






LAMA
LAMA: Language Models as Knowledge Bases? 2019.9
任务:NLU(实事抽取)
prompt: cloze + Hand Craft Prompt
核心:不经过微调的Bert在知识抽取和开放与问答上效果惊人的好,可以比肩有监督的KG基准
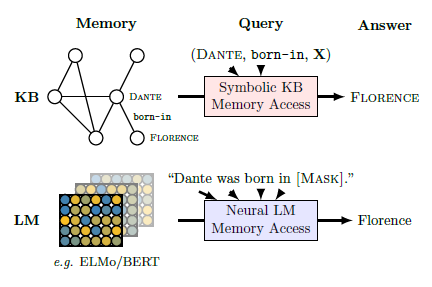
LAMA是在GPT2和GPT3之间提出的一个探测(probe)任务,旨在研究预训练模型存储的知识信息,这里只考虑实体关系三元组(Subject, Relation, Object)。
LAMA设计的Probe方案就是人工设计的完形填空(cloze)类型的prompt模板。例如把出生地实体识别,转化成小明出生于[MASK]的完形填空任务,如果模型预测MASK正确,就认为模型掌握了这一知识。
来具体说下LAMA针对不同关系构建的Prompt模板。论文使用以下4个评测数据
-
Google-RE
Wikipedia抽取的事实,包括5种关系,论文只保留了出生地,死亡地,出生日期3种关系,因为剩余两种的预测结果为多token,而LAMA的答案模板限制只预测1个token。每种关系作者手工构建了Prompt填空模板,举个栗子
-
出生时间
-
Federico Falco is an Argentinian writer born in [MASK] .
-
Steve Lindsey (born May, 6th [MASK]) is an American record producer
-
-
出生地
-
Lucy Toulmin Smith was born at [MASK], Massachusetts, USA
-
Born in [MASK], New Jersey, Connor attended parochial schools as a child
-
-
死亡地
-
Uvedale Tomkins Price died at [MASK] in 1764
-
Lewin died on December 18, 2010, at the age of 84 in [MASK]
-
-
T-REx
wikidata三元组,比Google-RE范围更广,作者选取了41种关系,每种关系采样了1000条事实。每种关系作者手工构建了Prompt模板,部分Prompt如下
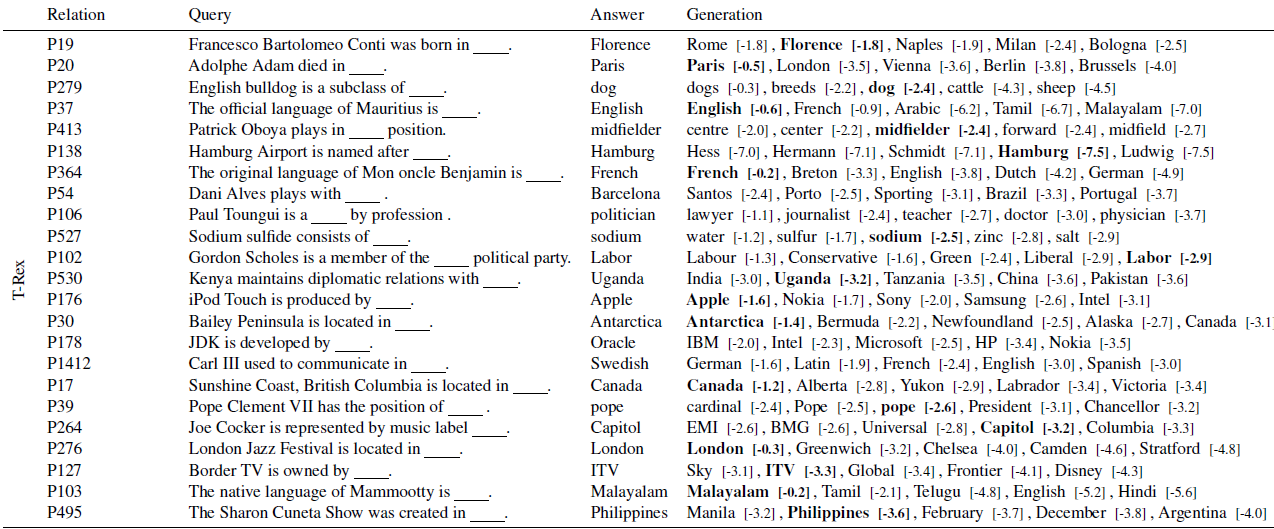
-
ConceptNet
多语言词之间的常识关系,作者只考虑object为英文单字的16种关系,部分prompt如下

-
SQuAD
QA数据集,论文选取了305条上下文无关,且回答为单字的问题。prompt模板通过人工把问题改造成MLM语句得到,举个例子
-
The Normans combine with the [MASK] culture in Ireland
-
Isaac's chains made out of [MASK].
因为LAMA只检测实体三元组关系,所以除Squad外的prompt模板可以抽象为'[X] relation [Y]'的完形填空形式, 但是prompt构建本身还是依赖人工,完整的LAMA数据集详见github~
这类Hand Crafted Prompt的构建主要有2个问题,一个是全靠人工,另一个在论文中也有提到就是不同的prompt对结果有较大影响,那如何找到最优的构建方案是个需要解决的问题
在Answer模板上LAMA限定了答案只能是token,这和它选择的预训练模型是BERT有关,所以Answer的解析没啥好说的就判断预测token是否正确即可。
其他探测任务相关的细节这里就不展开,感兴趣的盆友可以去看论文~
AutoPrompt
paper: AutoPrompt Eliciting Knowledge from Language Models,2020.10
任务:NLU(NLI,实事抽取,关系抽取)
prompt: Discrete + Gradient Search Prompt
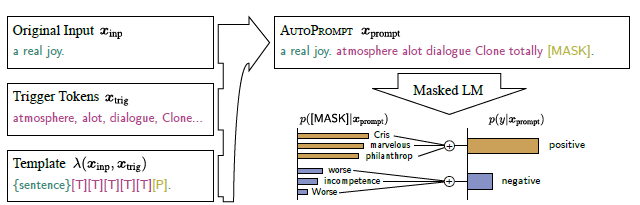
AutoPrompt是在LAMA上的改进,针对LAMA需要人工构造Prompt的问题,提出了一种基于梯度自动生成提示词的方案。论文针对分类任务,作者设计了通用的prompt模板如下,在原始文本输入的基础上,拼接多个触发词[T],最后一个MASK token为模型预测[P]。

下面分别针对Prompt和Answer Engineering来说下细节
Gradient-Based Prompt Search
LAMA的一个核心问题就是人工构造Prompt的成本和效果的不确定性,AutoPrompt借鉴了文本对抗AdvTrigger的梯度搜索方案,给定样本和模型可以自动搜索任务相关触发词。
AdvTrigger旨在找到和输入以及模型无关的通用Trigger,把这个Trigger拼接在输入文本的开头或者结尾可以使得模型得到特定的结果,可以是增加模型的误判率,使得模型输出有种族歧视的文本,或者让模型输出相同的错误结果等等。以下是AdvTrigger中给出的例子(注意以下案例只显示模型结果)

AutoPrompt使用了相同的Trigger搜索方式,首先把触发词用[MASK]初始化,然后逐步迭代来最大化以下似然函数,即加入触发词后MASK预测为正确标签的概率最大化
p(y|xprompt)=∑wp([MASK]=w|xprompt)
每一步迭代通过用以下一阶泰勒展开来近似把触发词改成j后似然函数的变化(梯度*词向量),得到最大化似然函数的topK个触发词。然后把触发词拼接输入,重新计算上述似然函数。以上两步迭代多次,得到最终的TopK触发词,这里K作为超参可以有{3,6}个
Vcand=topkw∈V[wTin▽logp(y|xprompt)]
所以AutoPrompt虽然省去了人工构建prompt,但是需要下游标注任务样本来搜索触发词,一定程度上不算是tunning-free范式,更像是Fixed-LM Prompt-Tunning,除非搜索得到的触发词能直接迁移到相同任务其他领域数据中,不过这部分论文中并未评测。
Auto Label Token Selection
AutoPrompt除了评估事实抽取任务,还加入了对分类任务的评估所以需要对Answer部分进行额外处理把模型预测的token映射到分类标签。这里主要是多token到单label的映射,例如哪些单词代表情感正向,哪些是负向。依旧是基于下游人物样本的有监督方案,top-k标签词的选择需要两步
第一步是label表征,作者使用了模型对[MASK]的模型输出作为x,真实标签作为Y,训练了一个logit classifer,这时模型权重(hidden_size * label_size )其实就是标签的空间表征

第二步是token打分,作者把[MASK]替换为其他候选token,p(y|htoken)�(�|ℎ�����)概率值越高,意味着token的输出向量和标签向量相似度越高,因此选择概率值最高的K个token来作为标签的答案词。
最后我们看下AutoPrompt搜索得到的触发词和答案长啥样,可以说是完全出乎意料,毫无逻辑可言,触发词和答案候选词都很离谱哈哈哈

至于效果AutoPrompt超越LAMA嘛,本身AutoPrompt就是使用下游任务样本搜索的Prompt和label,不好才奇怪不是~~~
在线教程
- 麻省理工学院人工智能视频教程 – 麻省理工人工智能课程
- 人工智能入门 – 人工智能基础学习。Peter Norvig举办的课程
- EdX 人工智能 – 此课程讲授人工智能计算机系统设计的基本概念和技术。
- 人工智能中的计划 – 计划是人工智能系统的基础部分之一。在这个课程中,你将会学习到让机器人执行一系列动作所需要的基本算法。
- 机器人人工智能 – 这个课程将会教授你实现人工智能的基本方法,包括:概率推算,计划和搜索,本地化,跟踪和控制,全部都是围绕有关机器人设计。
- 机器学习 – 有指导和无指导情况下的基本机器学习算法
- 机器学习中的神经网络 – 智能神经网络上的算法和实践经验
- 斯坦福统计学习
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓


人工智能书籍
- OpenCV(中文版).(布拉德斯基等)
- OpenCV+3计算机视觉++Python语言实现+第二版
- OpenCV3编程入门 毛星云编著
- 数字图像处理_第三版
- 人工智能:一种现代的方法
- 深度学习面试宝典
- 深度学习之PyTorch物体检测实战
- 吴恩达DeepLearning.ai中文版笔记
- 计算机视觉中的多视图几何
- PyTorch-官方推荐教程-英文版
- 《神经网络与深度学习》(邱锡鹏-20191121)
- …

第一阶段:零基础入门(3-6个月)
新手应首先通过少而精的学习,看到全景图,建立大局观。 通过完成小实验,建立信心,才能避免“从入门到放弃”的尴尬。因此,第一阶段只推荐4本最必要的书(而且这些书到了第二、三阶段也能继续用),入门以后,在后续学习中再“哪里不会补哪里”即可。

第二阶段:基础进阶(3-6个月)
熟读《机器学习算法的数学解析与Python实现》并动手实践后,你已经对机器学习有了基本的了解,不再是小白了。这时可以开始触类旁通,学习热门技术,加强实践水平。在深入学习的同时,也可以探索自己感兴趣的方向,为求职面试打好基础。

第三阶段:工作应用

这一阶段你已经不再需要引导,只需要一些推荐书目。如果你从入门时就确认了未来的工作方向,可以在第二阶段就提前阅读相关入门书籍(对应“商业落地五大方向”中的前两本),然后再“哪里不会补哪里”。
有需要的小伙伴,可以点击下方链接免费领取或者V扫描下方二维码免费领取🆓

















 4017
4017











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









