






You Only Look Once: Unified,Real-Time Object Detection
原文链接
CVPR 2016 Open Access Repository (cv-foundation.org)
Abstract 摘要
Yolo使用一个神经网络通过一次评估从图片中预测出物体的anchor和分类的置信度。与当时其他的目标检测模型相比,yolo是一个端到端模型,预测速度很快,会更多的产生定位错误而更少的在背景区域产生假阳性(false positive,将没有物体的区域判断为有物体)误判
- Introduction 简介
一个快速且精准的物体检测系统,可以使得辅助设备向使用者提供实时的场景信息,从而使更多更高效的功能有可能实现。
传统的物体检测分类方法将定位于分类分开处理,系统过于复杂,使得运行速度慢且难以调整,各个模块需要分别进行训练。
而yolo将分类与定位两个问题结合在一起,可以直接从像素信息中预测出物体的边框与分类置信度。
Yolo的运行速度很快,并且在实时系统上表现很好。
Yolo有更好的全局视野。相比于传统的滑窗法,yolo在训练和与测试时从全局的信息进行推断,在分类和定位时毫无保留地对上下文信息进行编码。
Yolo泛化能力更强。在引用于新的领域以及特殊的输入时,yolo的表现强于当时其他模型。
Yolo的准确度上落后于当时其他模型,尤其是小物体。
- Unified Detection 检测模式
将分离的物体检测组件整合到一个神经网络中。Yolo从图片的全部信息中预测每一个边框,同时对每一个边框进行分类。这种结构使得yolo可以进行端到端训练,且在满足实时低时延的高速处理时保持高准确率。
Yolo系统将输入图像分割成S*S的网格。物体的中心点落入哪个网格中就由这个网格负责检测出该物体。
每个网格预测B个边框以及该框的置信度(是框中是否存在物体的置信度,而不是分类的置信度)。定义其为 ,我们希望:如果网格中没有物体,则
,我们希望:如果网格中没有物体,则![]() ,否则
,否则 。
。
每个边框包括五个维度的信息:x,y,w,h,C。其中(x,y)表示边框中心点在网格中的位置,(w,h)表示边框的宽和高,C表示预测框与真实物体边框的交并比。
每一个网格会预测一组其包含各类物体的条件概率PClassiObject![]() ,而不对每个边框单独预测。每个边框的分类置信度可以通过下式计算。
,而不对每个边框单独预测。每个边框的分类置信度可以通过下式计算。

根据上述设计,若预测时可以对N类物体进行分类,则网络输出的张量维度为
![]()
- Network Design 网络架构
灵感来源于GoogLeNet,yolo网络层次包含24个卷积层与2个全连接层,每个卷积层后接1*1的收缩层和3*3的卷积层

yolo网络结构示意图
- Training 训练
在原结构上适当增加卷积层和全连接层可以提升网络效果
使(x,y)除以网格大小,(w,h)除以图片尺寸,将他们归一化可以提高收敛速度
简单实用残差平方和所谓误差估计,位置信息和置信度的预测对调整参数的影响无法区分。且假阳性预测对梯度下降的影响较大,会使模型参数不稳定而在训练时发散。而
故对包含了物体的网格中的loss进行了加重,而对不包含物体的网格中的loss进行减轻,设定参数![]() 和
和![]() 进行权重区分,文中预设
进行权重区分,文中预设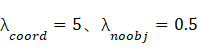 。
。
残差平方和对大边框和小边框的loss也没有区分,而实际中小边框对残差的敏感程度大于大边框。所以在计算(w,h)的loss时使用根残差平方和,来对放大残差对小边框的loss的影响(因为已经预先进行了归一化)。
我们指定一个预测器只负责预测一个边框与其具有最高IOU的物体,这使得每个网格的预测器之间产生差异。每个预测器对特定的大小、角度、种类的物体预测效果更好,从而提升整体召回率( )
)

Loss定义式
- Inference 推断
不同于其他基于分类器的物体检测方法,Yolo只需要通过一个网络进行预测,所以yolo的预测速度很快。
当图片中有大型物体穿过多个网格时,在预测结果中会出现多个边框,这时通过非极大抑制法来消除重复检测。
非极大抑制法:
- 对预测结果中同类的所有边框按置信度进行排序,选出置信度最高的
- 输出该边框,但遍历其余边框,删去与其IOU超过预设的阈值的边框
- 对剩余未处理的边框集合进行同样的操作,直到所有的预测结果都经过了上述方法的筛选
为了避免过拟合,使用了dropout和数据增强
- Limitation of YOLO YOLO的局限性
- Yolo有很强的空间局限性
由于在一个划分好的网格中只能预测预设好的B个边框和一个分类的物体,yolo在面对成群的小物体时表现很无力。
- Yolo采用全监督的训练模式
由于yolo的参数学习都来自于输入的数据,yolo在面对未训练到的特殊角度和分布时表现不佳。
- Yolo对尺度不同的边框在小误差情况下计算loss时区分度不足
在小边框预测中,准确度对误差敏感度非常高,虽然在loss函数通过根残差平方和的计算方法中对小边框的误差进行了加重修正,但是修正量仍然不足。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









