










目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路(见文末!)。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于深度学习的无人机实时密集小目标检测系统
设计思路
一、课题背景与意义
由于无人机飞行高度高,航拍图像中存在大量小目标,其可提取特征少,且由于无人机飞行高度变化大,物体比例变化剧烈,导致检测精度低;在实际飞行拍摄中存在复杂场景,密集小目标之间会存在大量遮挡,且易被其他目标或背景遮挡。因此需要设计一种适用于密集小目标场景下的无人机航拍实时目标检测模型,以满足实际应用场景需求。
二、算法理论原理
2.1 空间-通道注意力模块
将更多有效权重分配给浅层高分辨率特征图X,可以融合更多小目标特征。同时,将高权重分配给具有更多深层高语义信息的特征图Y能减少浅层特征图中语言歧义的问题,提高模型的泛化能力。为了更加合理地分配权重,文通过一种基于注意力机制的动态权重分配方法来分配2种尺度下的特征图权重。SCAFF能利用更加灵活和准确的动态注意力权重来融合更多小目标特征,提高了最终的检测精度。
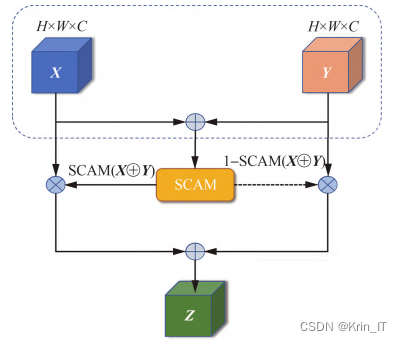
采用SC-AFF模块替换YOLOv5特征金字塔网络中的Concat模块,修改后的特征融合网络与原本直接由Concat操作进行特征融合不同,SC-AFF利用SCAM模块计算得到对应特征图的注意力权重,动态分配权重到不同尺度特征图,更好地融合上、下采样后特征图中的小目标特征,缓解特征融合过程中小目标特征丢失的问题。Self-Attention机制属于注意力机制的一种,减少了对外部信息的依赖,更擅长捕捉特征图内部的相关性,解决像素间的长距离依赖问题21。因此在Self-Attention网络结构中加入传统的注意力。
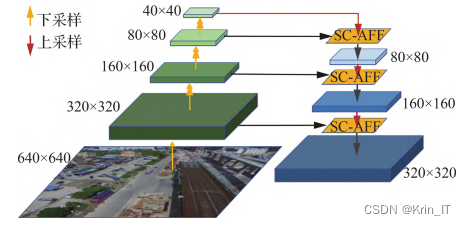
2.2 自注意力主干网络
在无人机小目标检测中,复杂背景更容易遮挡小目标,不利于小目标的特征提取。在主干网络中,提取特征图中的上下文信息,可以加强模型对有效目标与背景噪声的理解。但对复杂背景下的小目标来说,提取到的上下文信息会存在大量无效信息,因此需要过滤掉这些噪声,将更多注意力放到有效目标上。Multi-Head Attention Module可以理解为多个带有Self-Attention机制的模块组成的Multi-Head Attention。将输入序列X分为多个子空间进行多组Self-Attention处理,将每一子空间得到的结果拼接起来进行一次线性变换得到最终的输出,这使得模型能够综合利用各子空间中的特征信息,缓解过度集中自身位置信息的问题,有助于模型捕捉更丰富的特征信息。
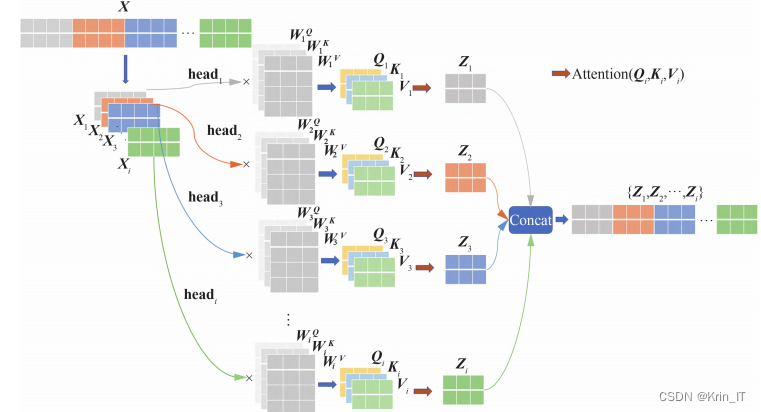
多头注意力模块中的Self-Attention机制作为SC-Transformer中的核心模块,使得当前特征图中每个像素更关注其他像素特征,建立各个像素间的相关性权重,根据权重大小分析出不同目标之间存在的某种联系,从全局提取出更多的有效特征,获得更丰富的上下文信息。另外,用SC-AFF模块替换残差连接处的特征融合模块,引入动态注意力权重,从通道和空间维度进一步提高特征融合能力。因此,在主干网络中添加SC-Transformer模块,可以增强主干网络在复杂背景下对小目标的特征提取能力。
相关代码:
class FeatureFusionModule(nn.Module):
def __init__(self, in_channels, out_channels):
super(FeatureFusionModule, self).__init__()
# 定义注意力机制
self.attention = nn.Sequential(
nn.Conv2d(in_channels, 1, kernel_size=1), # 用于生成注意力权重的卷积层
nn.Sigmoid() # 用于将注意力权重限制在0到1之间
)
# 定义特征融合
self.fusion = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
attention_weights = self.attention(x) # 生成注意力权重
fused_features = self.fusion(x) # 特征融合
weighted_features = attention_weights * fused_features # 使用注意力权重对特征进行加权
output = x + weighted_features # 将加权特征与原始特征进行相加
return output
三、检测的实现
3.1 数据集
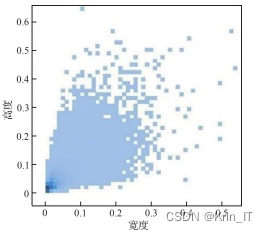
由于网络上没有现有的合适的数据集,我决定自己使用无人机进行空中拍摄,收集图片并制作一个全新的数据集。这个数据集包含了各种场景中的密集小目标,例如城市街道、人群聚集地等。通过无人机拍摄,我能够捕捉到真实的场景和多样的环境,这将为我的研究提供更准确、可靠的数据。

在面对有限的数据集时,为了增加数据的数量和多样性,采用了数据扩充和数据增强的方法。数据扩充通过对原始图像进行变换和操作,生成新的样本,如平移、旋转、缩放和翻转等操作。数据增强则通过对图像进行滤波、添加噪声、模拟不同光照和天气条件等处理,生成具有不同特征和属性的新样本。这些技术能够有效地提升无人机实时密集小目标检测算法的性能和可靠性,充分利用有限的原始数据,提供更多样化、更丰富的训练样本。
3.2 实验环境搭建
具体设置如下:
- 训练epochs设置为300次
- warmup epochs设置为3次
- 初始学习率为0.01
3.3 实验及结果分析
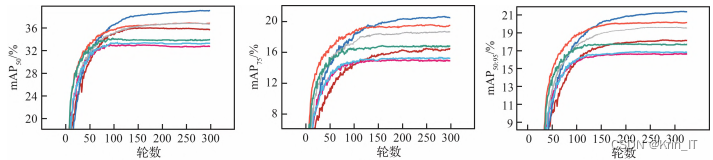
采用消融实验来评估空间-通道注意力模块(SCAM)、基于注意力特征融合模块(SC-AFF)以及引入自注意力机制的自注意力主干网络对目标检测算法性能的影响。实验在相同的条件下进行,选择了Ultralytics 5.0版本的YOLOv5s作为基准模型,输入图像分辨率设定为640×640。验证了不同模块的有效性,并评估它们对目标检测算法性能的影响。
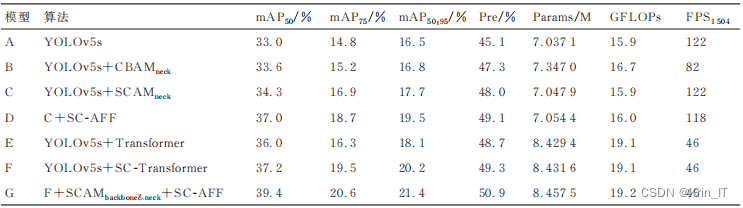
通过在backbone中引入注意力机制和自注意力机制,将更多的注意力集中在密集小目标区域,提升了对小目标的特征提取能力。同时,在特征融合网络的neck部分引入注意力机制,动态分配不同尺度特征图的权重,提高了小目标特征图融合的能力。这种改进算法在保持一定实时性的前提下,有效提升了对小目标的特征提取能力,使得模型在处理无人机航拍图像目标检测任务时具有更大的优势
相关代码如下:
model = yolov5s(pretrained=True)
# 设置模型为评估模式
model.eval()
# 定义类别标签
class_labels = ['object']
# 加载测试图像
image = torch.randn(1, 3, 416, 416) # 示例输入图像,尺寸为(1, 3, 416, 416)
# 运行图像通过模型进行推理
with torch.no_grad():
outputs = model(image)
# 解析预测结果
pred_boxes = outputs.pred[0][:, :4] # 预测框坐标
pred_scores = outputs.pred[0][:, 4] # 预测置信度
pred_class_indices = outputs.pred[0][:, 5].long() # 预测类别索引
# 根据置信度阈值过滤预测结果
threshold = 0.5 # 置信度阈值
filtered_indices = pred_scores >= threshold
filtered_boxes = pred_boxes[filtered_indices]
filtered_scores = pred_scores[filtered_indices]
filtered_class_indices = pred_class_indices[filtered_indices]
实现效果图样例

创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









