







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
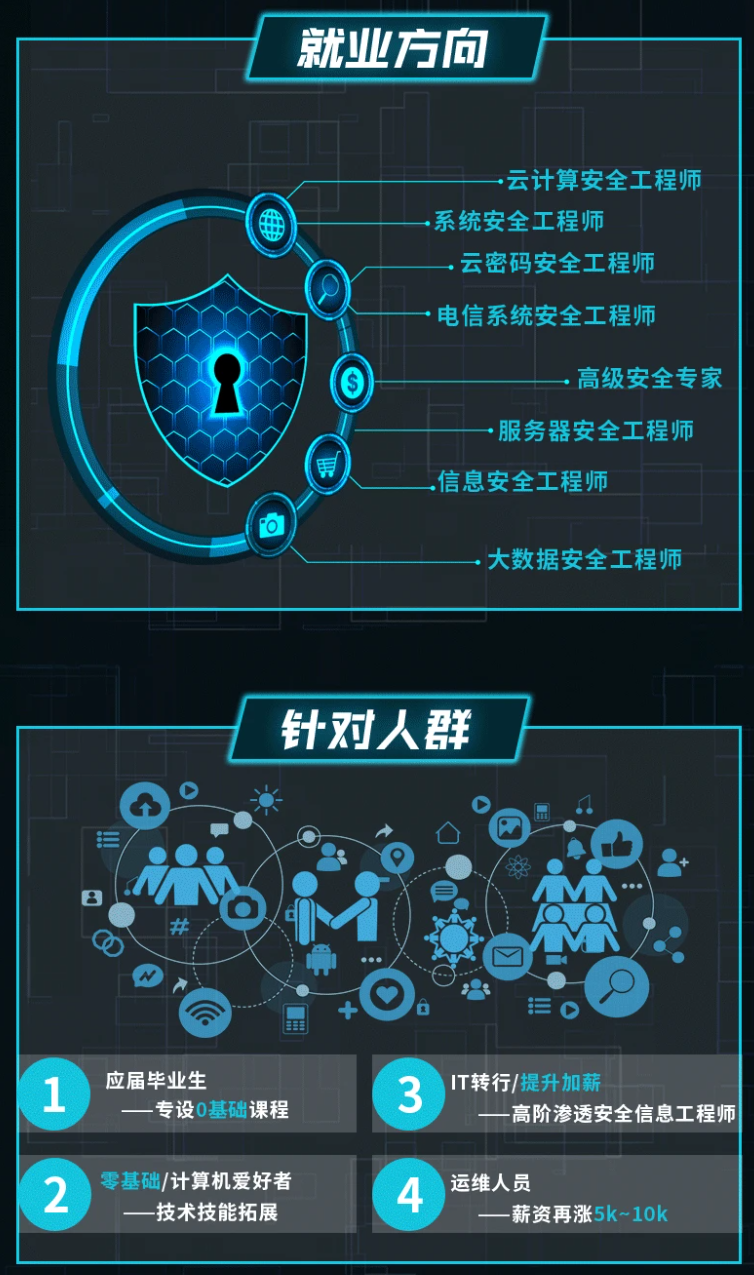

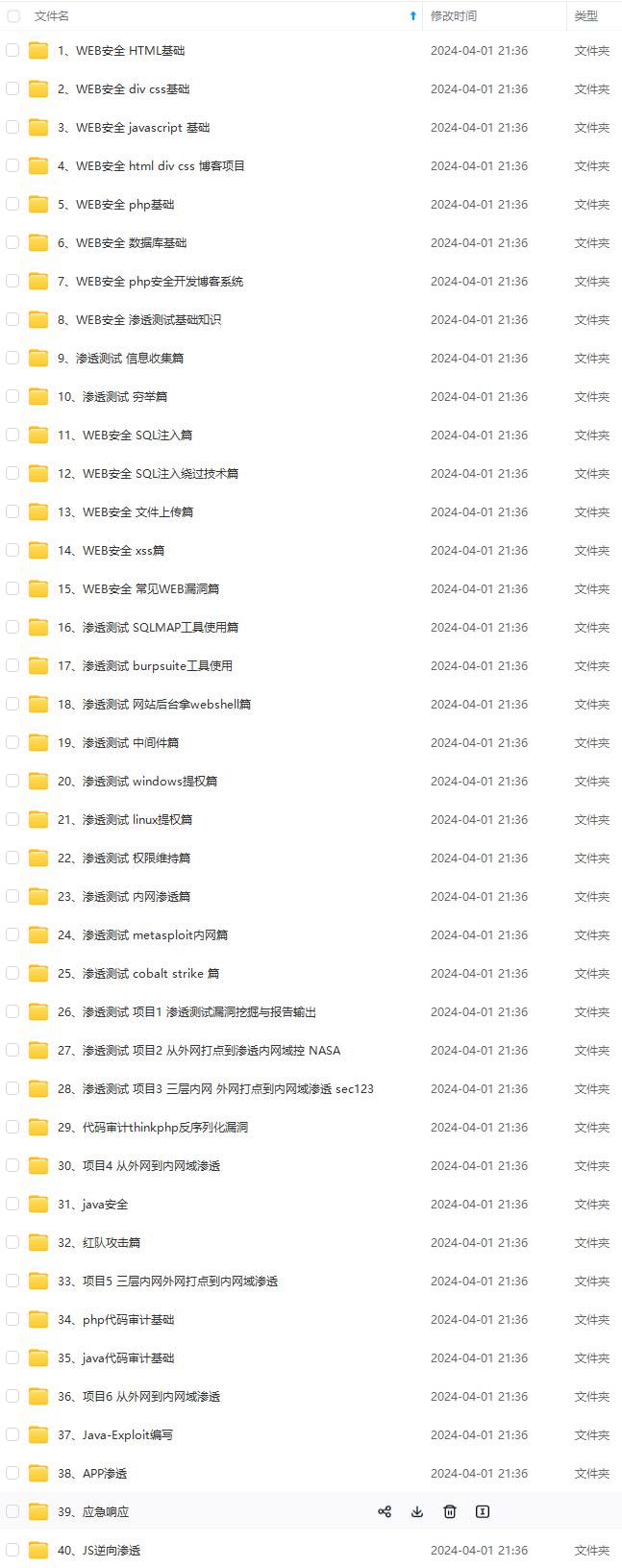
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注网络安全)

正文
* [2. meta-theme](#2_metatheme_304)
* [3. end to end](#3_end_to_end_312)
* [4. feature adversaries](#4_feature_adversaries_321)
* [5. k-Winners-Take-All](#5_kWinnersTakeAll_331)
* [6. EOT (Elastic-Weight Consolidation)](#6_EOT_ElasticWeight_Consolidation_349)
* [7. PGD](#7_PGD_353)
* [8. Generative Classifier](#8_Generative_Classifier_368)
* [9. Variational Auto-Encoder framework](#9_Variational_AutoEncoder_framework_380)
* [10. 自动编码器](#10__394)
* [11. KL-divergence test](#11_KLdivergence_test_407)
* [12. l0 adversarial examples](#12_l0_adversarial_examples_424)
* [13. Max-Mahalanobis center (MMC) loss](#13_MaxMahalanobis_center_MMC_loss_434)
* [14. BIM (Basic Iterative Method)](#14_BIM_Basic_Iterative_Method_448)
* [15. FGSM (Fast Gradient Sign Method)](#15_FGSM_Fast_Gradient_Sign_Method_470)
* [16. MIM (Momentum Iterative Fast Gradient Sign Method)](#16_MIM_Momentum_Iterative_Fast_Gradient_Sign_Method_497)
+ [阅读时间](#_537)
On Adaptive Attacks to Adversarial Example Defenses
对于对抗性样本防御的自适应性攻击
阅读
自适应性攻击虽然不可以完全自动化,但是可以有效攻破13种攻击方式。
全文针对对抗样本防御的自适应攻击的方法和策略。作者对13种防御方法进行了全面的分析,并提供了从头到尾执行自适应攻击所需的方法和步骤。文章强调了攻击的简单性,并提出了一些通用的攻击策略,如攻击整个防御系统、识别和攻击重要的防御部分等。作者的主要目标是评估每种防御的初始鲁棒性评估是否合适,并在发现不合适的情况下,展示如何构建更强大的自适应攻击。同时,作者并不希望声称许多防御技术完全没有价值,而是认为某些技术的实现可能会提高模型的鲁棒性。
答疑笔记
1. 量化
量化是一种压缩,使得模型占用空间减小,运行时间变短。
量化样本对推理时间时,鲁棒性比行进中模型高。
对抗样本的迁移性在量化样本和普通样本之间较差。
理解为 “量化” 是一种压缩数据的方式,将数据从原始形式转换为更紧凑、数字表示的形式,通常可以获得以下好处:
- 空间效率: 量化可以减小数据的存储需求,因为数字表示通常比原始数据更紧凑。这对于在存储资源受限的环境中处理大量数据非常有用。
- 传输效率: 在网络通信中,量化可以减小数据传输的带宽需求,使数据传输更加高效。这对于快速数据传输和实时通信至关重要。
- 速度加快: 量化可以使数据处理和分析更快速,因为数字数据通常更容易操作和计算。这对于需要快速响应的应用程序和系统非常重要。
- 鲁棒性增强: 数字表示通常更容易进行错误检测和修复。这意味着在传输或存储过程中出现错误时,可以更容易地识别和纠正问题,从而提高数据的鲁棒性。
对抗样本的迁移性通常是相对差的,无论是对量化样本还是对普通样本。对抗样本是通过对原始数据进行微小的、经过精心设计的扰动来欺骗机器学习模型,使其做出错误的预测。这些扰动通常是非常特定的,以欺骗特定模型,因此它们通常不具备很好的迁移性。
对抗样本的迁移性差的原因包括:
- 模型依赖性: 对抗样本的生成通常依赖于目标模型的详细信息,包括模型的架构、权重和训练数据。因此,对抗样本通常只对特定模型有效,不容易泛化到其他模型。
- 输入依赖性: 对抗样本的扰动通常是基于原始输入的微小变化生成的。因此,即使输入数据略有不同,也可能导致不同的对抗样本,这会降低迁移性。
- 模型复杂性: 随着深度学习模型的复杂性增加,它们对输入的微小变化变得更加敏感。这使得对抗样本更难迁移到其他模型。
- 不同数据分布: 如果不同的模型针对不同的数据分布进行了训练,那么对抗样本的迁移性可能会受到影响,因为对抗样本可能在训练数据分布之外无法起作用。
2. 投票法和加权投票法
模型集成的一种常见方法是使用投票法。在投票法中,每个模型对输入数据进行预测,然后最终预测结果是根据多数投票或加权投票来确定的。在加权投票法中,每个模型的预测结果都有一个权重,这些权重根据模型性能或其他因素来确定。最终结果是根据模型的投票和权重的组合。
3. Decision-based boundary attack (DBB)
“Decision-based boundary attack” (DBB) 是一种用于评估神经网络模型鲁棒性的对抗攻击方法。该方法通过在输入空间中搜索决策边界来生成对抗样本,从而使模型的输出从目标类别转换为错误的类别。与其他对抗攻击方法不同,DBB攻击不需要计算梯度,因此可以避免梯度掩盖和梯度误差等问题。相比于其他对抗攻击方法,DBB攻击具有更高的攻击成功率和更少的查询次数。
内容
1. abstract
自适应攻击已经成为评估对抗性示例防御方法的事实标准。然而,我们发现典型的自适应评估方法存在不完整之处。我们演示了最近在 ICLR、ICML 和 NeurIPS 发表的十三种不同防御策略的防御方法,尽管试图使用自适应攻击进行评估,但它们仍然可以被规避。以前的评估论文主要关注最终结果,即显示防御方法无效,而本文侧重于阐述执行自适应攻击所需的方法和途径。我们的一些攻击策略具有一定的通用性,但没有一种策略足以应对所有的防御方法。这突显了我们的主要观点,即自适应攻击无法自动化,总是需要仔细和适当地调整以适应特定的防御方法。我们希望这些分析可以为如何正确执行对抗性示例防御的自适应攻击提供指导,从而使社区能够在构建更加健壮的模型方面取得进一步的进展。
2. introduction
研究领域的人们对于,防御对抗性样本的攻击做出了很多尝试,但是这个过程十分困难。事实上,常见的防御方式只能对静态或者微小的攻击起到防御作用,而会被强大的防御躲避开。
最近社区为改进国防评估所做的努力和指导方针已经产生了显著的积极影响。特别是,针对自适应攻击(即专门针对给定防御而设计的攻击)的评估已经得到了广泛的采纳——针对自适应攻击的防御评估比例从2017年的接近零增加到2018年的三分之一,再到今天的几乎全部这就引出了一个问题:
有了他们改进的评估实践,这些防御真的具有很高的鲁棒性吗?
我们发现情况并非如此。具体来说,从最近的ICLR, ICML和NeurIPS会议中选择了13个防御来说明不同的防御策略,我们发现我们可以绕过所有这些防御,并大大降低了最初声称的准确性。
(知其然,而不知其所以然)
重要的是,虽然几乎所有这些防御都进行了涉及适应性攻击的评估,但这些评估结果并不充分。例如,文献中常见的做法是将现有的"自适应"攻击改头换面,绕过一些先前的防御,而不考虑如何将其改为针对新的防御。我们猜想,造成这一缺陷的部分原因可能是,以前关于规避防御的工作通常只显示了最终的、成功的攻击,而没有描述用于发起这种攻击的方法,从而留下了诸如"攻击是如何被发现的? "或"其他哪些攻击是不成功的? "等公开问题。
(会讲出来,如何产生相应攻击方法的猜想,以及推理过程,包括最终成型的攻击方式)
为了解决这个问题,我们不只是证明我们研究的13种防御可以被更强的攻击绕过,而是带领读者了解我们分析每种防御的完整过程,从最初的论文通读,到我们对规避防御所需条件的假设,再到最终成功的攻击。这种方法使我们能够更清楚地记录开发强适应性攻击所涉及的许多步骤。
我们分析的目标不是将分析模型的准确率一直降低到0 %。相反,我们想证明现有的自适应攻击评估方法存在不足,更强的自适应攻击会导致(至少部分)从原始评估报告中降低每个防御的准确率。
尽管之前的工作通常需要开发新技术来规避防御,但我们发现已经存在适当评估防御的技术工具。更好的攻击可以只使用文献中众所周知的工具来构建。因此,目前防务评估的问题是方法问题而不是技术问题。
在描述了我们的方法(第3节)和提供了从我们的评估中提取的共同主题的概述(第4节)之后,我们给出了每个防御的评估的总结(第5节),由于篇幅限制,在附录留了完整的评估。
(设计损失函数,评定原模型的损失量,损失越高说明攻击越强,攻击效果越好)
我们评估的一个首要主题是简单性。攻击不必复杂,即使在防御的时候也是如此。在复杂的防御中往往只有少量的重要组件,谨慎地针对这些组件可以导致更简单和更强的攻击。我们设计了我们的损失函数,这是成功的自适应攻击的基石,使它们易于优化和一致,从而更高的损失值导致严格更强的攻击。虽然我们的一些技术是通用的,但没有一个单一的攻击策略可以满足所有的防御。这突出了一个重要的事实,即自适应攻击无法自动化,并且总是需要对每个防御进行适当的调整。
本着负责任的披露精神,我们联系了我们在提交之前评估的所有抗辩的作者,并提出分享代码或对抗的例子,以使我们的索赔得到独立的验证。在除(其中辩护作者没有回应我们的原始信息)外的所有案例中,作者都承认我们的攻击是有效的。为了促进可重复性,并鼓励其他人执行独立的再评价防御,我们在https://github.com/wielandbrendel/adaptive_attacks_paper.发布了所有攻击的代码
3. background
对于一个分类神经网络f和一个带有真实标签y的自然输入x ( e.g. ,取自测试集),一个对抗样本是一个扰动的输入x′,使得:( 1 )对于某个距离函数‖·‖ (我们在威胁模型下对每种防御进行评估,并声称其具有鲁棒性;在所有情况下,对各种p≥0的p范数),‖x′- x‖很小,但(2)是它被错误地分类,或者是针对性不强(找不到精准的t,使得f ( x′) = t),使得f ( x′) != y,或者是针对性很强的,使得对于某个选定的f ( x′) = t时,有t != y。
(从交叉熵开始定义损失函数,使之在微小扰动下loss最大化)
为了生成对抗样本,构造一个损失函数L,使得当f ( x ) != y时L( x , y)较大,然后在保持扰动‖x-x′‖较小的情况下最大化L( x′, y)。定义合适的损失函数L是任何自适应攻击的关键组成部分。任何损失函数的典型起点都是交叉熵损失LCE。
虽然生成对抗性示例的方法有很多,但最广泛采用的方法是输入空间上的梯度下降。设x0 = x,然后反复设定
x(i+1 )= Proj(xi + α · normalize(∇xi L(xi, y)))
其中,Proj将输入投影到一个较小的域以保持失真较小,归一化在考虑的范数下强制一个单位长度的步长,α控制所采取的步长大小。经过N步(例如, 1000)后,我们令x′= xN为生成的对抗样本。关于常见对抗样本生成技术的进一步背景介绍见附录A。
在某些情况下,将分类器表示成f ( x ) = arg max z ( x )的形式是有用的,其中z ( x )是类得分向量,我们称之为logit层(例如,在任何softmax激活函数之前) (其中z(x)是我们称之为logit层的class-scores向量(例如,在任何softmax激活函数之前));因此,z ( x ) i是第i类关于输入x的logit值.通过稍微滥用符号,我们有时用f ( x )指代分类器的输出类(即f ( x )) = y )或类概率的全向量(即f ( x )) = [ p1 , … , pK] )。选择要从语境中明确。
我们在本文中研究的所有防御都声称是白盒鲁棒性:在这里,对手被假设拥有模型体系结构、权重和任何必要的附加信息的知识。这允许我们使用上述攻击技术。
4. Methodology
本文的核心部分记录了我们在十三种防御上开发的攻击。由于篇幅限制,我们的评估总结在第5节,全文在附录中提供。我们每个评估部分的结构如下:
- 防御是如何运作的:我们首先简要描述防御,并介绍必要的组件。我们鼓励读者在阅读我们的方法之前,在本节结束后停下来思考一下如何攻击所描述的防御。
- 我们为什么选择这种防御方式:虽然我们在本文中研究了许多防御措施,但我们不能指望评估过去几年发表的所有防御措施。我们根据两个标准选择每个辩护:(1)它已被ICLR, ICML或NeurIPS接受;表明独立审稿人认为它有趣且合理,并且(2)它清楚地说明了某些概念;如果两个防御是基于相同的想法,或者我们认为在相同的情况下会失败,我们只选择一个。
- 最初的假设和实验:我们首先阅读每篇论文,重点是寻找防御可能仍然容易受到对抗性示例攻击的潜在原因,尽管论文中最初进行了鲁棒性评估。为了开发额外的攻击假设,我们还研究了防御的源代码,这些源代码是公开的,或者应所有防御的要求。
- 最后的稳健性评估:鉴于我们对防御失败的候选假设,我们转而发展自己的适应性攻击。在大多数情况下,这包括(1)构造一个改进的损失函数,其中梯度下降可以成功地生成对抗性示例,(2)选择最小化损失函数的方法,以及(3)根据从攻击尝试中收集到的新见解重复这些步骤。
- 吸取的教训:在绕过了防御之后,我们回顾并询问我们从这次攻击中学到了什么,以及如何将其应用于未来。
每个部分的流程直接反映了我们实际采取的评估防御健壮性的步骤,而没有追溯得出我们希望如何发现缺陷的结论。我们希望这将允许我们的评估策略作为如何从头到尾执行未来评估的案例研究,而不仅仅是观察最终结果。
我们强调,我们的主要目标是评估每个防御的初始鲁棒性评估是否合适,如果我们发现不合适,就说明如何对该防御建立更强的适应性攻击。重要的是,我们不希望宣称这些防御方法中的许多所使用的鲁棒性技术没有任何价值。很可能这些技术的一些实例化可以提高模型的鲁棒性。然而,要令人信服地提出这样的主张,这个防御必须得到一个强有力的适应性评估的支持- -这是我们教程的重点。
5. Recurring Attack Themes
我们确定了6个主题(和一个元主题),它们是多个评估共有的。下面我们分别进行讨论。表1给出了与我们所研究的每个防御相关的主题的概述。
- (元主题)T0:力求简单。 我们的自适应攻击始终比每篇论文中评估的自适应攻击更简单。在所有情况下,我们的攻击都尽可能接近具有适当损失函数的直接梯度下降;只有当简单的攻击失败时,我们才会增加额外的复杂性。更容易诊断简单攻击的失败,以便迭代更强大的攻击。下面的主题主要是各种方法,使攻击更简单,但更强大。
- T1:攻击(一个功能接近)完全防御。如果一个防御是端到端可微的,那么整个防御应该被攻击。除非必要,否则应避免附加损失条款;相反,如果可能的话,应该包括任何组件,特别是预处理功能。
- T2:识别和瞄准重要的防御部分。一些防御以复杂的方式组合了许多子组件。通常,检查这些组件会发现,只需要一两个组件就足以使防御失败。只针对这些组件可以导致更简单、更强大和更容易优化的攻击。
- T3:调整目标以简化攻击。 有许多目标函数可以被优化以生成对抗性示例。选择“最佳”策略并非无关紧要,但可以极大地提高攻击成功率。例如,我们发现目标攻击(或“多目标攻击”有时比非目标攻击更容易制定。我们还表明,特征攻击[SCFF16]是规避检测对抗性示例的许多防御的有效方法。这里,我们从x以外的另一个类中选择一个自然输入x *,并生成一个与x *在某个内层的特征表示相匹配的对抗示例x '。
- T4:确保损失函数一致。 先前的工作表明,由于损失函数难以优化,许多防御评估失败。我们发现许多防御评估受到正交和更深层次问题的影响:所选择的损失函数实际上并不是攻击成功的良好代理。也就是说,即使有一个保证找到损失最优的全能优化器,攻击也可能失败。这样的损失函数是不一致的,应该避免。
- T5:用不同的方法优化损失函数。 给定一个尽可能简单的有用损失函数,应该选择合适的攻击算法以及正确的超参数(例如,足够多的迭代或重复)。特别是,基于白盒梯度的攻击并不总是优化损失函数的最合适算法。在某些情况下,我们发现应用基于分数的“黑盒”攻击或基于决策的攻击可以优化难以区分的损失函数。
- **T6:在对抗性训练中使用强适应性攻击。**许多论文声称,将他们的防御与对抗性训练相结合比单独使用任何一种技术都能产生更强的防御。然而,我们发现许多这样的组合防御导致比单独的对抗训练更低的鲁棒性。这揭示了弱自适应攻击的另一种失败模式:如果用于训练的攻击无法可靠地找到对抗性示例,则模型将无法抵抗更强的攻击。
6. Our Adaptive Evaluations
我们评估并规避了13种防御。在这一节中,我们简要地描述了每种防御是如何运作的,以及我们需要做些什么来规避它。防卫的排序具有任意性。由于篇幅限制,对每一道防线的完整评价见附录。
(1)k-Winners Take All
防御方式:用不连续的k- winner - take - all函数替换标准的ReLU激活来有意掩盖梯度。
攻击:使用EOT,寻找连续光滑可导的近似函数。
这种防御通过用不连续的k- winner - take - all (k- wta)函数替换标准的ReLU激活来有意掩盖梯度,该函数将层中除k个最大激活外的所有激活设置为零。因此,即使输入的微小变化也会极大地改变网络中的激活模式,并导致预测的大幅跳跃。由于模型不是局部光滑的,很难找到标准的基于梯度攻击的对抗例子。
每当防御会导致模型预测中出现这样的半随机的不连续跳变时,我们的第一个假设是,我们需要找到模型的决策面的光滑近似,使得梯度下降能够成功。尽管这种防御是确定性的,但我们采用了一种类似于EOT技术 (见附录A)的策略,该技术常用于平滑随机防御中的变异。我们从输入的20,000个小扰动中通过有限差分估计平滑梯度,并运行PGD 100步。这使得在k - WTA激活下对抗训练的CIFAR - 10模型的准确率从50.0 %降低到0.16 %。因此,与对抗训练基线相比,添加k - WTA激活实际上降低了鲁棒性。
(2)The Odds are Odd
防御方式:基于分类器的logit值的分布来检测对抗性示例,即加入噪声不影响原来分类。
攻击:结合EOT,多次计算求平均值来针对防御的随机性。采用“特征对手”。
这种防御基于分类器的logit值的分布来检测对抗性示例。在输入x上,防御方将logit向量z(x)与“噪声”logit向量z(x + δ)进行比较,其中δ ~ N在测试时从某个分布N(例如多项高斯分布)中采样。假设对于干净的例子,z(x)≈z(x + δ),而对于对抗的例子,两个logit向量将显著不同。第5.13节中的辩护也有类似的理由。
作者评估了结合EOT的标准攻击,以平均防御的随机性。然而,通过设计,与干净的输入相比,许多攻击找到的对抗性示例要么对噪声不鲁棒,要么对噪声过于鲁棒。为了创建与干净输入具有相似噪声鲁棒性的对抗性示例,我们使用“特征对手”:我们从x以外的另一个类中选择一个干净输入x *,并最小化||z(x ') - z(x *)||2^2,以匹配干净输入的logits。此攻击将CIFAR-10的防御精度降低到17% (ε = 8/255)。进一步包括EOT将精度降低到0%。
(3)Are Generative Classifier More Robust?
这种防御是基于变分自编码器框架。它相当复杂,并且显示了许多使评估具有挑战性的特征,例如使用多个模型、多个损失的聚合、随机性和额外的检测步骤。
防御首先通过一组随机编码器-解码器模型运行输入。然后计算每个类的四个损失项,并将这些损失项组合起来形成每个类的似然得分。最后,根据KL -散度测试,防御拒绝具有"异常"类分数的输入。
作者评估了对所有防御组件进行优化的攻击,即使在大扰动下也找不到对抗性的例子。通过检查模型的四个损失项,我们发现只有一个项对类分数有很强的影响。只优化这种损失就能产生更简单的攻击,并且成功率更高。为了避免检测步骤,我们使用“特征对手”,并创建敌对示例,其类别得分与其他类别的干净示例相匹配。此攻击将CIFAR-10的防御精度降低到1% ( ε = 8/255)。
(4)Robust Sparse Fourier Transform 稳健的稀疏傅里叶变换
这种防御通过“压缩”每个图像并投影到离散余弦变换的前k个系数来防止 0对抗性示例。本文没有分析其对自适应攻击的鲁棒性。因此,我们发现以一种直接可微的方式实现防御,然后在这个组合函数上生成’ 0个对抗示例是成功的。我们的攻击在被防御的分类器上生成对抗性示例,其中值失真为14.8像素,与报道的未防御模型的15像素相当。
(5)Rethinking Softmax Cross Entropy
防御模型:使用新的损失函数MMC & l2。
攻击:不同于以往的直接使用交叉熵作为损失函数,我们直接优化f(x)和目标向量 μy之间的l2损失。
这种防御在训练期间使用了一个新的损失函数,以增加对抗鲁棒性。作者提出了Max-Mahalanobis中心(MMC)损失和l2损失,其中每个类标签都有一个目标向量μy,并且分类(大致)由arg miny(f (x)−μy)2给出。
一般来说,每当防御改变用于训练模型的损失函数时,我们的初始假设是新模型具有不太适合具有标准softmax交叉熵损失的攻击的损失面。我们发现这就是这里的情况。我们不是间接优化softmax交叉熵损失,而是直接优化f (x)与目标向量μy之间的l2损失。这种攻击在CIFAR-10上失真 ε = 0.031时将分类器精度降低到0.5%以下。
(6)Error Correcting Codes
防御方式:采用非常多的分类器,进行“投票”,票数最多的分类则被输出。这是一种典型的梯度掩码防御。
攻击:先去除让梯度信号变脆弱的部分(说明攻击的成功不是因为这些部分异常),之后运行多目标攻击。
这一防御提出了一种训练具有足够多样性的模型集合的方法,冗余可以作为纠错码,从而实现鲁棒分类。与集成中的每个模型具有相同的输出标签分布不同,所有模型都是基于类的随机划分的二元分类器。集合的输出是集合的多数投票。
本文不包含适应性评价。这在强声明中显示:在ε = 0.5的l∞失真下,本文报告了近40 %的精度- -梯度掩盖的一个明显符号。为了攻击该防御,我们首先去除一些使梯度信号变脆弱的不分(例如,连续的sigmoid函数和log操作)。通过运行多目标攻击,在ε = 0.031时,我们将集成精度降低到5 %,而在该失真下,报告的精度为57 %。
(7)Ensemble Diversity 一系列的多元化
防御模型:利用正则项,使模型有多样性。
攻击:增加步数和重复次数,可将准确率降到很低。
这种防御训练了一个具有正则化项的模型集合,该正则化项鼓励模型预测之间的多样性。不同模型的集成被认为比单一模型或较少多样化的集成更健壮。其基本原理类似于第5.6节中的防御。
由于防御依赖于似乎不会引起梯度掩盖的训练目标的变化,因此似乎不需要对标准的梯度下降攻击进行自适应的改变。作者评估了PGD 、BIM和MIM 等广泛的攻击,但这些攻击都非常相似。此外,攻击只运行了10步,步长为ε/ 10,因此很可能无法收敛。我们发现,将PGD的步长乘以3将准确率从48 %降低到26 %。将步数增加到250步,精度进一步降低到10 %。在每个样本上重复攻击三次,准确率降低到7 %。最后,对剩下的样本使用20步5次的B & B攻击(这在这篇辩护文发表时是没有的),将准确率降低到0 (在CIFAR - 10上,ε = 0.01)。
(8)EMPIR
防御模型:构建模型集合,权重和激活值的精度是混合的。三个模型,采用投票方式进行分类。
攻击:对整个模型集合进行梯度下降,信息在模型中正确传播…100次PGD迭代可降低准确率。
这个防御是我们研究的第三个构建模型集合来防御对抗性示例的防御方法,但这次使用了混合精度的权重和激活。本文训练了三个模型{fi},每个模型在权重和激活上具有不同精度水平,并返回输出作为模型的多数投票。
本文没有明确分析其对自适应攻击的鲁棒性,但对集成进行了标准的基于梯度的攻击分析。在研究作者的代码时,我们发现他们的攻击确实包含了一个BPDA-style的梯度估计。我们最初的假设是,对整个模型集合执行梯度下降,并确保梯度信息在模型中正确传播,就足以绕过这种防御。
由于多数投票可能在数值上不稳定,我们取三个模型fi(x), f2(x), f3(x)的概率向量,并对它们进行分量平均,以获得一个模型f,其对i类的预测由f(x)给出ˆ f (x)i= (f1(x)i+ f2 (x)i+ f3(x)i)/ 3。然后,我们在f的交叉熵损失上运行PGD。通过100次PGD迭代,我们在ε = 0.031时将防御的准确率降低到1.5%(原始评估报告的准确率为13.5%,在ε= 0.1时进行40次PGD迭代)。
(9)Temporal Dependency 时序依赖
防御模型:语音识别。检测样本的前半部分的分类与整段文本的前半部分的分类相近。
攻击:① 最小化前缀输入f(x pre)和全输入f(x)的转录损失(成功率低); ② 改变前缀函数的计算方式。
这个防御检测语音识别的对抗样本。它检查一个音频样本的前半部分的分类是否与整个音频样本的前半部分的分类相似。也就是说,如果xpre是序列x的前缀,那么这个防御检查f ( x ) pre≈f ( xpre )。
本文进行了广泛的适应性评估,尝试了三种不同的攻击技术。其中一种攻击类似于我们自己的一个成功攻击的初始假设:选择一个目标序列t,并最小化前缀输入f ( xpre )和全输入f ( x )上的转录损失,其中前缀输入上的损失是在f ( xpre )的分类和目标序列t的前缀之间计算的。然而,我们确信,在原始评估中存在一些错误,因为对于无界攻击,攻击的成功率很低:即使没有对对抗失真进行约束,攻击在欺骗检测器时也没有100 %成功。
我们发现了一些细节,当它们结合在一起时,以很小的失真将攻击成功率显著提高到100 %。我们做的最重要的改变是在前缀函数的计算方式上。具体地,优化损失函数L ( x′) = L ( f ( x′),t ) + L ( f ( x′pre ),tpre ),其中t pre为真实预测t的前l个字符,l = len ( f ( x′pre ) )。重要的是,这不仅仅是f ( x′)的前l个字符:这个值在任何时间点都可能不是正确的输出。
在基线分类器上,我们要求中位数l∞失真为41 (在65536的16位整数范围内)。对于该防御的分类器,我们要求失真为46,略有增加,但不显著高于基线防御(例如,比特量化)。
(10)Mixup Inference
防御模型:推理时的随机插值过程来减轻对抗扰动的影响。
攻击:采用一种自适应性攻击,结合PGD和EOT来对抗防御的随机性;每个PGD步骤中,多次计算求随机差值样本梯度的平均值作为整个防御梯度的近似值。
这种防御通过推理时的随机插值过程来减轻对抗扰动的影响。在输入x上,防御计算K个线性插值^xk = λx + ( 1-λ ) sk和其他随机样本sk,并平均模型对所有K个插值的预测。
作者最初的评估确实考虑了一种适应性攻击,然而,它的性能并不优于其他非适应性攻击。考虑的自适应攻击将多个非自适应攻击产生的对抗样本进行平均,因此不直接考虑防御方的特殊推理过程。我们提出了一种自适应攻击,将PGD与EOT过程相结合,以考虑防御的随机性:在每个PGD步骤中,我们通过平均从多个随机插值样本中获得的梯度来估计整个防御的梯度。我们的攻击使得最强防御模型(它与对抗训练相结合)在CIFAR - 10上的准确率从57 %下降到43.9 %,接近基线模型的鲁棒性( 42.5 % )。
(11)Mixup Inference
防御模型:预处理图像时,随机丢弃像素,再矩阵估计(BPDA的方法)像素补全重建图像,降低图片对微小变化的敏感度。
攻击:采用EOT+BPDA (但是发现,即使没有预处理,攻击效果也不会进一步++,说明有一定的鲁棒性)。
这种防御方法使用随机丢弃图像中像素的预处理步骤,然后使用矩阵估计来重建图像。防御在这些预处理的输入上训练模型,目的是学习对小输入变化不太敏感的表示。
作者的评估使用BPDA通过矩阵估计步骤来近似梯度。我们表明,攻击也可以通过使用EOT来加强,以解释丢弃像素的随机选择。同时使用BPDA和EOT将CIFAR-10的防御精度降低到15% (ε= 8/255)。但是即使我们完全去除预处理步骤,攻击也不能进一步改进,从而表明学习的模型确实具有一定的鲁棒性。
作者还将他们的防御与对抗训练相结合。我们发现该模型的鲁棒性不如单独使用对抗训练的模型- -这可能是因为原始的BPDA攻击(没有EOT )在训练时也没有在模型上找到强对抗样本。
(12)Asymmetrical Adversarial Training 不对称对抗训练
防御模型:集成分类器,先输出一个分类,然后检测是否高于阈值,防止其他扰动对输入造成影响。
攻击:构造多目标攻击。最大化一个错误分类的可能,欺骗检测器。
这种防御方法使用对抗训练的模型来检测对抗样本。在"集成分类器"模式下,防御方首先使用一个基分类器f输出一个预测f ( x ) = y。然后,输入x被送到该类别的检测器,hy,如果hy ( x )低于某个阈值,则拒绝。对每个检测器hi进行对抗训练,以拒绝来自除i以外的类的扰动输入。
防御非常简单,因此不太可能遭受梯度掩盖。作者提出了一种自然自适应攻击,旨在联合欺骗基分类器f和所有检测器hi。问题是,这种攻击"过度优化",试图欺骗所有检测器,而不是只欺骗预测类的检测器。我们证明,构造"多目标"攻击非常简单且更有效:对于每个目标类t != y,我们联合最大化f ( x ) t (以得到一个错误的分类为t)和ht ( x ) (为了欺骗t类检测器)。然后,我们为每个输入选择最佳的目标类。
我们在CIFAR - 10 ( = 8 / 255 )上将防御的准确率从30 %降低到11 %。作者还提出了一种简单组合鲁棒检测器和输出y = arg maxi hi ( x )的防御方法。我们将这种防御的准确率从55 %降低到37 %,略低于(标准)对抗训练。
(13)Turning a Weakness into a Strength 化弱为强
防御模型:有两个检测,一个是噪声不干扰输入的分类;另一个是输入的最近对抗样本距离某个阈值较远。
攻击:生成一个高置信度的对抗样本x′,然后在x′和输入x之间执行二分搜索。
这个防御通过两个测试来检测一个输入是对抗的:①用噪声干扰输入不会导致分类的改变;②输入的最近对抗样本距离某个阈值较远。这种抗辩在概念上与第5.2节中的抗辩非常相似。
虽然防御在概念上是简单的,但原始的评估方法是复杂的,构建编码攻击者目标的单一统一损失函数是具有挑战性的。特别地,作者开发了一个具有两个不可微分量的四维加权损失,因此本文应用BPDA 。我们认为,BPDA并不是一种在遭遇不可微损失时应该作为首次尝试的方法,而是一种不得已而为之的方法。
防御依赖于这样的假设:没有输入( a )对随机噪声有很高的置信度,但( b )在进行对抗攻击时仍然接近决策边界。我们显式地构造具有这两种性质的输入,首先生成一个高置信度的对抗样本x′,然后在x′和输入x之间执行二分搜索。该攻击在CIFAR - 10和ImageNet上以0 %的检测率将防御的准确率降低到< 1 %,与原文中相同的威胁模型。
7. conclusion
与之前的研究工作相比,我们看到防御评估有了明显的改进:而在过去,论文根本不会使用强适应性攻击进行评估,我们研究的几乎所有防御评估都执行旨在逃避提议防御的自适应攻击。然而,我们发现,尽管存在自适应攻击评估,我们分析的所有13个防御都可以通过改进的攻击绕过。
我们已经描述了许多攻击策略,这些策略被证明可以有效地绕过不同的防御。然而,我们敦促社区不要使用这些自适应攻击作为模板,以便在未来的评估中复制。为了说明原因,我们提出以下非正式的“无免费午餐定理”:
对于任何提出的攻击,都有可能构建一个非健壮的防御来阻止该攻击。
这样的防御一般不具有趣味性。因此,我们鼓励将针对先前攻击的鲁棒性评估(包括对先前防御的适应性攻击)仅作为有用的健康检查。鲁棒性评估的主要重点应放在开发全面的自适应攻击,明确地揭露并瞄准防御最薄弱的环节(只有在适当的情况下,利用已有的技术)。特别地,我们鼓励作者将评估的重点放在自适应攻击(并将基于非适应性攻击的评估延迟到附录中)上。然而,重要的是要包括一个非适应性的评估,以证明简单的方法是不够的。我们希望本文能对此类自适应攻击的实施和评估起到一定的指导作用。
至关重要的是,自适应攻击是针对特定的防御而手工设计的。任何一个自动化的工具都不可能全面地评估一个防御的健壮性,无论多么复杂。例如,自动化攻击中的最新技术" AutoAttack " [ ? ]评估了我们所做的四种相同的防御。在两种情况下,当我们完全攻破这些防御时,AutoAttack只能部分成功地攻击所提出的防御。此外,现有的自动化工具,如AutoAttack,不能直接应用于我们研究的许多防御,如检测对抗样本的防御。
从我们的分析中也许最重要的教训是,自适应攻击应该尽可能简单,同时解决任何潜在的优化困难。在直接梯度下降的基础上添加的每个新分量是另一个可能产生误差的地方。总的来说,过去几年在防御评估方面的进展是令人鼓舞的,我们希望更强的自适应攻击评估将为更稳健的模型铺平道路。
8. broader impact
研究机器学习安全的研究,特别是那些主要目的是制定攻击防御建议的论文,必须小心做得比伤害更多。我们相信,在我们的论文中也会出现这种情况。经过数十年的争论,计算机安全界在很大程度上已将"负责任披露"作为披露漏洞的最优方法:在发现漏洞后,负责任披露要求首先通知受影响的各方,并在合理的时间后将披露公之于众,以便整个社会都能从中学习。
研究机器学习安全的研究,特别是那些主要目的是制定攻击防御建议的论文,必须小心做得比伤害更多。我们相信,在我们的论文中也会出现这种情况。经过数十年的争论,计算机安全界在很大程度上已将"负责任披露"作为披露漏洞的最优方法:在发现漏洞后,负责任披露要求首先通知受影响的各方,并在合理的时间后将披露公之于众,以便整个社会都能从中学习。
然而,我们构建攻击的方法仍然有可能被用来攻破一些已经部署的或将要部署的其他系统。这是不可避免的,然而我们坚信,我们的论文可以为设计新防御的研究人员提供的帮助明显大于它可能提供的实际恶意行为者的帮助。我们的论文致力于帮助研究人员进行更深入的评估,并诊断评估中的故障- -而不是攻击真实的系统或用户。
概念
1. adaptive attack
“Adaptive attack” 是一个广泛用于描述计算机安全领域的术语,它指的是攻击者根据其目标系统的反应和防御措施,灵活地调整攻击策略和技术的能力。这种攻击方式是为了增加攻击成功的机会和减少被检测的风险。Adaptive attacks 的特点包括:
- 动态性:攻击者会不断地调整其策略和技术,以适应目标系统的变化或对抗措施的加强。这种灵活性使得攻击者可以更好地规避检测和防御。
- 目标定制:攻击者可能会对不同的目标系统采用不同的攻击方法,根据目标系统的弱点和防御措施的不同来调整攻击策略。
- 持续性:Adaptive attacks 可能是长期进行的,攻击者会持续监控目标系统的状态,以便随时调整攻击策略,以确保攻击的成功。
- 多样性:攻击者可能使用多种不同的攻击技术,包括恶意软件、社交工程、网络渗透等,以适应不同的情况和目标。
为了应对adaptive attacks,安全专业人员需要不断升级防御和检测机制,以及实施安全最佳实践,以最大程度地减少系统受到攻击的风险。此外,安全教育和培训也对帮助员工警惕潜在的攻击尤为重要,以减少社交工程攻击的成功率。
2. meta-theme
“Meta-theme” 是一个术语,通常用于描述或指代一个更高级别的主题、概念或范畴,它可以包含一系列相关的次级主题。它表示对主题的更广泛或更抽象的理解,通常用于分析或讨论研究领域中的核心思想、趋势或问题。
举例来说,如果在一篇关于环境问题的研究中,讨论了气候变化、生物多样性丧失、资源管理和可持续发展等多个次级主题,那么"环境问题"可以被视为这些次级主题的"meta-theme"。这意味着"环境问题"是一个更大范围的主题,涵盖了这些具体的次级主题,而这些次级主题则是构成了这一更大主题的一部分。
“Meta-theme” 有助于组织和理解各种相关主题之间的关系,帮助研究者或作者更全面地探讨某个领域或主题的多个方面。这个概念常用于学术研究、文学分析和讨论复杂主题的文档或讨论中。
3. end to end
“End-to-end” 是一个概念,它描述了一个系统或流程的设计和实现方式,其中数据或信息从起始点传递到最终点,经过的步骤和中间处理尽可能少或不存在。这个概念的目标是简化系统,减少中间环节,提高效率和直观性。下面是更详细的解释:
- 直接传递:在 “end-to-end” 的系统或流程中,数据或信息在整个过程中直接传递,从一个端点到另一个端点,中间没有复杂的中间步骤或中断。这意味着数据不需要在不同的阶段进行转换或处理,而是以原始形式连续传递。
- 最小中间处理: “end-to-end” 的方法旨在最小化中间处理或转换的数量。中间处理是指对数据进行某种形式的修改、转换或计算,通常需要额外的资源和时间。 “End-to-end” 试图减少或消除这些中间处理步骤,使整个流程更加简单和高效。
- 系统的连续性: “end-to-end” 通常关注整个系统的连续性,确保数据或信息可以在系统中无缝流动,而不会在不同阶段中断或需要额外的干预。
- 适用性: “end-to-end” 方法在某些情况下可能不适用,特别是在需要特定中间处理步骤的情况下。然而,当一个系统或流程可以被设计为 “end-to-end” 时,它通常会带来许多优势,包括更低的复杂性、更高的效率和更容易理解和维护的特点。
4. feature adversaries
“Feature adversaries” 是一个术语,通常用于机器学习和深度学习领域,特别是与对抗性示例攻击相关的研究。它指的是攻击者针对模型中的特征或特征提取器进行攻击的情况。特征在这里指的是用于描述数据的属性或特性,这些特征可以被用于训练机器学习模型。
在对抗性示例攻击中,攻击者试图修改输入数据,以使机器学习模型做出错误的预测。在 “feature adversaries” 中,攻击者专注于修改数据的特征,而不仅仅是数据本身。这种攻击方式的目标是欺骗模型,通过修改数据的特征来误导模型,使其做出不正确的决策。
“Feature adversaries” 的重要性在于,它们可以用来检测机器学习模型中的弱点,特别是对于那些对特征非常敏感的模型。攻击者可以尝试找到模型对特征的脆弱性,然后利用这些脆弱性来制造对抗性示例,从而绕过模型的防御。
总之,“feature adversaries” 是一种攻击方式,它专注于修改数据的特征,以干扰机器学习模型的预测,从而暴露模型的脆弱性,有助于改进对抗性示例的防御策略。
5. k-Winners-Take-All
学习路线:
这个方向初期比较容易入门一些,掌握一些基本技术,拿起各种现成的工具就可以开黑了。不过,要想从脚本小子变成黑客大神,这个方向越往后,需要学习和掌握的东西就会越来越多以下是网络渗透需要学习的内容:
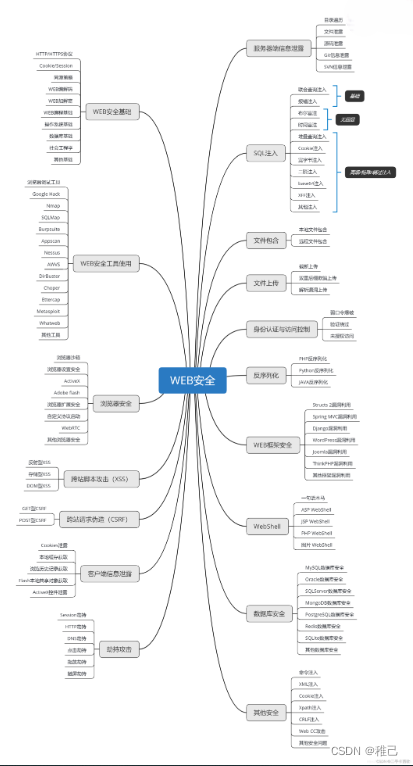
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
露模型的脆弱性,有助于改进对抗性示例的防御策略。
5. k-Winners-Take-All
学习路线:
这个方向初期比较容易入门一些,掌握一些基本技术,拿起各种现成的工具就可以开黑了。不过,要想从脚本小子变成黑客大神,这个方向越往后,需要学习和掌握的东西就会越来越多以下是网络渗透需要学习的内容:
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注网络安全)
[外链图片转存中…(img-MBuXwflB-1713387779574)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









