







 本文介绍了快速排序、归并排序和堆排序三种常见排序算法,通过代码示例和原理阐述,以及topK问题的应用,展示了这些算法在IT技术中的重要性。
本文介绍了快速排序、归并排序和堆排序三种常见排序算法,通过代码示例和原理阐述,以及topK问题的应用,展示了这些算法在IT技术中的重要性。
百日筑基篇——排序算法二(算法篇)
前言
排序算法有许多,而本章则主要简单介绍一下三个算法:快速排序、堆排序、归并排序。
一、快速排序
取一个元素P(第一个元素),使元素P归位。
即列表被P分成两部分,左边比P小,右边都比P大。
将左侧和右侧的子列表递归地进行排序,直到子列表只包含一个元素或为空,则排序完成。
def quick_sort(li):
if len(li) <= 1:
return li
else:
pivot = li[0]
less = [x for x in li[1:] if x <= pivot]
greater = [x for x in li[1:] if x > pivot]
return quick_sort(less) + [pivot] + quick_sort(greater)
# 测试
li = [5, 2, 8, 9, 1, 3, 7, 67, 54, 76, 34, 98, 87]
sorted_li = quick_sort(li)
print(sorted_li)
- 首先,检查列表是否只包含一个元素或为空,如果是,则直接返回该列表
- 否则,选择第一个元素作为P值(pivot),使用列表推导式将小于等于P值的元素放在less列表中,大于P值的元素放在greater列表中
- 最后,通过递归地对less列表和greater列表调用quick_sort函数来完成排序
- 最终,函数返回以P值为中心的排序好的列表
二、归并排序
归并排序是一种分治算法,它将待排序的数组分成两个子数组,分别进行排序,最后将排序好的子数组合并起来
同时也运用到了递归的思想
使用归并:
- 分解:将列表越分越小,直至分成一个元素
- 合并:将两个有序列表归并,列表越来越大。
如图所示:
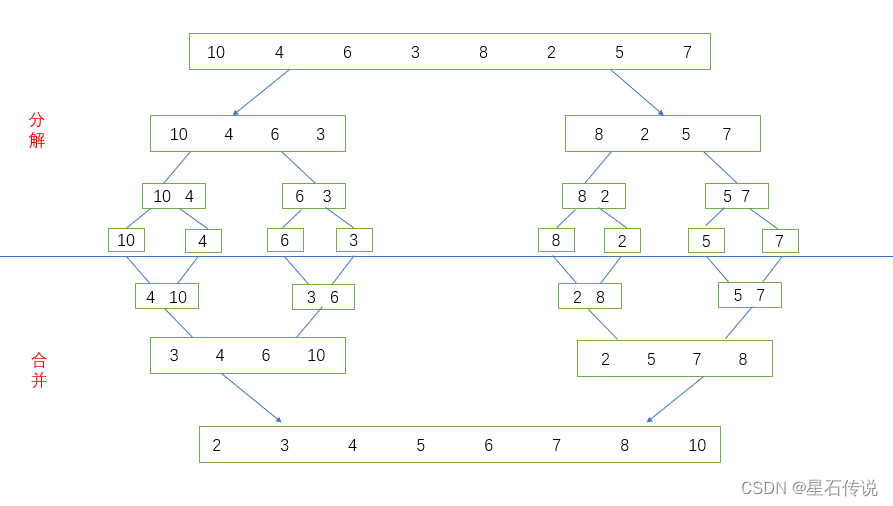
def merge(li, low, mid, high):
i = low
j = mid + 1
tmp = []
while i <= mid and j <= high: # 只要左右两边都有数
if li[i] < li[j]:
tmp.append(li[i])
i += 1
else:
tmp.append(li[j])
j += 1
# 处理剩余的元素
while i <= mid:
tmp.append(li[i])
i += 1
while j <= high:
tmp.append(li[j])
j += 1
li[low:high + 1] = tmp
def merge_sort(li, low, high):
if low < high:
mid = (low + high) // 2
merge_sort(li, low, mid)
merge_sort(li, mid + 1, high)
merge(li, low, mid, high)
return li
merge():该函数用于合并两个有序子数组。
-
首先,定义两个指针i和j分别指向左子数组和右子数组的起始位置。
-
然后,通过比较左右子数组的元素,按顺序将较小的元素添加到临时列表tmp中。
-
最后,将剩余的元素添加到临时列表tmp中,并将临时列表的内容复制回原始列表li的相应位置。
merge_sort():该函数用于递归地进行归并排序操作
- 首先,如果low小于high,则继续进行操作。然后,计算子列表的中间索引mid。
- 接下来,调用merge_sort函数对左半部分进行递归排序,然后,对右半部分进行递归排序.
- 最后,调用merge函数对排序后的左右子列表进行合并,返回排序好的列表li。
三、堆排序
堆排序是一种基于完全二叉树的排序算法,它利用堆的性质进行排序。步骤如下:
- 构建一个堆(大根堆或小根堆),使得堆顶元素为最大或最小值。
- 将堆顶元素和最后一个元素交换位置,然后减少堆的大小。
- 重复步骤2,直到堆为空。
3.1 树
树是一种可以递归定义数据结构,由许多节点组成的集合。
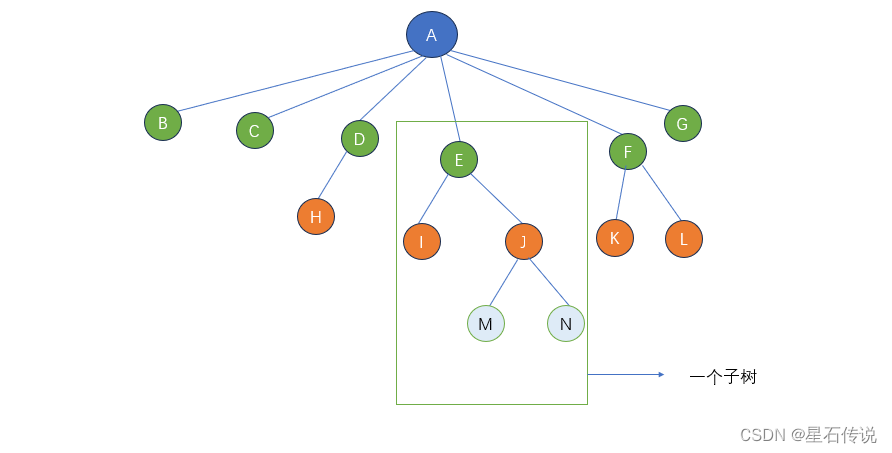
从这个树的图中可看出:
- 根节点与叶子节点(A为根节点;B、C…,即下面无分叉的为叶子节点)
- 树的高度(如图中的树高度为4)
- 树的度(整个树哪个节点分叉最多,如A节点分叉最多,则度为6)
- 孩子/父节点 (如A是B的父节点,B是A的孩子节点)
- 子树(将整个树的一部分单拿出来,如图中)
3.2 二叉树
树的度不超过2的树,即每个节点最多有两个孩子节点。
完全二叉树:
叶子节点只能出现在最下层和次下层,且最下面一层的节点都集中在该层的最左边的若干位置的二叉树
满二叉树:
一个每一层的节点数都达最大值的二叉树,是完全二叉树的特殊情况。
完全二叉树示例图:
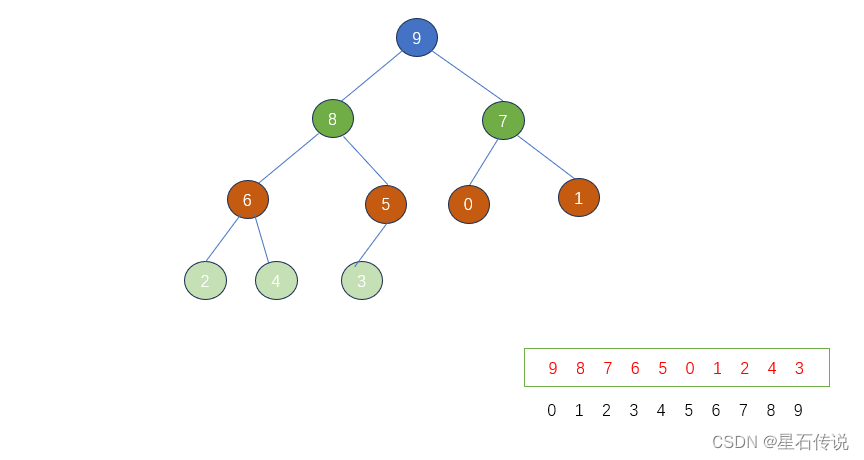
二叉树的顺序存储方式:
父节点(i)与左孩子节点的编号下标之间关系:
0–1;1–3;2–5;3–7;4–9
故有 i — 2i+1
与右孩子节点…:
i — 2i+2
3.3 堆
堆是一种特殊的完全二叉树结构,它是有序的,分为大根堆和小根堆
大/小根堆:一棵完全二叉树,满足任一节点都比其孩子节点大/小
如何建堆:
堆的向下调整性质:
(假设根节点的左右子树都是堆,但是根节点不满足堆的性质,可以通过一次向下的调整,将其变为一个堆)
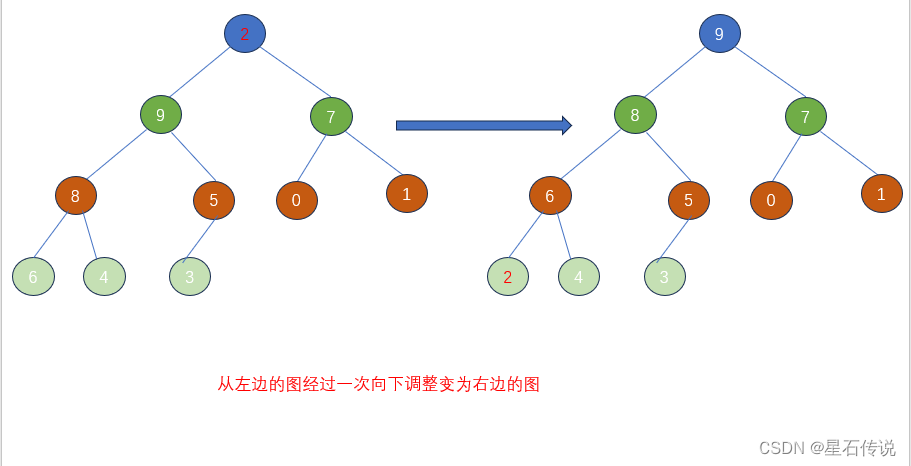
因为 2 比9 和7 小,则 2 向下,9 上位;接着再比较,有 2 继续向下,8上位;2 继续向下,6 上位。最终构建出了大根堆。
建堆一般遵从:从上到下,(同一层)从左到右的原则
3.4 堆排序代码实现
#向下调整函数
def sift(li, low, high):
i = low # i最开始指向根节点
j = 2 * i + 1 # 最开始是左孩子节点
tmp = li[low] # 将根节点存起来
while j <= high:
if j + 1 <= high and li[j + 1] > li[j]:
j = j + 1
if li[j] > tmp:
li[i] = li[j]
i = j
j = 2 * i + 1
else:
li[i] = tmp
break
else:
li[i] = tmp
#堆排序
def heap_sort(li):
n = len(li)
for i in range(n - 2 // 2, -1, -1):
sift(li, i, n - 1)
for i in range(n - 1, -1, -1):
li[0], li[i] = li[i], li[0]
sift(li, 0, i - 1)
return li
向下调整函数:
- 通过传入一个列表 li,以及要调整的范围 low 到 high,在该范围内进行元素的向下调整操作。
- 首先,先存储根节点的值为 tmp,
- 然后根据左孩子和右孩子的大小比较,选择较大的孩子节点进行交换。如果孩子节点的值大于 tmp,则将孩子节点的值赋给当前节点并继续向下进行调整,
- 否则将 tmp 的值赋给当前节点并结束调整。
堆排序函数:
- 首先,通过循环从最后一个非叶子节点开始,逐个向上遍历到根节点,在每次循环中,对当前节点进行向下调整操作,以构建一个大根堆。
- 然后,通过循环将堆顶元素与最后一个元素交换位置,并对剩余元素进行向下调整,以重新构建最大堆。重复这个过程直到所有元素都被排序。最后,返回排序后的列表。
3.5 python内置模块实现
import heapq
def heap_sort(li):
heapq.heapify(li) # 建小根堆
result = []
while li:
result.append(heapq.heappop(li))
return result
li = [3, 5, 6, 7, 3, 2, 5, 8, 9, 1]
list_new = heap_sort(li)
print(list_new)
四、topK问题
Top-K 问题是指从一个数据集中找出前 K 个最大(或最小)的元素。常见的解决方法有使用堆数据结构
- 取列表前K个元素建立一个小根堆,堆顶就是目前第K大的数,
- 对于数据集中的剩余元素,依次进行以下操作:判断当前元素是否大于小根堆的堆顶元素。如果大于,则将堆顶元素替换为当前元素,并进行堆调整。
- 遍历列表的所有元素后,倒序弹出堆顶
import heapq
def find_top_k(nums, k):
heap = []
for num in nums:
if len(heap) < k:
heapq.heappush(heap, num)
else:
if num > heap[0]:
heapq.heappushpop(heap, num)
top_k = sorted(heap, reverse=True)
return top_k
k = 4
li = [5, 3, 8, 2, 7, 1, 6, 4]
result = find_top_k(li, k)
print(result)
#结果
[8, 7, 6, 5]
总结
总的来说,对于这三种排序:
- 快速排序:通过选取一个P值,将列表划分为两个子序列(左边小于,右边大于),然后递归地对子序列进行排序。
- 归并排序: 将列表递归地划分为两个子序列,然后合并过程中对子序列进行排序。
- 堆排序: 将列表构建成一个堆,然后不断将堆顶元素与末尾元素交换,并对剩余元素进行向下调整操作,重新构建堆。(重复这个过程直到所有元素都被排序)
洛阳亲友如相问,一片冰心在玉壶。
–2023-8-2 算法篇


















 173
173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











