







目录
一.领域现状
目标检测长期发展以来two-stage算法(RCNN系列)占据地位,直至YOLO和SSD等one-stage算法的出现。
从R-CNN到Faster R-CNN一直采用的思路是proposal+分类 (proposal 提供位置信息, 分类提供类别信息)精度已经很高,但由于two-stage(proposal耗费时间过多)处理速度不行达不到real-time效果。
二.YOLOv1思想
1.Detection转化为Regression
YOLO提供了另一种更为直接的思路: 直接在输出层回归bounding box的位置和bounding box所属的类别(整张图作为网络的输入,把 Object Detection 的问题转化成一个 Regression 问题)。
算法首先把输入图像划分成S×S的格子,然后对每个格子都预测B个bounding boxes,每个bounding box都包含5个预测值:x,y,w,h和confidence。

x,y是bounding box的中心坐标,与grid cell对齐(即相对于当前grid cell的偏移值),使得范围变成0到1;
w,h进行归一化(分别除以图像的w和h,这样最后的w和h就在0到1范围)。
confidence代表了所预测的box中含有object的置信度和这个box预测的有多准的两重信息:

如果ground truth落在这个grid cell里,那么Pr(Object)就取1,否则就是0,IOU就是bounding box与实际的groud truth之间交并比,confidence是二者(Pr(Object)和IOU)乘积。
在yolov1中作者将一幅图片分成7x7个网格(grid cell),由网络的最后一层输出7×7×30的tensor,也就是说每个格子输出1×1×30的tensor。30里面包括了2个bound ing box的x,y,w,h,confidengce以及针对格子而言的20个类别概率,输出就是 7x7x(5x2 + 20) 。

(通用公式: SxS个网格,每个网格要预测B个bounding box还要预测C个categories,输出就是S x S x (5×B+C)的一个tensor。 注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的)
如何判断一个grid cell中是否包含object呢?
答案是:如果一个object的ground truth的中心点坐标在一个grid cell中,那么这个grid cell就是包含这个object,也就是说这个object的预测就由该grid cell负责。
每个grid cell都预测C个类别概率,表示一个grid cell在包含object的条件下属于某个类别的概率。
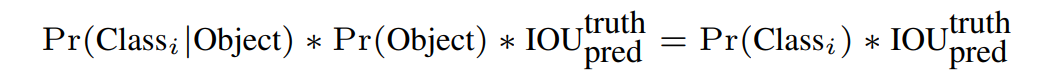
二.网络结构
该论文提出的网络结构,包括 24 个卷积层,最后接 2 个全连接层。文章设计的网络借鉴 GoogleNet 的思想,在每个 1∗11∗1 的 归约层(Reduction layer) 之后再接一个 3∗33∗3 的卷积层的结构替代 Inception结构。文章中还提到了 fast 版本的 Yolo,只有 9 个卷积层,其他的结构基本一致。网络的主体结构如下:

三.损失函数
四.训练策略
该论文的训练策略,总体给人的感觉:比较复杂,技巧性比较强。可以看得出作者为了提升性能花了不少功夫。
1.首先利用 ImageNet 的数据集 Pretrain 卷积层。使用上述网络中的前 20 个卷积层,外加一个全连接层,作为 Pretrain 的网络,训练大约一周的时间,使得在 ImageNet 2012 的验证数据集 Top-5 的准确度达到 88%,这个结果跟 GoogleNet 的效果相当。
2.将 Pretrain 的结果应用到 Detection 中,将剩下的 4 个卷积层及 2 个全连接层加入到 Pretrain 的网络中。同时为了获取更精细化的结果,将输入图像的分辨率由 224224 提升到 448448。
3.将所有的预测结果都归一化到 0~1, 使用 Leaky RELU 作为激活函数。
4.对比 localization error 和 classification error,加大 localization 的权重.
5.在 Pascal VOC 2007 和 2012 上训练 135 个 epochs, Batchsize 设置为 64, Momentum 为 0.9, Decay 为 0.0005.
在第一个 epoch 中 学习率是逐渐从0.001增大到 0.01,然后保持学习率为0.01,一直训练到 75个 epochs,然后学习率为0.001训练 30 个 epochs,最后 学习率为0.0001训练 30 个 epochs。
6.为了防止过拟合,在第一个全连接层后面接了一个 ratio=0.5ratio=0.5 的 Dropout 层。并且对原始图像做了一些随机采样和缩放,甚至对调节图像的在 HSV 空间的饱和度。
五.实验结果
从实验结果上来看,Yolo在速度上有很大的优势,在 mAP 与 state of art 的结果还有不少差距。


六.论文总结
1…YOLO(v1)的优点
1.速度快,能够达到实时的要求。在 Titan X 的 GPU 上 能够达到 45 帧每秒。
2.使用全图作为 Context 信息,背景错误(把背景错认为物体)比较少。
3.泛化能力强。
2…YOLO(v1)的缺陷
1.YOLO对相互靠的很近的物体(挨在一起且中点都落在同一个格子上的情况),对很小的物体检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
2.测试图像中,当同一类物体出现的不常见的长宽比和其他情况时泛化能力偏弱。
3.由于损失函数的问题,定位误差是影响检测效果的主要原因,尤其是大小物体的处理上,还有待加强。
3.后续工作进展
由于没有手撸过YOLO代码,因此暂时不对损失函数做深入探讨,后续会更新本文。















 8923
8923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









