







 本文介绍了一种基于深度学习的道路裂缝识别算法系统,利用卷积神经网络和注意力机制,如YOLOv5和坐标注意力模块,以提高裂缝检测的精度。文章详细描述了课题背景、算法理论、数据集收集、实验环境设置以及模型训练过程。
本文介绍了一种基于深度学习的道路裂缝识别算法系统,利用卷积神经网络和注意力机制,如YOLOv5和坐标注意力模块,以提高裂缝检测的精度。文章详细描述了课题背景、算法理论、数据集收集、实验环境设置以及模型训练过程。
目录
3.2 模型训练
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的道路裂缝识别算法系统
设计思路
一、课题背景与意义
随着我国高速公路和城市道路的日益增多,道路裂缝的检测和修复成为了一个重要的课题。传统的道路裂缝检测方法费时费力,且精度不高。因此,基于深度学习的道路裂缝识别算法系统应运而生。该系统利用计算机视觉技术和深度学习算法,可以快速、准确地识别道路裂缝,对于提高道路维护效率和保障道路安全具有重要意义。
二、算法理论原理
2.1 卷积神经网络
卷积神经网络(CNN)是一种深度学习模型,广泛应用于计算机视觉任务中,如图像分类、目标检测和图像生成等领域。它是受到生物视觉系统启发而设计的,通过模拟人类视觉皮层的结构和功能来提取图像中的特征。卷积神经网络的核心是卷积层,通过对输入数据进行卷积操作,提取出输入数据的特征。卷积操作使用卷积核(或滤波器)对输入数据进行滑动窗口运算,并通过逐元素相乘、求和等操作来计算输出特征图。卷积层的参数包括卷积核的大小、步幅、填充等,可以通过调整这些参数来控制输出特征图的尺寸和特征提取的方式。在卷积神经网络中,通常会交替使用卷积层和池化层。池化层用于减小特征图的尺寸,降低模型复杂度,并且具有一定的平移不变性。常见的池化操作包括最大池化和平均池化。

除了卷积层和池化层,卷积神经网络还包括全连接层和激活函数。全连接层用于将卷积层的输出特征进行扁平化,并与输出层连接,进行最终的分类或回归预测。激活函数则引入非线性性质,使网络能够学习非线性关系。在训练卷积神经网络时,通常使用反向传播算法和梯度下降优化算法来更新网络参数,使得网络能够逐渐优化并减小损失函数的值。此外,为了防止过拟合问题,还可以采用一些正则化技术,如dropout和权重衰减等。
卷积神经网络通过多层卷积和池化操作,以及全连接层和激活函数的组合,能够自动从图像中学习到更高级别的特征表示,从而实现对图像进行分类、检测和生成等任务。它在计算机视觉领域取得了很多重要的突破,并成为深度学习中最常用的模型之一。
2.1 YOLOv5算法
在路面裂缝图像中,裂缝占比较小且背景通常较为复杂,会带有光影斑驳、车道线、水迹、生活杂物等噪声。这些因素都会对裂缝的识别和检测带来挑战。为了解决这一问题,我们引入了注意力模块。注意力模块是一种能够使神经网络在进行特征提取时更加关注与病害相关的特定语义信息的技术。通过注意力模块,神经网络能够更加集中地学习和提取与裂缝相关的特征,从而提升检测的精度。
为了保证模型的轻量化,我们引入了Ghost模块。Ghost模块是一种能够减少模型参数量的技术。传统的卷积神经网络模型通常具有大量的参数,这会导致模型的计算复杂度和内存占用较大。而Ghost模块通过特殊的结构设计,能够在保证模型性能的同时,大幅减少模型的参数量。这样,不仅能够提高模型的计算效率,还能降低模型的硬件要求,使得模型更加适合在移动设备或嵌入式设备上部署和运行。

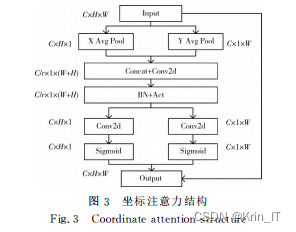
为了进一步提高路面裂缝检测模型的性能,我们引入了坐标注意力(Coordinate Attention,CA)模块。这种模块的独特之处在于它能够将图像的位置信息嵌入到通道注意力中,从而使神经网络在提取目标跨通道特征的同时,还能够提取出目标的方向特征和位置特征。这种方法能够有效地增强模型对裂缝检测的能力,因为它不仅关注裂缝的纹理信息,还关注裂缝在图像中的具体位置和方向。
在实际应用中,我们将CA模块放置在骨干网络的SPPF层之后。SPPF层是一种能够融合多尺度特征的层,它可以帮助模型更好地理解图像中的全局和局部信息。通过将CA模块与SPPF层结合使用,模型能够更加精确地识别和定位路面裂缝。
CA模块的结构包括两部分:坐标信息嵌入和坐标注意力生成。在坐标信息嵌入部分,模型会将图像中每个像素的坐标信息编码为一种特殊的嵌入向量,并将其与原始的图像特征通道相加,从而使网络能够利用这些位置信息。在坐标注意力生成部分,模型会根据这些嵌入向量计算出一个注意力权重,这个权重反映了每个位置对于裂缝检测的重要性。通过这种方式,模型能够更加专注于图像中与裂缝相关的区域,从而提高裂缝检测的准确性和效率。
三、裂缝检测
3.1 数据集
由于网络上现有的道路裂缝数据集有限,本研究决定通过网络爬取的方式,收集了大量道路裂缝的图片,并制作了一个全新的数据集。这个数据集包含了各种道路裂缝的图片,通过现场拍摄和网络爬取,我能够捕捉到真实的路面情况和多样的工作环境,这将为我的研究提供更准确、可靠的数据。

3.2 实验环境
本实验采用的操作系统为Ubuntu 18.04,显卡为NVIDIA GeForce RTX 3090,处理器为Intel Xeon E5-2678v3,实验环境为Python 3.8,在PyTorch 1.7.1深度学习框架下搭建模型,并使用YOLOv5s在ImageNet数据集下的预训练权重进行网络参数初始化。实验参数配置见下表。

3.2 模型训练
道路裂缝识别算法系统的设计思路如下:
- 数据收集和预处理:首先,需要收集大量的道路图像数据,包括正常道路和带有裂缝的道路。这些图像应该具有不同的光照条件、角度和道路类型,以提高算法的鲁棒性。然后,对收集到的图像进行预处理,如调整大小、灰度化和归一化,以便输入到深度学习模型中。
- 构建卷积神经网络模型:基于深度学习的道路裂缝识别算法系统通常使用卷积神经网络(CNN)作为模型的基础。模型的设计可以包括多个卷积层、池化层和全连接层,以及适当的激活函数。卷积层用于提取图像中的特征,池化层用于降低特征图的维度,全连接层用于最终的分类决策。
- 数据划分和模型训练:将收集到的图像数据划分为训练集和测试集。训练集用于模型的参数学习,测试集用于评估模型的性能。然后,使用训练集对深度学习模型进行训练,通过反向传播算法和梯度下降优化算法来更新网络参数,使得模型能够逐渐优化并减小损失函数的值。
- 模型评估和调优:使用测试集对训练好的模型进行评估,计算识别准确率、召回率等性能指标。根据评估结果,可以进行模型的调优,如调整模型的超参数、增加训练数据量、应用正则化技术等,以提高模型的性能和泛化能力。
- 实时道路裂缝识别系统:在完成模型训练和调优后,将该模型部署在实时道路裂缝识别系统中。该系统可以接收实时采集的道路图像,并通过深度学习模型进行道路裂缝的识别。识别结果可以通过可视化展示、报警或记录等方式进行处理和应用。
部分代码如下:
class Backbone(nn.Module):
def __init__(self):
super(Backbone, self).__init__()
# Define your backbone network layers here
def forward(self, x):
# Implement the forward pass of your backbone network here
return x
class SPPF(nn.Module):
def __init__(self, levels):
super(SPPF, self).__init__()
self.levels = levels
def forward(self, x):
pyramid_features = []
for level in self.levels:
level_pool = F.adaptive_max_pool2d(x, level)
pyramid_features.append(level_pool.view(x.size(0), -1))
sppf_output = torch.cat(pyramid_features, dim=1)
return sppf_output
class CAModule(nn.Module):
def __init__(self, in_channels, reduction_ratio):
super(CAModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Linear(in_channels, in_channels // reduction_ratio)
self.fc2 = nn.Linear(in_channels // reduction_ratio, in_channels)
def forward(self, x):
b, c, _, _ = x.size()
attention = self.avg_pool(x).view(b, c)
attention = F.relu(self.fc1(attention))
attention = torch.sigmoid(self.fc2(attention)).view(b, c, 1, 1)
out = x * attention.expand_as(x)创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!















 2218
2218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









