






这一周学习的总目的:
1.学会处理训练集
2.学习神经系统学习正向传播和反向传播的过程
1.二分类
二分类问题是对于一个问题或者一个东西的判断,只有1和0,是或否。
吴承恩课程中以判断一张图片是不是一只猫为例
计算机中,保存一张图片是保存三个矩阵里面分别是红蓝绿三个颜色通道
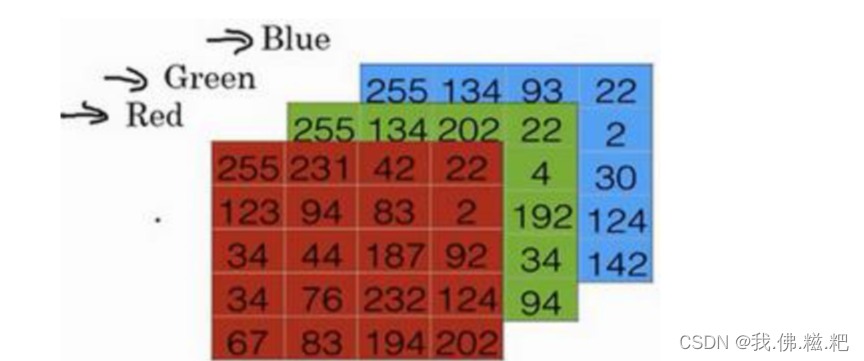
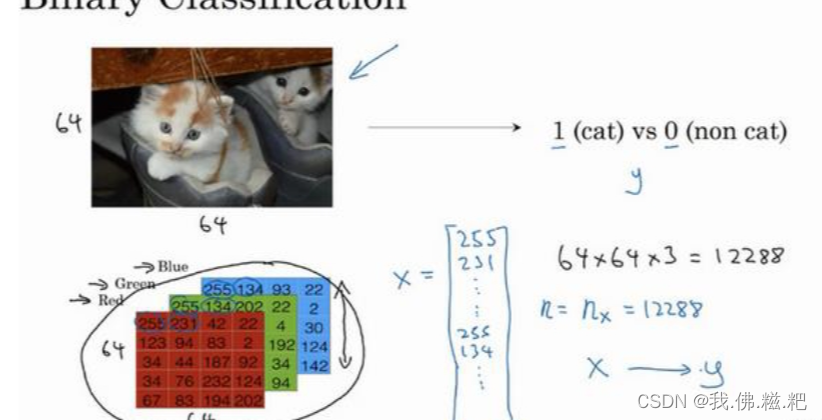
这三个矩阵表示了各个颜色的强度,将所有颜色的像素取出来,放入一个特征向量中(先红后绿最后蓝色),必入一张图片是64*64的他的维度就为64*64*3,也是他的总像素量,表示为nx = 12288
计算机是这样储存一个图片的,那就以这个特征向量作为参数,给出图片是否是猫的结果0和1,来训练神经网络,最后训练结果就是输入一个张图片的特正向量得到这张图片的0和1.
2.会用到的符号
x:输入数据,也就是特征向量,维度为(nx,1)
y:输出数据,范围(0,1)
(𝑥(𝑖), 𝑦(𝑖)):表示第𝑖组数据
𝑋 = [𝑥(1), 𝑥(2), . . . , 𝑥(𝑚)]:表示所有的训练数据集的输入值,放在一个 𝑛𝑥 × 𝑚的矩阵中,
其中𝑚表示样本数目;
𝑌 = [𝑦(1), 𝑦(2), . . . , 𝑦(𝑚)]:对应表示所有训练数据集的输出值,维度为1 × 𝑚。
训练样本的个数,会写作𝑀𝑡𝑟𝑎𝑖𝑛,当涉及
到测试集的时候,我们会使用𝑀𝑡𝑒𝑠𝑡来表示测试集的样本数,
X:X[x1,x2......xm]把输入数据放入一个(nx,m)的矩阵中

输出y就很简单[y1,y2,......ym]
y^:输出结果,代表了可能为1的概率
y,shape = (1,m)
逻辑回归
吴承恩课程中展示的是逻辑回归的一种,叫做假设函数,对于数据假设了一个一元一次函数,
y^ = 𝑤𝑇𝑥 + 𝑏
wt是一个跟x相同维度的一个矩阵,那么wt与x的乘积实际上是w1*x1+w2*x2+……+wm*xm,这里的每一个x1,x2事实上都是一个特征,或者说一个变量,因此对应的w1,w2是对应特征的权重,如你所见的这一个长串的式子,实际上是只对一组数据的拟合,对于总体,每个w1,w2等都是对总体w1,w2取平均值。千万不能误以为这里的x1,x2是多组数据的代表
wT维度与x相同,称为特征权重,我的理解是重要程度,放在图片中就是斜率
b就是偏差。
对于这个函数一定会有大于1和小与0的部分,目标y的结果应该在(0,1)之间,因此我们要以这个函数为自变量,放在另一个只在(0,1)之间的函数里面,必须得是递增的
sigmoid函数

𝜎(𝑧) = 1/1+𝑒−𝑧,放在这个函数使得结果在(0,1)区间
代价函数
当训练完成一个神经网络,如何判定一个神经网络的w和b值设置的合理,结果更准确,这个代价函数的值就作为判断标准,也就是说代价函数是对整个函数来评判
对于这个代价函数的要求是当y^的值约接近y时,他的代价函数值尽可能小,反之则越大
损失函数
损失函数跟代价函数一样,他是对于单个数据的,就是一组(xi,yi),所有数据组的损失函数的和取平均值就是代价函数的值
𝐿(𝑦^ , 𝑦) = −𝑦log(𝑦^) − (1 − 𝑦)log(1 − 𝑦^)
注:y是实际值,所以y的值只有0和1,y^是预测值,所以y^的值属于(0,1)
这就是逻辑回归中用到的损失函数,当y等于1时只看左边,log(y^)的值尽可能大,y^就尽可能大,y^就趋近于1,同样y=0时,只看右边。
梯度下降法
代价函数是判断逻辑回归中预测函数的w和b参数选择的好坏程度,那么我们就可以根据代价函数找到一个最小值,他对应的w和b值就是最优解决(只适用于只有一个最优解,有很多函数有局部最优解)
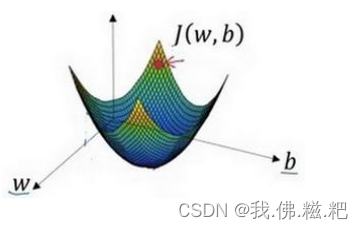
例子中的代价函数是有最优解的。那么我们要找到这个最优解最快的方法就是梯度下降法
梯度下降法实际上就像是在这个函数的坑上放一个小球,小球会往最陡的地方下降直到找到最低点。
以二维层面先看
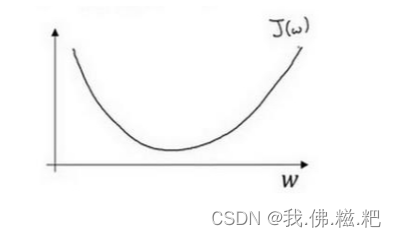
𝑤 ≔ 𝑤 − 𝑎 𝑑𝐽(𝑤)/𝑑𝑤(:=代表迭代)
小球的位置即w,a为变化率(步长,理解为一次走多少)
当小球位于右边时,dj(w)/dw,dj对于w的导数为正,w就会往左走,而且此时导数比较大,往左走的就大一点,越往左,导数越小变化越小
小球位于左边,导数为负,往右走
到三维层面,就有两个参数,就要使用偏导数,偏导数的笔记另作啦
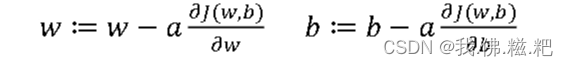
接下来的三节课为导数,还有图计算,图求导数,其实就是先介绍了导数,再讲解了复合函数求导,就不详细记笔记了
计算图
计算图就是把计算的过程用图表示出来,计算图的作用就是可以快速求导数,不论整体有多复杂,每一个节点只需要把自己这一部分的导数求出返回给上一层即可
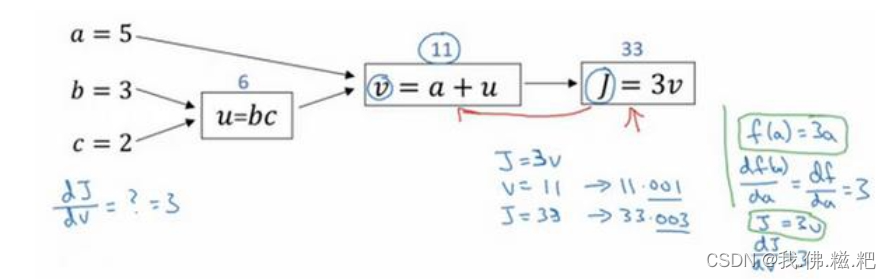
从右往左看,第一步j对v的导是3,3传入上一层v对a的导数是1,用3*1对应了j对a的导数,这就意味着简化了复合函数求导。
逻辑回归中的梯度下降
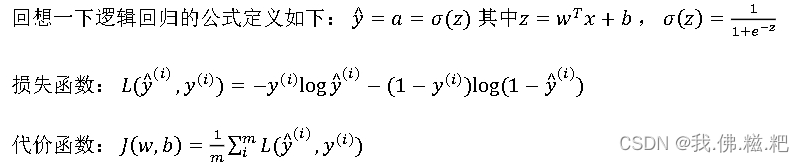
这是逻辑回归的三个公式
梯度下降中我们的目标就是找到l最小的对应的w和b,之前得出来的w和b的公式
这里的目标就是通过计算图来计算w和b的l对w的偏导数,偏导数的计算我还不会,暂时理解
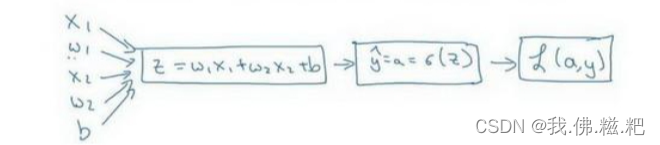
这里的x1,x2,w1,w2是指该样本数据里面只有两个特征,即x这个特征向量里面只有两个数。
z的计算公式为𝑧 = 𝑤1𝑥1 + 𝑤2𝑥2 + 𝑏
通过计算图来算每一步的导数,dl/da = −𝑦/𝑎 + (1 − 𝑦)/(1 − 𝑎)
求(da/dz) * (dl/da),计算过程很麻烦,直接给出结果dl/dz = a - y
最终对于单个样本
𝑑𝑤1 = 𝑥1 ⋅ 𝑑𝑧
𝑑𝑤2 = 𝑥2 ⋅ 𝑑𝑧
𝑑𝑏 = 𝑑𝑧
(注:dz是python用来命名,实际上的值指的是dl/dz即a-y)
这里的dw1和dw2就是这组数据最合适的w1,w2值,有多个特征时同上
以上对应一个样本,我们讨论的都是损失函数,回忆起来对一个w和b的评判是代价函数,代价函数是损失函数的和取平均值那么对于所有的样本,最合适的w1和w2值就是所有w1,w2各自和的平均值(不要忘记最后拟合的其实是一条直线(对于一个特征来说),因此取平均值)每个特征取平均值,最后多个特征组合出来的图才可能是三维或者多维的

向量化
向量化其实是对以上过程的简化,用线性代数矩阵的知识简化计算的过程。
对于每一个z的计算我们都要进行如下的式子
z = wt*x+b
那么用向量化来简化这个过程,x是一个形状为(nx,m)的矩阵,wt是一个(1,m)的矩阵,两矩阵相乘的结果刚好是一个wi*xi的矩阵形状为(1,m)而+b就是一个(1,m)的全为b的矩阵·
最终得到的矩阵,里面的每一项就是每一个数据对应的z的值
import numpy as np
z = np.dot(w.T,x)+bnp.dot()计算两个向量的叉乘,b实际上是python把他自动转化成为一个与前面维度相同全为b的一个矩阵,以此就减少了第一层的for循环,加快了计算速度
对于第二个for循环,计算dw的综合的for循环,一样可以用向量化来简化,创建的dw是一个全为0的向量,给这个向量累加上np.dot(dz,x)
z向量里面的每一个是对应了m个数据,也就是说z里面的每一个对应了第几组数据
同理,计算a就只需要将z这个矩阵传入𝜎(𝑧) = 1/1+𝑒^−z函数中即可,得到的一个(1,m)的矩阵里面每一个对应了a的值
计算dw的向量里面实际上是m个数据的每个特征向量对应的dw值的和
最后再dw/m即可
总结
z = np.dot(wt,x)+b
a = 𝜎(𝑧)
dz = a-y
dw = 1/m*np.dot(x,dz.T)
db = 1/m*np.sum(dz)
最后根据这个梯度下降,你就可以更新w和b的值
w := w-a*dw
b := b-a*db
(这里a指的是变化率)
以上是完成了一次迭代,但你仍需要一个for循环来选择迭代的次数

















 1562
1562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









