






Token 是什么
token 是大模型(LLM)用来表示自然语言文本的基本单位,可以直观的理解为 “字” 或 “词”。
通常 1 个中文词语、1 个英文单词、1 个数字或 1 个符号计为 1 个 token
一般情况下模型中 token 和字数的换算比例大致如下:
- 1 个英文字符 ≈ 0.3 个 token。
- 1 个中文字符 ≈ 0.6 个 token。
所以,我们可以近似的认为一个汉字就是一个 token
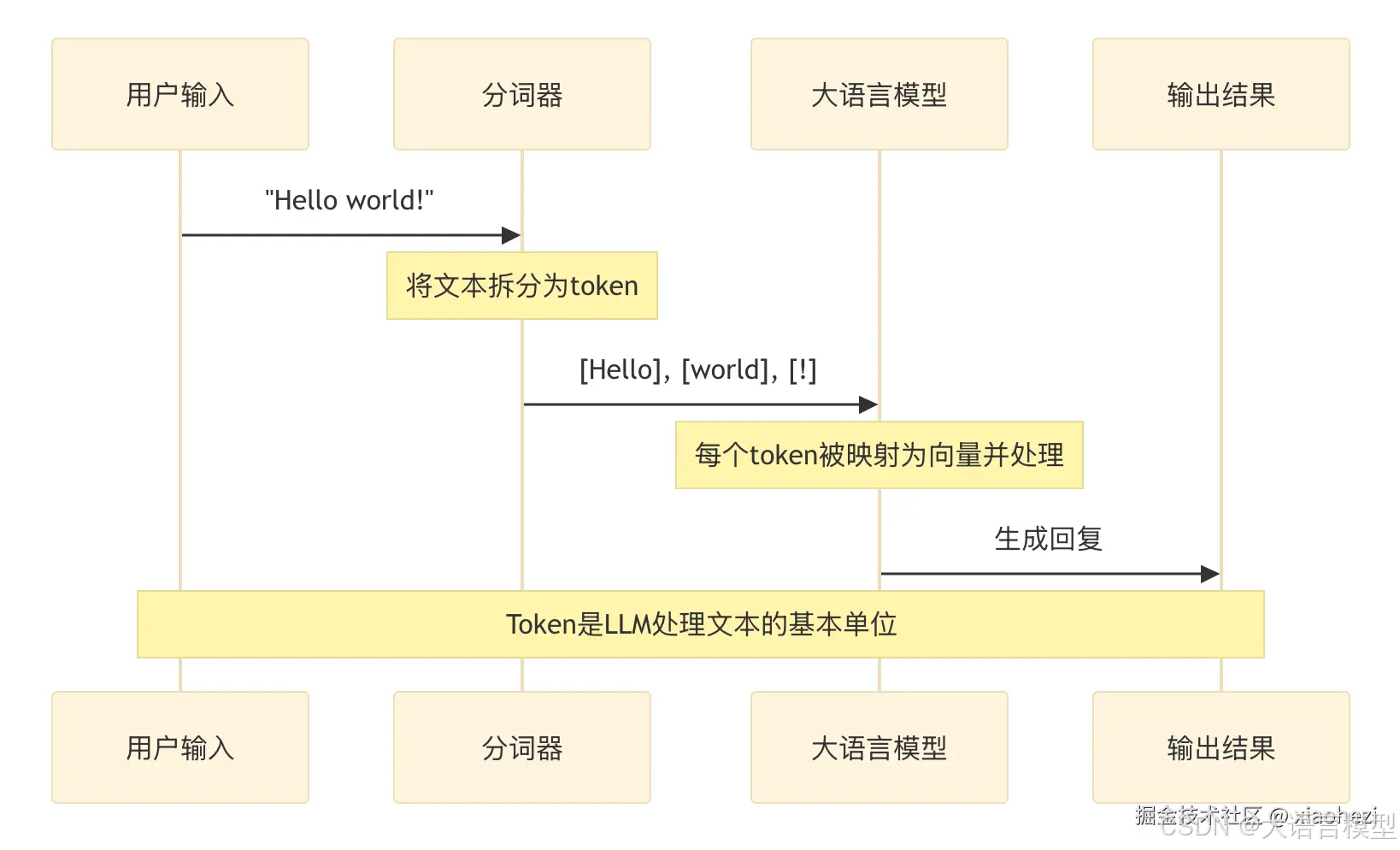
大模型处理我们的输入也是将文本转成 token 再处理的:
最大输出长度
这里我们以 DeepSeek 为例:
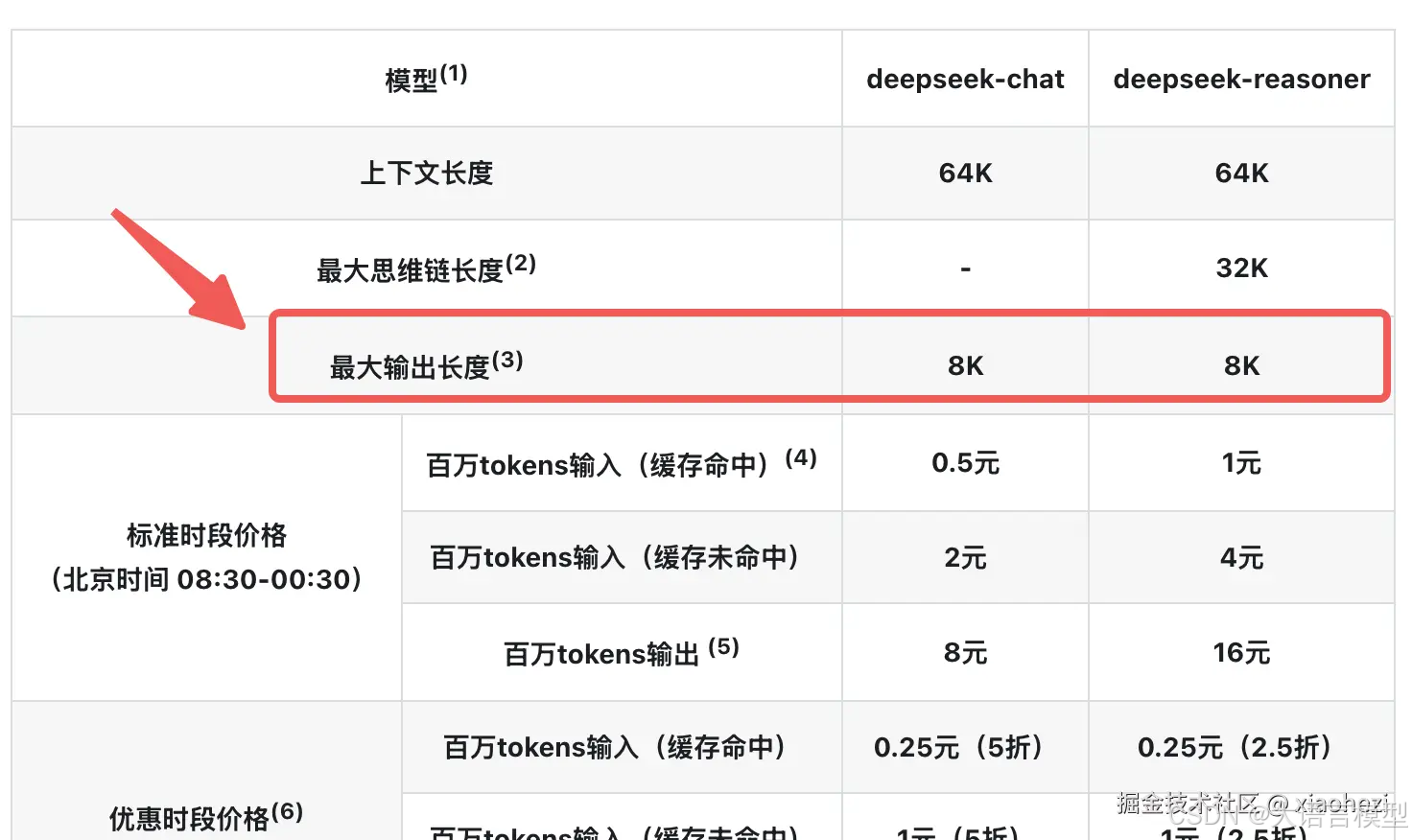
上图中 deepseek-chat 模型对应 DeepSeek-V3;deepseek-reasoner 模型对应 DeepSeek-R1
可以看到在 DeepSeek 中,无论是推理模型 R1 还是对话模型 V3 他们的最大输出长度均为 8K 。
我们已经知道一个汉字近似的等于一个 token ,那么这 8K 的意思就可以约等于说:一次输出最多不超过 8000 个字
最大输出长度这个概念非常清晰,很好理解,反正就是模型每次给你的输出最多 8000 个字,多了你就别想了,超限制了,人家做不到~~
上下文长度
“上下文长度” 在技术领域实际上有一个专有的名词:Context Window
我们还是以 DeepSeek 为例:
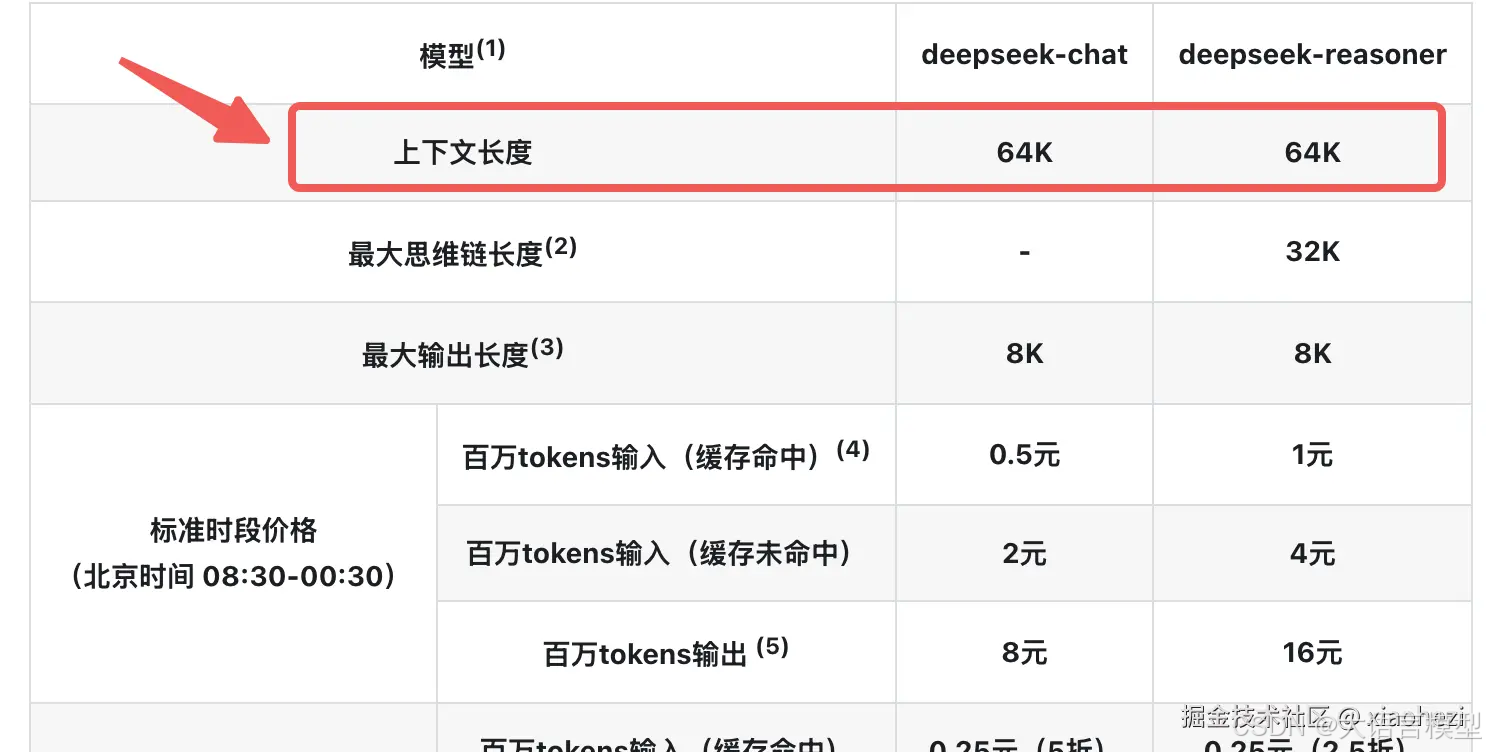
可以看到无论是推理模型还是对话模型 Context Window 都是 64K ,
这个 64K 意味着什么呢 ?请继续往下看。
如果我们要给 Context Window 下一个定义,那么应该是这样:
LLM 的 Context Window 指模型在单次推理过程中可处理的全部 token 序列的最大长度,包括:
- 输入部分(用户提供的提示词、历史对话内容、附加文档等)
- 输出部分(模型当前正在生成的响应内容)
这里我们解释一下,比如当你打开一个 DeepSeek 的会话窗口,开启一个新的会话,然后你输入内容,接着模型给你输出内容。这就是一个 单次推理 过程。在这简单的一来一回的过程中,所有内容(输入+输出)的文字(tokens)总和不能超过 64K(约 6 万多字)。
你可能会问,那输入多少有限制吗?
有。上文我们介绍了 “上下文长度”,我们知道最长 8K,那么输入内容的上限就是:64K- 8K = 56K
总结来说在一次问答中,你最多输入 5 万多字,模型最多给你输出 8 千多字。
你可能还会问,那多轮对话呢?每一轮都一样吗?
不一样。这里我们要稍微介绍一下多轮对话的原理
多轮对话
我们仍然以 DeepSeek 为例,假设我们使用的是 API 来调用模型。
多轮对话发起时,服务端不记录用户请求的上下文,用户在每次请求时,需将之前所有对话历史拼接好后,传递给对话 API。
以下是个示例代码,看不懂没关系就是示意一下:
from openai import OpenAI client = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com") # Round 1 messages = [{"role": "user", "content": "What's the highest mountain in the world?"}] response = client.chat.completions.create( model="deepseek-chat", messages=messages ) messages.append(response.choices[0].message) print(f"Messages Round 1: {messages}") # Round 2 messages.append({"role": "user", "content": "What is the second?"}) response = client.chat.completions.create( model="deepseek-chat", messages=messages ) messages.append(response.choices[0].message) print(f"Messages Round 2: {messages}")
在第一轮请求时,传递给 API 的 messages 为:
[
{"role": "user", "content": "What's the highest mountain in the world?"}
]
在第二轮请求时:
- 要将第一轮中模型的输出添加到 messages 末尾
- 将新的提问添加到 messages 末尾
最终传递给 API 的 messages 为:
[
{"role": "user", "content": "What's the highest mountain in the world?"},
{"role": "assistant", "content": "The highest mountain in the world is Mount Everest."},
{"role": "user", "content": "What is the second?"}
]
所以多轮对话其实就是:把历史的记录(输入+输出)后面拼接上最新的输入,然后一起提交给大模型。
那么在多轮对话的情况下,**实际上并不是每一轮对话的 Context Window 都是 64K,而是随着对话轮次的增多 Context Window 越来越小。**比如第一轮对话的输入+输出使用了 32K,那么第二轮就只剩下 32K 了,原理正如上文我们分析的那样。
到这里你可能还有疑问 🤔 :不对呀,如果按照你这么说,那么我每轮对话的输入+输出 都很长的话,那么用不了几轮就超过模型限制无法使用了啊。可是我却能正常使用,无论多少轮,模型都能响应并输出内容。
这是一个非常好的问题,这个问题涉及下一个概念,我把它叫做 “上下文截断”
上下文截断
在我们使用基于大模型的产品时(比如 DeepSeek、智谱清言),服务提供商不会让用户直接面对硬性限制,而是通过 “上下文截断” 策略实现“超长文本处理”。
举例来说:模型原生支持 64K,但用户累计输入+输出已达 64K ,当用户再进行一次请求(比如输入有 2K)时就超限了,这时候服务端仅保留最后 64K tokens 供模型参考,前 2K 被丢弃。对用户来说,最后输入的内容被保留了下来,最早的输入(甚至输出)被丢弃了。
这就是为什么在我们进行多轮对话时,虽然还是能够得到正常响应,但大模型会产生 “失忆” 的状况。没办法,Context Window 就那么多,记不住那么多东西,只能记住后面的忘了前面的。
这里请注意,“上下文截断” 是工程层面的策略,而非模型原生能力 ,我们在使用时无感,是因为服务端隐藏了截断过程。

到这里我们总结一下:
- 上下文窗口(如 64K)是模型处理单次请求的硬限制,输入+输出总和不可突破;
- 服务端通过上下文截断历史 tokens,允许用户在多轮对话中突破
Context Window限制,但牺牲长期记忆 - 上下文窗口限制是服务端为控制成本或风险设置的策略,与模型能力无关
各模型参数对比
各模型厂商对于 最大输出长度和上下文长度的参数设置是不一样的,我们以 OpenAI 和 Anthropic 为例,概览一下:

上图中,Context Tokens 就是上下文长度,Output Tokens 是最大输出长度。
技术原理
为什么要有这些限制呢?从技术的角度讲比较复杂,我们简单说一下,感兴趣的可以顺着关键词再去探索一下。
在模型架构层面,上下文窗口是硬性约束,由以下因素决定:
-
位置编码的范围:
Transformer模型通过位置编码(如 RoPE、ALiBi)为每个 token 分配位置信息,其设计范围直接限制模型能处理的最大序列长度。 -
自注意力机制的计算方式:生成每个新
token时,模型需计算其与所有历史token(输入+已生成输出) 的注意力权重,因此总序列长度严格受限。KV Cache 的显存占用与总序列长度成正比,超过窗口会导致显存溢出或计算错误。
典型场景与应对策略
既然知道了最大输出长度和上下文长度的概念,也知道了它们背后的逻辑和原理,那么我们在使用大模型工具时就要有自己的使用策略,这样才能事半功倍。
-
短输入 + 长输出
- 场景:输入 1K tokens,希望生成长篇内容。
- 配置:设置 max_tokens=63,000(需满足 1K + 63K ≤ 64K)。
- 风险:输出可能因内容质量检测(如重复性、敏感词)被提前终止。
-
长输入 + 短输出
- 场景:输入 60K tokens 的文档,要求生成摘要。
- 配置:设置 max_tokens=4,000(60K + 4K ≤ 64K)。
- 风险:若实际输出需要更多 tokens,需压缩输入(如提取关键段落)。
-
多轮对话管理
规则:历史对话的累计输入+输出总和 ≤ 64K(超出部分被截断)。
示例:
- 第1轮:输入 10K + 输出 10K → 累计 20K
- 第2轮:输入 30K + 输出 14K → 累计 64K
- 第3轮:新输入 5K → 服务端丢弃最早的 5K tokens,保留最后 59K 历史 + 新输入 5K = 64K。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 8098
8098

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









