






在AI浪潮席卷全球的今天,阿里巴巴云通义千问团队再次震撼业界!全新一代混合推理模型 Qwen3 正式开源,凭借“小而强大”的卓越性能和灵活多场景适配能力,刷新了全球开源模型的智能新高度。无论是数学推理、代码生成,还是多语言交互,Qwen3 都展现出无与伦比的实力!今天,我们就来一探究竟,看看这款“AI新星”如何为你的工作和生活注入无限可能!
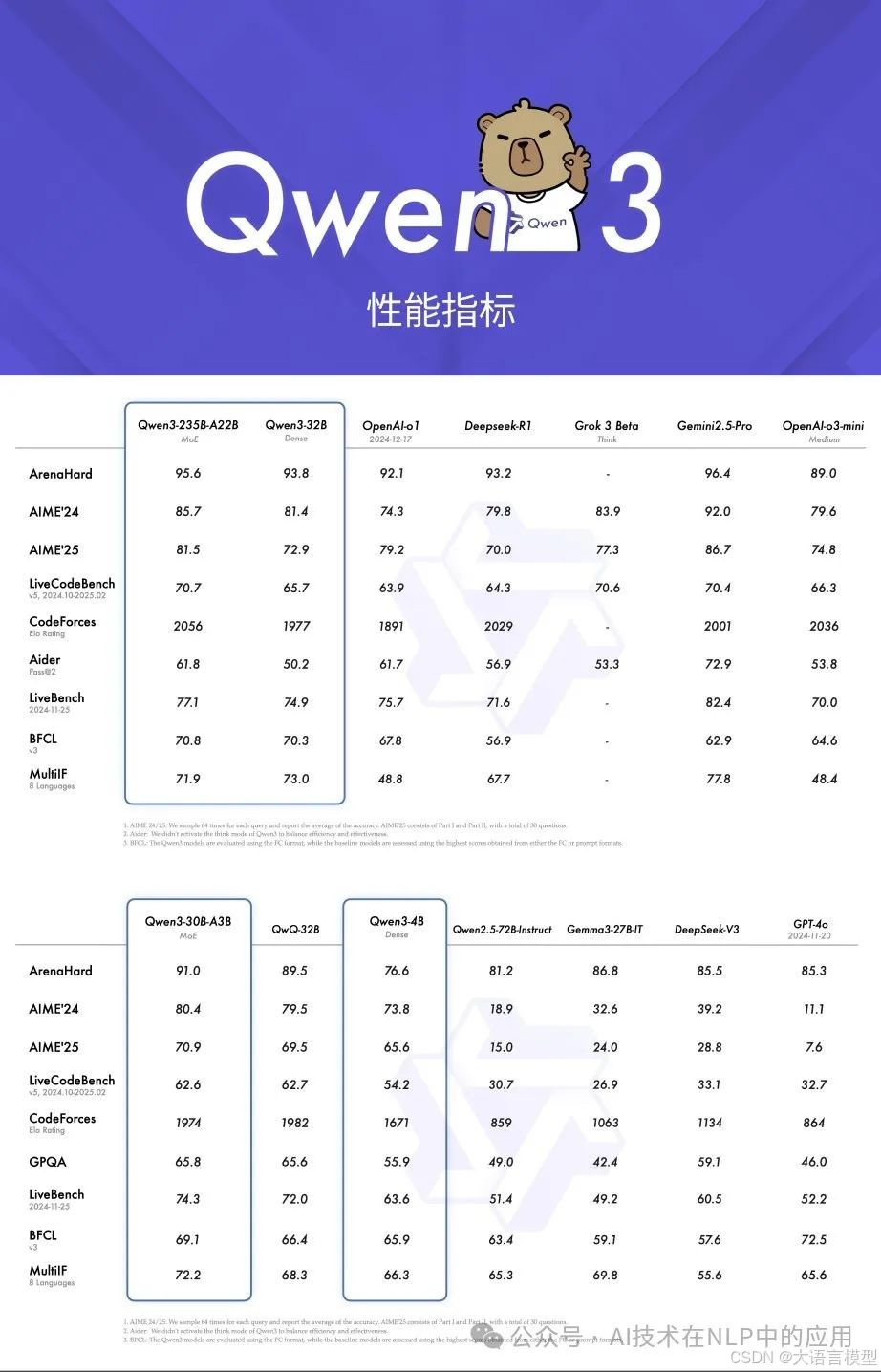
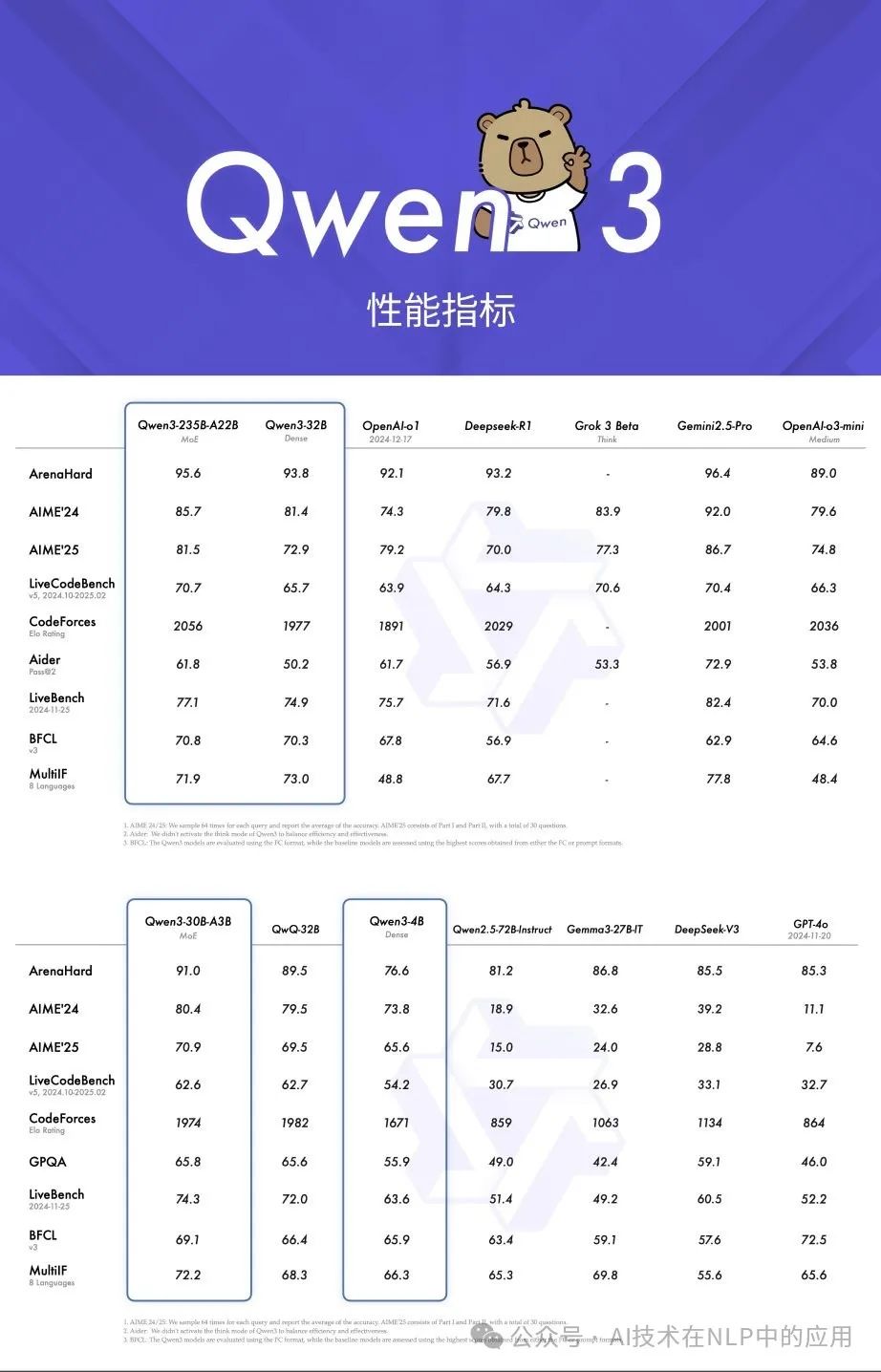
一、性能炸裂:小模型,大能量
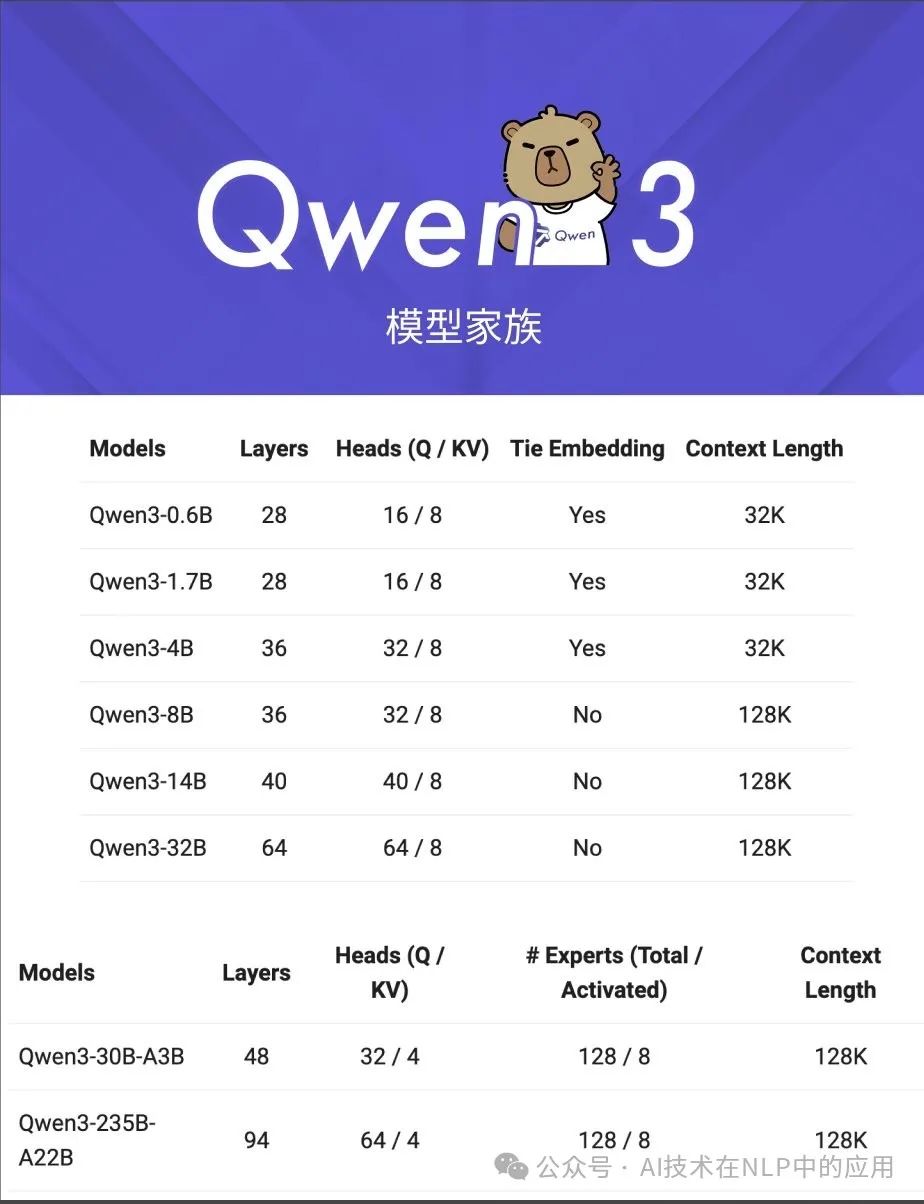
Qwen3 系列涵盖从 0.6B 到 235B 的多种规模模型,其中旗舰款 Qwen3-235B-A22B 以仅 22B 激活参数的混合专家(MoE)架构,实现了对上一代超大规模 Dense 模型的全面超越!
权威评测亮眼表现:在 GPQA、AIME24/25、LiveCodeBench 等国际权威评测中,Qwen3 性能直逼 GPT o1,稳居开源模型前列。
高效能低显存:Qwen3-235B-A22B 的显存占用仅为同级别模型的 1/3,让复杂任务处理更轻松,部署成本大幅降低。
多领域全能选手:从数学推理到代码生成,再到综合逻辑分析,Qwen3 都能游刃有余,堪称“全能王”!
更令人振奋的是,Qwen3 预训练数据量高达 36万亿 tokens,通过多轮强化学习和精细优化,在指令遵循、工具调用及多语言能力上实现质的飞跃,支持 119种语言,覆盖全球主要语种,真正实现“全球通”!
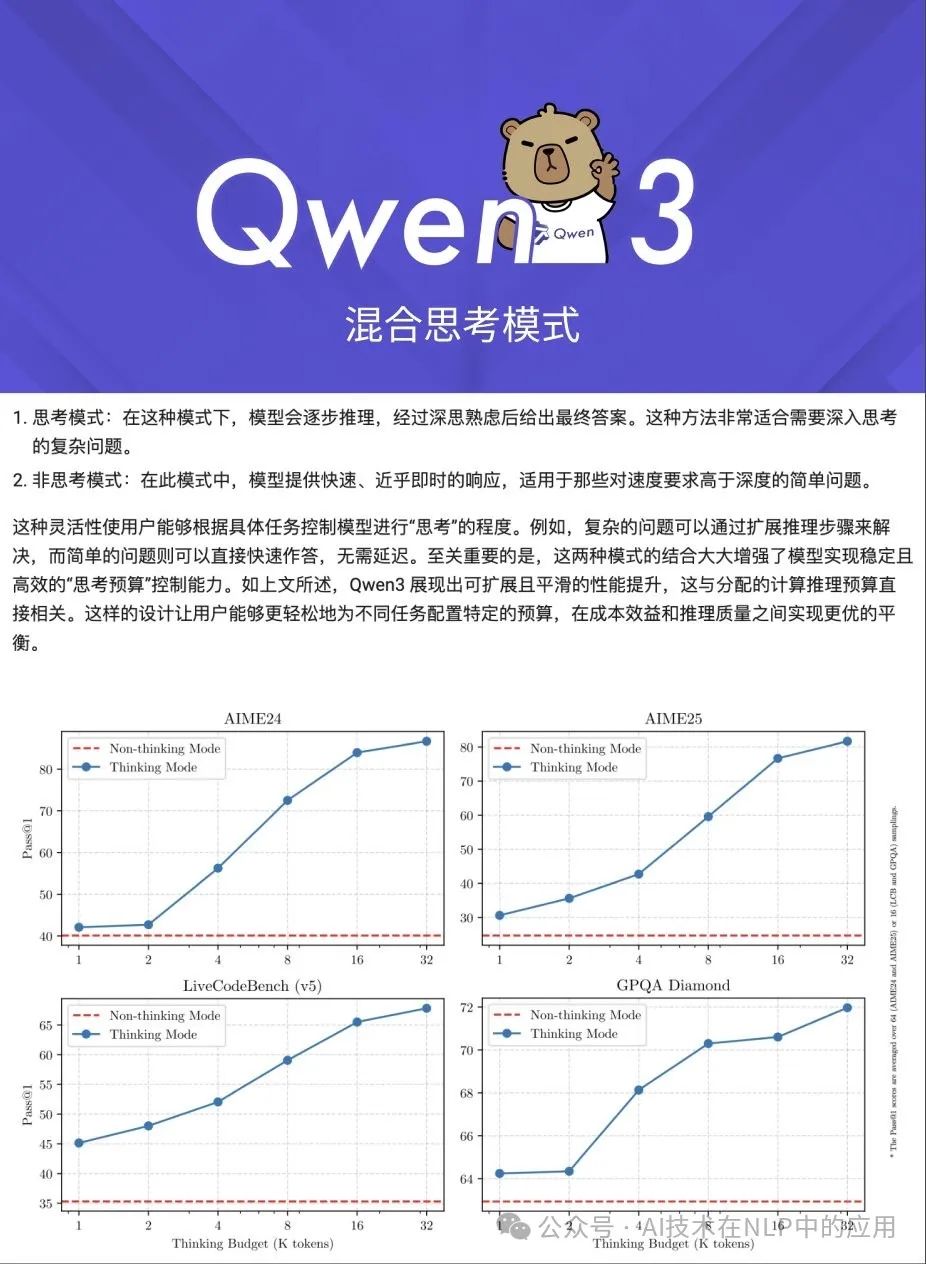
二、思考与非思考模式:灵活应对一切场景
Qwen3 的最大亮点之一是其独特的 “思考模式”与“非思考模式”,让模型在不同任务中切换自如,兼顾深度与效率:
-
• 思考模式:像人类一样“深思熟虑”,适合复杂任务。例如,在解数学题或编写代码时,模型会反复验证逻辑,输出包裹在
<think>...</think>块中的推理过程,确保结果精准。 -
• 非思考模式:追求极致速度,适合日常对话或快速问答,直接给出答案,响应秒级完成。
通过简单指令(如 /think 或 /no_think)或配置文件,你就能轻松切换模式。无论是需要严谨推理的学术研究,还是实时互动的聊天场景,Qwen3 都能完美适配!
互动示例:
想知道“strawberries 中有多少个 r”?在思考模式下,Qwen3 会一步步拆解:
Bot: <think> Let's break down the word "strawberries" into individual characters: s-t-r-a-w-b-e-r-r-i-e-s. Counting the 'r's: 1 (r in str), 2 (r in ber), 3 (r in ries). </think> There are 3 r's in "strawberries".
而在非思考模式下,直接秒回:
Bot: 3
三、开发者友好:多框架无缝集成
Qwen3 不仅性能强大,还为开发者提供了极佳的体验:
-
• 多框架支持:兼容 Hugging Face Transformers、vLLM、SGLang 等主流框架,部署简单高效。
-
• OpenAI API 兼容:通过 vLLM 或 SGLang 可快速创建与 OpenAI API 兼容的端点,开发门槛低。
-
• 本地开发便捷:支持 Ollama、LMStudio、llama.cpp 等工具,运行
ollama run qwen3:30b-a3b即可快速上手。 -
想快速体验?以下是一个简单的 Hugging Face Transformers 示例:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Give me a short introduction to large language model."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True, enable_thinking=True)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)
output = tokenizer.decode(generated_ids[0][len(model_inputs.input_ids[0]):], skip_special_tokens=True)
print(output)四、Agent 能力:让 AI 成为你的智能助手
通过 Qwen-Agent 框架,Qwen3 的工具调用能力进一步释放!无论是代码解释器、网页抓取,还是自定义工具集成,Qwen-Agent 都能大幅降低开发复杂性。
例如,你可以让 Qwen3 帮你分析网页内容:
from qwen_agent.agents import Assistant
llm_cfg = {'model': 'Qwen3-30B-A3B', 'model_server': 'http://localhost:8000/v1', 'api_key': 'EMPTY'}
tools = ['code_interpreter', {'mcpServers': {'fetch': {'command': 'uvx', 'args': ['mcp-server-fetch']}}}]
bot = Assistant(llm=llm_cfg, function_list=tools)
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
print(responses)五、开源生态:携手共建 AI 未来
Qwen3 系列模型(除部分规模外)均采用 Apache 2.0 许可,完全开源,开发者可自由使用和定制。阿里云百炼平台即将上线 Qwen3,提供 100万 tokens 免费体验,还有 Qwen Chat 网页版(https://chat.qwen.ai)让你随时随地体验!
写在最后
Qwen3 的发布,不仅是通义千问团队在 AI 领域的又一里程碑,也是全球开源社区的共同胜利!正如通义千问团队所说:“Qwickly forging AGI, enhancing intelligence。” Qwen3 正在加速推动人工智能通用化,让每个人都能享受 AI 的便利。
你准备好迎接 AI 新时代了吗?快来体验 Qwen3,解锁属于你的智能未来!在评论区告诉我们,你最期待用 Qwen3 做什么?是写代码、解数学题,还是打造专属智能助手?别忘了点个“在看”或分享给朋友,一起加入这场 AI 革命!
资源链接:
-
• Hugging Face: https://huggingface.co/Qwen/Qwen3-235B-A22B
-
• 魔搭社区: https://modelscope.cn/models/Qwen/Qwen3-235B-A22B
-
• 阿里云百炼: https://www.aliyun.com/product/tongyi
#Qwen3#Qwen#AI#通义千问

如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 994
994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









