







目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于大数据的二手房信息爬取与数据分析
设计思路
一、课题背景与意义
随着互联网技术的迅猛发展和大数据时代的来临,二手房交易信息日益丰富,但如何高效地从海量数据中提取有价值的信息并进行深入分析,成为了一个亟待解决的问题。基于大数据的二手房信息爬取与数据分析课题,旨在通过爬虫技术获取二手房交易数据,并利用数据分析方法挖掘潜在的市场规律、价格趋势和消费者行为等信息。这对于购房者、房产中介、金融机构以及政策制定者都具有重要的现实意义,能够帮助他们做出更加明智的决策,推动二手房市场的健康发展。
二、算法理论原理
2.1 Scrapy 爬取数据
网络爬虫,也被称为网络蜘蛛,是一个由编程者创建的程序,能自动地抓取和解析网页信息,并存储这些信息。它从一个或多个初始的URL开始,不断抓取新的URL并存入访问队列。一旦爬取完当前网页,就从队列中取出下一个URL进行爬取,直到满足停止条件或爬完所有URL。爬取的数据经过解析、筛选后存储到文件或数据库中。网络爬虫在许多领域都有应用,如搜索引擎、数据分析与挖掘、金融分析等。它也可以用于舆情监测、目标客户数据收集和房地产信息收集等。
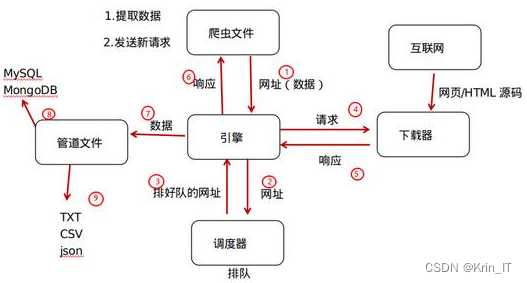
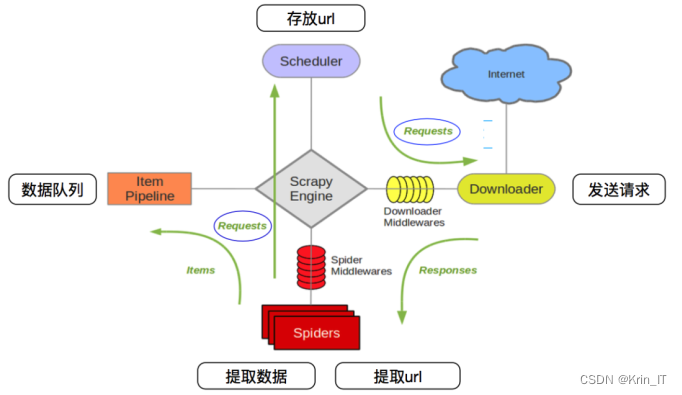
Scrapy是一个用于抓取网站和提取结构化数据的框架,广泛应用于信息处理、数据挖掘和历史存档。考虑到数据的真实性和可靠性,本文选择链接网合肥站进行数据爬取。通过在Anaconda Jupyter Notebook中创建Python3程序,编写爬虫程序,包括定义初始化、获取最大页数、爬取页及解析页的方法,同时设定爬取字段,实现高效的数据爬取。
import scrapy
class Spider(scrapy.Spider):
name = 'house'
start_urls = ['http://www.lianjia.com/fang/'] # 替换为你要爬取的二手房网站首页URL
def parse(self, response):
# 解析页面并提取所需数据
# 例如,提取所有二手房房源的标题和链接
for house in response.css('div.house'):
title = house.css('h1.title::text').get()
link = house.css('a::attr(href)').get()
yield {
'title': title,
'link': link
}2.2 pandas工具包
在数据预处理阶段,需要处理重复值和空值、字段合并以及字段值格式化。对于重复值,可以使用pandas的drop_duplicates方法删除重复数据。对于空值,可以采用均值填充、固定值填充等方法进行处理。字段合并则是根据数据分析需求,将相关列合并生成新的列。字段值格式化则是将需要计算的字段从文本型转换为float类型,并去除单位信息。这些处理可以提高数据分析的准确性和可靠性。
相关代码示例:
import pandas as pd
# 读取数据集
df = pd.read_csv('data.csv')
# 重复值处理
df.drop_duplicates(inplace=True)
# 空值处理
df['单价'].fillna(df['单价'].mean(), inplace=True)
df['地铁'].fillna('无', inplace=True)
# 字段合并
df['地址'] = df['小区'] + ' ' + df['位置']
# 字段值格式化
df['面积'] = df['面积'].str.replace('平方米', '').astype(float)
df['单价'] = df['单价'].astype(float)三、检测的实现
3.1 数据集
首先设计了多个爬虫程序,分别针对不同的房源网站进行爬取。在爬取过程中,我注意处理了反爬虫机制、数据格式不统一等问题,确保数据的准确性和完整性。经过一段时间的爬取和数据清洗工作,我成功构建了一个包含丰富字段的二手房交易数据集。这个数据集涵盖了房源的基本信息、价格、地理位置、户型等多个维度的数据,为我后续的数据分析提供了有力的支持。
3.2 实验及结果分析
数据可视化是一种强大的工具,能够将大量复杂的数据转换为直观、易于理解的图形和图表,从而为决策者提供有力的支持。对于市里每个区域的二手房数量和单价进行分析,并形成相应的折线图和柱状图,可以帮助我们更清晰地了解房地产市场的现状和趋势。
数据准备是进行数据可视化的基础,需要收集市里每个区域的二手房数量和单价数据,并清洗和处理空值、异常值和重复值等问题。之后,将数据整理成适合可视化的格式,每个区域作为一个数据点,包含数量和单价信息。对于分析单价的变化趋势,折线图是一个很好的选择,可以清晰地展示价格随时间的波动。而柱状图则更适合比较不同区域之间的二手房数量差异。通过选择合适的图表类型,能够更好地呈现数据的规律和趋势,为决策提供有力支持。
import pandas as pd
# 读取数据集
df = pd.read_csv('二手房数据.csv')
# 处理空值
df['数量'].fillna(df['数量'].mean(), inplace=True)
df['单价'].fillna(df['单价'].mean(), inplace=True)
# 处理异常值
df = df[(df['数量'] >= 0) & (df['单价'] >= 0)]
# 处理重复值
df.drop_duplicates(inplace=True)使用数据可视化库,如Matplotlib、Seaborn或Plotly,在Python中创建图表是数据可视化的核心步骤。通过绘制每个区域的二手房单价折线图,可以清晰地展示各区域的价格走势。而柱状图则能直观地比较不同区域之间的二手房数量差异。通过分析图表,可以深入了解市场的特点和趋势。例如,观察折线图可以发现哪些区域的二手房单价较高或增长较快,而观察柱状图则能了解哪些区域的二手房供应量较大或相对较少。
# 绘制二手房单价折线图
plt.figure(figsize=(10, 5))
plt.plot(df['区域'], df['单价'], marker='o')
plt.xlabel('区域')
plt.ylabel('单价')
plt.title('二手房单价折线图')
plt.show()
# 绘制二手房数量柱状图
plt.figure(figsize=(10, 5))
plt.bar(df['区域'], df['二手房数量'])
plt.xlabel('区域')
plt.ylabel('二手房数量')
plt.title('二手房数量柱状图')
plt.show()热力图是一种使用颜色表示数据密度或强度的图表,用于展示数据的分布和变化情况。在地理信息可视化中,热力图常用于表示空间位置的数据,帮助人们更好地理解空间分布和变化趋势。通过添加交互功能,用户可以更加深入地探索和分析数据,例如通过鼠标悬停或点击来查看详细的数据信息和操作。热力图有助于人们快速发现数据的分布特征和规律,如数据的高密度区域、低密度区域等。热力图通过颜色的深浅可以快速展示数据的大小,使数据更加直观易懂。
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 读取数据
df = pd.read_csv('二手房数据.csv')
# 将数据整理成适合可视化的格式,每个区域一个数据点,包含数量和单价信息
df_melt = pd.melt(df, id_vars=['区域'], var_name='属性', value_name='值')
# 生成热力图
plt.figure(figsize=(10, 5))
sns.heatmap(df_melt.pivot(index='区域', columns='属性', values='值'), cmap='YlGnBu', annot=True)
plt.xlabel('区域')
plt.ylabel('属性')
plt.show()海浪学长项目示例:

创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!















 1893
1893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









