







欢迎大家点赞、收藏、关注、评论啦 ,由于篇幅有限,只展示了部分核心代码。
一项目简介
一、项目背景与意义
电力负荷预测是电力系统规划和运行的关键环节,对于电网调度、电力供给、电力资源配置等具有重要意义。随着能源管理和优化的需求日益增长,准确预测电力负荷成为了一个迫切的需求。近年来,深度学习技术的快速发展为电力负荷预测提供了新的解决方案。本项目旨在利用Python编程语言和长短期记忆网络(LSTM)深度学习模型,通过整合多种特征对电力负荷进行精准预测。
二、项目目标
构建LSTM预测模型:利用Python编程语言和深度学习框架(如TensorFlow或PyTorch),构建基于LSTM的电力负荷预测模型。
多特征融合:整合时间序列、天气状况等多种特征,通过特征工程技术提取关键信息,提高预测准确性。
模型训练与优化:使用历史电力负荷数据对模型进行训练,并通过交叉验证和损失函数评估模型性能,根据评估结果调整模型参数。
实现精准预测:通过训练好的LSTM模型,对未来的电力负荷进行精准预测,为电力公司提前规划产能、提升运营效率提供支持。
三、技术实现
数据收集与预处理:
收集历史电力负荷数据、时间序列数据、天气状况等数据。
对数据进行清洗、处理缺失值、异常值等。
将非结构化数据(如天气信息)转化为数值形式,以便模型处理。
特征工程:
提取关键特征,包括时间序列特征(如小时、日期、季节)、天气因素(温度、湿度、风速等)。
运用特征选择或降维技术,进一步优化特征集,减少冗余信息。
模型构建与训练:
设计LSTM网络结构,包括输入层、隐藏层(含LSTM单元)和输出层。
选择合适的激活函数、优化器、损失函数等。
使用预处理后的数据训练LSTM模型,通过反向传播算法更新网络权重。
模型评估与优化:
使用测试数据集评估模型性能,计算准确率、召回率、F1分数等指标。
根据评估结果调整LSTM模型的结构和参数,如增加网络层数、改变神经元数量、调整学习率等。
使用交叉验证等技术避免过拟合问题。
预测与可视化:
利用训练好的LSTM模型对未来的电力负荷进行预测。
将预测结果与实际电力负荷数据进行对比和可视化展示。
四、项目特点与优势
高准确性:通过整合多种特征和LSTM模型的优势,实现了对电力负荷的精准预测。
可扩展性:项目采用模块化设计,易于添加新特征或替换现有模型,适应不同场景的需求。
可视化展示:提供预测结果的可视化展示功能,方便用户直观了解预测效果。
实际应用价值:项目成果可用于电力公司的产能规划、能源管理和市场策略制定等方面,具有实际应用价值。
二、功能
基于深度学习Python LSTM的多特征电力负荷预测
三、系统
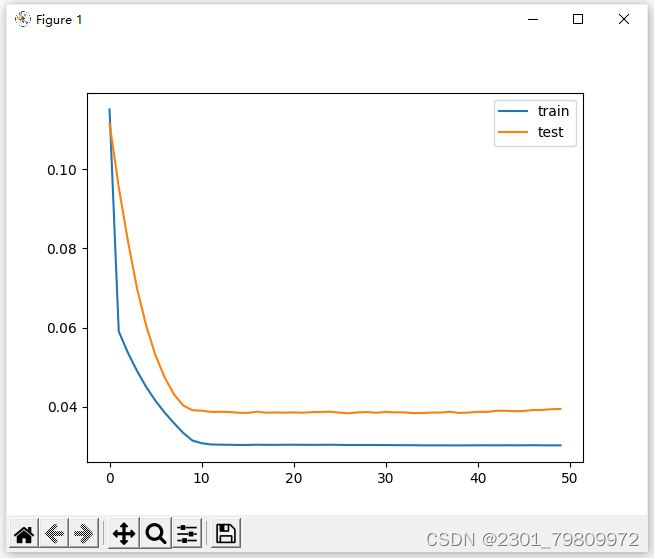
四. 总结
本项目基于深度学习Python LSTM技术实现了多特征电力负荷预测系统,通过整合多种特征和LSTM模型的优势,实现了对电力负荷的精准预测。未来,我们将继续优化模型结构和参数设置,提高预测准确率;同时探索更多应用场景和数据集以验证模型的泛化能力。此外,我们还将关注最新的深度学习技术和算法发展动态,并尝试将它们应用于本项目中以实现更好的效果。















 989
989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









