







训练循环
训练循环(Training Loop)是深度学习中模型训练的核心逻辑,负责协调数据加载、前向传播、损失计算、反向传播、参数更新等关键步骤。理解训练循环的逻辑不仅是实现自定义训练流程的基础,也是优化训练效率、调试模型的关键。
一、训练循环的本质与核心目标
1. 本质
训练循环是一个迭代优化过程,通过反复向模型输入数据、计算预测误差(损失)、更新模型参数,使模型在目标任务上的性能(如准确率、损失值)逐步提升。其核心是梯度下降(及其变种)的迭代应用。
2. 核心目标
- 最小化损失函数:通过优化模型参数 θ \theta θ,使损失函数 L ( f θ ( x ) , y ) L(f_\theta(x), y) L(fθ(x),y) 最小化。
- 泛化能力:在训练过程中避免过拟合,确保模型在未见过的数据上表现良好。
二、训练循环的核心组成部分
训练循环由多个紧密耦合的模块组成,每个模块承担特定功能,共同完成参数优化。以下是核心组件:
1. 数据加载与预处理(Data Loading)
- 数据划分:将数据集分为训练集(Training Set)、验证集(Validation Set)、测试集(Test Set)。
- 训练集:用于模型参数更新。
- 验证集:用于调整超参数、监控过拟合(不参与参数更新)。
- 测试集:仅在训练结束后评估模型泛化能力。
- 数据迭代器(Data Iterator):将数据划分为批次(Batch),按顺序或随机生成批次数据,支持批量训练(Batch Training)。
- 批次大小(Batch Size):影响内存占用、梯度估计方差和训练速度。
- 数据打乱(Shuffling):避免模型记忆数据顺序,提升泛化性。
- 预处理流程:标准化(Normalization)、归一化(Normalization)、数据增强(Data Augmentation)等,提升模型鲁棒性。
2. 模型定义(Model Definition)
- 网络结构:定义模型的层结构(如卷积层、全连接层)、激活函数、正则化层(如Dropout、BatchNorm)。
- 前向传播(Forward Pass):输入数据通过模型计算输出预测值 y ^ = f θ ( x ) \hat{y} = f_\theta(x) y^=fθ(x)。
3. 损失函数(Loss Function)
- 衡量预测值
y
^
\hat{y}
y^ 与真实值
y
y
y 的差异,如:
- 分类任务:交叉熵损失(Cross-Entropy Loss)、焦点损失(Focal Loss)。
- 回归任务:均方误差(MSE)、平均绝对误差(MAE)。
- 其他:铰链损失(Hinge Loss)、对比损失(Contrastive Loss)等。
4. 优化器(Optimizer)
- 基于损失函数的梯度更新模型参数,核心算法包括:
- 随机梯度下降(SGD):基础算法,需手动设置学习率。
- 自适应优化器:Adam、RMSprop、Adagrad等,自动调整学习率。
- 关键参数:学习率(Learning Rate)、动量(Momentum)、权重衰减(Weight Decay,L2正则化)。
5. 反向传播(Backpropagation)
- 通过链式法则计算损失函数对模型参数的梯度 ∇ θ L \nabla_\theta L ∇θL,用于指导参数更新。
- 自动微分(AutoDiff):深度学习框架(如PyTorch、TensorFlow)自动实现梯度计算,无需手动推导。
6. 学习率调度(Learning Rate Scheduling)
- 在训练过程中动态调整学习率,常见策略:
- 固定学习率:全程保持学习率不变。
- 阶梯衰减(Step Decay):每隔一定 epoch 降低学习率。
- 余弦退火(Cosine Annealing):周期性调整学习率,模拟余弦曲线。
- 自适应调度:根据验证损失动态调整(如 ReduceLROnPlateau)。
7. 验证与测试(Validation & Testing)
- 验证循环(Validation Loop):
- 在训练过程中定期用验证集评估模型,不计算梯度、不更新参数。
- 监控指标:损失值、准确率、F1分数等,用于早停(Early Stopping)和超参数调整。
- 测试循环(Testing Loop):
- 训练结束后用测试集评估最终模型,确保结果未受训练过程干扰。
三、训练循环的执行流程(伪代码解析)
以下是一个典型训练循环的伪代码框架,包含完整逻辑:
# 初始化模型、损失函数、优化器
model = NeuralNetwork()
loss_fn = CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001)
scheduler = CosineAnnealingLR(optimizer, T_max=100) # 学习率调度器
# 数据加载
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=64, shuffle=False)
# 训练循环
best_val_loss = float('inf')
early_stopping_counter = 0
for epoch in range(num_epochs):
# 训练模式(启用Dropout、BatchNorm等)
model.train()
train_loss = 0.0
# 遍历训练批次
for batch_idx, (x, y) in enumerate(train_loader):
# 前向传播
outputs = model(x)
loss = loss_fn(outputs, y)
# 反向传播与参数更新
optimizer.zero_grad() # 清空梯度
loss.backward() # 计算梯度
optimizer.step() # 更新参数
# 记录训练损失
train_loss += loss.item() * x.size(0)
# 打印中间结果(可选)
if batch_idx % log_interval == 0:
print(f"Epoch {epoch+1}, Batch {batch_idx}, Loss: {loss.item():.4f}")
# 计算 epoch 平均训练损失
train_loss = train_loss / len(train_loader.dataset)
# 验证循环(每个 epoch 结束后)
model.eval() # 评估模式(关闭Dropout、BatchNorm更新)
val_loss = 0.0
correct = 0
with torch.no_grad(): # 不计算梯度,节省内存
for x, y in val_loader:
outputs = model(x)
val_loss += loss_fn(outputs, y).item() * x.size(0)
_, preds = torch.max(outputs, 1)
correct += (preds == y).sum().item()
val_loss = val_loss / len(val_loader.dataset)
val_acc = correct / len(val_loader.dataset)
# 打印 epoch 结果
print(f"Epoch {epoch+1}/{num_epochs}, Train Loss: {train_loss:.4f}, Val Loss: {val_loss:.4f}, Val Acc: {val_acc:.4f}")
# 学习率调度更新
scheduler.step()
# 早停判断:若验证损失连续多次未下降,则终止训练
if val_loss < best_val_loss:
best_val_loss = val_loss
early_stopping_counter = 0
torch.save(model.state_dict(), "best_model.pth") # 保存最佳模型
else:
early_stopping_counter += 1
if early_stopping_counter >= early_stopping_patience:
print("Early stopping triggered.")
break
关键流程解析
- Epoch vs. Batch:
- Epoch:完整遍历一次训练数据集。
- Batch:一次迭代处理的一小部分数据,用于近似计算全量数据的梯度。
- 训练模式与评估模式:
model.train():启用Dropout、BatchNorm的更新机制。model.eval():关闭Dropout、固定BatchNorm参数(使用训练集的统计量)。
- 梯度清零(optimizer.zero_grad()):
- 避免梯度累加(PyTorch默认保留梯度),确保每个批次的梯度计算独立。
- 验证集的无梯度计算:
- 使用
with torch.no_grad()或tf.GradientTape()的watch参数关闭梯度计算,提升效率。
- 使用
四、训练循环的高级技巧与优化策略
1. 梯度相关技巧
- 梯度裁剪(Gradient Clipping):
- 防止梯度爆炸(Vanishing/Exploding Gradients),如:
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) # PyTorch - 混合精度训练(Mixed Precision Training):
- 使用FP16(半精度)计算梯度,减少内存占用和计算时间,需框架支持(如PyTorch的
torch.cuda.amp)。
- 使用FP16(半精度)计算梯度,减少内存占用和计算时间,需框架支持(如PyTorch的
2. 正则化与防过拟合
- 权重衰减(Weight Decay):在优化器中添加L2正则化,抑制参数过大。
- 早停(Early Stopping):当验证损失不再下降时终止训练,避免过拟合。
- 标签平滑(Label Smoothing):在损失函数中对真实标签添加噪声,防止模型过于自信。
3. 分布式训练(Distributed Training)
- 数据并行(Data Parallelism):将批次数据拆分到多个GPU,同步梯度更新(如PyTorch的
DataParallel/DistributedDataParallel)。 - 模型并行(Model Parallelism):将模型层拆分到不同GPU,适用于超大规模模型。
4. 自定义训练循环 vs. 框架内置循环
- 内置循环(如Keras的fit()):
- 优势:简洁、自动处理验证、支持回调函数(Callback)。
- 劣势:灵活性低,难以实现复杂逻辑(如动态调整损失函数)。
- 自定义训练循环:
- 优势:完全控制流程,支持定制化逻辑(如多任务学习、对抗训练)。
- 劣势:需手动实现数据加载、监控等细节。
5. 监控与调试
- 日志记录:记录损失、准确率、学习率等指标,常用工具:TensorBoard、WandB。
- 可视化:绘制损失曲线、特征分布、混淆矩阵,辅助分析模型行为。
- 调试技巧:
- 检查梯度是否为NaN/Inf,排查数据或模型结构问题。
- 使用
torch.autograd.grad_check验证梯度计算的正确性。
五、不同学习任务的训练循环差异
1. 监督学习(Supervised Learning)
- 核心流程:数据输入 → 前向传播 → 损失计算(基于标签)→ 反向传播。
- 典型场景:图像分类、回归预测。
2. 无监督学习(Unsupervised Learning)
- 损失函数设计:基于数据自身结构(如重构误差、对比损失)。
- 示例:自动编码器(AE)、变分自动编码器(VAE)、对比学习(Contrastive Learning)。
3. 半监督学习(Semi-Supervised Learning)
- 结合有标签和无标签数据,损失函数包含监督项和无监督项(如一致性损失)。
- 示例:Pseudo-Labeling、Mean Teacher模型。
4. 强化学习(Reinforcement Learning, RL)
- 训练循环包含环境交互:智能体与环境互动生成轨迹(状态、动作、奖励)。
- 核心组件:策略网络(Policy Network)、值函数(Value Function)、经验回放缓冲区(Experience Replay Buffer)。
- 典型算法:Q-Learning、深度强化学习(如DQN、PPO)。
六、框架差异与最佳实践
1. PyTorch vs. TensorFlow/Keras
| 特性 | PyTorch | TensorFlow/Keras |
|---|---|---|
| 动态图 vs. 静态图 | 动态图(Eager Execution),灵活易调试 | 静态图(Graph Execution),需编译优化 |
| 训练循环 | 需手动实现(自定义性强) | 内置model.fit(),支持自定义train_step |
| 自动微分 | torch.autograd自动跟踪梯度 | tf.GradientTape显式记录计算过程 |
2. 最佳实践
- 使用预训练模型:基于预训练权重初始化,减少训练时间(如迁移学习)。
- 批次大小调优:在内存允许的范围内尽量增大批次大小,提升并行效率。
- 断点续训(Checkpointing):保存训练状态(模型参数、优化器状态、epoch数),避免意外中断导致重复训练。
七、常见问题与解决方案
1. 损失不下降/NaN
- 原因:数据异常(如标签错误、全零输入)、学习率过高、梯度爆炸。
- 解决方案:检查数据预处理、降低学习率、启用梯度裁剪、使用更稳定的优化器(如Adam)。
2. 过拟合
- 原因:模型复杂度高、训练数据少、正则化不足。
- 解决方案:增加数据增强、添加Dropout/BatchNorm、使用早停或权重衰减。
3. 训练速度慢
- 原因:批次大小过小、硬件未充分利用(如未启用GPU)、框架优化不足。
- 解决方案:增大批次大小、启用混合精度训练、使用分布式训练、优化数据加载流程(如使用
num_workers预加载数据)。
总结:训练循环的核心逻辑脉络
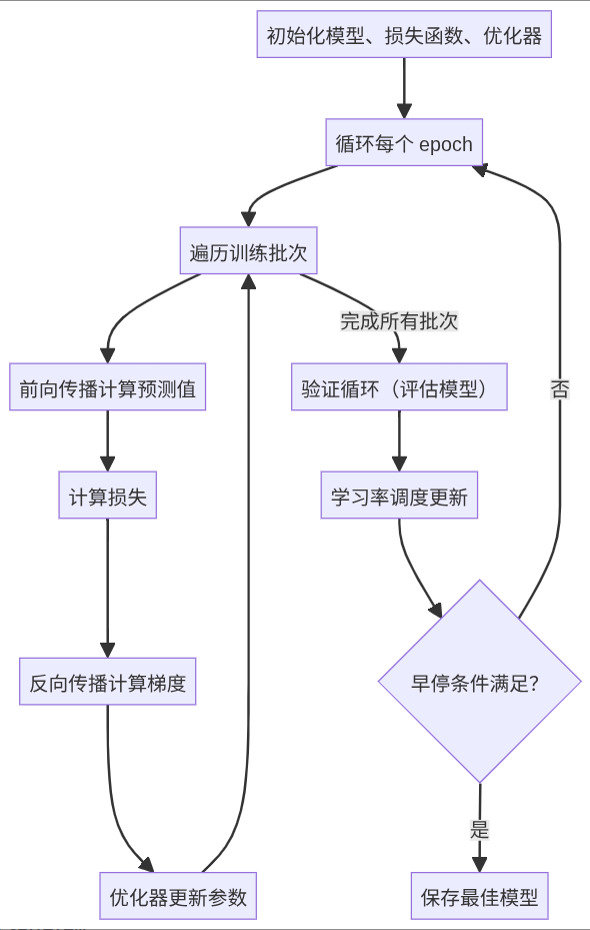
训练循环的设计需平衡灵活性与效率,理解其底层逻辑(如梯度下降、自动微分)是解决实际问题的关键。通过合理组合数据预处理、损失函数、优化策略,并结合框架特性,可高效实现从简单模型到复杂神经网络的训练过程。
训练迭代
在深度学习中,清空梯度、计算梯度、更新参数是训练神经网络的核心步骤,它们共同构成了优化模型参数的闭环。
一、清空梯度(Clear Gradients)
逻辑原理
- 梯度的累加特性:神经网络在反向传播时,梯度会累加到参数的
.grad属性中(如 PyTorch 的Tensor.grad)。若不手动清空,当前批次的梯度会与历史梯度叠加,导致参数更新偏离当前批次的真实梯度方向。 - 批次独立性要求:训练时通常按批次(Batch)处理数据,每个批次的梯度应仅反映该批次数据的误差,而非所有历史批次的累积误差。
为什么要这样做?
- 避免梯度泄漏:例如,若连续两个批次计算梯度时未清空,第二批的梯度会加到第一批的梯度上,导致参数更新基于错误的“混合梯度”,引发训练不稳定甚至发散。
- 确保单次迭代的独立性:每次迭代仅针对当前批次数据计算梯度,符合随机梯度下降(SGD)的基本假设。
代码示例(PyTorch)
optimizer.zero_grad() # 清空优化器管理的所有参数的梯度
二、计算梯度(Compute Gradients)
逻辑原理
- 正向传播与反向传播:
- 正向传播:输入数据通过神经网络,计算输出值和损失函数(如交叉熵损失)。
- 反向传播:从损失函数出发,利用链式法则(Chain Rule)逐层计算每个参数的梯度(导数),表示损失对该参数的敏感程度。
- 梯度的物理意义:梯度是损失函数对参数的导数,指示了参数更新的方向(梯度上升方向为损失增加最快的方向,梯度下降则反之)。
为什么要这样做?
- 指导参数更新方向:没有梯度,就无法知道如何调整参数以降低损失。梯度是优化的“指南针”。
- 实现端到端优化:通过反向传播,梯度能将输出层的误差传递到所有中间层,实现对整个网络参数的联合优化。
代码示例(PyTorch)
output = model(input) # 正向传播
loss = criterion(output, target) # 计算损失
loss.backward() # 反向传播,计算所有参数的梯度
三、更新参数(Update Parameters)
逻辑原理
- 优化算法的作用:基于计算得到的梯度,使用优化算法(如 SGD、Adam、RMSprop 等)更新参数。典型公式为:
参数= 参数 - 学习率 * 梯度(或其修正值) - 参数更新的本质:通过调整权重和偏置,使模型在后续迭代中对输入数据的预测更接近真实标签,从而降低损失。
为什么要这样做?
- 实现模型学习:清空梯度和计算梯度只是准备工作,参数更新才是“学习”的实际动作。若不更新参数,模型将永远停留在初始状态,无法优化。
- 平衡学习效率与稳定性:不同优化算法通过调整梯度(如引入动量、自适应学习率),可在收敛速度和避免局部最优解之间取得平衡。
代码示例(PyTorch)
optimizer.step() # 执行参数更新(如 SGD: w = w - lr * grad)
四、三步逻辑的内在联系与执行顺序
1. 顺序不可颠倒
- 清空梯度 → 计算梯度 → 更新参数:
- 若不清空梯度直接计算,会导致梯度累加(错误);
- 若先更新参数再计算梯度,下一次迭代的梯度将基于已更新的参数,符合逻辑,但实际流程中需先处理当前批次数据。
2. 循环迭代的意义
- 这三步构成一次完整的训练迭代(Iteration),通过不断遍历训练数据(Epoch),模型逐渐拟合数据分布。
- 示例流程:
for epoch in range(num_epochs): for batch in data_loader: inputs, targets = batch optimizer.zero_grad() # 1. 清空梯度 outputs = model(inputs) # 正向传播 loss = criterion(outputs, targets) # 计算损失 loss.backward() # 2. 计算梯度 optimizer.step() # 3. 更新参数
3. 框架的自动化支持
- 在 PyTorch、TensorFlow 等框架中,清空梯度可能由优化器自动处理(如
optimizer.zero_grad()),或需手动调用;计算梯度和更新参数则通过backward()和step()显式触发。 - 关键注意点:若使用自定义梯度(如
torch.autograd.grad),需特别注意梯度的累加问题,避免内存泄漏或计算错误。
五、常见问题与深层理解
1. 为什么梯度需要手动清空?框架不能自动处理吗?
- 框架设计时考虑到灵活性:梯度累加在某些场景下是有用的(如梯度累积,Gradient Accumulation),用于模拟更大的批次大小。因此,是否清空梯度由用户决定,而非强制自动清空。
2. 梯度计算与参数更新的解耦
- 在某些高级场景中(如多GPU训练、半精度训练),梯度计算和参数更新可能分离(如先收集所有GPU的梯度再更新),但核心逻辑仍遵循“计算→更新”的顺序。
3. 梯度消失/爆炸的影响
- 若梯度计算后数值异常(如趋近于0或无穷大),参数更新将失效。此时需通过正则化、归一化、激活函数选择等手段缓解。
总结
- 清空梯度:确保每次迭代的梯度仅来自当前批次,避免历史干扰;
- 计算梯度:通过反向传播确定参数调整的方向和幅度;
- 更新参数:利用优化算法执行实际的参数调整,实现模型学习。
这三步形成了深度学习优化的最小闭环,缺一不可。理解其逻辑不仅能帮助正确编写训练代码,还能深入分析训练过程中的异常(如损失波动、收敛缓慢等),是掌握神经网络训练的核心基础。


















 2985
2985

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









