






在结构体初阶的时候学习了结构体的声明和初始化,我们知道,声明相当于给了一个建筑图纸,知道结构体要怎么建立、包含哪些类型,此时并没有在内存中开辟空间,而当初始化的时候,才算用这个图纸盖了一栋房子,在内存中开辟了空间
然后学习了两种访问成员的方法以及结构体传参,今天学习结构体的自引用和内存对齐
1、结构体的自引用
在数据存储的时候,有两种存储方式,一个是顺序存储结构一个是链式存储结构
顺序存储结构就是数据从低地址到高地址连续存储
那如果我们不想顺序存储呢,那只能打乱顺序排放存储,但是我们又想在找到其中一个的时候找到下一个,那这时候就需要用到链式存储结构

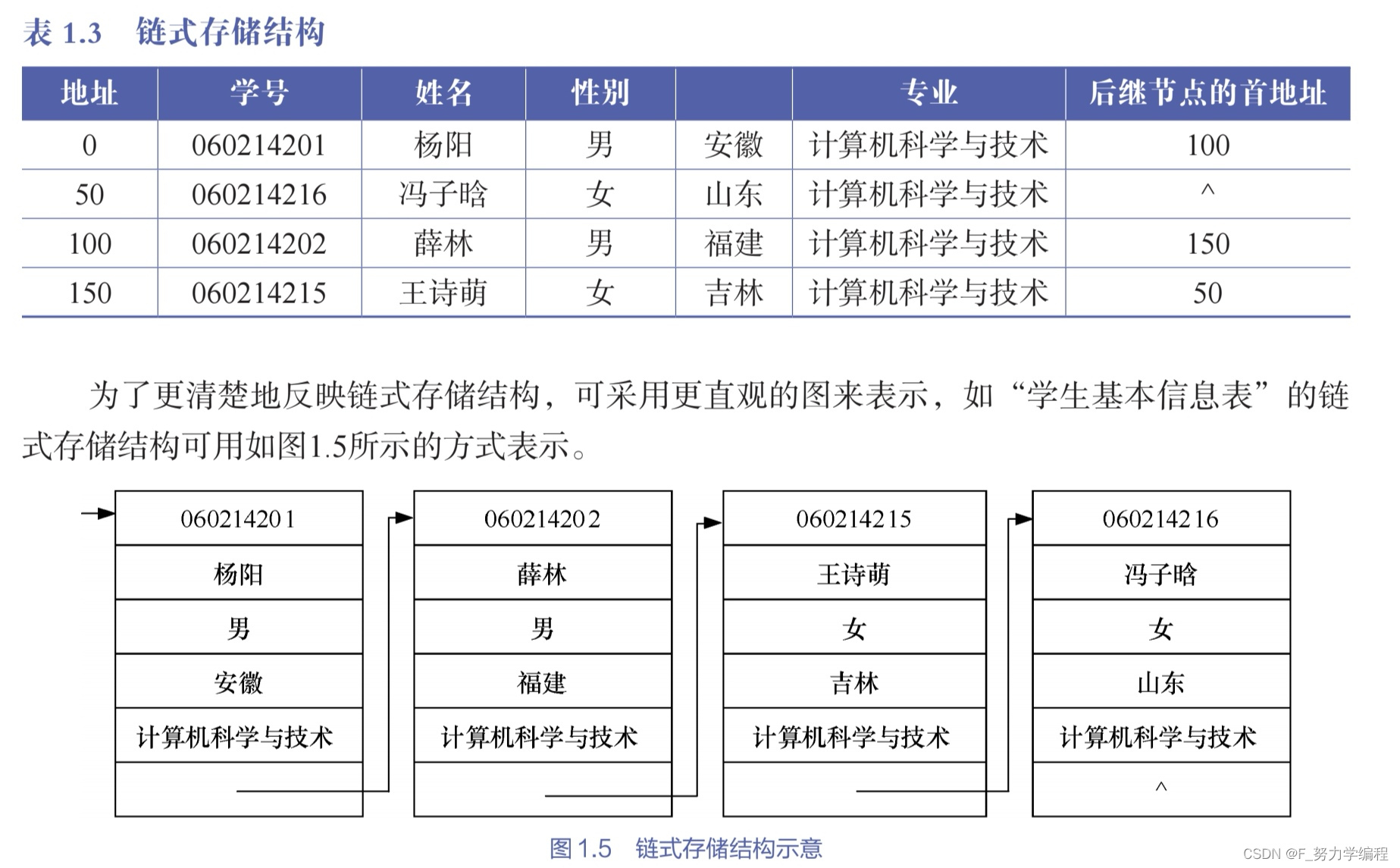
代码实现:

注意:第一种写法是错误的,因为结构体嵌套自己本身时,无法计算该结构体的大小,会不断的引用自身导致程序崩溃(相当于递归没有终止条件)
而且我们在上面也说过链式存储结构要包含下一个数据的地址,所以这里要用指针(指针的大小就可以计算了)

第一种代码不可行,因为在结构体声明的时候没有写出struct tag中的tag(结构体标签),所以这个代码是非法的
1/3日更新
第一种不可行的原因是在还没有重新定义名字的时候就使用了Node,所以才不可行,并不是说tag省略就错了
第二种代码是重新定义类型:
typedef意思是把这个结构体重新定义了一个新的名字,以后想用它那么:
struct Node n;
Node n2;
就是一个意思了
2、内存对齐
当知道了结构体的基本使用之后,那我们应该考虑一个问题,结构体的大小应该如何计算?
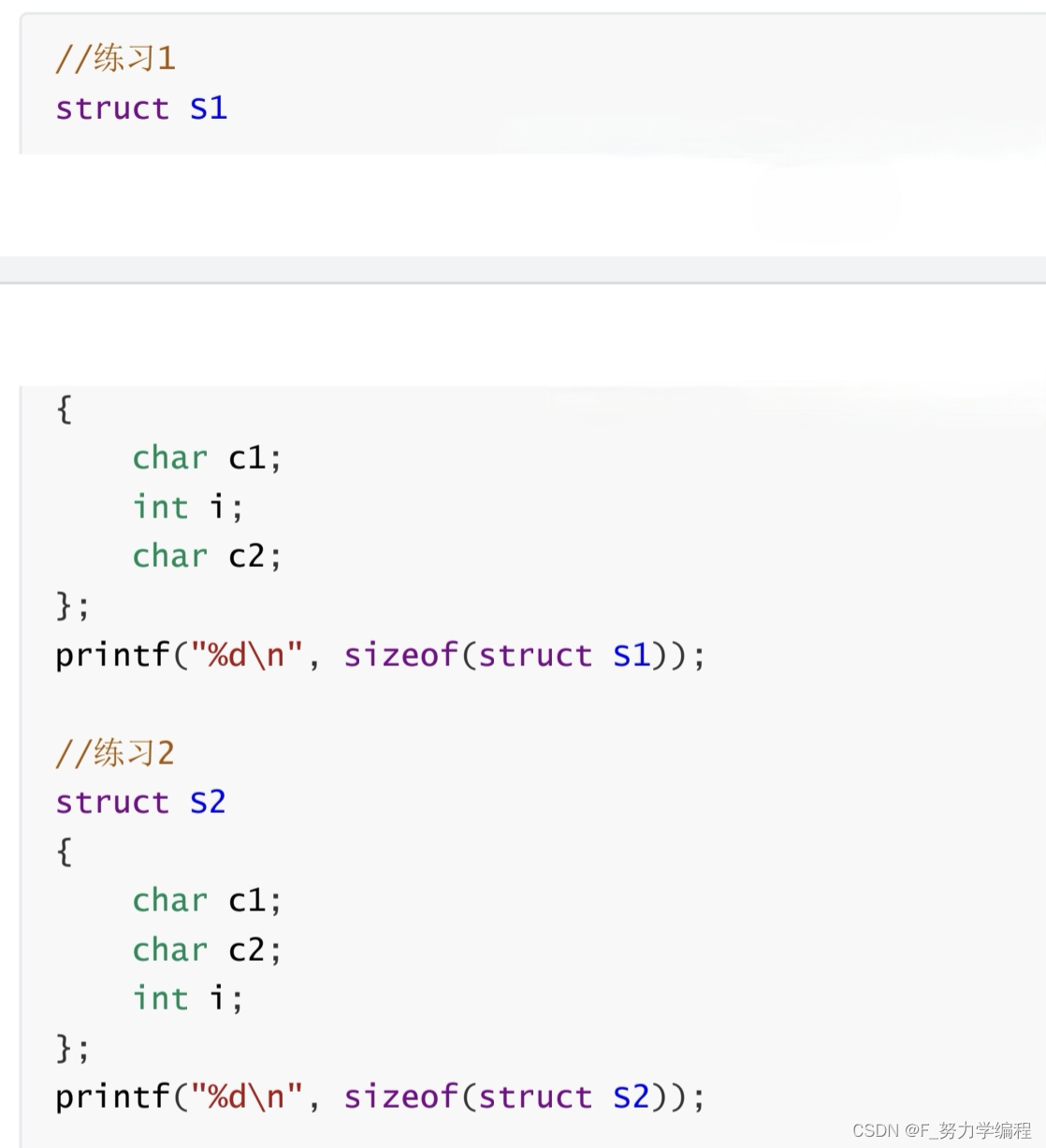
s1大小是12,s2大小是8
仅仅只是结构体里面换个顺序,为什么大小会不一样呢?
这里要介绍一个规则:内存对齐

根据对齐规则一个一个看:
1.什么是偏移量
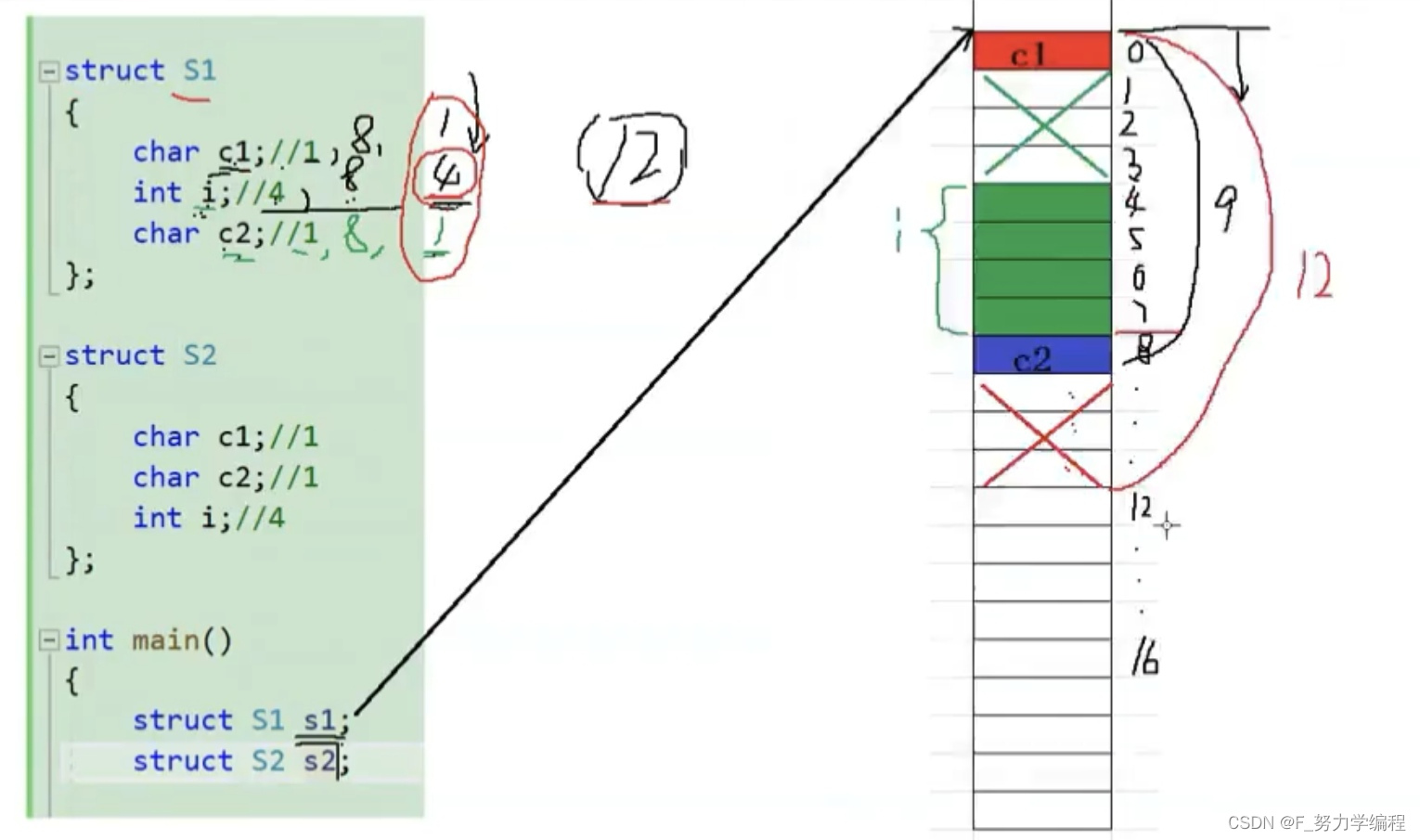
以s1举例:当确定了s1在某个地址处开始时,它的第一个内存块就是偏移量为0的地址,第二个内存块是偏移量为1的地址,以此类推
2、对齐数
s1第一个成员放完之后,占用了偏移量为0的内存块,然后开始放第二个成员,从第二个开始就要考虑对齐数,根据规则,第二个成员的对齐数为4
那么4的整数倍是4、8、12等等,所以第二个成员要从偏移量为4的内存块开始(绿色部分)
接着看第三个成员,它的对齐数是1,也就是哪里都能放,所以直接放在第二个成员后面就行,此时结构体总大小应该是9个字节
3、结构体总大小
全部成员放完之后并不算结束,还要检查结构体的总大小,我们知道s1最大对齐数是4,所以结构体的总大小应该是4、8、12、16等等,所以我们要把s1的总大小修正为12
4、嵌套结构体的大小计算

根据上述规则计算s3:
double的大小8字节,从偏移量为0的内存块开始存放,连续存放八个字节;
char的大小1字节,对齐数是1,直接在偏移量为8的内存块存放,占一个字节;
int的大小4字节,对齐数是4,此时只能从偏移量为9的内存块存放,所以要对齐到偏移量为12的内存块,存放4个字节,此时存放到了偏移量为15的内存块,大小为16字节
检查,s3最大对齐数是8,16是8的整数倍,所以该结构体总大小是16字节
然后再来看s4的嵌套结构体大小
char大小1字节,在偏移量为0的内存块;
结构体s3的最大对齐数是8,所以要放在偏移量为8的内存块,连续存放16个字节,此时最后存放的在偏移量为23的内存块;
double对齐数是8,存放在偏移量为24的内存块中,连续存放8个字节,此时最后偏移量为31
所有最大对齐数是8,32字节符合要求,所以s4的大小是8
为什么存在内存对齐?
内存对齐会浪费空间,那为啥还要这样做呢?
1.平台原因(移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些定类型的数据,否则抛出硬件异常
2.性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。
原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问
总的来说:
结构体的内存对齐就是拿空间换时间的做法
















 986
986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









