






转载自: 向量检索实验室
https://mp.weixin.qq.com/s/gj39zXjZVhe_4hBQj6dCiQ
文章目录
1、论文介绍
- Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs
https://arxiv.org/abs/2312.05934
大型语言模型(LLMs)包含了大量事实信息,但这些知识是固有有限的,严重依赖于训练数据的特性。因此,使用外部数据集来引入新信息或优化LLMs对先前见过的信息的能力是一个重要挑战。
在论文中,作者比较了两种常见的方法:微调和检索增强生成(RAG)。在不同主题上对这两种方法进行了多方面的知识密集型任务评估。
- 改进方法1:微调继续模型并使用特定任务的数据对其进行调整。通过让模型接触特定的知识库,我们期望模型权重相应地进行调整。 这个过程旨在优化模型以用于目标应用,提高其在专业领域中的性能和语境相关性。
- 改进方法2:上下文学习(ICL)通过修改模型的输入查询,而不直接改变模型的权重,来提高预训练LLMs在新任务上的性能。检索增强生成(RAG)是ICL的一种形式。RAG利用信息检索技术使LLMs能够从知识源中获取相关信息,并将其合并到生成的文本中。
2、评估大模型具备的知识
知识和语言模型定义知识是一项复杂的哲学任务,远远超出了这项研究的范围。然而,我们可以在语言模型的背景下考察事实知识的含义。如果一个模型知道一个事实,它可以准确而一致地回答关于这个事实的问题。此外,它可以可靠地区分与这个事实相关的真实陈述和错误陈述。
在数学上,设 是一组 个多项式事实问题,其中每个问题有 个可能的答案,确切地有一个正确答案。设 是相应的可能答案集,是正确答案。
设 是一个语言模型。我们用 表示模型对第 个问题的预测答案。
我们定义模型 关于 的知识得分 为标准准确度得分:
我们说模型 关于问题集 具有任何知识,如果以下条件成立:
简单来说,模型可以一致地给出正确答案,超过了简单的随机猜测基准。自然地,如果知识得分 对于一个模型比另一个模型更高,那么我们断言前者在关于 的知识上比后者更有见识。
3、大模型失败的原因
- 领域知识不足:语言模型可能在其未接触过的特定领域缺乏全面的专业知识。例如,一个仅在威廉·莎士比亚的著作中进行训练的模型在被问及马克·吐温的作品时表现不佳。
- 信息过时:LLMs无可避免地有一个由它们的训练数据集确定的截止日期。因此,发生在最后一次训练更新之后的任何事件、发现或变化将不在模型的知识范围内,除非可以访问外部来源。
- 未记忆:有时模型在训练过程中接触到知识,但没有保留它。对于在训练数据集中很少出现的罕见事实,这一点尤为明显。
- 遗忘:语言模型通常在预训练阶段之后经历额外的训练(微调)。在某些情况下,这可能导致一种被称为灾难性遗忘的现象,模型失去了在微调过程之前具有的一些知识。
- 推理失败:在某些情况下,语言模型可能具有与事实相关的相关知识,但未能正确利用它。这在复杂的多步推理任务或在提出关于同一事实的不同问题时,导致不同的结果时尤为明显。
4、改进方法1:微调
微调是在特定、通常更狭窄的数据集或任务上调整预训练模型以提高其在特定领域性能的过程。在这里,区分不同类型的微调是至关重要的。微调技术通常分为监督、无监督和强化学习(RL)方法。
在原始中,作者采用无监督微调方法,并评估其在提高模型学习新信息的能力方面的有效性。
4.1 有监督微调
监督微调(SFT)需要一组带标签的输入-输出对。其中最常见的SFT方法之一是指令微调,它已经成为提高模型性能最强大的方法之一。在指令微调中,输入是一个自然语言任务描述,输出是期望行为的示例。许多当前最先进的LLMs在预训练阶段之后经历了指令微调。
4.2 强化学习
微调的另一种形式依赖于强化学习或受强化学习启发的优化策略,以更好地调整模型在预训练阶段之后的表现。一些著名的例子包括来自人类反馈的强化学习(RLHF)、DPO和PPO。
4.3 无监督微调
无微调过程被视为预训练阶段的直接延续。我们从原始LLM的保存检查点开始,以因果自回归的方式进行训练,即预测下一个标记。与实际预训练相比的一个主要区别是学习率。通常,当继续模型的预训练时,需要更低的学习率,以避免灾难性遗忘。
5、改进方法2:检索增强生成(RAG)
RAG核心思想是,给定一个辅助知识库 B Q \Beta_{Q} BQ 和一个输入查询 q q q,我们使用RAG架构在知识库中查找与输入查询相似的文档。
然后将这些文档添加到输入查询中,从而为模型提供有关查询主题的更多上下文。
在实践中,实施建议的架构非常简单:给定一个辅助知识库 B Q \Beta_{Q} BQ 和一个预训练的嵌入模型 M e M_{e} Me,我们为每个文档 b ∈ B Q b \in \Beta_{Q} b∈BQ 创建一个密集向量表示(嵌入),并将其存储在向量存储中。
在接收到新的查询 q q q 后,我们使用其嵌入 M e ( q ) M_{e}(q) Me(q),根据点积排名,检索 q q q 的前 K 个最接近的邻居,即 b q = { b k } 1 K b_q = \{b_k\}_1^K bq={bk}1K。
然后,我们将
q
q
q 更新为
q
~
=
b
q
∣
∣
q
\tilde{q} = b_q || q
q~=bq∣∣q,其中 || 表示字符串连接。最后,我们将 作为模型的输出
M
(
q
~
)
M(\tilde{q})
M(q~)。
6、论文实验
6.1 实验数据集
作者从Massively Multilingual Language Understanding Evaluation(MMLU)基准(Hendrycks et al., 2021)中选择了四个不同的任务,涉及解剖学、天文学、大学生物学和大学化学等主题。
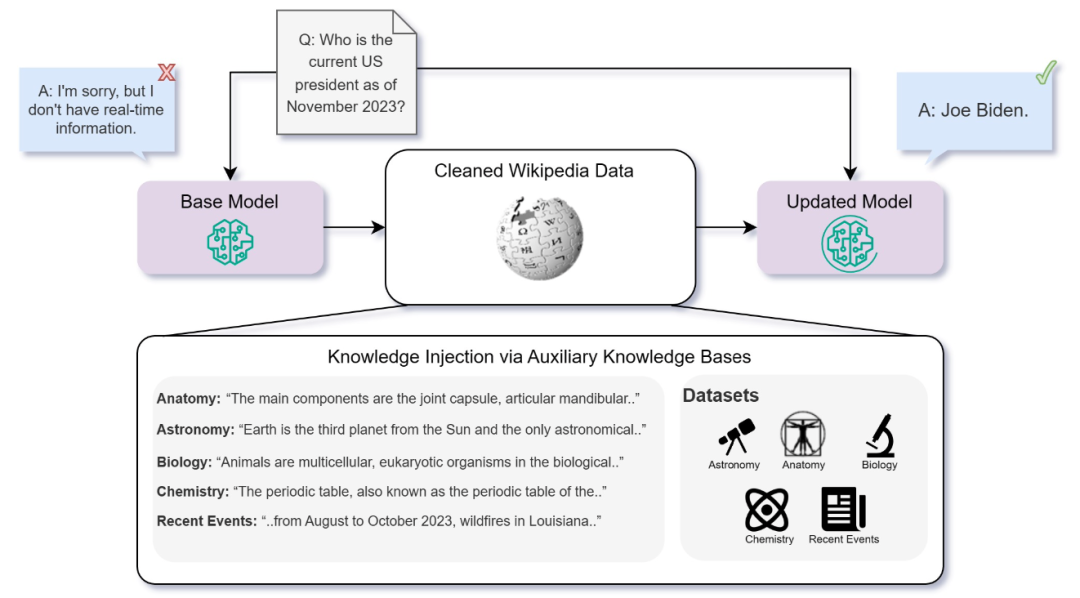
此外作者还创建了一个包含关于当前事件的多项选择问题的任务。这个任务包括有关发生在各种模型训练数据截止日期之后的事件的多项选择问题。重点关注了美国在2023年8月至11月期间的“当前事件”,这些事件包含在相关的维基百科索引中。
6.2 对比模型
模型选择我们选择了三个模型进行推理评估:Llama2-7B,Mistral-7B和Orca2-7B。
选择这些模型是为了代表最受欢迎的开源基础模型和各种基线能力上的指导调整模型。
此外,我们选择了bge-large-en作为RAG组件的嵌入模型,并使用FAISS作为其向量存储。
这个嵌入模型是目前HuggingFace MTEB排行榜4上的开源嵌入模型的SOTA。
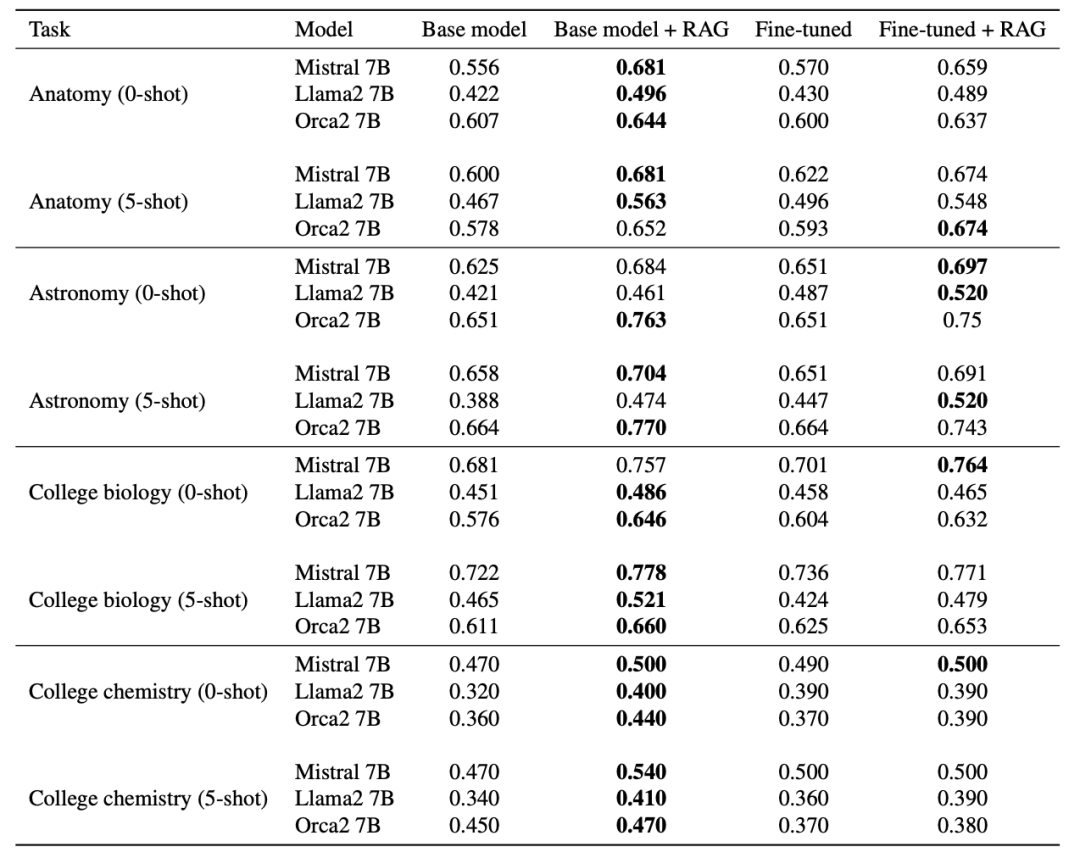
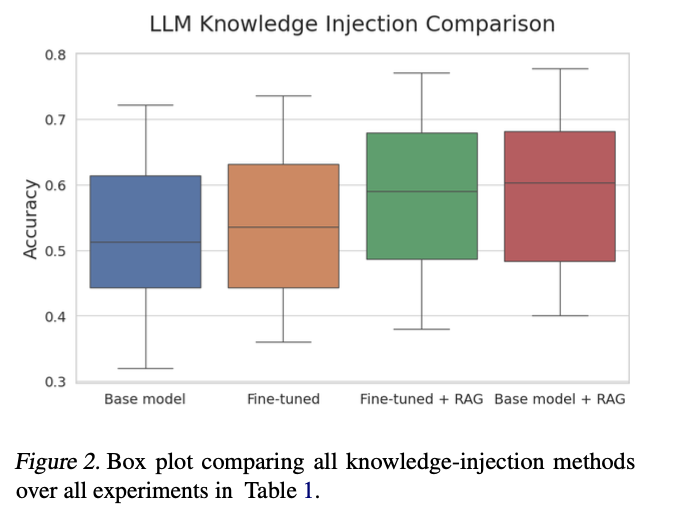
6.3 实验结果
在所有情况下,RAG相对于基础模型表现出显著优势。
此外,使用RAG与基础模型作为生成器的性能始终优于仅进行微调。
- 为了教给预训练的LLM新的知识,知识必须以多种方式重复。
















 114
114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









