






随着在线平台的兴起,用户评论成为了企业和产品的重要反馈渠道。这些评论不仅包含了用户对产品或服务的满意度,还反映了用户的情感和对品牌的整体感知。通过对这些评论进行有效的分析,企业能够深入了解用户的需求、改进产品、优化用户体验,甚至预测未来的市场趋势。然而,面对海量的评论数据,如何高效、全面地处理和分析这些信息,仍然是一个巨大的挑战。本文将通过R语言展示一种复杂的用户评论分析方法,涵盖文本预处理、主题建模、情感分析以及数据可视化等多个层面,帮助企业从海量评论中提取出有价值的信息。
在本次分析中,我们首先模拟了一组用户评论数据,涉及多个维度的内容,如产品质量、服务体验、价格评价等。评论的情感差异明显,既有对产品的赞美,也有对服务的不满。为了更好地分析这些评论,我们需要对文本进行一系列的预处理操作。在数据清洗阶段,我们利用了R语言中的`tm`包,进行常规的文本转换,包括去除标点符号、转换为小写、删除停用词等。此外,我们还使用了词干提取(stemming)技术,将词汇还原到它们的基本形式,这不仅能够减少冗余信息,还能提高后续分析的准确性。
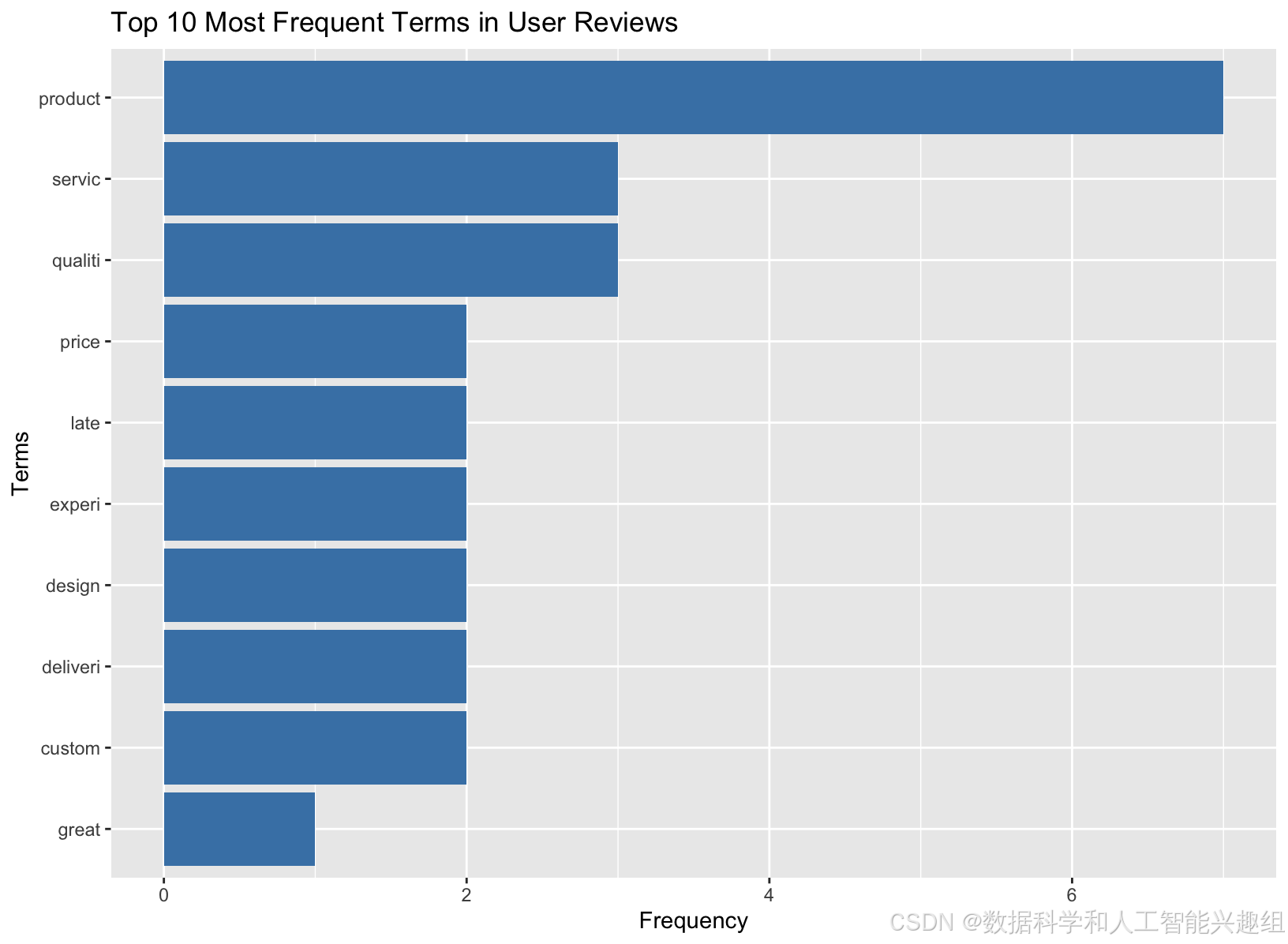
在预处理完成后,我们生成了文档-词矩阵(Document-Term Matrix, DTM),这是文本分析中的核心步骤之一。通过将评论转化为词频矩阵,我们可以量化每个词语在评论中的出现频率。这为后续的词频分析和主题建模奠定了基础。为了展示评论中的高频词,我们使用了`ggplot2`包绘制了词频图,显示了评论中最常见的词汇。我们还生成了一幅词云,直观地呈现了用户在评论中频繁提及的关键词。这些高频词不仅能反映用户关注的重点,还能为企业提供进一步优化产品和服务的参考依据。
接下来,我们引入了主题建模技术,具体使用了Latent Dirichlet Allocation(LDA)模型。通过LDA模型,我们能够从评论数据中提取出多个潜在主题。每个主题由若干高频词构成,代表了用户在讨论的不同方面。例如,一些评论集中讨论了产品质量,另一些评论则更关注价格和服务体验。通过主题建模,我们可以更好地理解用户在不同维度上的反馈,帮助企业制定更有针对性的改进措施。
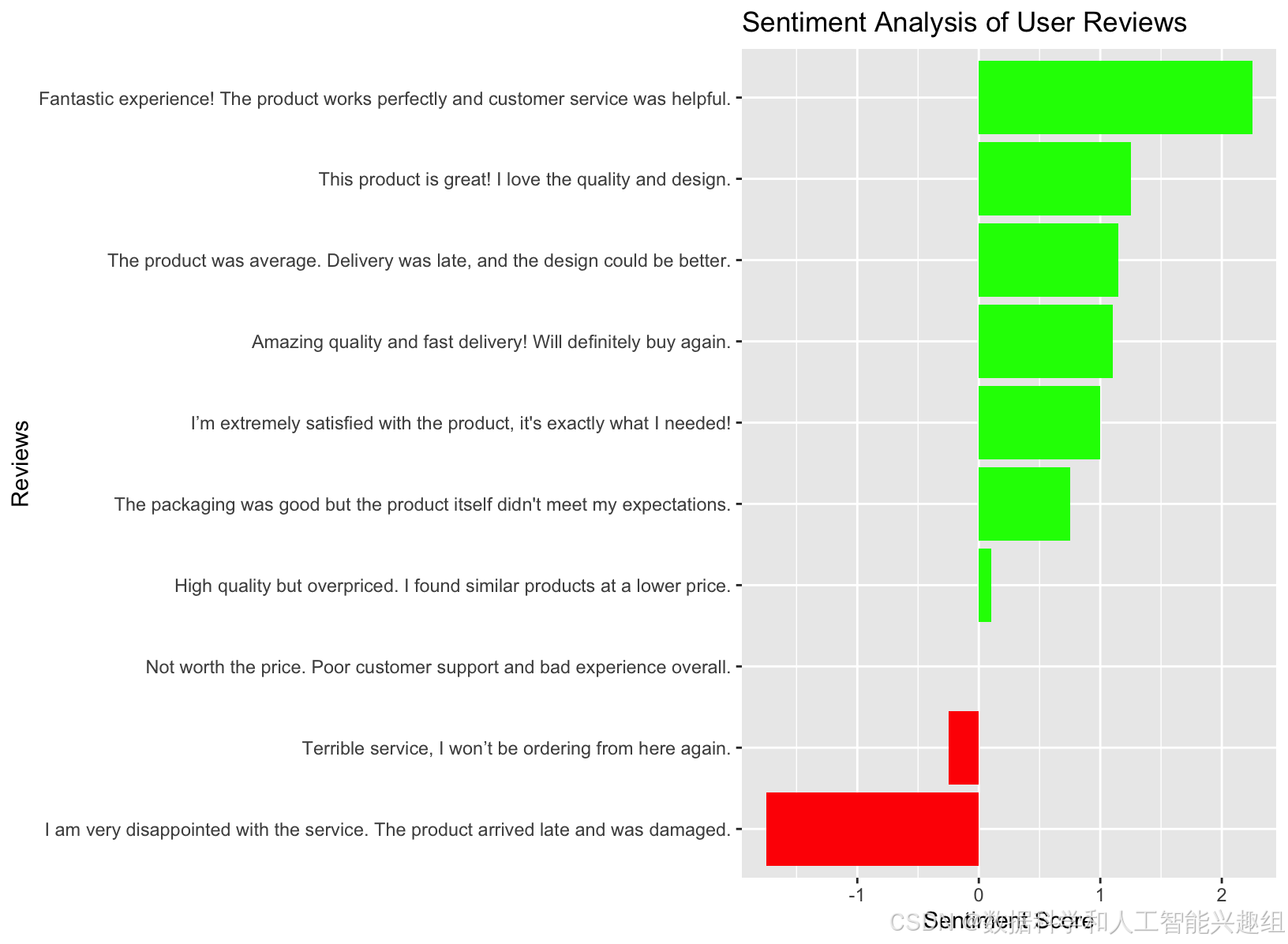
除了主题分析,情感分析也是本次评论分析的一个重点。我们使用了`syuzhet`包对每条评论进行了情感分析,该包可以检测出文本中的多种情感,如愤怒、悲伤、喜悦、信任等。情感分析不仅能区分出正面和负面的情绪,还能量化每种情感在评论中的强度。通过分析结果,我们发现用户对产品的评价情感强烈,正面评论往往伴随着高度的信任和喜悦,而负面评论则充满了失望和愤怒。为了直观展示情感强度的变化,我们还绘制了情感强度的可视化图表。通过这些图表,企业能够快速识别出情感最为强烈的评论,从而更好地理解用户的情绪动机。
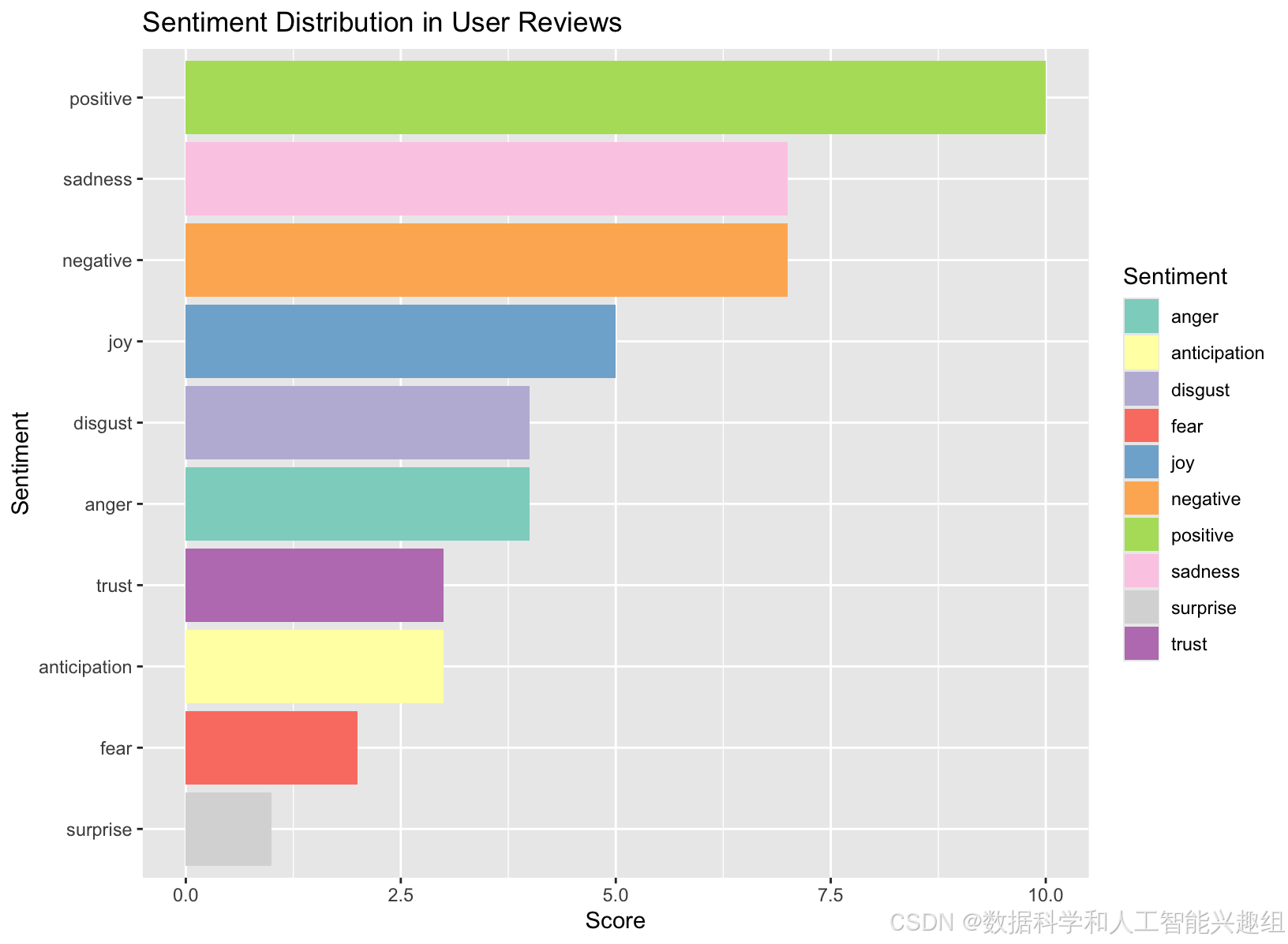
在情感分析的基础上,我们进一步深入分析了评论中的情感强度变化。通过对评论进行分词,并对每个词汇的情感进行分析,我们能够准确地捕捉到评论中情感波动的细微之处。情感强度的变化不仅揭示了用户在不同情境下的情绪反应,还能为企业提供更加精准的客户洞察。例如,通过分析用户在不同时间段的评论情感变化,企业可以调整营销策略,选择最佳的时间段进行推广。
总结而言,本篇文章通过R语言详细介绍了复杂用户评论分析的全过程。从数据预处理、词频分析、主题建模,到情感分析和可视化展示,我们全面展示了如何利用现代数据分析工具对用户评论进行深度挖掘。通过这种分析方法,企业不仅能够理解用户的情感和需求,还可以发现产品和服务中的潜在问题,从而在市场竞争中占得先机。未来,随着用户评论数据量的持续增长,这种基于数据驱动的评论分析方法将为企业的决策提供更加重要的参考价值。
# 加载所需的包
library(tm) # 文本挖掘
library(text2vec) # 文本向量化
library(syuzhet) # 情感分析
library(topicmodels) # 主题建模
library(wordcloud) # 词云
library(ggplot2) # 数据可视化
library(dplyr) # 数据操作
# 模拟更多用户评论数据
text_data <- c(
"This product is great! I love the quality and design.",
"I am very disappointed with the service. The product arrived late and was damaged.",
"Amazing quality and fast delivery! Will definitely buy again.",
"Not worth the price. Poor customer support and bad experience overall.",
"The packaging was good but the product itself didn't meet my expectations.",
"Fantastic experience! The product works perfectly and customer service was helpful.",
"The product was average. Delivery was late, and the design could be better.",
"I’m extremely satisfied with the product, it's exactly what I needed!",
"Terrible service, I won’t be ordering from here again.",
"High quality but overpriced. I found similar products at a lower price."
)
# 创建文本数据集
corpus <- Corpus(VectorSource(text_data))
# 高级文本预处理
corpus <- tm_map(corpus, content_transformer(tolower)) # 转换为小写
corpus <- tm_map(corpus, removePunctuation) # 去除标点符号
corpus <- tm_map(corpus, removeWords, stopwords("en")) # 去除停用词
corpus <- tm_map(corpus, stripWhitespace) # 去除多余空格
corpus <- tm_map(corpus, stemDocument) # 词干提取(stemming)
# 创建文档-词矩阵
dtm <- DocumentTermMatrix(corpus)
term_matrix <- as.matrix(dtm)
term_freq <- colSums(term_matrix)
# 词频排序
term_freq <- sort(term_freq, decreasing = TRUE)
# 词频图
term_freq_df <- data.frame(term = names(term_freq), freq = term_freq)
ggplot(term_freq_df[1:10,], aes(x = reorder(term, freq), y = freq)) +
geom_bar(stat = "identity", fill = "steelblue") +
coord_flip() +
labs(title = "Top 10 Most Frequent Terms in User Reviews", x = "Terms", y = "Frequency")
# 生成词云
set.seed(123)
wordcloud(words = names(term_freq), freq = term_freq, min.freq = 2, max.words = 100,
random.order = FALSE, colors = brewer.pal(8, "Dark2"))
# 主题建模(LDA)
lda_model <- LDA(dtm, k = 3, control = list(seed = 123))
lda_terms <- terms(lda_model, 5) # 提取每个主题的前5个关键词
print(lda_terms)
# 情感分析
sentiments <- get_nrc_sentiment(text_data)
print(sentiments)
# 添加情感强度
text_sentiment <- get_sentiment(text_data, method = "syuzhet")
text_sentiment_df <- data.frame(text = text_data, sentiment = text_sentiment)
# 可视化情感强度
ggplot(text_sentiment_df, aes(x = reorder(text, sentiment), y = sentiment, fill = sentiment > 0)) +
geom_bar(stat = "identity", show.legend = FALSE) +
coord_flip() +
labs(title = "Sentiment Analysis of User Reviews", x = "Reviews", y = "Sentiment Score") +
scale_fill_manual(values = c("red", "green"))
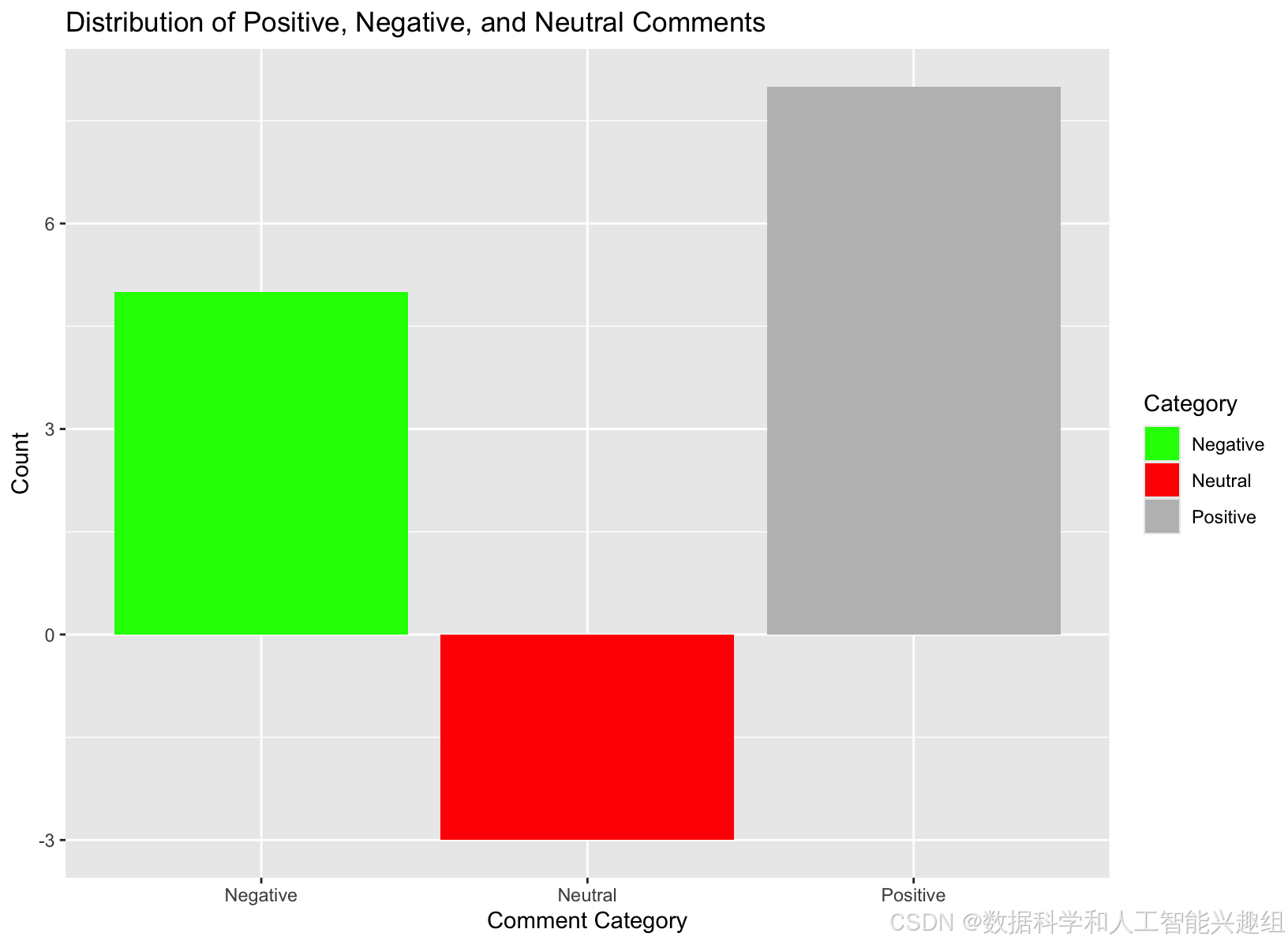
# 提取正面和负面评论的比例
positive_comments <- sum(sentiments$positive > 0)
negative_comments <- sum(sentiments$negative > 0)
neutral_comments <- length(text_data) - positive_comments - negative_comments
comment_summary <- data.frame(
Category = c("Positive", "Negative", "Neutral"),
Count = c(positive_comments, negative_comments, neutral_comments)
)
# 可视化评论分类
ggplot(comment_summary, aes(x = Category, y = Count, fill = Category)) +
geom_bar(stat = "identity") +
labs(title = "Distribution of Positive, Negative, and Neutral Comments", x = "Comment Category", y = "Count") +
scale_fill_manual(values = c("green", "red", "gray"))
# 高级情感分析:分词后情感强度计算
tokenized_reviews <- unlist(strsplit(tolower(text_data), "\\W"))
token_sentiments <- get_nrc_sentiment(tokenized_reviews)
token_sentiments_summary <- colSums(token_sentiments)
print(token_sentiments_summary)
# 可视化情感分布
sentiment_df <- data.frame(Sentiment = names(token_sentiments_summary), Score = token_sentiments_summary)
ggplot(sentiment_df, aes(x = reorder(Sentiment, Score), y = Score, fill = Sentiment)) +
geom_bar(stat = "identity") +
coord_flip() +
labs(title = "Sentiment Distribution in User Reviews", x = "Sentiment", y = "Score") +
scale_fill_brewer(palette = "Set3")
图结果如下:


~~~~~~~~~~
在这里,你学到的并非仅仅是 R 的某一个技巧,而是能够从零开始,深入且系统地学习 R 语言。此外,本专栏每周至少定期更新三篇文章,每篇文章篇幅均在 5000 字以上。而且,对于已经发表的知识点,我们也会根据新的技术或理解及时进行更新,这是纸质版图书无法做到的。为了让更多的忠实粉丝和同学们享受到实惠,本专栏采用折扣定价策略。随着章节的不断完成,折扣力度会逐渐减小。所以,现在正是订阅的最佳时机!
https://blog.csdn.net/2301_79425796/category_12729892.html?spm=1001.2014.3001.5482
第一章:认识数据科学和R
1章1节:数据科学的发展历程,何 R 备受青睐及我们专栏的独特之处(更新20240822)-CSDN博客
1章2节:关于人工智能、机器学习、统计学连和机器学习、R 与 ChatGPT 的探究 (更新20240814)-CSDN博客
1章3节:R 语言的产生与发展轨迹(更新2024/08/14)-CSDN博客
1章4节:数据可视化, R 语言的静态绘图和 Shiny 的交互可视化演示(更新20240814)-CSDN博客
第二章:R的安装和数据读取
2章1节:R和RStudio的下载和安装(Windows 和 Mac)_rst语言选择哪个镜像-CSDN博客
2章2节:RStudio 四大区应用全解,兼谈 R 的代码规范与相关文件展示_rstudio的console和terminal-CSDN博客
2章3节:RStudio的高效使用技巧,自定义RStudio环境(更新20240823)_rstudio如何使用-CSDN博客
2章4节:用RStudio做项目管理,静态图和动态图的演示,感受ggplot2的魅力-CSDN博客
2章5节:认识和安装R的扩展包,什么是模糊搜索安装,工作目录和空间的区别与设置(更新20240807 )-CSDN博客
2章6节:R的数据集读取和利用,如何高效地直接复制黏贴数据到R(更新20240807 )_r语言 复制数据集-CSDN博客
2章7节:读写RDS,CSV,TXT,Excel,SPSS、SAS、Stata、Minitab等的数据文件(更新20240807)_r语言读取rds文件-CSDN博客
2章8节:一文学会 R Markdown 的文档核心操作,切记文末有R资源的分享_r markdown文件(.rmd)-CSDN博客
2章9节:认识R与数据库连接和网络爬虫,学会在R中使用SQL语言_sql和r语言-CSDN博客
2章10节:用 R 直接下载并分析 NHANES 数据库的数据,文末示例自创便捷下载函数(更新20240807)_nhanes数据分析-CSDN博客
第三章:认识数据
3章1节:数据的基本概念以及 R 中的数据结构、向量与矩阵的创建及运算-CSDN博客
3章2节:继续讲R的数据结构,数组、数据框和列表-CSDN博客
3章3节:R的赋值操作与算术运算_r里面的赋值-CSDN博客
第四章:数据的预处理
4章1节:全面了解 R 中的数据预处理,通过 R 基本函数实施数据查阅_r数据预处理-CSDN博客
4章2节:从排序到分组和筛选,通过 R 的 dplyr 扩展包来操作-CSDN博客
4章3节:处理医学类原始数据的重要技巧,R语言中的宽长数据转换,tidyr包的使用指南-CSDN博客
4章4节:临床数据科学中如何用R来进行缺失值的处理_临床生存分析缺失值r语言-CSDN博客
4章5节:数据科学中的缺失值的处理,删除和填补的选择,K最近邻填补法-CSDN博客
4章6节:R的多重填补法中随机回归填补法的应用,MICE包的实际应用和统计与可视化评估-CSDN博客
4章7节:用R做数据重塑,数据去重和数据的匹配-CSDN博客
4章8节:用R做数据重塑,行列命名和数据类型转换-CSDN博客
4章9节:用R做数据重塑,增加变量和赋值修改,和mutate()函数的复杂用法_r语言如何在数据集中添加变量-CSDN博客
4章10节:用R做数据重塑,变体函数应用详解和可视化的数据预处理介绍-CSDN博客
4章11节:用R做数据重塑,数据的特征缩放和特征可视化-CSDN博客
4章12节:R语言中字符串的处理,正则表达式的基础要点和特殊字符-CSDN博客
4章13节:R语言中Stringr扩展包进行字符串的查阅、大小转换和排序-CSDN博客
4章14节:R语言中字符串的处理,提取替换,分割连接和填充插值_r语言替换字符串-CSDN博客
4章15节:字符串处理,提取匹配的相关操作扩展,和Stringr包不同函数的重点介绍和举例-CSDN博客
4章16节:R 语言中日期时间数据的关键处理要点_r语言 时刻数据-CSDN博客
第五章:定量数据的统计描述
5章1节:用R语言进行定量数据的统计描述,文末有众数的自定义函数-CSDN博客
5章2节:离散趋势的描述,文末1个简单函数同时搞定20个结果-CSDN博客
5章3节:在R语言中,从实际应用的角度认识假设检验-CSDN博客
5章4节:从R语言的角度认识正态分布与正态性检验-CSDN博客
5章5节:认识方差和方差齐性检验(三种方法全覆盖)-CSDN博客
5章9节:组间差异的非参数检验,Wilcoxon秩和检验和Kruskal-Wallis检验-CSDN博客
第六章:定性数据的统计描述
6章1节:定性数据的统计描述之列联表,文末有优势比计算介绍-CSDN博客
6章2节:认识birthwt数据集,EpiDisplay和Gmodels扩展包的应用-CSDN博客
6章3节:独立性检验,卡方检验,费希尔精确概率检验和Cochran-Mantel-Haenszel检验-CSDN博客
6章4节:相关关系和连续型变量的Pearson相关分析-CSDN博客
6章5节:分类型变量的Spearman相关分析,偏相关分析和相关图分析-CSDN博客
6章6节:相关图的GGally扩展包,和制表的Tableone扩展包-CSDN博客
第七章:R的传统绘图
7章1节:认识R的传统绘图系统,深度解析plot()函数和par()函数的使用-CSDN博客
7章2节:R基础绘图之散点图、直方图和概率密度图-CSDN博客
7章5节:散点矩阵图,与小提琴图、Cleveland 点图、马赛克图和等高图-CSDN博客
7章6节:用R进行图形的保存与导出,详细的高级图形输出,一文囊括大多数保存的各种问题,和如何批量保存不同情况的图形-CSDN博客
第八章:R的进阶绘图
8章1节:认识 ggplot2 扩展包,深度解析 qplot() 函数的使用-CSDN博客
8章2节:深度讲解 ggplot2 的绘图步骤,理解其核心逻辑, 和 ggplot()函数-CSDN博客
8章3节:用R来绘制医学地理图,文末有具体完整代码-CSDN博客
8章4节:维恩图的认识与应用,和使用UpSet图-CSDN博客
8章5节:用R绘制平行坐标图-CSDN博客
8章8节:绘制自定义的高质量动态图和交互式动态图-CSDN博客
第九章:临床试验的统计
9章4节:两组例数相同的均数比较的样本量估计和绘制功效曲线-CSDN博客
9章5节:两组的例数不等的均数比较的样本量估计和可视化-CSDN博客



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











