






理解临床术语系统可以分为不同类别是非常重要的,因为这些分类帮助医学专业人员有效地组织和使用医学术语,确保语义一致性,并选择最适合特定应用场景的系统。并且,现在临床数据体系的标准化分类不仅促进了医学信息的交流和共享,还提升了医疗信息管理的整合性和互操作性,从而支持临床实践、研究和健康信息技术的发展,改善了医疗服务的质量和效率。
我们可以将临床术语系统大致分为以下几类:
-
词库:
- 使用接近自然语言的语义关系来关联现有术语。
- 例如医学主题词(MeSH)。
-
聚合术语或分类法:
- 使用规则将个体实体归类到不重叠的类别中。
- 例如ICD-10分类。
-
本体:
- 通过基于逻辑的公理来分类对象并描述其关系。
- 例如SNOMED CT或开放生物医学本体(OBO)Foundry。
总体而言,词库提供术语及其之间的简单语义关系,如同义词,而本体则通过精确的数学表达描述实体的属性和关系,即提供形式语义和组成的语法规则。然而,仅使用术语标准中的代码是不够的,因为缺乏实际或上下文方面的内容。

医学主题词(MeSH)
医学主题词(MeSH)是由美国国家医学图书馆(NLM)创建的一个综合的受控词汇表,用于生命科学领域的期刊文章和书籍的索引和检索。作为一个词库,MeSH 促进了信息的检索和组织,主要应用于 MEDLINE/PubMed 数据库和 NLM 的图书目录。
1. 起源与早期发展(1947-1960 年代)
-
1947 年:MeSH 的前身出现,称为“Subject Heading Authority List”(主题词权威列表),用于分类美国国家医学图书馆(NLM)馆藏的书籍和期刊。这一列表是基于 1940 年代开发的军队医学图书馆分类法(Army Medical Library Classification System)。
-
1954 年:NLM 引入了“Index Medicus Subject Headings”系统,为索引医学文献开发更为系统的术语列表。
-
1960 年:正式推出 MeSH 词表,包含 4000 个术语,标志着现代 MeSH 系统的开始。MeSH 词表成为了索引《Index Medicus》(一本详细列出医学文献的期刊)的标准工具。
2. 扩展和电子化(1970-1990 年代)
-
1970 年代:随着计算机技术的发展,MeSH 词表逐渐电子化。NLM 开始使用计算机辅助的索引系统,极大地提高了文献索引的效率和准确性。
-
1980 年代:MeSH 词表扩展到包含超过 10,000 个术语,进一步增强了索引和检索医学文献的能力。NLM 开发了在线检索系统(如 MEDLINE),使研究人员和医疗专业人员能够更方便地访问和检索生物医学文献。
3. 国际化和多语言支持(2000 年代至今)
-
2000 年代初:NLM 推出了多语言 MeSH 版本,支持英语、法语、西班牙语、葡萄牙语等多种语言,促进了全球范围内的医学信息共享和交流。
-
2010 年代:NLM 不断更新和扩展 MeSH 词表,新增了许多现代医学和生物医学技术术语,以反映学科的快速发展。同时,NLM 推出了基于 Web 的 MeSH 浏览和检索工具(如 MeSH Browser),进一步提升用户体验和检索效率。
在 PubMed 中,MeSH 提供扩展搜索功能,使检索更加精确。MeSH 词汇表不仅限于英语,还翻译成多种语言,方便全球用户使用。MeSH 的详细信息和使用可以通过其官网(MeSH官网)获取。
MeSH的结构分类
- 主题词(Descriptors):描述文章的主题,并附有定义、相关词和同义词。
- 子目(Qualifiers):与主题词结合,描述特定方面,如"哮喘/药物治疗"。
- 出版类型(Publication Types):描述文章类型。
- 补充概念记录(Supplementary Concept Records, SCRs):描述化学物质和药物等,不包含在主题词中。
在 MEDLINE/PubMed 中会被索引约10-15个主题词和子目。自动映射功能帮助用户更准确地检索文献。在 ClinicalTrials.gov 中,MeSH 关键词用于描述临床试验的研究疾病和干预措施。MeSH 是一个重要的工具,帮助医学和健康信息的检索和管理,促进了全球范围内的学术交流和研究合作。

系统化的医学术语临床术语(SNOMED CT)
SNOMED CT,即系统化的医学术语临床术语(Systematized Nomenclature of Medicine Clinical Terms),是一套系统化、计算机可处理的医学术语集合,提供了用于临床文档和报告的代码、术语、同义词和定义。它被认为是世界上最全面的多语言临床医疗术语体系。
SNOMED CT 的主要目的是对健康信息中使用的含义进行编码,支持有效的临床数据记录,旨在改善患者护理。SNOMED CT 提供了电子健康记录的核心通用术语,包括:临床发现、症状、诊断、程序、身体结构、病原体、物质、药品、设备和标本等。
SNOMED CT 由SNOMED International 维护和分发,该组织是位于英国伦敦的国际非营利标准开发组织。SNOMED International 负责SNOMED CT 的“持续维护、开发、质量保证和国际分发”,成员包括世界上许多领先的电子健康国家和地区。
SNOMED 于1965年作为系统化的病理学术语(SNOP)开始,后来发展成为基于逻辑的医疗术语。1999年,SNOMED 通过与两个大型术语体系的合并、扩展和重组创建了SNOMED CT:即美国病理学会(CAP)开发的SNOMED 参考术语(SNOMED RT)和英国国家医疗服务体系(NHS)开发的临床术语版本3(CTV3)。最终产品于2002年发布。
结构
SNOMED CT 包含四个主要核心组件:
- 概念代码(Concept Codes):识别临床术语的数字代码,组织在层级结构中。
- 描述(Descriptions):概念代码的文本描述。
- 关系(Relationships):具有相关含义的概念代码之间的关系。
- 参考集(Reference Sets):用于将概念或描述分组为集合,包括参考集和跨分类标准的映射。
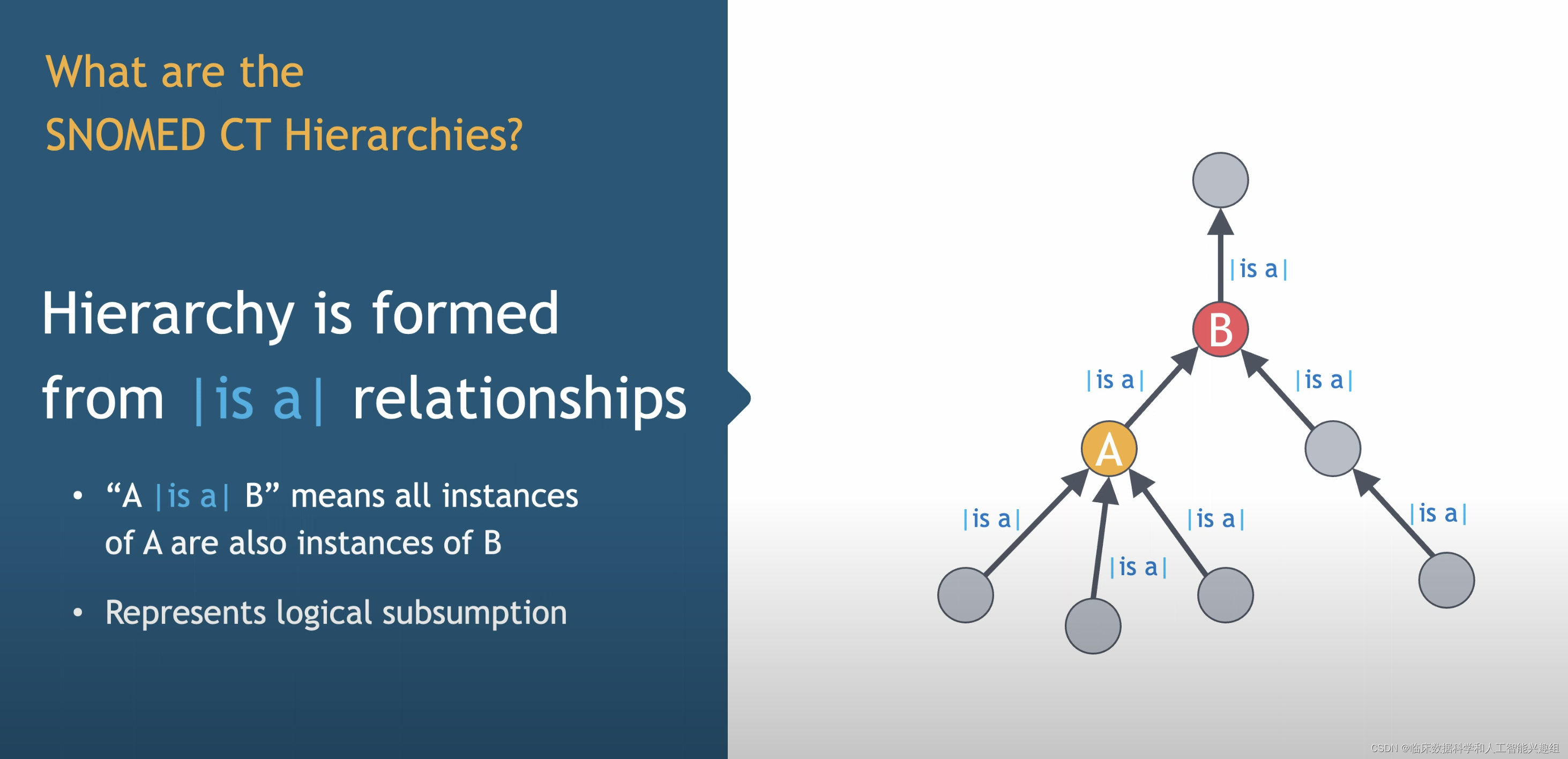
SNOMED CT 的“概念”是表示单位,分类所有需要在医疗过程中记录的事项。这些概念按非循环的分类层次结构组织,例如“病毒性肺炎”是“感染性肺炎”的一种,“感染性肺炎”是“肺炎”的一种。概念通过各种临床术语或短语进一步描述,这些描述分为完全指定名称(FSN)、首选术语(PT)和同义词。每个概念有一个唯一的FSN,一个PT,可能有多个同义词。SNOMED CT 为每个概念分配一个语义标签,存在于每个概念的完全指定名称中的括号内。例如,“药品/生物制品”顶层层次结构使用的语义标签包括:产品、药品、药品形式和临床药物。
SNOMED CT 被用于多种方式,包括:
- 在提供医疗服务时捕获详细的临床信息。
- 通过数据共享,减少每次与新医疗专业人员接触时重复健康历史的需要。
- 允许在不同地点由不同的人记录信息,并将其合并到患者记录中的简单信息视图中。
- 使用通用术语减少信息解释的潜在差异。
- 支持基于FHIR标准的结构化数据捕获医疗表单和问卷。
SNOMED CT 也被用在许多计算机应用程序中,如电子健康记录系统(EHRs)、计算机化医生订单输入(CPOE)、临床决策支持系统(CDSS)等。
SNOMED CT 的使用需要许可证。许可证有两种类型:
- 国家/地区成员资格,根据国民生产总值收费。
- 附属许可证,根据最终用户数量收费。
用于医学信息学科学研究、演示或评估目的的SNOMED CT资源可以免费下载和使用。注册的统一医学语言系统(UMLS)用户可以访问SNOMED CT的原始资源。
临床数据在语境和实际应用情景
然而,仅使用术语标准中的代码是不够的,还需要考虑语境和实际应用的方面。例如,“哮喘”这一术语需要嵌入信息模型中才能完整表达其含义。许多数据源缺乏这种嵌入,默认情况下,一个临床数据集中的代码代表了该数据集创建时存在的实例,这通常是不够的。以“发烧”为例,仅使用SNOMED CT的“发烧(发现)”概念,无法明确是患者报告的发烧还是由医疗专业人员测量的发烧,测量过程也没有说明。这些语境和溯源信息的提供属于(临床)信息模型的范畴。
为了避免数据孤岛,尽管有详细的临床模型(DCMs)(如ISO/TS 13972:2015)等标准被提出,但制造商对这些标准的采纳及其嵌入标准化术语的程度仍然较低。Alan Rector曾将本体和信息模型之间的区别描述为意义模型与使用模型的区别。本体表达和定义了对于一个类的所有成员普遍适用的内容,而临床模型则表达了关于作为临床信息主要参照对象的个体的各种语境陈述。术语/本体标准和信息模型标准之间的明确界限问题被称为边界问题。

Alan Rector 是一位著名的计算机科学家和医学信息学家,专注于生物医学信息学领域。他在本体论和语义网络的研究方面做出了重要贡献。Alan Rector 教授在医学信息学中的工作尤其突出,他的研究涉及医学本体、知识表示、信息集成和语义标准化等领域。他将本体和信息模型之间的区别表述为意义模型与使用模型。本体表达和定义了对所有类成员(或概念实例)普遍真实的内容,而临床模型则表达了关于作为临床信息主要参照对象的个体的各种上下文声明。术语/本体标准和信息模型标准之间的适当划分被称为边界问题。理论上,这一区别等同于本体论和认识论之间的对比。然而,两类标准之间的重叠带来了主要挑战,以防止所谓的等语义模型的出现,例如在一起使用术语和信息模型时。
其它重要的医疗数据标准
| 标准制定组织 | 标准 | 范围 |
|---|---|---|
| 解剖学术语联合委员会(FCAT) | Terminologia Anatomica (TA) | 英文和拉丁文的解剖学术语 |
| Health Level Seven (HL7) | v2 | 消息传递协议;该标准的多个章节涵盖临床内容 |
| v3 (RIM) | 信息本体;“临床声明”工作旨在创建可重用的临床数据标准 | |
| CDA Level 1–3 | 临床文档的信息模型(在第2级和第3级中嵌入术语标准);尤其是护理连续性文档(CCD)和统一的CDA(C-CDA)规范增加了临床文档标准的细节 | |
| FHIR | 信息和文档模型;核心规范的多个部分涉及临床内容 | |
| 整合医疗企业(IHE) | 多种整合概况 | 包括引用要使用的临床数据标准的临床工作流程 |
| 国际标准化组织(ISO) | TS22220:2011 | 护理对象的识别 |
| 21090:2011 | 信息交换的统一数据类型 | |
| 13606 | 临床信息模型的高层描述 | |
| 23940 (ContSys) | 护理连续性的健康护理过程 | |
| 14155 | 临床研究 | |
| IDMP | 药品 | |
| 国家电气制造商协会(NEMA) | DICOM | 医学影像及相关数据 |
| openEHR基金会 | openEHR | 临床信息模型规范 |
| Regenstrief研究所 | LOINC | 实验室和其他可观察项目的术语 |
| UCUM | 根据SI单位(ISO 80000)标准化表示单位 | |
| 个人连接健康联盟(PCHAlliance) | Continua Design Guidelines | 收集个人健康设备的数据 |
| SNOMED International | SNOMED CT | 电子健康记录的术语/本体(“语境模型”= SNOMED CT的信息模型) |
| 世界卫生组织(WHO) | ICD-10 / ICD-11 | 疾病分类 |
| ICF | 功能、残疾和健康分类 | |
| ICHI | 健康程序分类 | |
| INN | 药物通用名称 | |
| ATC | 药物成分分类 | |
| 世界家庭医生组织(WONCA) | ICPC | 初级保健分类 |
标准的质量和可用性
临床数据的标准工具对于临床数据的支持越多,它们就越能支持语义互操作性。数据项在语义上是互操作的,如果数据创建者所意图的含义被数据接收者完全理解。假设有两个描述年龄组的数据项:D1包含英文单词“adolescent”,D2包含属性-值对:年龄(年):[14.0; 17.999]。只要没有一致的定义来说明D1对应的年龄区间(根据不同来源有不同的区间),就可能出现关于D1和D2是否等价的误解。这种情况在人类使用自然语言进行交流时非常典型。
专业术语解释
-
语义互操作性:这是指不同系统之间能够准确理解和使用彼此的数据的能力。换句话说,数据的含义在不同系统中保持一致,不会被误解。
-
数据项:这是指在数据集中记录的一个具体的值或信息单元,比如一个人的年龄、血压等。
-
属性-值对:这是用来表示数据的一种方式。例如,“年龄(年):[14.0; 17.999]”中的“年龄”是属性,“[14.0; 17.999]”是值。
-
自然语言:这是人类日常使用的语言,比如英语、中文等。自然语言往往含义丰富且灵活,但也因此容易引起误解。
只有当创建者和接收者共享相同的词汇,并且这些词汇在相同的上下文中具有相同的基本含义时,才能避免上述的误解。统一医疗保健中的含义是临床数据标准的主要依据。如有一个标准,将“adolescent”一词定义为“人类年龄在14岁以上但未满18岁”。
然而,问题在于词汇并不总是由标准组织控制,并且同一个标准可以以不同的方式定义它。最后,许多语言使用者可能以多种方式使用“adolescent”一词。换句话说,为了避免误解,数据创建者和接收者必须在相同的上下文中理解相同的词汇。标准化的定义在医疗保健中非常重要,但要注意的是,不同标准和不同语言使用者可能对相同的词汇有不同的理解。
这就是为什么在一些临床模型中,用户总是需要提供不仅是值(例如“adolescent”),还要提供一个引用,指向将特定定义附加到该值的标准。其他临床模型规定使用特定术语作为其定义的一部分,从而克服了每次使用该临床模型时引用特定标准的负担。但即使在这种情况下,如果没有对值的含义进行规范,标准通常也无法发挥其作用。
例如,SNOMED CT从一个命名法向一个本体标准的过渡尚未完成,因此概念“Adolescent (person)”的SCTID 133937008缺乏正式和文本定义,这使其作为一个标准是不充分的,因为用户对“adolescent”一词的理解只能依赖他们各自的理解,而这些理解在不同语言和司法管辖区之间有所不同。
临床数据标准的实施
临床数据标准的实施仅在其服务于公认且可观察到的目的时才有意义。这些目的可以来源于多种渠道,包括市场上的商业利益、组织内部的经济利益,以及法律法规所规定的社会利益。对于医疗数据来说,标准实施的益处对记录数据的个人用户而言并不总是显而易见的,因此要在各方之间建立一个共同的目标变得尤为重要。在医疗保健领域,数据标准的实施通常出于以下几种非常明确的目的之一或其组合:
1. 改善患者诊断和治疗过程的结果
数据标准的实施旨在改善涉及医疗专业人员团队的个别患者的诊断和治疗过程的结果。例如,基于患者特征的计算机临床指导系统已经促使乳腺癌诊断中多个参数的标准化记录,以支持创建最佳的个人治疗计划。这种标准化记录使得医疗团队能够更准确地分析患者的数据,从而制定出更加个性化和有效的治疗方案,提高了治疗的成功率和患者的生存质量。
2. 服务于地方或国家卫生系统
数据标准的实施也为地方或国家卫生系统服务,包括报销、质量报告、公共卫生、卫生技术评估和临床研究等方面。例如,监控糖尿病患者所提供护理的质量已经导致关键过程指标以及近端和远端结果的结构化记录。这些结构化数据可以帮助卫生系统更好地评估和改进医疗服务的质量,确保患者能够获得最佳的护理。同时,这些数据也为公共卫生政策的制定提供了重要的依据,促进了整体社会的健康水平提升。
3. 增强商业利益
数据标准的实施还为增强商业利益创造了机会,吸引了对患者和/或专业人员在健康管理和医疗服务提供中所需解决方案的投资。例如,典型放射科设备的多样性已经导致DICOM标准在数字成像中的早期和几乎完全实施,从而使多个供应商可以进入医疗成像设备市场。这样的标准化使得不同厂商的设备能够互相兼容,提高了市场竞争力,最终受益的是医疗机构和患者,因为他们可以获得更多选择和更高质量的服务。


















 742
742

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











