






这一周的主要目的是提升你的神经网络的性能
训练、开发、测试集
训练集是训练神经网络的,开发机是用来比较不同超参数设置,不同的函数使用,得到的神将网络的性能的,测试集是用于评判一个神经网络的性能
上一个机器学习时代,习惯将数据集的70%作为训练集30%作为测试集,或者60%作为训练集20%开发集20%开发集,因为数据不够大
在大数据时代,我们数据集可能很大很大,而开发集和测试集不需要太多的数据,因此,开发集和测试机可能只占到2%
保证开发、测试集数据分布一致
保证开发测试集数据分布一致,能更好的提升神经网络更新效率(这个更新指的是你选择的超参数以及函数、深度等)
测试集给的是一个无偏的评价,如果你不需要也可以没有
偏差、方差

如图,上面一行是训练集的失误率,下面一行是开发集的失误率我简称为T和D
当TD二者相差很大时,被认为是有高方差的,意味着这个算法的泛化性不好
当T和D的数值很大,大于理想误差很多时,被认为是有高偏差的
方差是T和D之间的比较,偏差是T和D与理想误差的比较,理想误差指的是这个数据最小能达到的误差
过拟合,欠拟合
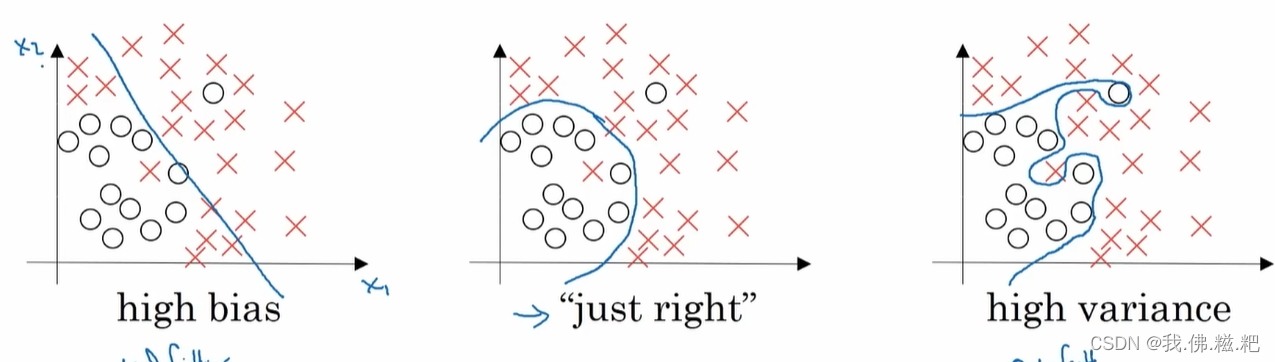
如图,左图是欠拟合,右图是过拟合,中间的图是最合适的情况
欠拟合不能很好的分类每个情况如图是一个近乎线性的
过拟合他将两个特例甚至可能是错误的数据也分开。
在一个神经系统中,可能不止存在一种情况,可能一会欠拟合,一会过拟合,解决办法在下文
正则化
L2正则化,正则化可以减少过拟合的现象
L2的操作就是对成本函数J进行操作,再通过J对w的偏导,改变dw的值,最后回到w的迭代更新上
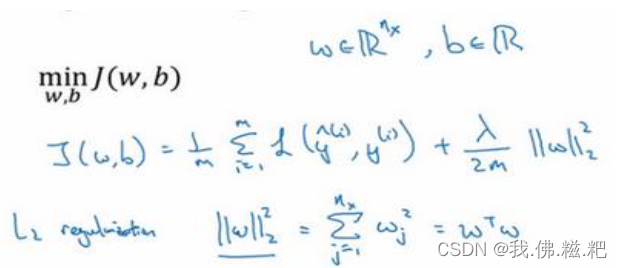
如图就是L2的正则化,lambda/2m后面的东西称为范数平方,就是里面所有的数的平方求和。
接下来是对dw里面的操作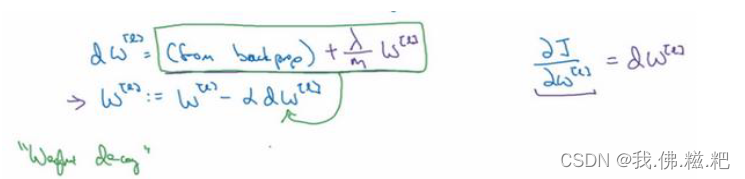
dw加上lambda/2mw ^[l],由此可见lambda也是一个需要选择的超参数和学习率一样
(注:python中lambda是关键字,因此命名时一般为lambd省去a)
为什么正则化可以减少过拟合的现象
简单理解一下正则化所做的事,就是将右图往左图靠拢,就是把这条线弄直了,或者说更靠近线性。
从公式上来看
当lambda处于一个很大的值的时候,w的值会变小,z的值也就会变小,z就会被限制在一个区间当中,如何激活函数是tanh

那么神经网络趋近于线性,整个深度神经网络就趋近于线性,类似欠拟合的现象。
也就是说,lambda的值越大,神经网络就越趋近于线性,当你选择一个合适的lambda的值就可以减少过拟合的现象。
(注:当你在你的神经网络中实现正则化,代价函数J的值理应加上L2的正则化的值,不然可能得不到随着迭代次数增加,成本递减的图像)
正则化抛弃
另一个正则化就是dropout,将一个神经网络随机删除某一层的某个节点,使得神经网络拟合更趋于线性,解决过拟合的问题
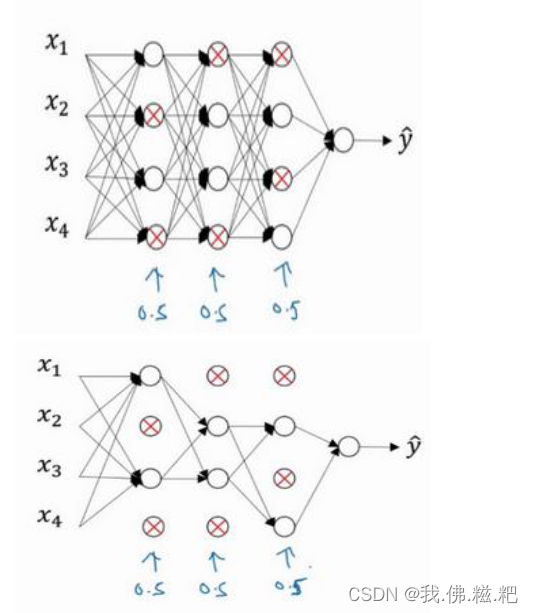
如图,某一层的每个节点都有1/2的概率被保留
用python来实现,

如图,keep-prob就是保留概率,第二行代码就是实现一个随机生成1或0的一个,跟a3维度相同的一个矩阵,通过multplx使得每一项对应相乘,就得到了删除节点后的a3

此外,不能忘记给a3每一项除以keep-prob这样以确保Z[4]的期望值不变,具体原因如下
设有m个数据被删除为0,总共有50个数据
(50-m) * a[3] * w[4] + m * 0 * w[4] = (50 * a[3] * w[4]_yuan)
(50-m) * a[3] * w[4] = (50 * a[3] * w[4]_yuan)
通过调整w[4],我们可以得到:
w[4] = (50 * a[3] * w[4]_yuan) / ((50-m) * a[3])
简化后,我们可以得到:
w[4] = w[4] *(50/(50-m))
而50/(50-m)就是keep-prob的倒数,因此给a[3]除以keep-prob能够确保z [4] 的期望值
对于测试集,我们不需要dropout,因为我们不希望得到的结果是随机的,一般在开发集中使用(只有在观察到过拟合的情况)
其次我们需要一个inverted dropout来记住上一次删除的结果
如何理解抛弃
删去个别节点可以减少神经网络对与这个节点的以来,或者说权重,线条就偏向于线性,就可以减少过拟合的现象
更多的正则化
除以上两种正则化,还有更多可以解决过拟合的方法,
第一点就是增加训练集的量,但有时候可能很难得到新的数据
有一种比较简单的方法可以创立一个伪训练集
如果你的神经网络训练一个猫的图片,你可以将他缩放,或者旋转的方式来扩展训练集,但这样的操作对于神经网络远远不如一张新的图片
另外一种方法就是 early stopping
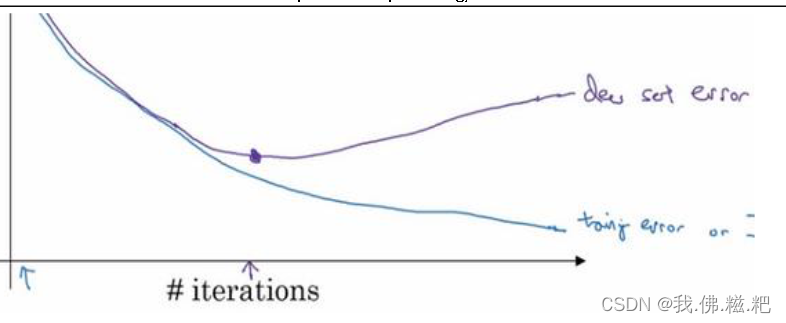
如图,你的神经网络可能在这一点显示出好的性能,就在此处停止。
坏处是,如果这样做,就相当于只关心w和b的值,而不修改代价函数J,而不关心其他的正交化的事,最后的结果就是代价函数J的值不够小,但你又不希望出现过拟合的现象,会让问题变得复杂。
不如通过调整代价函数J,就可以同时实现两个目标(J的值足够小,不出现过拟合)
归一化输入
通过归一化输入可以提升神经网络的速度,我将详细解释为什么它能够提升速度
归一化输入分为两步
1.零均值
2.归一化
首先零均值,就是给每一项都减去平均值,让均值为0,第二步归一化,就是将方差归一,让每一项除以𝜎的平方
𝜎^2 = (𝑥^(𝑖))^2的1到m的和除以m
如图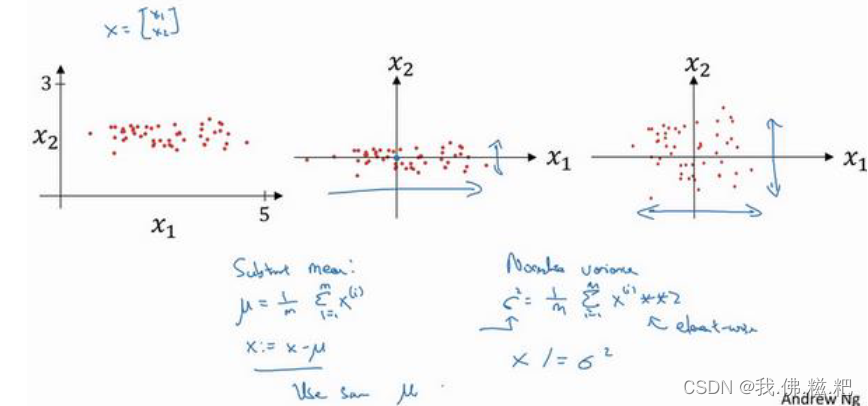
这样做能怎么样呢
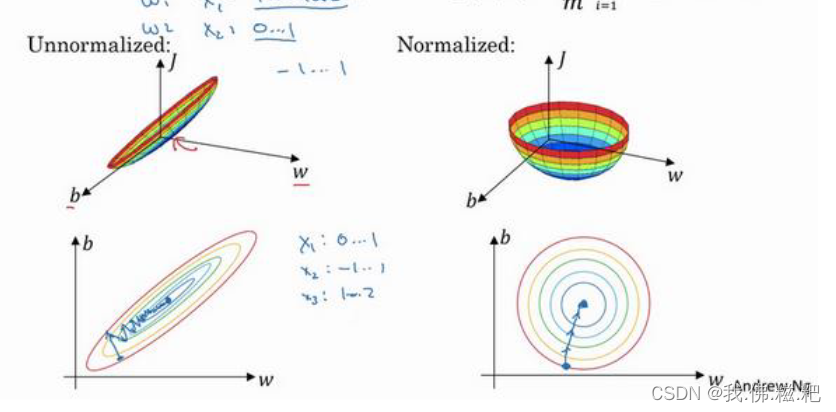
左图是未使用归一化的代价函数的图像,右图是使用了。
由此可见,使用归一化输入的情况下,无论初值在哪里,梯度下降总能往最小的方向,如果不用,w的值可能会在最小值附近波动。
为什么会展现出这样的图呢,假设特征向量有两个值,当这两个值取值范围差距很大的时候,图像就会显得扁平。归一化操作就是让图像更均匀。
梯度消失,爆炸
当你初始化权重w的时候,假设w的值比一大一点点,在深层神经网络中,每一层累加下去会导致y值非常大,w的值比一小一点点,每一层累加会特别小
这两种情况都会使得计算非常麻烦,梯度下降的步长就会非常大或者非常小,导致梯度下降的学习时间就变得更长。
深层网络权重初始化
其实就是初始化w的方法,来使得梯度不那么快的消失或者爆炸
以Relu为例,给每一项w除以根号下上一项的导数乘2,会得到更好的结果。
这些初始化方法也可以作为一种超参数
梯度检查
如何确保你的后向传播是正确的呢?
先将每一项的w和b整合成一个向量组成一个函数f,每一项的dw和db整合乘函数g
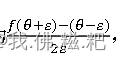
用一个for循环,只要

这两个值近似相等就可以了,怎么判定近似相等呢
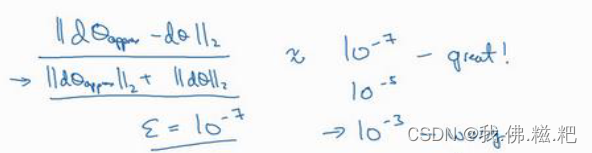
只要这个式子的值小于10的-7次方即可,上面的值就是矩阵中每一个数的平方和开根号。















 829
829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









