







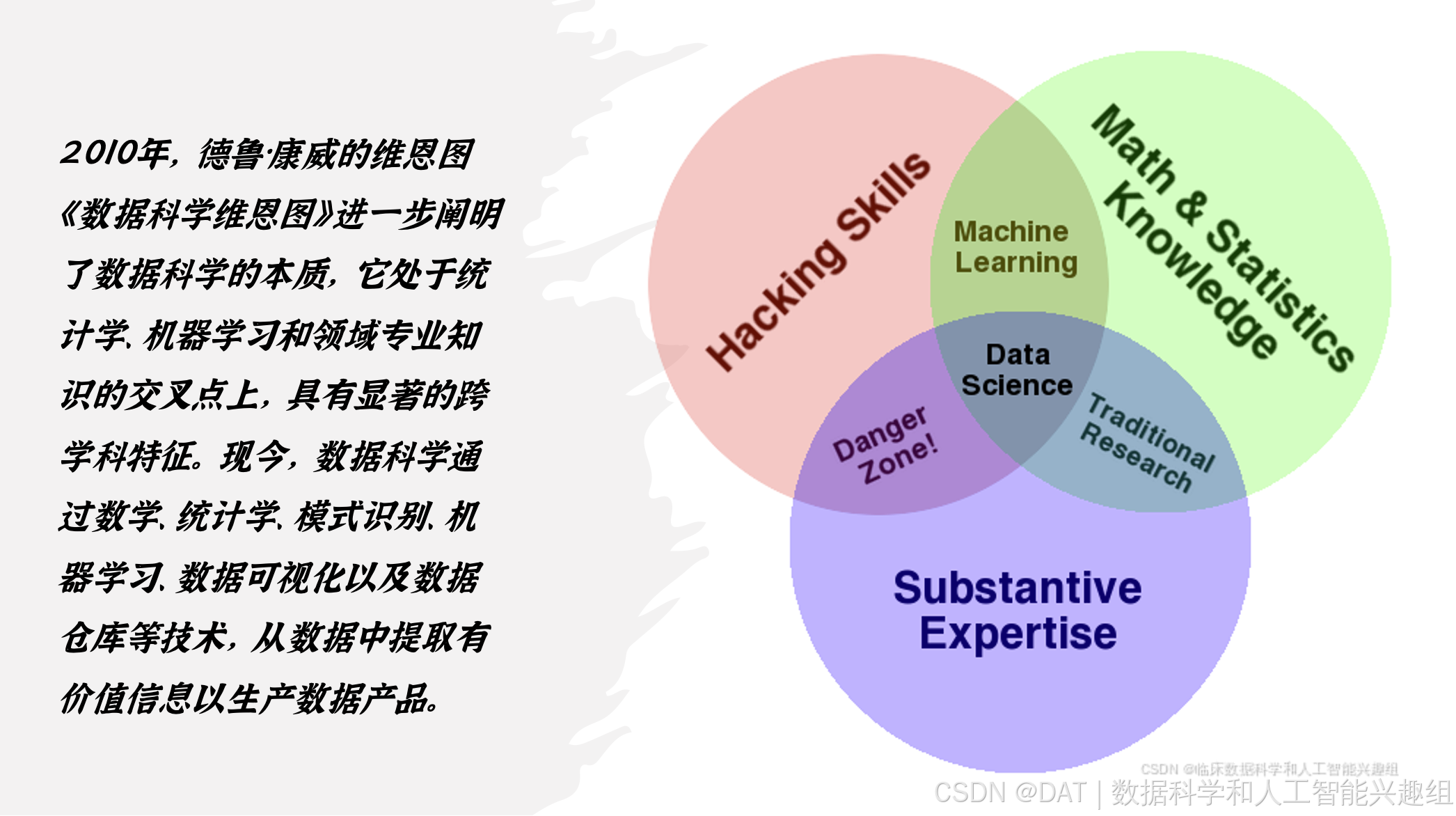
数据科学作为一门跨学科的领域,融合了统计学、计算机科学和领域知识,致力于从数据中提取有价值的信息。数据科学的发展可以追溯到20世纪中期,当时计算机科学和统计学逐渐兴起,为数据分析提供了技术基础。同时,随着数据科学在临床数据分析和挖掘中的应用增多,医药数据科学成为一门跨学科的学科,结合临床医学、统计学和计算机技术。

一、数据科学和临床数据科学的发展
1、认识数据科学
数据科学(Data Science)是一门跨学科的学术领域,利用统计学、科学计算、科学方法、数据处理、科学可视化、算法和系统,从可能存在噪声的结构化或非结构化数据中提取或推断知识和见解。同时,数据科学也整合了来自应用领域的领域知识(如自然科学、信息技术和医学等),使其更具多样性。
许多统计学家(如Nate Silver)认为数据科学不是一个新的领域,而是统计学的另一个名称。另一方面,一些人认为数据科学不同于统计学,因为它专注于数字数据独有的问题和技术。Vasant Dhar指出,统计学强调定量数据和描述性分析,而数据科学处理定量和定性数据(例如来自图像、文本、传感器、交易、客户信息等),更注重预测和行动。哥伦比亚大学的Andrew Gelman则认为统计学在数据科学中并非必要的组成部分。斯坦福教授David Donoho指出,数据科学并非因数据集的大小或计算的使用而与统计学区分开来,且许多研究生项目将他们的分析和统计训练误导性地宣传为数据科学课程的核心内容。他认为,数据科学是一门从传统统计学发展而来的应用领域。
数据科学的起源可以追溯到1962年,当时统计学家John W. Tukey在他的文章《数据分析的未来》中首次提出了数据分析作为一门独立的科学方法。1974年,计算机学家Peter Naur在《计算机方法的简明调研》中明确定义了数据科学,将其描述为一门基于数据处理的科学,旨在发现数据与事物之间的关系,为其他领域的研究提供支持和启示。

约翰·W·图基(John Wilder Tukey,1915年6月16日 - 2000年7月26日)出生于美国马萨诸塞州新贝德福德,后于普林斯顿大学获得数学博士学位。二战期间,他曾在火控研究所工作,战后重返普林斯顿大学,并在AT&T贝尔实验室担任重要职务。
在20世纪60年代,图基挑战了传统的验证性数据分析方法,主张灵活分析数据、重视数据的探索性。他将这种方法称为“探索性数据分析 (Exploratory Data Analysis,EDA)”,提倡通过数据的探索和观察发现潜在的信息与模式。EDA不仅改变了数据分析的方式,还影响了后来数据科学的发展。图基意识到计算机科学在EDA中的重要性,主张用计算机图形来研究多变量数据。他在70年代早期构想并开发了PRIM-9程序,这是首个用于多维数据可视化的软件,推动了EDA的应用。尽管数据科学这一术语在20世纪末才广泛应用,但图基的工作为数据科学奠定了坚实的基础。他认为数据分析不仅是从数据中推导结论,还应包括数据探索和发现。通过整合计算机科学和数据分析,图基的研究为现代数据科学的形成提供了重要的理论基础,因此他也被誉为“数据科学之父”。
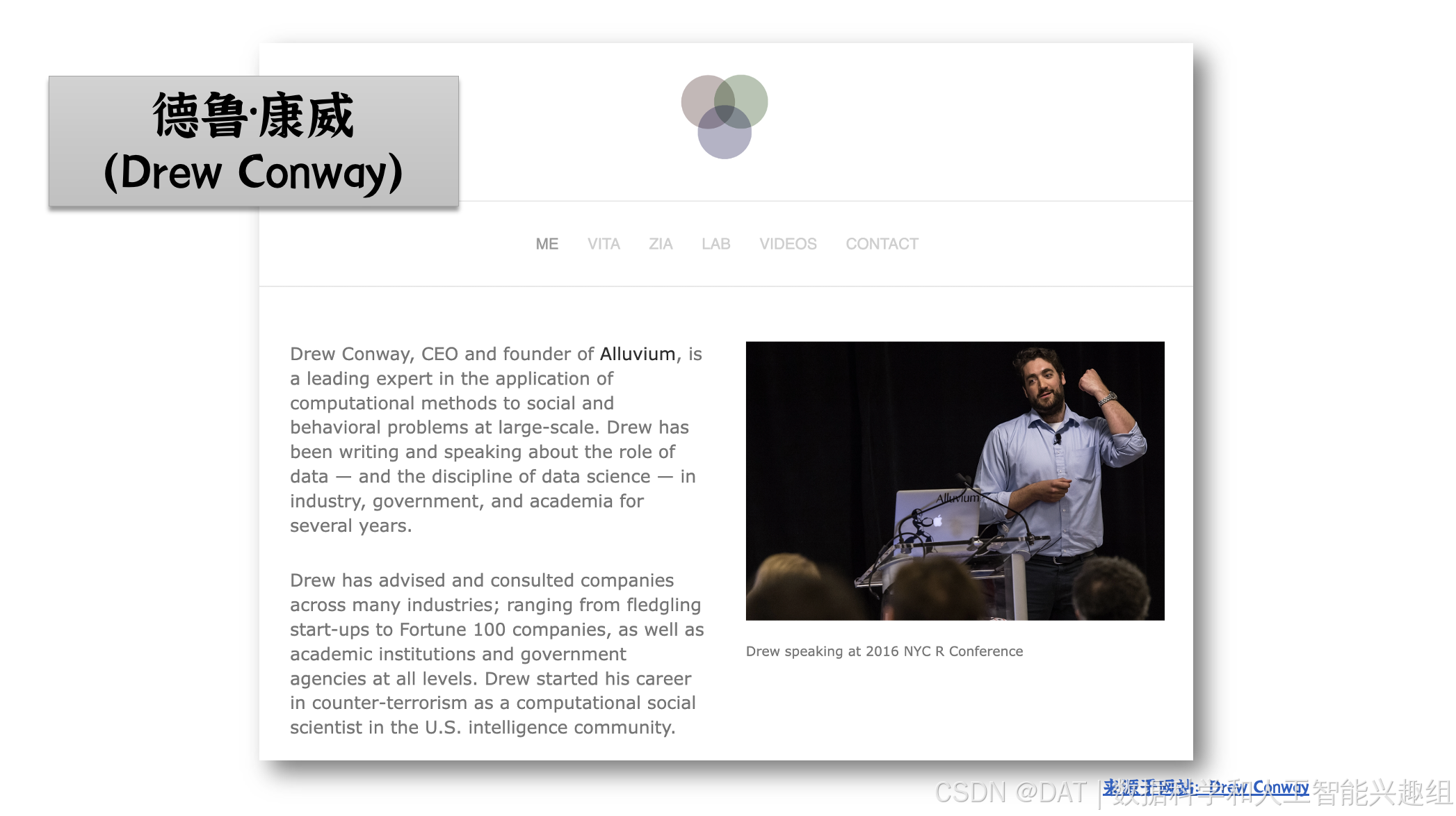
德鲁·康威(Drew Conway),Alluvium的首席执行官兼创始人,是在大规模社会和行为问题上应用计算方法的领先专家。他创建了数据科学维恩图,定义了该领域的核心概念。作为《Machine Learning for Hackers》的作者,他推广了机器学习技术的普及。作为Alluvium公司的创始人兼首席执行官,他领导了一家专注于企业人工智能的企业。他还是DataGotham的联合创始人,支持纽约市的数据社区发展。同时,Drew Conway在Two Sigma Private Investments领导数据科学团队,推动私募股权、风险投资、房地产和ESG投资的创新决策,并在美国情报界担任计算社会科学家。
据报告,健康相关数据约占全球数据总量的30%。医疗保健领域产生的大量数据推动了健康数据市场的发展,这些数据通过连接所有者并货币化,支持科学发现。临床数据广义上指与健康相关的信息,包括从常规护理到临床试验计划的各种数据,主要来源于医疗机构,涵盖人口统计学信息、筛查、诊断、治疗、预后、生存率及死亡率等,是医学大数据的关键组成部分。
2、医学/临床数据科学
随着数据科学在临床数据分析和挖掘中的应用增多,医学/临床数据科学成为一门跨学科的学科,结合临床医学、统计学和计算机技术,探索不同类型、状态和属性的临床数据,揭示其中潜在的临床规律。医学/临床数据科学家或者行业专业人士利用每天在医疗系统内产生的庞大数据量来解决与健康相关的挑战。
生物医学数据科学(Biomedical Data Science):更强调对生物数据(如基因组学、蛋白质组学和代谢组学)以及临床数据的分析。
医学/临床数据科学(Medical Data Science/ Clinical Data Science):更强调专注于数据科学的医学/药学/临床方面的数据科学应用。
健康数据科学(HealthData Science):更强调涵盖各种健康相关数据,包括社会健康决定因素、公共卫生数据和医疗利用情况。
医学/临床数据科学与生物医学数据科学、医疗保健分析和生物医学信息学密切相关,尽管它们之间存在一些区别。生物医学数据科学侧重于对大规模生物数据集进行分析,以理解和解决健康问题。医疗保健分析则是基于来自医疗核心领域的数据进行的分析活动,包括索赔和成本数据、药品和研发数据、临床数据、患者行为和情感数据等。
| 特征/领域 | 医学/临床数据科学 | 生物医学数据科学(生物信息学) |
|---|---|---|
| 关注点 | 更强调应用数据科学于改善医疗系统和患者健康,提高医疗服务效率和质量 | 更强调分析大规模生物数据集或者生物数据和临床数据的整合分析 |
| 数据来源 | 电子健康记录(EHR)、临床实验室数据、索赔和成本数据等 | 基因组学数据、蛋白质组学数据等 |
| 处理方法 | 更强调数据挖掘、统计分析、预测建模等在医学和药学的应用 | 更强调生物信息学方法和工具的应用 |
| 任务目标 | 更强调改善患者的整体健康和医疗系统效率,提高患者护理质量 | 更强调理解疾病机制、发展个性化基因治疗策略 |
虽然医药数据科学的应用尚处于起步阶段,人们对其认识也不尽相同,但这一领域已经衍生出许多相关概念,如数据驱动的临床研究、临床二次数据挖掘、医学机器学习和现代医学统计学等。这些概念各有侧重,但它们共同围绕一个核心主题:如何从实际的临床工作中提取数据,并通过计算机算法从中挖掘出科研线索或新的研究结论,为医学临床和科研提供支持。
所以,无论是医学研究生还是专业研究人员,掌握一种强大的数据分析工具都是必须的。
二、建议选择R语言的5点理由
为了掌握好数据科学的数据分析技术,掌握一门强大的计算机语言工具至关重要。这些工具不仅能够帮助我们处理海量的数据,还能提供丰富的分析和可视化手段,使得我们可以从数据中提取有价值的洞见。SAS、R、Python、JAVA等都是广受欢迎的数据科学工具,每种语言都有其独特的优势和应用场景。然而,对于初学者和专业数据科学家来说,R语言可能是最佳的选择。
R语言是一门开源的统计编程语言,以其强大的数据分析和可视化功能而著称。自1993年首次发布以来,R语言已经发展成为数据科学家、统计学家的主要工具之一。R语言不仅支持各种统计分析方法,还提供了丰富的扩展包,使其在临床数据科学和金融数据科学领域具有广泛的应用前景。
第1点理由,免费且开放的语言
首先,R语言的一个显著优势是它的免费和开源性。与SPSS、SAS,甚至Excel等商业软件相比,R完全免费。SPSS和SAS这些统计软件虽然功能强大,但通常价格昂贵,对于学生和学者来说,获取和使用这些软件的成本可能非常高。此外,我们常用的OFFICE软件的EXCEL也能进行数据分析,但是定期支付许可费用才能继续使用。

不仅如此,R语言拥有一个庞大而活跃的开源社区,全球的开发者和用户不断贡献代码和扩展包,形成了丰富的资源库。用户可以方便地找到所需的工具和文档,从简单的数据处理到复杂的统计分析,R语言几乎涵盖了所有可能的需求。而且,由于R是开源的,这些资源通常也是免费的,这进一步减轻了用户的负担。同时,这意味着用户可以免费使用并分发代码,而不用担心版权问题。
第2点理由,简单易学的R语言
R语言的语法设计相对简洁,特别适合那些没有编程背景的用户。与其他编程语言(如Python或Java)相比,R语言的语法更直观,特别是在处理统计分析时。例如,R的函数命名通常直接反映其功能,如mean()计算均值,sum()计算总和,plot()生成图表等,这使得初学者能够快速理解和应用。
此外,R语言的交互式环境使得用户可以立即查看代码的运行结果,这对新手来说非常有帮助。通过R的命令行接口,用户可以一步一步地执行代码,逐步理解每个步骤的作用。对于非计算机专业的用户,这种学习方式降低了学习曲线,使他们能够更快地掌握数据分析的基本技能。
随着人工智能技术的飞速发展,学R语言变得更加轻松易行。AI的加持不仅提升了R语言的易学性,也进一步降低了入门的门槛。智能化的编程助手、自动化的代码建议以及即时的错误修正功能,极大地简化了学习过程。现如今,许多AI驱动的工具能够实时提供代码示例、优化建议,甚至帮助初学者理解复杂的统计概念。借助这些智能化工具,R语言学习者能够迅速掌握代码编写技巧,并通过即时反馈来不断优化自己的编程能力。在这样的智能环境中,R语言不仅保持其语法简洁直观的优点,更通过AI技术让用户能够在更短的时间内完成更复杂的任务。
第3点理由,超强大的统计分析
R语言诞生于统计学界,自然拥有强大的统计分析能力。R的核心功能包括各种统计模型、数据处理、可视化工具等,几乎涵盖了所有常见的数据分析需求。对于那些需要进行本科或研究生论文的学生,R语言提供了丰富的统计函数和方法,可以轻松实现从数据清洗到高级统计建模的一整套流程。
R还拥有广泛的社区支持,大量的开源扩展包(如ggplot2、dplyr、caret等)可以进一步扩展其功能。这些扩展包使得R可以非常简单地处理从基本统计分析到复杂的机器学习任务的各类工作。对于学术研究,R的统计能力不仅能帮助用户进行数据分析,还可以通过可视化工具生成高质量的图表,使得研究成果的展示更加直观。
R语言最初是为统计分析而设计的,至今仍然在这方面保持领先地位。无论是基础统计、回归分析、时间序列分析还是高级统计建模,R都能提供丰富的函数和包,帮助我们轻松实现各种统计分析,很简单的代码就能完成任务。

强大的数据可视化能力: R语言拥有ggplot2等强大的可视化包,可以生成高质量的图表和图形,使得数据可视化变得简单而直观。通过R,我们可以创建各种图表,如散点图、线形图、柱状图、热图等,帮助我们更好地理解和展示数据。如下面的图,我们都可以很简单地画出来。另外,我们还可以绘制动态的图形。
第4点理由,无缝对接学术需求
对于需要撰写本科生论文、研究生论文、或者发表学术成果的用户来说,R的优势在于它与学术写作的无缝衔接。例如,R Markdown是一个非常实用的工具,它允许用户在同一文件中撰写文字和代码,并直接生成报告或论文。通过R Markdown,用户可以将数据分析、统计结果、图表和文字内容集成在一起,形成一个完整的学术文档。同时,R Markdown支持直接导出PDF、Word、HTML等多种格式,满足不同出版和提交需求。
Zotero是一款广泛使用的参考文献管理工具,能够帮助用户轻松地收集、组织和引用文献。对于学生和学者来说,使用Zotero可以大大简化文献管理的过程,而R语言与Zotero的集成更是如虎添翼。
第5点理由,广泛的行业支持和兼容性
虽然R语言的设计初衷是用于统计分析,但它在多个行业中得到了广泛应用,包括金融、医学、社会科学、市场研究等。对于非计算机专业的用户,R不仅能够满足他们在学术研究中的需求,还能在未来的职业发展中提供重要的技能支持。
R语言的开放性和跨平台兼容性也是其受欢迎的原因之一。RStudio作为R语言的主要集成开发环境,提供了跨平台的支持,可以在Windows、macOS和Linux等操作系统上运行。这种跨平台兼容性使得无论用户使用何种操作系统,都可以轻松地安装和运行RStudio,体验一致的开发环境。同时,通过不同的扩展包,R与其他编程语言(如Python、SQL、Java等)同时使用,进一步增强其功能。
数据科学作为一门融合统计学、计算机科学与领域知识的跨学科领域,自 20 世纪 60 年代起源以来,已发展成为从结构化或非结构化数据中挖掘知识的核心工具。随着健康数据占全球数据总量的 30%,临床数据作为医学大数据的核心,推动了医学 / 临床数据科学的兴起。这一领域聚焦于通过临床医学、统计学与计算机技术的交叉应用,解析电子健康记录、临床试验数据等多维度临床信息,揭示潜在的临床规律,旨在提升医疗效率、优化患者健康。与生物医学数据科学(侧重生物组学数据)和健康数据科学(涵盖社会健康因素)不同,医学 / 临床数据科学更强调数据科学在医疗系统与患者护理中的实际应用,通过数据挖掘、预测建模等技术,衍生出数据驱动的临床研究、医学机器学习等方向,为医学科研与临床实践提供了创新的方法论支持。


















 3029
3029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











