






Crystal
=======
https://crystal-lang.org/

Crystal已经面试很多年了,Crystal的特点是兼具C语言的高效和Ruby的静态类型。今年初已经发布了1.0版本,目前最新版本为1.2.1,已经足够稳定。
Microsoft Terminal
==================
https://github.com/Microsoft/Terminal
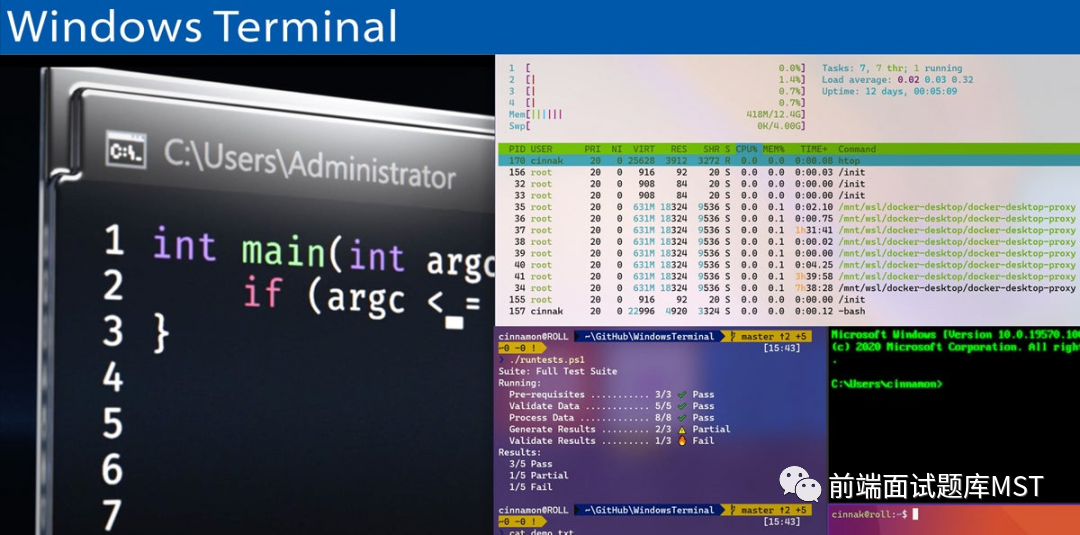
Microsoft Terminal 是一个开源的Windows的终端,提供类似Mac和Linux命令行的体验。Microsoft Terminal具有GPU加速渲染,较传统控制台具有更好的性能提升。
OBS Studio
==========
https://obsproject.com/
OBS Studio 是一款用于直播和屏幕录制的软件,为高效捕获,合成,编码,记录和流传输视频内容而设计,支持所有流媒体平台。快捷键可让试图平滑切换,甚至还有画中画和实时字幕的新功能。
Shotcut
=======
https://shotcut.org/
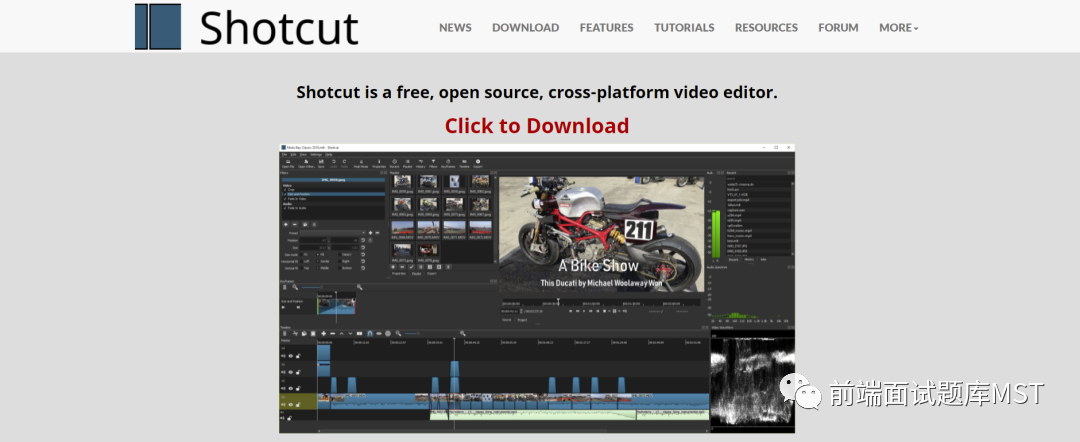
Shotcut是一个强大的视频编辑工具。Shotcut具有中文版支持,可在Windows,MacOS,Linux,BSD等操作系统上运行,Shotcut具有数百种音频、视频格式,以及编解码器,且无需导入,可直接编辑。
Weave GitOps
============
https://github.com/weaveworks/weave-gitops
Weave GitOps 是一个GitOps工具。其目的是简化DevOps的工作流程,通过声明配置使Kubernetes更加稳定和安全。Weave GitOps 基于 云原生基金会的 Flux。
Apache Solr
===========
https://solr.apache.org/
Apache Solr 是基于 Lucene 的全文搜索服务器,也是最流行的企业级搜索引擎。Solr 放弃了开源的许可证,不过现在仍然是免费的。Solr 可集群部署、可在云端部署,甚至包括 LTR 算法,可自动调整加权结果。
MLflow
======
https://mlflow.org/

MLflow 是由 Apache Spark 技术团队开源的一个机器学习平台。MLflow 由 Databricks 创建,并由 Linux 基金会托管,是一个 MLOps 平台,可让用户跟踪、管理和维护各种机器学习模型、实验及其部署。MLflow提供了记录和查询实验(代码、数据、配置、结果)的工具,将数据科学代码打包成项目,并将这些项目接入工作流程。
Orange
======
https://orangedatamining.com/
Orange 是一款用于开源机器学习和数据可视化的工具。Orange与 R Studio 和 Jupyter等程序化或文本工具相比,Orange 更直观易操作。Orange 包含了完整的一系列的组件以进行数据预处理,并提供了数据帐目,过渡,建模,模式评估和勘探的功能。
Flutter
=======
https://flutter.dev/
Flutter是谷歌推出的一个新用于构建跨平台的手机、网页、桌面,嵌入式设备应用的SDK。Flutter 的组件,比如,滚动条、导航、图标和字体,整合了IOS和安卓平台的差异。
Apache Superset
===============
https://github.com/apache/superset
Apache Superset是一个现代的、轻量级可视化BI分析工具。Apache Superset在可视化、易用性和交互性上非常有特色,用户可以轻松对数据进行可视化分析。而且Apache Superset 已经达到企业级商业软件的水平。
Presto
======
https://prestodb.io/

Presto 是一个开源的分布式 SQL 引擎,用于集群中的在线分析处理。Presto 可以查询各种各样的数据源,从文件到数据库,并将结果输出到BI和分析环境。更重要的是,Presto 可以在 Hive、Cassandra、关系型数据库中进行查询,而且Presto 还可以结合多个来源的数据查询。
脸书、Uber、推特和阿里巴巴创立了 Presto 基金会。其他成员现在包括 Alluxio、Ahana、Upsolver 和英特尔。
Apache Arrow
============
https://arrow.apache.org/

Apache Arrow 是一个列式内存分析层,旨在为CPU和GPU上加速大数据的分析。它包含了一套平面和分层数据的典型内存表示,Arrow 内存格式支持零拷贝读取,并且不必序列化的情况下访问数据极快。目前Apache Arrow支持的语言包括 C、C++、C#、Go、Java、JavaScript、Julia、MATLAB、Python、R、Ruby 和 Rust。
InterpretML
===========
https://interpret.ml/
InterpretML是微软推出的可解释机器学习包。其中包含了几个最先进的机器学习可解释性技术。InterpretML提供了两类解释性类型:明箱(glassbox) 模型和黑箱(blackbox)模型。InterpretML 可让实践者通过在一个统一的 API 下,借助内置的可扩展可视化平台,使用多种方法来轻松地比较可解释性算法。InterpretML 也包含了可解释 Boosting 机(EBM)的首个实现,这是一种强大的可解释明箱模型,可以做到与许多黑箱模型同等准确。
Lime
====
https://github.com/marcotcr/lime
Lime(Local interpretable model-agnostic explanations 局部可解释模型-不可知解释的缩写),Lime用于表格或图片的解释机器学习的分类器。Lime 能够解释两个或更多类的黑盒分类器。分类器实现了一个函数,该函数接收原始文本或 numpy 数组并输出每个类的概率。
Dask
====
https://dask.org/

Dask 是一个用于并行计算的开源库,可将 Python 包扩展到多台机器上。Dask 可将数据和计算分布在多个 GPU 上,即可在单一系统也可在多节点集群中运行。Dask 可与 Rapids cuDF、XGBoost 和 Rapids cuML 集成,用于 GPU 加速的数据分析和机器学习。Dask还可与 NumPy、Pandas 和 Scikit-learn 集成进行并行化工作。
BlazingSQL
==========
https://blazingsql.com/
BlazingSQL 是一个基于 Rapids 生态系统构建的 GPU 加速 SQL 引擎。BlazingSQL基于 Apache 2.0 许可证开源。BlazingSQL是cuDF的SQL接口,具有支持大规模数据科学工作流(包括提取,转换,加载)和企业数据集的各种功能。
Rapids
======
https://rapids.ai/
Nvidia 的 Rapids是由英伟达开源的一款开源机器学习GPU加速平台。Rapids 使用英伟达 CUDA 基元进行底层计算优化,通过Python 将 GPU 的并行和高带宽内存以接口方式向外开放。Rapids 依赖于 Apache Arrow 柱状内存格式,包括cuDF(类似 Pandas 的 DataFrame 库);cuML(机器学习库集合,提供 Scikit-learn 中大多数算法的 GPU 版本);以及cuGraph(类似 NetworkX 的加速图分析库)。
PostHog
=======
https://posthog.com/
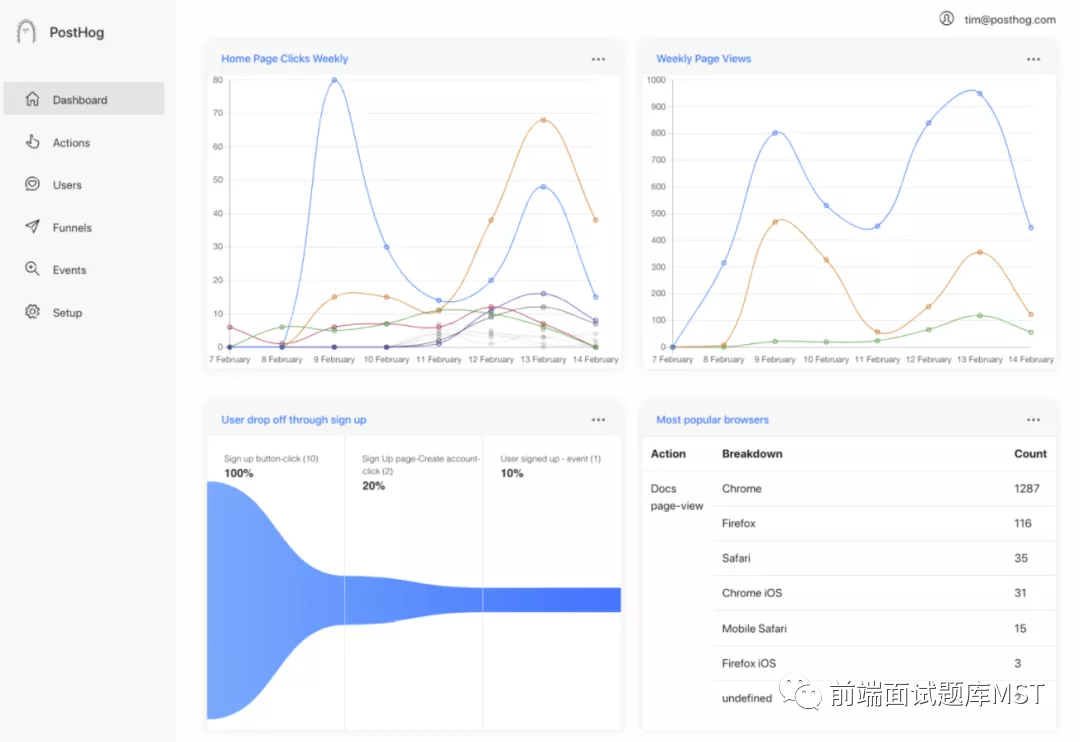
PostHog 是一个为开发者构建的开源产品分析平台。自动收集网站或应用程序上的每个事件,无需向第三方发送数据。PostHog 提供基于用户事件的分析,捕获网站的使用数据,统计各用户在网站中的具体操作。PostHog会自动捕获点击次数和综合浏览量,以分析网站用户在做什么,而无需手动推送事件。
LakeFS
======
https://lakefs.io/
LakeFS 提供了一种"像管理代码一样管理数据湖"的方式,独特引入类似Git功能来管理数据的版本。LakeFS 可以帮助用户创建独立、零拷贝(Zero-copy)的数据分支,且在运行、测试和建模分析中,又不存在破坏共享对象的风险。与Git类似,LakeFS 的数据中会带有提交记录、元数据字段和回滚等信息,此外还有hooks,即在分支合并到主分支前,hooks会检查数据,确保完整性和质量。Amazon S3 和 Azure Blob已在使用 LakeFS。
Meltano
=======
https://meltano.com/

Meltano始于2018年GitLab的内部项目,服务于 GitLab 数据管理。2021年从GitLab独立出来成为一个初创公司。
Meltano是一款免费 DataOps 时代的ETL工具,旨在替代替代传统 ELT的工具,ELT是指数据提取、加载、转换操作的统称。
Meltano特点是开源、自托管、CLI(命令行)、可调试和可扩展。
Meltano创建管道即代码的概念,Meltano项目可进行版本控制、代码审查、持续集成和部署 (CI/CD )以及容器化等。
Trino
=====
https://trino.io/
总结
前端资料汇总
-
框架原理真的深入某一部分具体的代码和实现方式时,要多注意到细节,不要只能写出一个框架。
-
算法方面很薄弱的,最好多刷一刷,不然影响你的工资和成功率😯
-
在投递简历之前,最好通过各种渠道找到公司内部的人,先提前了解业务,也可以帮助后期优秀 offer 的决策。
-
要勇于说不,对于某些 offer 待遇不满意、业务不喜欢,应该相信自己,不要因为当下没有更好的 offer 而投降,一份工作短则一年长则 N 年,为了幸福生活要慎重选择!!!
喜欢这篇文章文章的小伙伴们点赞+转发支持,你们的支持是我最大的动力!

















 104
104

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









