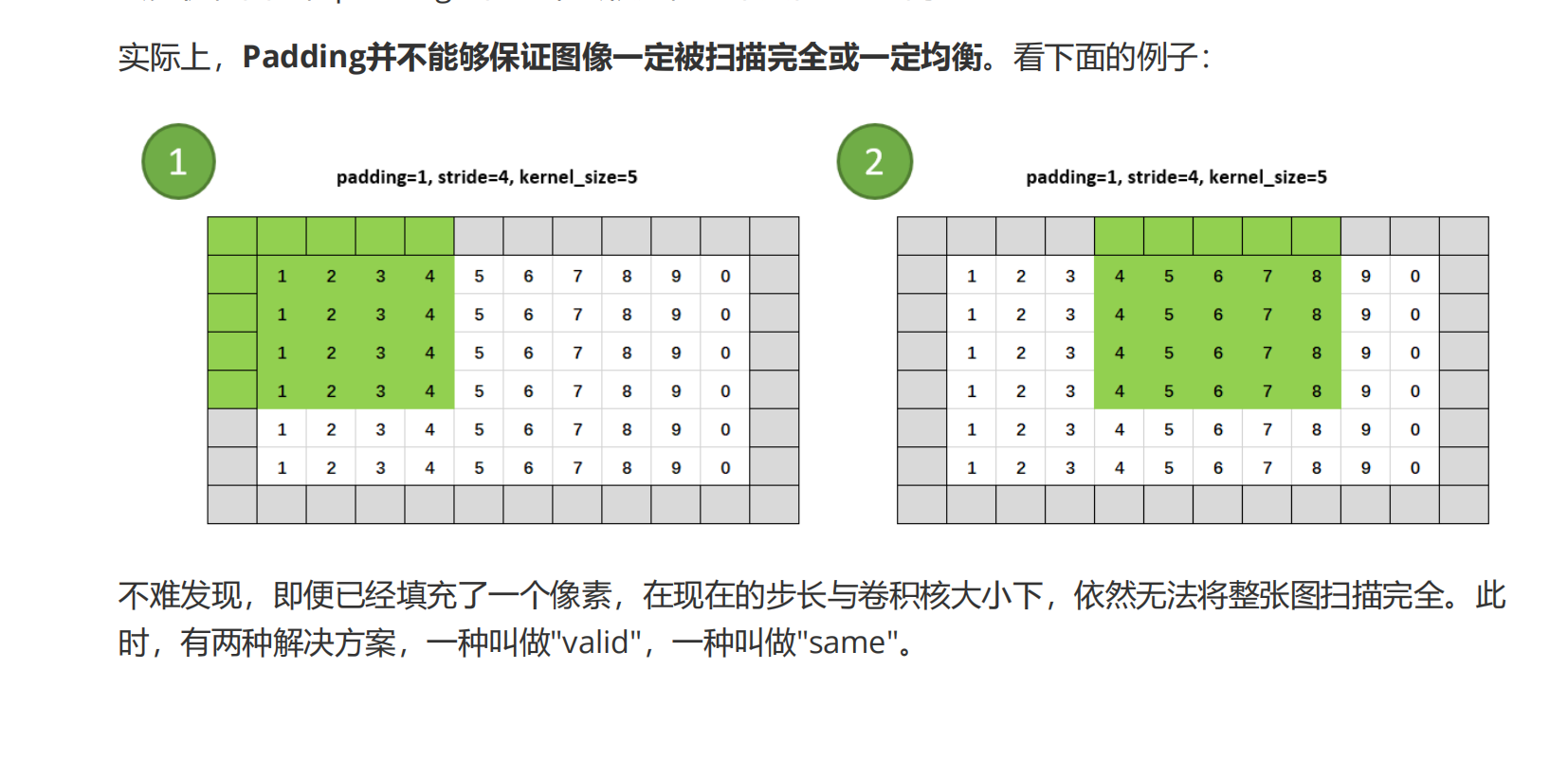
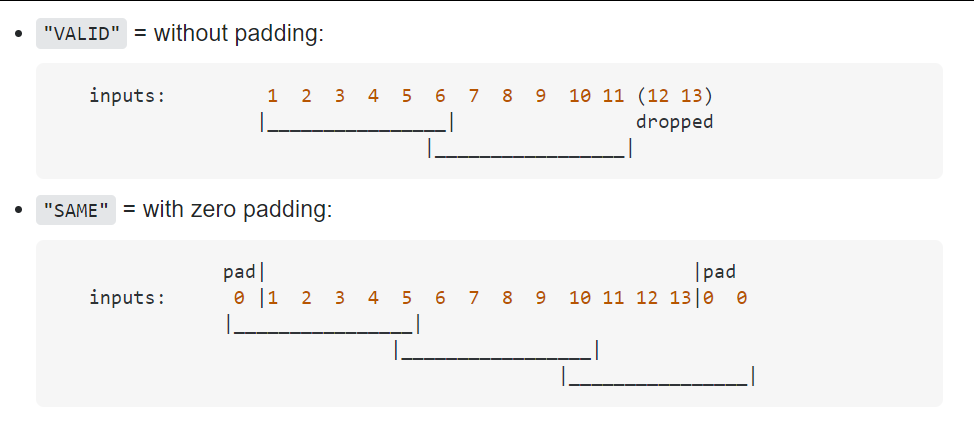
valid模式就是放弃治疗,对于扫描不到的部分,直接丢弃。“same”模式是指,在当前卷积核与步长设置下无法对全图进行扫描时,对图像右侧和下边进行“再次填充”,直到扫描被允许进行为止。从上图看,same模式下的padding设置本来是1(即左右两侧都填上0),但在右侧出现11、12、13和填充的0列无法被扫描的情况,则神经网络自动按照kernel_size的需要,在右侧再次填充一个0列,实现再一次扫描,让全部像素都被扫描到。
这个操作看上去很智能,但遗憾的是只能够在tensorflow中实现。对于PyTorch而言,没有“same”的选项,只要无法扫描完全,一律抛弃。为什么这样做呢?主要还是因为kernel_size的值一般比较小,所以被漏掉的像素点不会很多,而且基本集中在边缘。随着计算机视觉中所使用的图片分辨率越来越高,图像尺寸越来越大,边缘像素包含关键信息的可能性会越来越小,丢弃边缘就变得越来越经济。对于一张28x28的图像而言,丢弃2、3列或许会有不少信息损失,但对于720x1080的图片而言,究竟是720x1078还是720x1080,其实并无太大区别。

import torch
from torch import nn
#记住我们的计算公式
#(H + 2p - K)/S + 1
#(W + 2p - K)/S + 1
#并且卷积网络中,默认S=1,p=0
data = torch.ones(size=(10,3,28,28)) #10张尺寸为28*28的、拥有3个通道的图像
conv1 = nn.Conv2d(3,6,3) #这一层输出的feature map结构应该是?
conv2 = nn.Conv2d(6,4,3) #这一层呢?输入数据为conv1的结果
conv3 = nn.Conv2d(4,16,5,stride=2,padding=1) #现在加上步长和填充,输入数据为conv2的结果
conv4 = nn.Conv2d(16,3,5,stride=3,padding=2)
#conv1,输入结构28*28
#(28 + 0 - 3)/1 + 1 = 26
#验证一下
conv1(data).shape
#conv2,输入结构26*26
#(26 + 0 - 3)/1 + 1 = 24
#验证
conv2(conv1(data)).shape
#conv3,输入结构24*24
#(24 + 2 - 5)/2 + 1 = 11,扫描不完全的部分会被舍弃
conv3(conv2(conv1(data))).shape
#conv4,输入结构11*11
#(11 + 4 - 5)/3 + 1 = 4.33,扫描不完全的部分会被舍弃
conv4(conv3(conv2(conv1(data)))).shape
padding和stride是卷积层最基础的操作,之后的课程中我们还会有各种各样的操作,他们都有可能会改变卷积层的输出结构或参数量。对于入门而言,学会padding和stride也就足够了。
2 池化层nn.MaxPool & nn.AvgPool
无论是调整步长还是加入填充,我们都希望能够自由控制特征图的尺寸。除了卷积层之外,另一种可以高效减小特征图尺寸的操作是“池化”Pooling。池化是一种非常简单(甚至有些粗暴的)的降维方式,经常跟在卷积层之后,用以处理特征图。最常见的是最大池化(Max Pooling)和平均池化(Average Pooling)两种操作,他们都很容易理解:
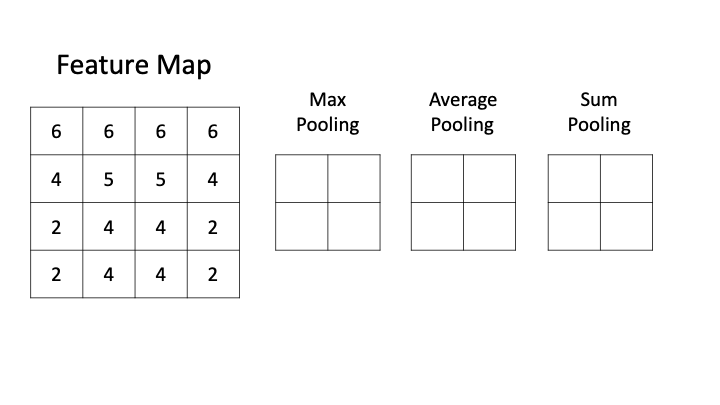
池化层也有核,但它的核没有值,只有尺寸。在上图之中,池化核的尺寸就是(2,2)。池化核的移动也有步长stride,但默认步长就等于它的核尺寸,这样可以保证它在扫描特征图时不出现重叠。当然,如果我们需要,我们也可以设置参数令池化核的移动步长不等于核尺寸,在行业中这个叫“Overlapping Pooling”,即重叠池化,但它不是非常常见。通常来说,对于特征图中每一个不重叠的、大小固定的矩阵,池化核都按照池化的标准对数字进行计算或筛选。在最大池化中,它选出扫描区域中最大的数字。
在平均池化中,它对扫描区域中所有的数字求平均。在加和池化中,它对扫描区域中所有的数字进行加和。
在这几种简单的方法中,最大池化是应用最广泛的,也是比较有效的。考虑看看feature map中的信息是怎么得来的?feature map中每个像素上的信息都是之前的卷积层中,图像与卷积核进行互相关操作的结果。对之前的卷积层而言,卷积核都是一致的,唯一不同的就是每次被扫描的区域中的像素值。像素值越大,说明颜色信息越多,像素值越小,说明图像显示约接近黑色,因此经过卷积层之后,像素值更高的点在原始图像上更有可能带有大量信息。MaxPooling通过摘取这些带有更多信息的像素点,有效地将冗余信息消除,实现了特征的“提炼”。相对的,平均和加和的“提炼”效应就弱一些。
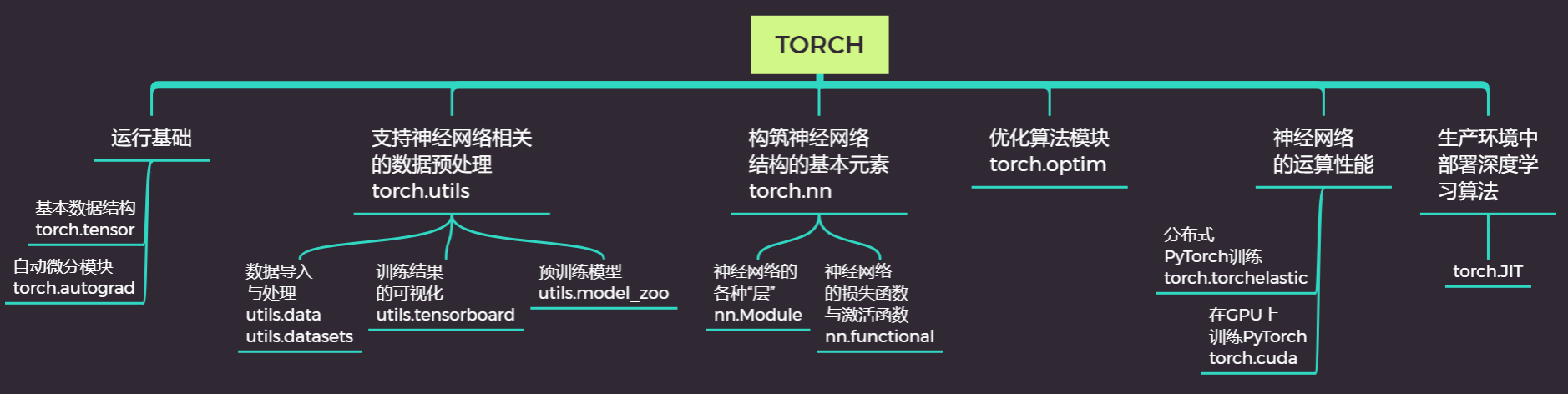
在PyTorch中,池化层也有多种选项,但这些多属于“普通池化”的范围。在传统计算机视觉中,我们还有空间金字塔池化(Spatial Pyramid Pooling)等操作。

data = torch.ones(size=(10,3,28,28))
conv1 = nn.Conv2d(3,6,3) #(28 + 0 - 3)/1 + 1 = 26
conv3 = nn.Conv2d(6,16,5,stride=2,padding=1) # (26 + 2 - 5)/2 +1 = 12
pool1 = nn.MaxPool2d(2) #唯一需要输入的参数,kernel_size=2,则默认使用(2,2)结构的核
# (12 + 0 - 2)/2 + 1 =6
#验证一下
pool1(conv3(conv1(data))).shape
事实上,使用(2,2)结构的池化层总是会将featrue map的行列都减半,将整个feature map的像素数减少3/4,因此它是非常有效的降维方法。
与卷积不同,池化层的操作简单,没有任何复杂的数学原理和参数,这为我们提供了精简池化层代码的可能性。通常来说,当我们使用池化层的时候,我们需要像如上所示的方法一样来计算输出特征图的尺寸,但PyTorch提供的“Adaptive”相关类,允许我们输入我们希望得到的输出尺寸来执行池化:
CLASS torch.nn.AdaptiveMaxPool2d (output_size, return_indices=False)
CLASS torch.nn.AdaptiveAvgPool2d (output_size)
可以看到,在这两个类中,我们可以输入output_size,而池化层可以自动帮我们将特征图进行裁剪。我们来试试看:
data = torch.ones(size=(10,3,28,28))
conv1 = nn.Conv2d(3,6,3) #(28 + 0 - 3)/1 + 1 = 26
conv3 = nn.Conv2d(6,16,5,stride=2,padding=1) # (26 + 2 - 5)/2 +1 = 12
pool1 = nn.AdaptiveMaxPool2d(7) #输入单一数字表示输出结构为7x7,也可输入数组
pool1(conv3(conv1(data))).shape
可惜的是,PyTorch官方没有给出这两个类具体是怎样根据给出的输出特征图的尺寸数来倒推步幅和核尺寸的,在PyTorch官方论坛也有一些关于这个问题的讨论,但都没有给出非常令人满意的结果。大家达成一致的是:如果输入一些奇怪的数字,例如(3,7),那在池化的过程中是会出现比较多的数据损失的。
除了能够有效降低模型所需的计算量、去除冗余信息之外,池化层还有特点和作用呢?
1、提供非线性变化。卷积层的操作虽然复杂,但本质还是线性变化,所以我们通常会在卷积层的后面增加激活层,提供ReLU等非线性激活函数的位置。但池化层自身就是一种非线性变化,可以为模型带来一些活力。然而,学术界一直就池化层存在的必要性争论不休,因为有众多研究表明池化层并不能提升模型效果(有争议)。
2、有一定的平移不变性(有争议)。
3、池化层所有的参数都是超参数,不涉及到任何可以学习的参数,这既是优点(增加池化层不会增加参数量),也是致命的问题(池化层不会随着算法一起进步)。
4、按照所有的规律对所有的feature map一次性进行降维,feature map不同其本质规律不然不同,使用同样的规则进行降维,必然引起大估摸信息损失。
不过,在经典神经网络架构中,池化层依然是非常关键的存在。如果感兴趣的话,可以就池化与卷积的交互相应深入研究下去,继续探索提升神经网络效果的可能性。
3 Dropout2d与BatchNorm2d
Dropout与BN是神经网络中非常经典的,用于控制过拟合、提升模型泛化能力的技巧,在卷积神经网络中我们需要应用的是二维Dropout与二维BN。对于BN我们在前面的课程中有深入的研究,它是对数据进行归一化处理的经典方法,对于图像数据,我们所需要的类如下:
CLASS torch.nn.BatchNorm2d (num_features, eps=1e-05, momentum=0.1, affine=True,track_running_stats=True)
BN2d所需要的输入数据是四维数据(第一个维度是samples),我们需要填写的参数几乎只有num_features一个。在处理表数据的BatchNorm1d里,num_features代表了输入bn层的神经元个数,然而对于卷积网络来说,由于存在参数共享机制,则必须以卷积核/特征图为单位来进行归一化,因此当出现在卷积网络前后时,BatchNorm2d所需要输入的是上一层输出的特征图的数量。例如:
data = torch.ones(size=(10,3,28,28))
conv1 = nn.Conv2d(3,32,5,padding=2)
bn1 = nn.BatchNorm2d(32)
bn1(conv1(data)).shape #不会改变feature map的形状
#输入其他数字则报错
#bn1 = nn.BatchNorm2d(10)
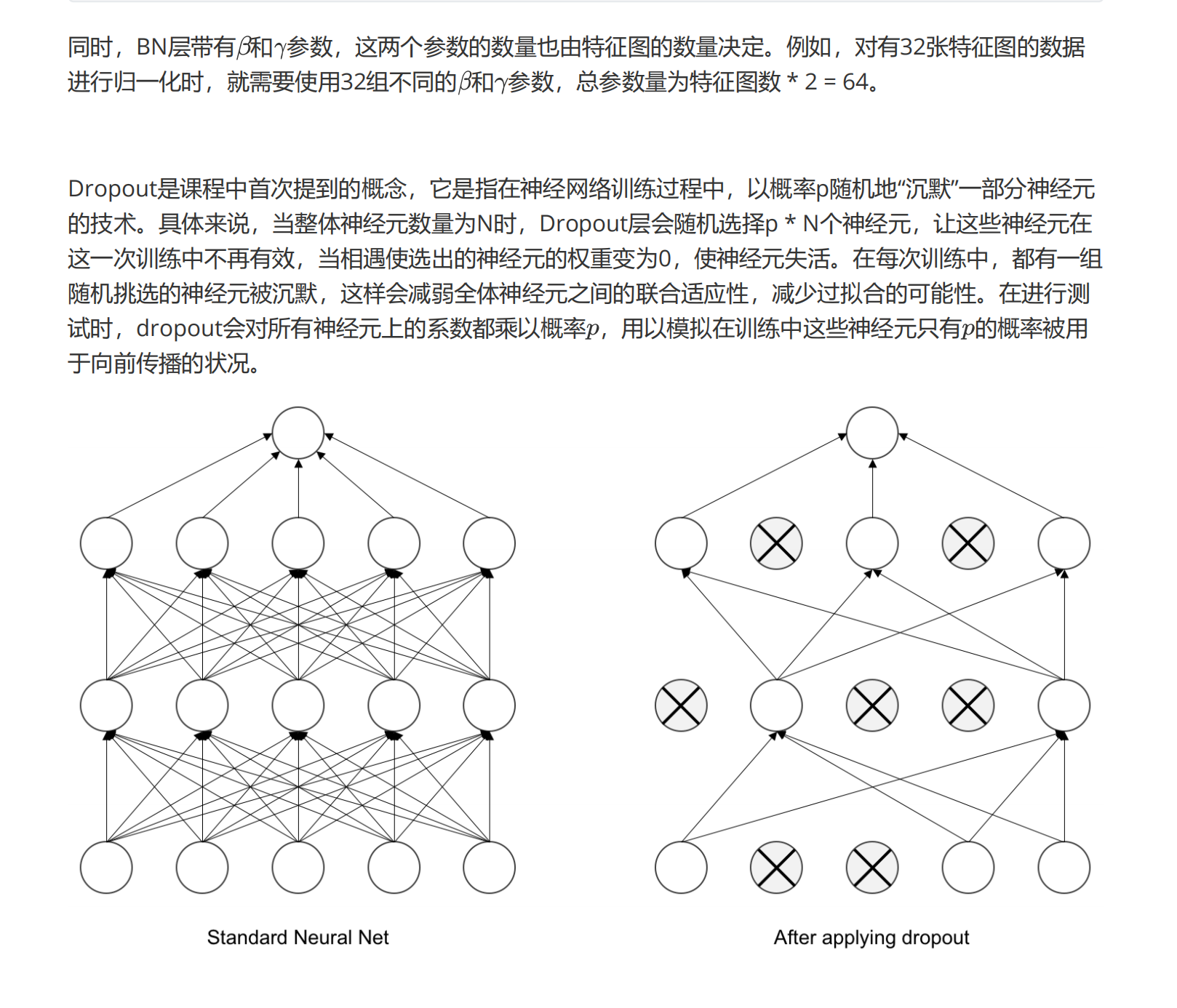
对于卷积神经网络来说,我们需要使用的类是Dropout2d,唯一需要输出的参数是p,其输入数据同样是带有samples维度的四维数据。不过在卷积中,Dropout不会以神经元为单位执行“沉默”,而是一次性毙掉一个通道。因此,当通道总数不多时,使用Dropout或Dropout中的p值太大都会让CNN丧失学习能力,造成欠拟合。通常来说,使用Dropout之后模型需要更多的迭代才能够收敛,所以我们总是从p=0.1,0.25开始尝试,最多使用p=0.5,否则模型的学习能力会出现明显下降。
CLASS torch.nn.Dropout2d (p=0.5, inplace=False)
data = torch.ones(size=(10,1,28,28))
conv1 = nn.Conv2d(1,32,5,padding=2)
dp1 = nn.Dropout2d(0.5)
dp1(conv1(data)).shape #不会改变feature map的形状
Dropout层本身不带有任何需要学习的参数,因此不会影响参数量。
接下来,我们来实现一些由卷积层和池化层组成的神经网络架构,帮助大家回顾一下神经网络的定义过程,同时也加深对卷积、池化等概念的印象。
4 复现经典网络:LeNet5与AlexNet
4.1 现代CNN的奠基者:LeNet5
使用卷积层和池化层能够创造的最简单的网络是什么样呢?或许就是下面这样的架构:
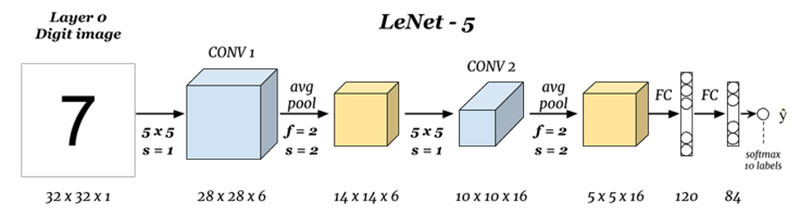
首先,图像从左侧输入,从右侧输出,数据传输方向与DNN一致。整个网络由2个卷积层、2个平均池化层和2个全连接层组成,虽然没有标注出来,但每个卷积层和全连接层后都使用激活函数tanh或sigmoid。
这个架构就是著名的LeNet5架构,它在1998年被LeCun等人在论文《Gradient-Based Learning Applied to Document Recognition》中正式提出,它被认为是现代卷积神经网络的奠基者。在LeNet5被提出后,几乎所有的卷积网络都会连用卷积层、池化层与全连接层(也就是线性层)。现在,这已经成为一种非常经典的架构:卷积层作为输入层,紧跟激活函数,池化层紧跟在一个或数个卷积+激活的结构之后。在卷积池化交替进行数次之后,转向线性层+激活函数,并使用线性层结尾,输出预测结果。由
于输入数据结构的设置,以上架构图中的网络可能与论文中有一些细节上的区别(论文见下载资料),在其他教材中,你或许会见到添加了更多卷积层、或添加了更多池化层的相似架构,这些都是根据LeNet的核心思想“卷积+池化+线性”来搭建的LeNet5的变体。
在上面的架构中,每层的结构和参数都标识得非常清楚,在PyTorch中实现其架构的代码如下:
import torch
from torch import nn
from torch.nn import functional as F
data = torch.ones(size=(10,1,32,32))
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1,6,5)
self.pool1 = nn.AvgPool2d(kernel_size=2,stride=2)
self.conv2 = nn.Conv2d(6,16,5)
self.pool2 = nn.AvgPool2d(kernel_size=2,stride=2)
self.fc1 = nn.Linear(16*5*5,120) #这里的上层输入是图像中的全部像素
self.fc2 = nn.Linear(120,84)
def forward(self,x):
x = F.tanh(self.conv1(x))
x = self.pool1(x)
x = F.tanh(self.conv2(x))
x = self.pool2(x)
x = x.view(-1,16*5*5) #需要将数据的特征部分“拉平”才能够进入FC层
x = F.tanh(self.fc1(x))
output = F.softmax(self.fc2(x),dim=1)
net = Model()
net(data)
#卷积网络的一大特点是:改变输入数据的尺寸,整个网络就会开始花式报错
#你可以试试将数据32*32的结构修改至28*28
#安装torchinfo库,查看网络结构
!pip install torchinfo
from torchinfo import summary
net = Model()
summary(net, input_size=(10, 1, 32, 32))
这是我们在之前的课程中学到的写法,这种写法适合层数较少、层次简单的神经网络,但这个网络和我们之前写的只有线性层的网络比起来还是略有些复杂了。在这段代码中你可以清晰地看见卷积层、池化层以及全连接层是如何链接在一起共同作用的。我们将“层”放在init中定义,而将“函数”放在forward中定义,令init中的结构与forward中的结构一一对应,并使用forward函数执行向前传播流程。从今天的眼光来看,LeNet5无疑是很简单并且有些弱小的卷积网络,然而,当加入学习率衰减等优化方法并训练恰当时,单一的LeNet5模型可以在Fashion-MNIST数据集上获得超过91%的训练准确率(可参考kaggle kernel:https://www.kaggle.com/jaeboklee/pytorch-fashion-mnist-lenet5-ensemble)。这个效果已经比只有线性层的网络提升了约5%的成绩。虽然简单,LeNet5却切实展示了卷积神经网络的实力。
4.2 从浅层到深度:AlexNet
在二十一世纪的前十年,LeNet5作为现代卷积网络的奠基者并没有引起太大的水花,大多数人并不相信机器提取的特征能够比人亲自提取的特征更强大,事实上,LeNet5也确实无法在复杂任务上战胜传统计算机视觉方法。卷积网络在被提出的几十年内一直在蛰伏,直到2012年,AlexNet横空出世,真正第一次证明了,当数据量达标、训练得当时,卷积神经网络提取的特征效果远远胜过人类提取的特征。
AlexNet诞生于有“视觉界奥林匹克”之称的大规模视觉识别挑战比赛ILSVRC(ImageNet Large Scale Visual Recognition Challenge)。ILSVRC使用ImageNet数据集,共有一千四百多万幅图像,共2万多个类别,图像的尺寸有224×224,227×227,256×256,299×299等不同类型。在ILSVRC中,参赛队伍需要使用大约包含一百万张图片的训练集来训练模型,并识别出测试集中的一千个类别,再按“错误率”从低到高进行排名(具体错误率是如何计算的,将在我们使用ImageNet进行训练的时候来说明)。在AlexNet出现之前,最好成绩一直由手工提取特征+支持向量机的算法获得,最低错误率为25.8%。2012年,AlexNet进入ILSVRC竞赛,一下将错误率降低到了15.3%。在过去的ImageNet竞赛中,哪怕有一个百分点的提升都是非常不错的成绩,而深度学习首次入场就取得了10个百分点的提升,这给整个图像领域带来了巨大的震撼,从那之后图像领域的前沿研究就全面向深度学习倾斜了。AlexNet无疑是真正让“深度视觉”出圈的架构,其架构如下所示:
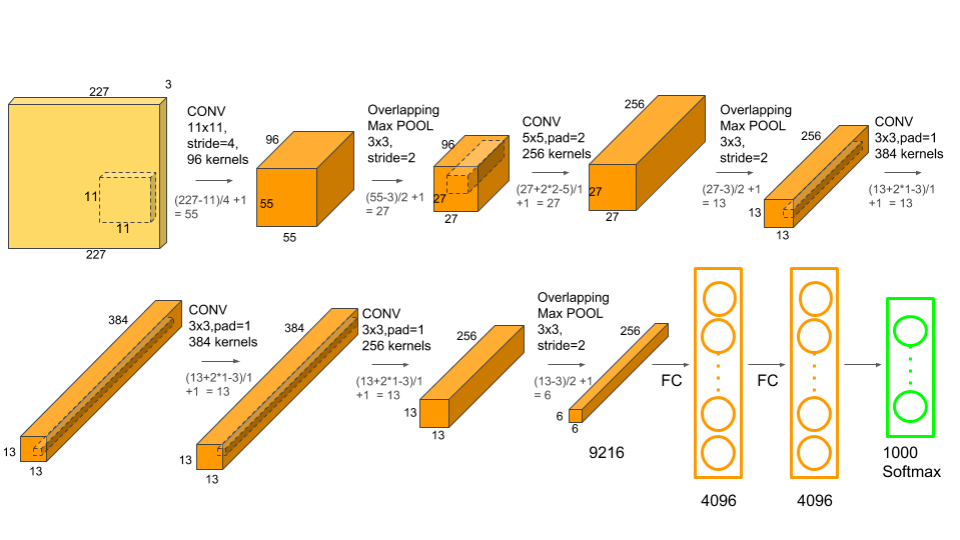
AlexNet总共有11层,其中有5个卷积层、3个池化层、2个全连接隐藏层,1个全连接输出层,实际上,在全连接层的前后AlexNet使用了Dropout层,但在大部分架构上都不会把DP表现出来。
在有的文献上,你可能看到人们称AlexNet为8层(不计算池化层)。实际上,在学术界,我们对于神经网络的“层”的计数方法没有明确的定义,有的文献会将所有卷积中的元素都算做“层”,例如、池化、BN、Dropout等都是层,而有的文献认为,只有带有训练参数的才能够被称为“层”,其他对数据进行处理的、不带训练参数的功能(如池化、激活函数、Dropout等)都属于参数层的附属。大部分文献中的架构图只会写出卷积、池化以及全连接层是如何排列,即便文献中提到使用了Dropout或BN等计算方
式,可能也不一定会明确这些计算在整体网络架构的哪一部分。在PyTorch中进行计算时,就连激活函数也可以是单独的层。因此,人们对于一个神经网络究竟有几层是没有明确定义的。在学习架构时,不用去纠结整体的层数,而要从层与层之间的组合入手。例如,AlexNet的架构若用文字来表现,则可以打包成4个组合:
输入→(卷积+池化)→(卷积+池化)→(卷积x3+池化)→(线性x3)→输出
相对的,LeNet5的架构可以打包成3个组合:
输入→(卷积+池化)→(卷积+池化)→(线性x2)→输出
虽然省略了不少细节,但是这样的组合比架构图更容易记忆,可以快速帮助你判断眼前的代码究竟依赖于怎样的经典架构来建立。
和只有6层(包括池化层)的LeNet5比起来,AlexNet主要做出了如下改变:
1、相比之下,卷积核更小、网络更深、通道数更多,这代表人们已经认识到了图像数据天生适合于多次提取特征,“深度”才是卷积网络的未来。LeNet5是基于MNIST数据集创造,MNIST数据集中的图片尺寸大约只有30*30的大小,LeNet5采用了5x5的卷积核,图像尺寸/核尺寸大约在6:1。而基于ImageNet数据集训练的AlexNet最大的卷积核只有11x11,且在第二个卷积层就改用5x5,剩下的层中都使用3x3的卷积核,图像尺寸/核尺寸至少也超过20:1。小卷积核让网络更深,但也让特征图的尺寸变得很小,为了让信息尽可能地被捕获,AlexNet也使用了更多的通道。小卷积核、多通道、更深的网络,这些都成为了卷积神经网络后续发展的指导方向。
2、使用了ReLU激活函数,摆脱Sigmoid与Tanh的各种问题。
3、使用了Dropout层来控制模型复杂度,控制过拟合。
4、引入了大量传统或新兴的图像增强技术来扩大数据集,进一步缓解过拟合。
5、使用GPU对网络进行训练,使得“适当的训练“(proper training)成为可能。
除此之外,在原论文中,作者Alex Krizhevsky还提出了其他创新,例如,他们使用了overlap pooling的技术——一般的池化层在进行扫描的时候,都是步幅 >= 核尺寸,而在AlexNet中,池化层中的步幅是小于核尺寸的,这就让池化过程中的扫描区域出现重叠(overlap),根据论文所示,这个技术可以缓解过拟合。从以上这些点,很容易看出为什么AlexNet对于卷积神经网络而言如此地重要,它几乎从算法、算力、数据、架构技巧等各个方面影响了现代卷积神经网络地发展。AlexNet之后,ImageNet竞赛上就很少看到传统视觉算法的身影了。当然,竞赛环境与工业环境有极大的区别,在实际落地的过程中,深度学习还受到各种限制,因此传统方法依然很关键。
现在,让我们在PyTorch中来复现AlexNet的架构:
import torch
from torch import nn
from torch.nn import functional as F
data = torch.ones(size=(10,3,227,227)) #假设图像的尺寸为227x227
class Model(nn.Module):
def __init__(self):
super().__init__()
#大卷积核、较大的步长、较多的通道
self.conv1 = nn.Conv2d(1,96,kernel_size=11, stride=4)
self.pool1 = nn.MaxPool2d(kernel_size=3,stride=2)
#卷积核、步长恢复正常大小,进一步扩大通道
self.conv2 = nn.Conv2d(96,256,kernel_size=5, padding=2)
self.pool2 = nn.MaxPool2d(kernel_size=3,stride=2)
#连续的卷积层,疯狂提取特征
self.conv3 = nn.Conv2d(256,384,kernel_size=3,padding=1)
self.conv4 = nn.Conv2d(384,384,kernel_size=3,padding=1)
self.conv5 = nn.Conv2d(384,256,kernel_size=3,padding=1)
self.pool3 = nn.MaxPool2d(kernel_size=3,stride=2)
#全连接层
self.fc1 = nn.Linear(256*6*6,4096) #这里的上层输入是图像中的全部像素
self.fc2 = nn.Linear(4096,4096)
self.fc3 = nn.Linear(4096,1000) #输出ImageNet的一千个类别
def forward(self,x):
x = F.relu(self.conv1(x))
x = self.pool1(x)
x = F.relu(self.conv2(x))
x = self.pool2(x)
x = F.relu(self.conv3(x))
x = F.relu(self.conv4(x))
x = F.relu(self.conv5(x))
x = self.pool3(x)
x = x.view(-1,256*6*6) #需要将数据的特征部分“拉平”才能够进入FC层
x = F.relu(F.dropout(self.fc1(x),0.5)) #dropout:随机让50%的权重为0
x = F.relu(F.dropout(self.fc2(x),0.5))
output = F.softmax(self.fc3(x),dim=1)
net = Model()
net(data)
与LeNet5实现时候的情况一致,由于输入数据的结构可能与原论文有区别,我们的网络架构中的小细节可能与原论文有些许不同。从代码量来看,其实AlexNet并没有比LeNet5复杂太多,当结构清晰时,我们甚至认为AlexNet有些简单。但在AlexNet出世之前,学术界普遍认为深度网络是不可能训练的,而今天我们都了解,只要有足够的算力和数据,即便是几亿参数的巨量网络也是可以训练的。AlexNet所带来的观念上的转变才是真正推动卷积神经网络向前发展的核心。
只要有架构图,复现经典架构其实并不是一件难事(照着敲代码,一点也不难),但我们不太可能完全记住经典架构中的每个细节。在复现架构时,我们应该注意哪些方面呢?
1、首先,代码可以不自己写,但一定要通
2、了解此架构的核心思想,以及在此思想下其结构大概如何排布。对于比较简单的网络(比如AlexNet),可以记住具体的层的结构(包括参数大概的大小),但对于复杂网络,可以不用难为自己,理解思想为主,看见代码能认出是该网络,并且看见代码之后能够理解每层具体在做什么,做的事情如何与该网络的核心思想一致。
3、了解此架构被提出的背景,即可了解它的突破与局限
4、发现架构与自己熟悉的不一致,先多谷歌下不同的架构图,或许你看到的只是别人基于经典架构修改的变体。实在纠结,再回看提出框架的具体论文。
到这里,相信大家对卷积层和池化层的应用已经有了基本的了解。作为进阶内容,大家可以试着摆脱课件中的代码,自己对着架构图复现网络架构,你甚至可以试着计算一下各层特征图的大小,将此架构改写为更简洁的形式,并利用这些架构在经典数据集上进行各种尝试。
















 6850
6850











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









