






时间序列问题分析
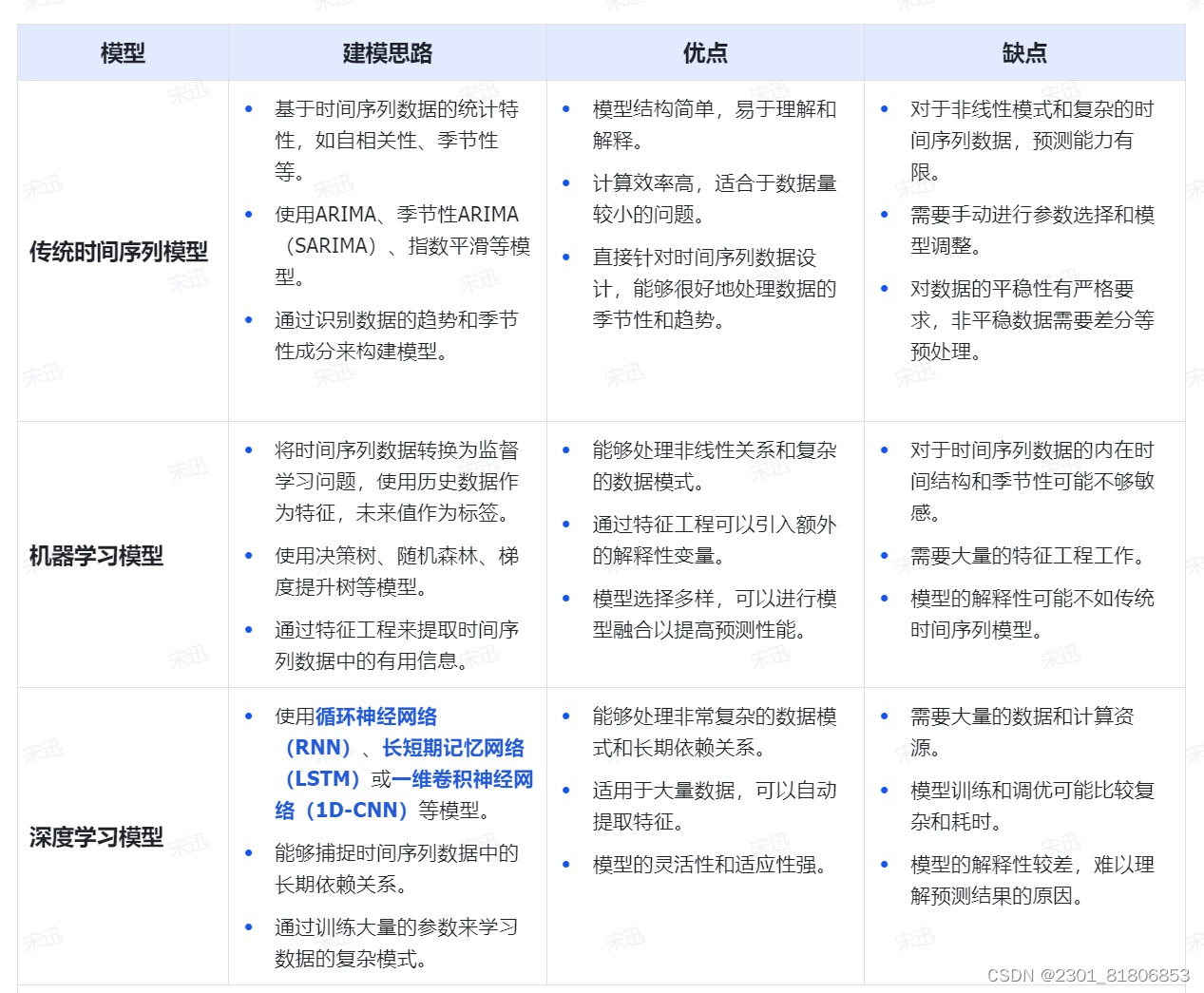
时间序列问题是针对时间顺序排列的数据点进行分析和预测,而序列问题可分为时间序列模型、机器学习模型和深度学习模型。

代码分析
这段代码是用于电力需求预测任务的数据预处理部分,主要目的是计算训练集中每个id在时间戳小于等于20的情况下target列的平均值,并将这个平均值应用到测试集上。下面是对代码每一行的详细解释:
1.导入了两个常用的Python数据分析库:pandas和numpy。import pandas as pd
import numpy as np
这两行代码分别导入了pandas和numpy库,它们是进行数据处理和分析的基础工具。
2.从文件中读取训练集和测试集数据。train = pd.read_csv('./data/data283931/train.csv')
test = pd.read_csv('./data/data283931/test.csv')
这两行代码使用pandas的read_csv()函数来读取位于指定路径的训练集和测试集数据,并将其存储为DataFrame对象。
3.计算训练数据中每个id在时间戳小于等于20时对应的target列的平均值。target_mean = train[train['dt']<=20].groupby(['id'])['target'].mean().reset_index()
这里首先筛选出训练集中dt列值小于等于20的行,然后按id分组并对target列求均值。reset_index()方法用于重置索引,使得结果的索引变为常规的整数索引。
4.将计算得到的target平均值合并到测试集中。test = test.merge(target_mean, on=['id'], how='left')
这行代码将test DataFrame与target_mean DataFrame基于id列进行左连接合并。这意味着对于测试集中的每一个id,如果存在对应的target均值,则将其添加到测试集中;如果不存在,则保持原样。
5.将处理后的结果保存到本地文件。test[['id','dt','target']].to_csv('submit.csv', index=None)
最后一行代码将处理好的测试集数据保存为CSV文件,其中只包含id, dt, 和target三列。index=None参数表示不写入索引列。
建议:
1.数据读取:确保train.csv和test.csv文件的路径正确无误,并且文件格式符合预期。如果文件路径或名称有变化,需要相应更新这里的路径。
2.数据筛选:在计算target平均值时,代码假设dt列是一个时间序列类型,并且只考虑了dt小于等于20的情况。如果dt不是时间序列或者需要考虑的时间范围不同,应该相应调整筛选条件。
3.数据合并:使用merge方法时,确保on参数指定的列名在两个DataFrame中都存在,并且拼写一致。此外,how='left'表示左连接,这通常是为了保留测试集中的所有记录,即使某些id在target_mean中没有匹配项。
4.结果保存:保存的文件只包含了id, dt, target三列,这是根据任务需求决定的。如果需要包含其他信息,应相应增加列名。
优化建议
1.错误处理:在读取文件时,可以添加异常处理代码以应对文件不存在等情况。
2.性能优化:如果数据量很大,可以考虑使用更高效的方法来计算均值,例如使用dask库来处理大数据,或者使用groupby的transform方法来减少内存占用。
3.数据验证:在合并之前,应该检查训练集和测试集的列是否匹配,以及id列是否有缺失值。
4.结果检查:在保存结果前,应该检查数据是否存在空值或者异常值。
机器学习知识
















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









