






损失函数
损失函数(Loss Function)在机器学习和深度学习中扮演着至关重要的角色,它用来衡量模型预测值与真实值之间的差异,是优化算法的核心。通过最小化损失函数,可以使模型的预测结果更接近真实值,从而提高模型的性能。
以下是损失函数的一些重要特点和作用:
-
衡量预测误差:损失函数用来衡量模型输出与真实标签之间的差异或误差。通过定义合适的损失函数,可以指导模型学习如何调整参数以减小误差。
-
优化目标:在训练过程中,优化算法的目标通常是最小化损失函数。通过梯度下降等优化算法,模型会不断调整参数以降低损失函数的值。
-
不同任务使用不同损失函数:不同的任务和模型可能需要使用不同的损失函数。例如,回归问题通常使用均方误差(MSE),分类问题通常使用交叉熵损失(Cross Entropy Loss)或对数损失(Log Loss)。
-
影响模型训练和泛化能力:选择合适的损失函数可以影响模型的训练效果和泛化能力。一些损失函数对异常值敏感,一些损失函数可以帮助模型更好地泛化到未见过的数据。
-
正则化和损失函数:有时候会将正则化项结合到损失函数中,形成带有正则化的损失函数,以避免过拟合。
在机器学习和深度学习中,损失函数用于衡量模型预测值与真实值之间的差异,是优化算法的关键部分。以下是一些常见的损失函数:
-
均方误差(Mean Squared Error,MSE):
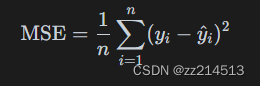
其中,𝑦𝑖 是真实值,𝑦^i 是模型预测值,𝑛 是样本数量。MSE适用于回归问题(线性回归)。
-
交叉熵损失(Cross Entropy Loss):
- 二分类交叉熵损失:
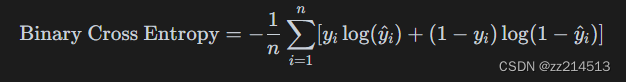
- 多分类交叉熵损失:

其中,𝑦𝑖 是真实标签的概率分布,𝑦^𝑖 是模型预测的概率分布,𝐶 是类别数。交叉熵损失常用于分类问题。
- 二分类交叉熵损失:
-
对数损失(Log Loss):
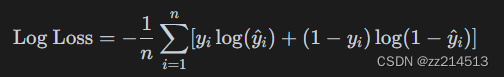
对数损失也是二分类问题中常用的损失函数,特别适用于逻辑回归模型。
-
Hinge Loss:

Hinge Loss通常用于支持向量机(SVM)等模型,特别适用于分类问题。
逻辑回归的损失函数
为了预测输出值和实际值有多接近,我们用预测值和实际值的平方差或者它们平方差的一半,但是逻辑回归的优化目标不是凸优化(找到多个局部最优值),我们需要寻找全局最优值:
![]()
当y = 1时,损失函数为,
尽可能大(因为sigmoid函数【激活函数】取值范围【0,1】,导致
无限接近于1)才能使得L尽可能得小;
当y = 0时,损失函数为,
尽可能小(因为sigmoid函数【激活函数】取值范围【0,1】,导致
无限接近于0)才能使得L尽可能得小。
由此定义算法的代价函数是对𝑚个样本的损失函数求和然后除以m:
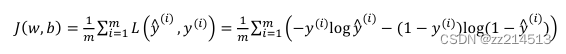
小编持续更新中,有问题欢迎指出~















 1599
1599

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









