






Text2SQL 代理弥补了自然语言处理 (NLP) 和结构化查询语言 (SQL) 之间的差距。其主要优势如下:
前排提示,文末有大模型AGI-CSDN独家资料包哦!
-
帮助非技术用户使用 SQL : 并非所有用户都具有 SQL 背景或了解查询所涉及的表的结构。使用 Text2SQL 代理,用户可以用自然语言提出问题或请求数据,而无需深入了解数据库结构或 SQL 语法。
-
提高 SQL 开发效率 : 对于熟悉 SQL 的用户,Text2SQL 代理简化了流程,使用户能够快速构建复杂查询,而无需手动编写每个部分的代码。
-
最大限度地减少错误 : 手动编写 SQL 查询很容易出错,尤其是对于复杂的查询或不熟悉数据库结构的用户。Text2SQL 代理可以解释自然语言指令并生成准确的 SQL 查询,从而减少潜在的语法和逻辑错误。
-
提升数据分析能力 : 在商业智能和数据分析中,快速从数据中获取见解至关重要。Text2SQL 代理有助于更直接、更方便地从数据库中提取有价值的信息,从而有助于加快决策。
-
自动化和集成 : Text2SQL 代理可以集成到更大的系统中,以支持自动化工作流程,例如自动生成报告和数据监控。它还可以与其他服务和技术无缝集成,提供更丰富的应用可能性。
-
支持多种语言和多种表达方式 : 人们可以用多种方式表达同一个想法。一个有效的 Text2SQL 系统应该能够理解各种表达方式并准确地将其转换为 SQL 查询。
总之,Text2SQL 代理致力于使数据库查询更加直观和用户友好,同时确保效率和准确性。它迎合了广泛的用户群体,从完全不懂技术的个人到经验丰富的数据分析师和开发人员。
然而,传统的 Text2SQL 解决方案通常需要模型微调,当在企业环境中与 RAG 或 Agent 组件一起实施时,这会大大增加部署和维护成本。RAGFlow 基于 RAG 的 Text2SQL 利用现有的(连接的)大型语言模型 (LLM),允许与其他 RAG/Agent 组件无缝集成,而无需额外的微调模型。
基于RAG提供的Text2SQL的工作流程:
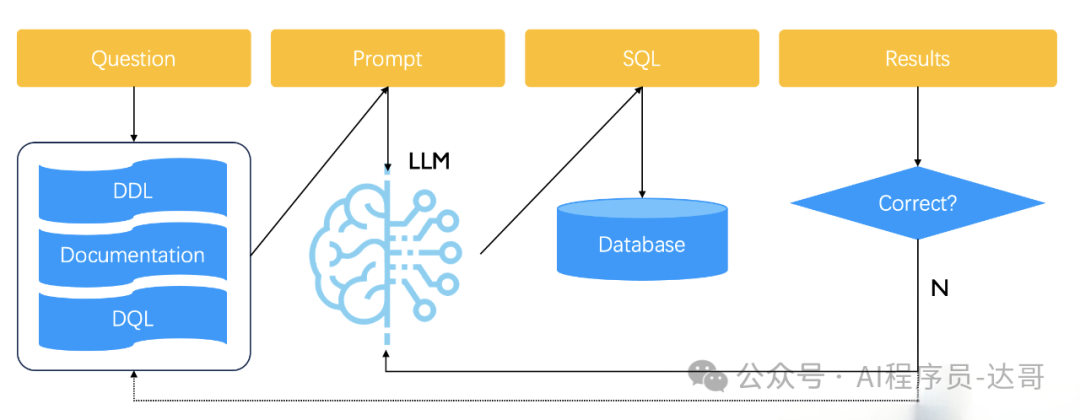
数据准备
数据库环境
Mysql-8.0.39
数据库表创建
SET NAMES utf8mb4;`
`-- ----------------------------``-- Table structure for Customers``-- ----------------------------```DROP TABLE IF EXISTS `Customers`;````CREATE TABLE `Customers` (`` `` `CustomerID` int NOT NULL AUTO_INCREMENT, `` `` `UserName` varchar(50) COLLATE utf8mb4_unicode_ci DEFAULT NULL, `` `` `Email` varchar(100) COLLATE utf8mb4_unicode_ci DEFAULT NULL, `` `` `PhoneNumber` varchar(20) COLLATE utf8mb4_unicode_ci DEFAULT NULL, `` ``PRIMARY KEY (`CustomerID`)```) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;`
`-- ----------------------------``-- Table structure for Products``-- ----------------------------```DROP TABLE IF EXISTS `Products`;````CREATE TABLE `Products` (`` `` `ProductID` int NOT NULL AUTO_INCREMENT, `` `` `ProductName` varchar(100) COLLATE utf8mb4_unicode_ci DEFAULT NULL, `` `` `Description` text COLLATE utf8mb4_unicode_ci, `` `` `Price` decimal(10,2) DEFAULT NULL, `` `` `StockQuantity` int DEFAULT NULL, `` ``PRIMARY KEY (`ProductID`)```) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;`
`-- ----------------------------``-- Table structure for Orders``-- ----------------------------```DROP TABLE IF EXISTS `Orders`;````CREATE TABLE `Orders` (`` `` `OrderID` int NOT NULL AUTO_INCREMENT, `` `` `CustomerID` int DEFAULT NULL, `` `` `OrderDate` date DEFAULT NULL, `` `` `TotalPrice` decimal(10,2) DEFAULT NULL, `` ``PRIMARY KEY (`OrderID`),`` ``KEY `CustomerID` (`CustomerID`)```) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;`
`-- ----------------------------``-- Table structure for OrderDetails``-- ----------------------------```DROP TABLE IF EXISTS `OrderDetails`;````CREATE TABLE `OrderDetails` (`` `` `OrderDetailID` int NOT NULL AUTO_INCREMENT, `` `` `OrderID` int DEFAULT NULL, `` `` `ProductID` int DEFAULT NULL, `` `` `UnitPrice` decimal(10,2) DEFAULT NULL, `` `` `Quantity` int DEFAULT NULL, `` `` `TotalPrice` decimal(10,2) DEFAULT NULL, `` ``PRIMARY KEY (`OrderDetailID`),`` ``KEY `OrderID` (`OrderID`),`` ``KEY `ProductID` (`ProductID`)```) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
配置知识库
对于 RAGFlow 基于 RAG 的 Text2SQL,通常需要以下知识库:
-
DDL : 数据库表创建语句。
-
DB_Description : 表和列的详细描述。
-
Q->SQL : 自然语言查询描述以及相应的 SQL 查询示例(问答对)。
然而,在专门的查询场景中,用户查询可能包括领域特定术语的缩写或同义词。如果用户引用领域特定术语的同义词,系统可能无法生成正确的 SQL 查询。因此,建议整合同义词词库,以帮助代理生成更准确的 SQL 查询。
-
TextSQL_Thesaurus : 涵盖特定领域术语及其同义词的同义词库。
配置DDL知识库
-
1.DDL文本内容如下:
`CREATE TABLE `vendor` (`` `` `id` varchar(66) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `` `` `name` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL , `` `` `status` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT 'Normal', `` `` `sync_mode` varchar(64) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL , `` `` `description` varchar(500) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL , `` `` `created_time` datetime(0) NULL DEFAULT NULL , `` ``PRIMARY KEY (`id`) USING BTREE```) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;```CREATE TABLE `vendor_task` (`` `` `id` varchar(66) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `` `` `vendor_id` varchar(66) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL , `` `` `status` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL , `` `` `type` varchar(32) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL , `` `` `error_msg` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL , `` `` `remark` varchar(500) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL , `` `` `content` text CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL , `` `` `retry_num` tinyint(4) NULL DEFAULT 0 , `` `` `next_retry_date` datetime(0) NULL DEFAULT NULL , `` `` `created_time` datetime(0) NULL DEFAULT NULL COMMENT '创建时间', `` ``PRIMARY KEY (`id`) USING BTREE,```) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
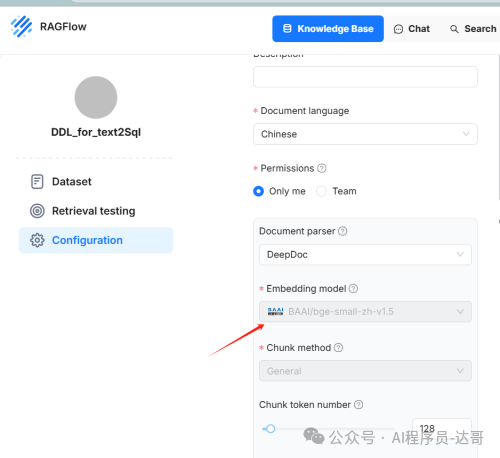
2.设置 DLL 知识库的块数据, 嵌入模型选择自带的模型,分块方式选择General就可以了。选择好后点击保存。
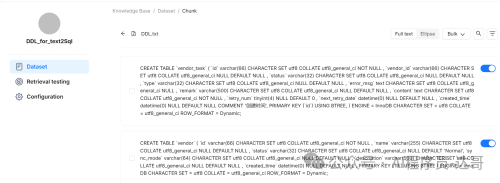
然后上传DDL.txt文件进行解析。
配置DB_Description知识库
1.DB_Description文本内容如下:
### vendor(厂商表)``vendor表记录了厂商的详细信息。以下是该表中每个字段的含义:` `id:厂商唯一标识符。` `name:厂商名称。` `status:厂商状态。其中Normal代表正常;Disabled代表禁用。` `sync_mode:同步模式。其中SystemAuto代表系统自动模式;Human代表人工无确认模式;HumanConfirm代表人工确认模式。` `created_time:创建时间。` `### vendor_task(厂商任务表)``vendor_task表记录厂商任务的详细信息。以下是该表中每个字段的含义:` `id:厂商任务唯一标识符。` `vendor_id:外键,引用vendor表中的id,指示哪个厂商的任务。` `status:任务状态。其中NO_SYNC代表不同步;DEFAULT 待同步;PROCESSING 处理中;SUCCESS 成功;FAILED 失败;CANCELLED 取消;UNCONFIRMED 待确认;CONFIRMED 已确认。` `type:任务类型。其中OpenCard 开卡;LossCard 挂失;UnLossCard 解除挂失;ReturnCard 退卡;ReplaceCard 换卡。` `error_msg:错误信息。` `reamrk:备注。` `content:任务内容。` `retry_num:任务重试次数。` `next_retry_date:任务下次重试时间。` `created_time:创建时间。
2.设置 DB_Description 知识库的块数据

配置Q->SQL知识库QA.xlsx
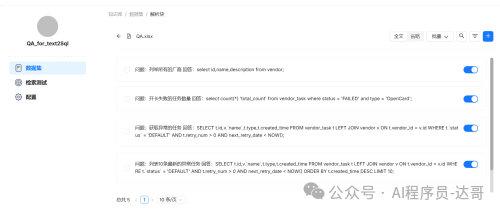
这是我配置的参考SQL,列举了一些任务失败、异常任务和正常重试任务的例子。
问题:列举所有的厂商 回答:select id,name,description from vendor;``问题:开卡失败的任务数量 回答:select count(*) 'total_count' from vendor_task where status = 'FAILED' and type = 'OpenCard';```问题:获取异常的任务 回答:SELECT t.id,v.`name`,t.type,t.created_time FROM vendor_task t LEFT JOIN vendor v ON t.vendor_id = v.id WHERE t.`status` = 'DEFAULT' AND t.retry_num > 0 AND next_retry_date < NOW();````问题:列表10条最新的异常任务 回答:SELECT t.id,v.`name`,t.type,t.created_time FROM vendor_task t LEFT JOIN vendor v ON t.vendor_id = v.id WHERE t.`status` = 'DEFAULT' AND t.retry_num > 0 AND next_retry_date < NOW() ORDER BY t.created_time DESC LIMIT 10;````问题:获取正在重试的任务 回答:SELECT t.id,v.`name`,t.type,t.created_time FROM vendor_task t LEFT JOIN vendor v ON t.vendor_id = v.id WHERE t.`status` = 'DEFAULT' AND t.retry_num > 0 AND next_retry_date >= NOW() ORDER BY t.created_time DESC;`
最终要整理成Excel,格式如下:
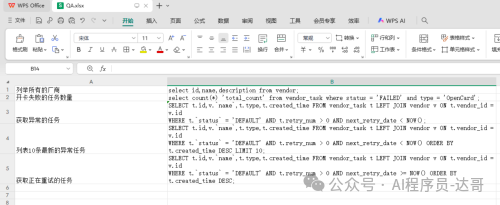
这里要注意,因为我们要上传的是Excel,所以解析方式要选择Q&A。
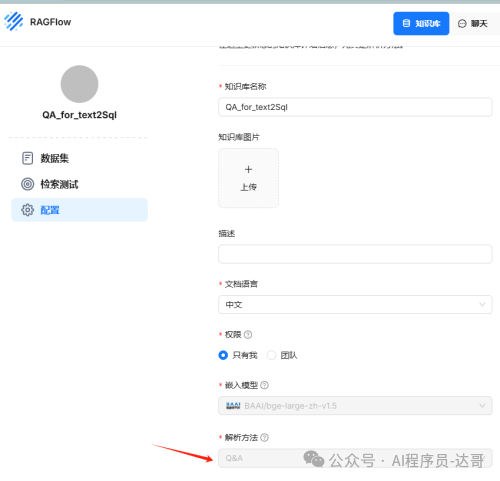
上传QA.xlsx
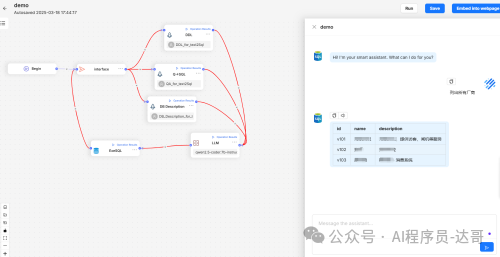
构建TextToSQl的Agent
路径:Agent -> Create agent -> Text To SQL
新建后系统默认生成一个模板。我们只需要添加一个ExeSQL插件即可。如图所示:
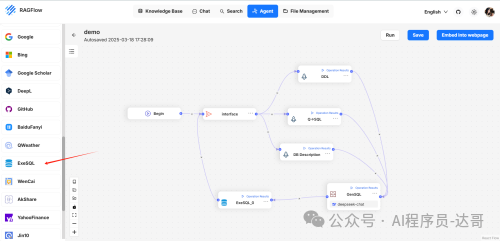
然后分别对DDL、Q->SQL、DB_Description、GenSQL和ExeSQL进行配置。
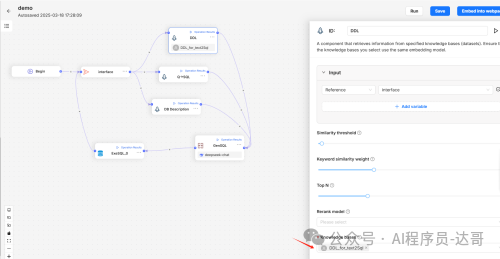
a.DDL
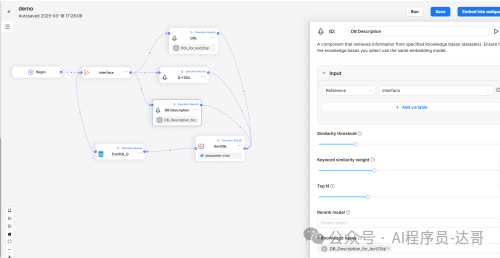
单击DDL,Input选择Interface,知识库选择之前新建的DDL知识库。
b.DB Description
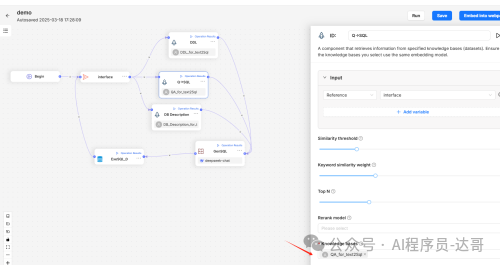
c.Q->SQL
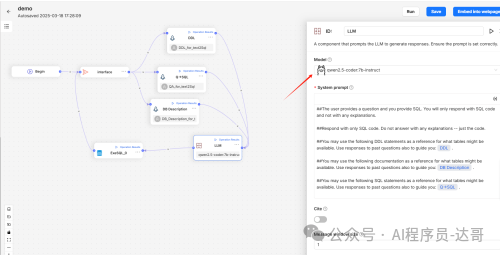
d.LLM
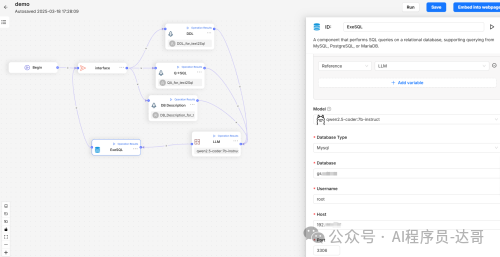
e.ExeSQL
5.运行
完成以上配置后,点击Run,我们就可以提问了。
📢喜欢的小伙伴欢迎
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!

😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 5428
5428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











