







文末有福利领取哦~
👉一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
👉二、Python必备开发工具

👉三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉 四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末领读者福利)

👉五、Python练习题
检查学习结果。

👉六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉因篇幅有限,仅展示部分资料,这份完整版的Python全套学习资料已经上传
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
p
1
p_1
p1>=
p
2
p_2
p2,即
p
1
p_1
p1-
p
2
p_2
p2>=0;
- 备择假设
H
1
H_1
H1:
p
1
p_1
p1<
p
2
p_2
p2,即
p
1
p_1
p1-
p
2
p_2
p2<0。
3.2 确定检验方向
由备择假设可以看出,检验方向为单项检验(左)。
3.3 选定统计方法
由于样本较大,故采用Z检验。此时检验统计量的公式如下:
z
=
p
1
−
p
2
(
1
n
1
1
n
2
)
×
p
c
×
(
1
−
p
c
)
z= \frac{p_1-p_2}{\sqrt{( \frac{1}{n_1}+\frac{1}{n_2})\times p_c \times (1-p_c)}}
z=(n11+n21)×pc×(1−pc)
p1−p2其中
p
c
p_c
pc为总和点击率。
3.3.1 方法一:公式计算
# 用户数
n1 = len(data[data.dmp_id == 1]) # 对照组
n2 = len(data[data.dmp_id == 3]) # 策略二
# 点击数
c1 = len(data[data.dmp_id ==1][data.label == 1])
c2 = len(data[data.dmp_id ==3][data.label == 1])
# 计算点击率
p1 = c1 / n1
p2 = c2 / n2
# 总和点击率(点击率的联合估计)
pc = (c1 + c2) / (n1 + n2)
print("总和点击率pc:", pc)
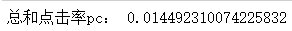
# 计算检验统计量z
z = (p1 - p2) / np.sqrt(pc \* (1 - pc)\*(1/n1 + 1/n2))
print("检验统计量z:", z)
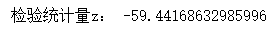
这里我去
α
\alpha
α为0.05,此时我们利用python提供的scipy模块,查询
α
=
0.5
\alpha=0.5
α=0.5时对应的z分位数。
from scipy.stats import norm
z_alpha = norm.ppf(0.05)
# 若为双侧,则norm.ppf(0.05/2)
z_alpha
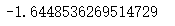
z
α
=
−
1.64
z_\alpha = -1.64
zα=−1.64, 检验统计量z = -59.44,该检验为左侧单尾检验,拒绝域为{z<
z
α
z_\alpha
zα},z=-59.44落在拒绝域。
所以我们可以得出结论:在显著性水平为0.05时,拒绝原假设,策略二点击率的提升在统计上是显著的。
假设检验并不能真正的衡量差异的大小,它只能判断差异是否比随机造成的更大。因此,我们在报告假设检验结果的同时,应给出效应的大小。对比平均值时,衡量效应大小的常见标准之一是Cohen’d,中文一般翻译作科恩d值:
d
=
样
本
1
平
均
值
−
样
本
2
平
均
值
标
准
差
d=\frac{样本_1平均值-样本_2平均值}{标准差}
d=标准差样本1平均值−样本2平均值
这里的标准差,由于是双独立样本的,需要用合并标准差(pooled standard deviations)代替。也就是以合并标准差为单位,计算两个样本平均值之间相差多少。双独立样本的合并标准差可以如下计算:
s
=
(
(
n
1
−
1
)
×
s
1
2
(
n
2
−
1
)
×
s
2
2
)
n
1
n
2
−
2
s=\frac{((n_1-1)\times s^2_1+(n_2-1)\times s^2_2)}{n_1+n_2-2}
s=n1+n2−2((n1−1)×s12+(n2−1)×s22)
其中s是合并标准差,n1和n2是第一个样本和第二个样本的大小,s1和s2是第一个和第二个样本的标准差。减法是对自由度数量的调整。
# 合并标准差
std1 = data[data.dmp_id ==1].label.std()
std2 = data[data.dmp_id ==3].label.std()
s = np.sqrt(((n1 - 1)\* std1\*\*2 + (n2 - 1)\* std2\*\*2 ) / (n1 + n2 - 2))
# 效应量Cohen's d
d = (p1 - p2) / s
print('Cohen\'s d为:', d)
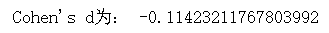
一般上Cohen’s d取值0.2-0.5为小效应,0.5-0.8中等效应,0.8以上为大效应。
3.3.2 方法二:Python函数计算
import statsmodels.stats.proportion as sp
# alternative='smaller'代表左尾
z_score, p = sp.proportions_ztest([c1, c2], [n1,n2], alternative = "smaller")
print("检验统计量z:",z_score,",p值:", p)

用p值判断与用检验统计量z判断是等效的,这里p值为0,同样也拒绝零假设。
至此,我们可以给出报告:
- 对照组的点击率为:0.0126,标准差为:0.11
- 策略二的点击率为:0.0262,标准差为:0.16
- 独立样本z=-59.44,p=0,单尾检验(左),拒绝零假设。
- 效应量Cohen’s d= -0.11,较小。
根据前面案例,我们用的是两个比率的z检验函数proportion.proportions_ztest,输入的是两组各自的总数和点击率;如果是一般性的z检验,可以用weightstats.ztest函数,直接输入两组的具体数值,可参考https://www.statsmodels.org/stable/generated/statsmodels.stats.weightstats.ztest.html
import statsmodels.stats.weightstats as sw
z_score1, p_value1 = sw.ztest(data[data.dmp_id ==1].label, data[data.dmp_id ==3].label, alternative='smaller')
print('检验统计量z:', z_score1, ',p值:', p_value1)
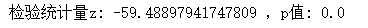
可以看到计算结果很接近,但是有点差异。因为非比率的z检验是不计算联合估计的。
作为补充,我们再检验下策略一的点击率提升是否显著。
z_score, p = sp.proportions_ztest([c1, len(data[data.dmp_id ==2][data.label == 1])],[n1, len(data[data.dmp_id ==2])], alternative = "smaller")
print('检验统计量Z:',z_score,',p值:',p)
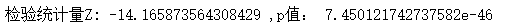
p值约为 7.450121742737582e-46,p<α,但是因为前面我们设置了对点击率提升的最小要求(1%),这里仍然只选择第二组策略进行推广。
3.3.3 方法三:蒙特卡洛法模拟
蒙特卡洛法其实就是模拟法,用计算机模拟多次抽样,获得分布。
在零假设成立(p1>=p2)的前提下, p1=p2 为临界情况(即零假设中最接近备择假设的情况)。如果连相等的情况都能拒绝,那么零假设的剩下部分( p1>p2)就更能够拒绝了。
定义effect_tb.csv中样本的总点击率为 p_all:
p_all = data.label.mean()
print('p\_all:', p_all)
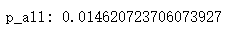
我们进行一次模拟,以 p_all 为对照组和策略二共同的点击率,即取p_old=p_new=p_all,分别进行n_old次和n_new次二点分布的抽样,使模拟的样本大小同effect_tb.csv中的样本大小相同:
choice1 = np.random.choice(2, size=n1, p=[1-p_all, p_all])
choice2 = np.random.choice(2, size=n2, p=[1-p_all, p_all])
diff = choice1.mean() - choice2.mean()
print('对照组结果:', choice1, ',策略二结果:', choice2, ',模拟的转化率差值:', diff)
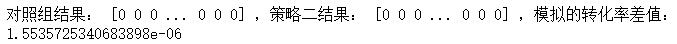
因为是随机抽样,所以每次模拟的点击率差值也是不同的,多运行几次就会发现,我们模拟出的结果很难比effect_tb.csv中样本的点击率差值更小,这说明了什么?
# 计算effect\_tb.csv样本的点击率差值
data_diff = data[data["dmp\_id"] == 1]["label"].mean()-data[data["dmp\_id"] == 3]["label"].mean()
print('effect\_tb.csv样本的点击率差值:', data_diff)
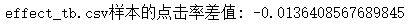
按照如上方式进行多次模拟,这里我们进行10000次,并计算出每个样本得到的策略点击率差值,将其存储在diffs中:
diffs=[]
for i in range(10000):
p2_diff = np.random.choice(2,size=n2,p=[1-p_all,p_all]).mean()
p1_diff = np.random.choice(2,size=n1,p=[1-p_all,p_all]).mean()
diffs.append(p1_diff - p2_diff)
实际上每次模拟都得到了一个大小为316205的样本,此处得到了10000个样本。在图上将模拟得到的diffs绘制为直方图,将effect_tb.csv中样本的点击率差值绘制为竖线:
diffs = np.array(diffs)
plt.hist(diffs)
plt.axvline(data_diff)
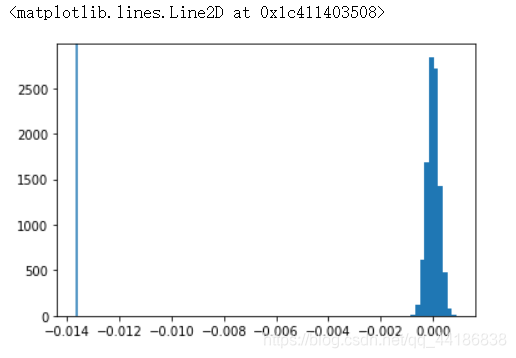
在diffs列表的数值中,有多大比例小于effect_tb.csv中观察到的点击率率差值?
(diffs < data_diff).mean()
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









