






实验目的
1. 清理数据:处理缺失值、异常值、重复值等,使数据更加干净和一致。
2. 数据整合:将多个数据源合并在一起,以获得更完整的数据集。
3. 数据转换:对数据进行缩放、离散化、分类编码等操作,以便于建模和分析。
4. 特征选择:选择与预测目标相关的特征,提高模型的准确性和效率。
5. 特征提取:通过降维技术(如主成分分析(PCA))减少特征数量,同时保留尽可能多的信息。
6. 数据分块:将数据集分成训练集、验证集和测试集,以评估模型的性能和泛化能力。
7. 数据可视化:利用Pandas的数据处理功能生成可视化报告,以更好地理解数据和趋势。
Pandas基本概念及特点
Pandas是一个强大的Python数据分析库,提供了快速、灵活和富有表现力的数据结构,旨在使得“关系”或“标记”数据的操作既简单又直观。
它是一个开源项目,具有强大的社区支持和广泛的应用场景,适用于数据清洗、处理、分析、挖掘等多种任务。
Pandas提供了两种主要的数据结构:Series和DataFrame,分别用于处理一维和二维数据。
读取各种格式文件
| 读取CSV文件 | 使用`pandas.read_csv()`函数,可以指定文件路径、分隔符、编码等参数。 |
| 读取Excel文件 | 使用`pandas.read_excel()`函数,需要安装`openpyxl`或`xlrd`等库支持。 |
| 读取SQL数据库 | 使用`pandas.read_sql()`函数,可以连接数据库并执行SQL查询语句。 |
数据导入与初步探索
查看数据集基本信息
| 查看前几行数据 | 使用`head()`函数,默认显示前5行数据。 |
| 查看数据集的形状 | 使用`shape`属性,返回一个元组,表示数据集的行数和列数。 |
| 查看后几行数据 | 使用`tail()`函数,默认显示后5行数据。 |
| 查看数据集的列名 | 使用`columns`属性,返回一个Index对象,包含所有列名。 |
合并数据
堆叠合并数据
concat函数 横向堆叠
1.引入库
#引入库
import pandas as pd
import numpy as np2. 行索引完全相同时的横向堆叠
user_all_info = pd.read_csv('C:/Intel/user_all_info (1).csv')
df1 = user_all_info.iloc[:,:3]#取出data的前3列数据
df2 = user_all_info.iloc[:,3:]#取出data的第四列到最后1列数据
print('df1的大小为%s,df2的大小为%s'%(df1.shape,df2.shape))
print('外连接合并后的数据框大小为:',pd.concat([df1,df2],axis=1,join='outer').shape)
print('内连接合并后的数据框大小为:',pd.concat([df1,df2],axis=1,join='inner').shape)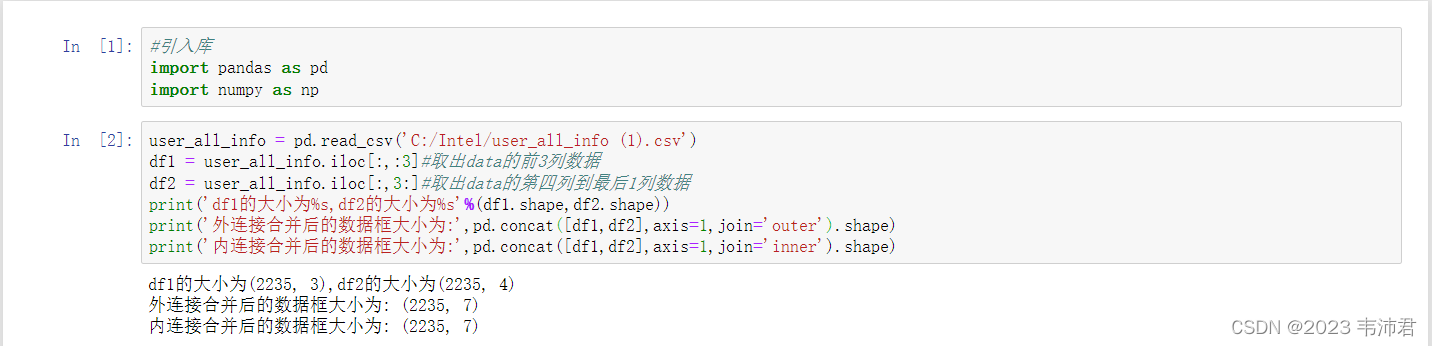
append方法 纵向堆叠
列名完全相同时的纵向堆叠
df3 = user_all_info.iloc[:500,:]#取出user_all_info的前500行数据
df4 = user_all_info.iloc[500:,:]#取出user_all_info的500行以后的数据
print('df3的大小为%s,df4的大小为%s'%(df3.shape,df4.shape))
print('外连接合并后的数据框大小为:',pd.concat([df3,df4],axis=0,join='inner').shape)
print('内连接合并后的数据框大小为:',pd.concat([df3,df4],axis=0,join='outer').shape)使用 append0方法进行纵向堆叠
print('堆叠前df3的大小为%s,df4的大小为%s'%(df3.shape,df4.shape))
result = df3.append(df4)
print('使用append()方法堆叠后的数据框大小为:',result)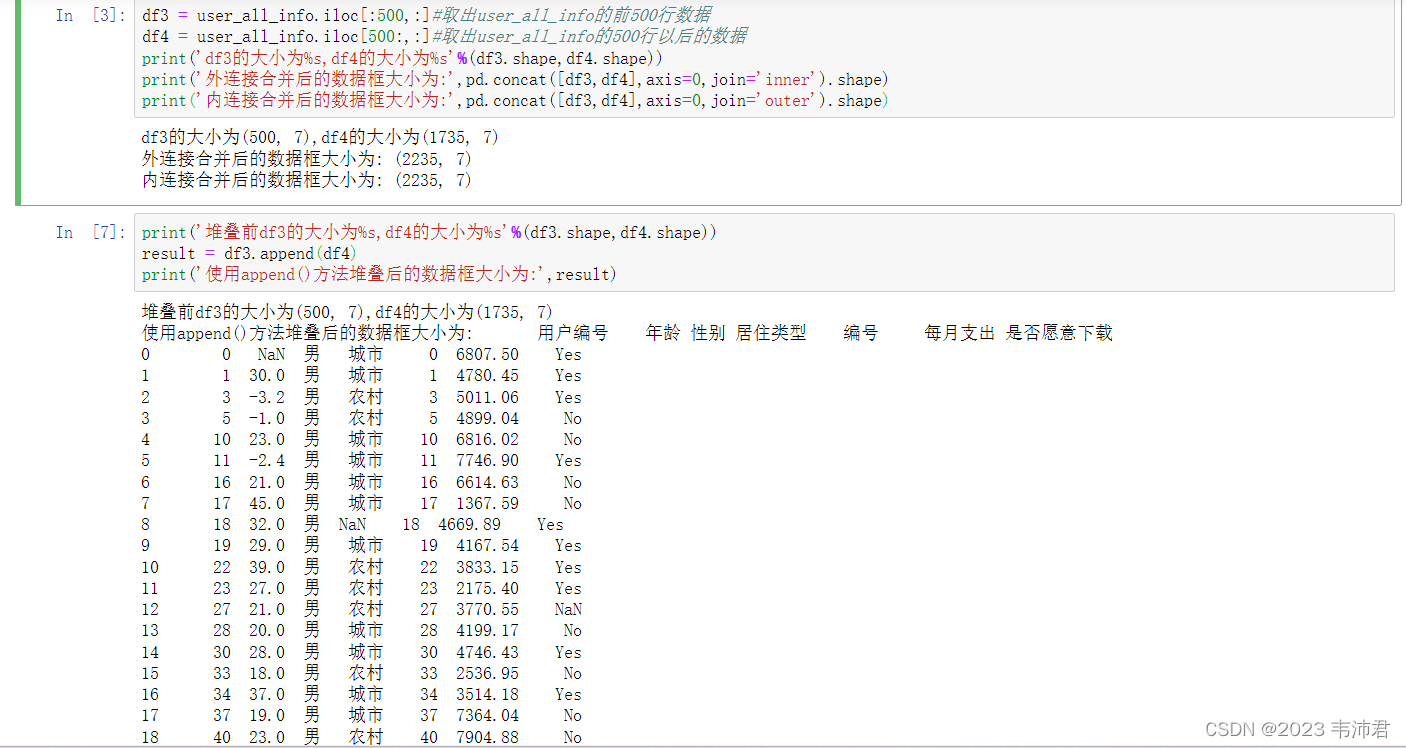
主键合并数据
merge函数
使用merge函数合并数据表
user_download = pd.read_csv('C:/Users/Lenovo/Downloads/user_download.csv',encoding='gbk')
user_download = pd.merge(user_download,user_all_info,left_on='用户编号',right_on='编号')
print('用户每月支出信息表的原始形状为:',user_all_info.shape)
print('用户下载意愿表的原始形状为:',user_download.shape)
print('用户下载意愿表和用户每月支出信息表主键合并后的形状为:',user_download.shape)
join函数
使用join()方法实现主键合并
user_download({'编号':'用户编号'},inplace=True)
user_download = user_download.join(user_download,on='用户编号',rsuffix='1')
print('用户下载意愿表和用户每月支出信息表主键合并后的形状为:',user_download.shape)重叠合并数据
combine_first方法
使用combine_first()方法进行重叠合并
import numpy as np#建立两个字典,除了ID外,其余特征互补
dict1 ={'ID':[1,2,3,4,5,6,7,8,9],'System':['min10','win10',np.nan,'win10'np.nan,np.nan,'win7','win7','win8'],'cpu':['i7','i5',np.nan,'i7',np.nan,np.nan,'i5','i5','i3']}
dict2 ={'ID':[1,2,3,4,5,6,7,8,9],'System':[np.nan,np.nan,'win7','np.nan,'win8','win7','np.nan,'np.nan,'np.nan,],'cpu':['np.nan,np.nan,'i3',np.nan,'i3','np.nan,'i7','i5','np.nan,'np.nan,'np.nan,]}
df1=pd.DataFrame(dict1)
df2=pd.DataFrame(dict2)
print('经过重叠合并后的数据为:\n',df1.combine_first(df2)数据清洗与转换技巧
利用list去重
import pandas as pd
list1 = [1, 2, 2, 3, 4, 4, 5]
list2 = pd.Series(list1).drop_duplicates().values.tolist()
print(list2) # 输出:[1, 2, 3, 4, 5]利用set的特性去重
# 使用集合(set)去重
def remove_duplicates(lst):
return list(set(lst))
# 示例
my_list = [1, 2, 2, 3, 4, 4, 5]
unique_list = remove_duplicates(my_list)
print(unique_list) # 输出: [1, 2, 3, 4, 5]数据类型转换和格式化操作
| 数据类型转换 | 将数据从一种类型转换为另一种类型,如将字符串转换为数值类型,或者将日期字符串转换为日期类型。 |
| 数据格式化 | 将数据按照特定的格式进行显示或处理,如设置日期格式、数字格式等。 |
| 数据离散化 | 将连续的数据划分为若干个离散的区间,以便于进一步的分析和处理。 |
| 数据标准化 | 将数据按照一定的比例缩放,使其符合特定的范围或标准,如将数据缩放到[0,1]之间。 |
drop_duplicates()方法 ————记入重复
equals()方法————特征重复
识别重复值
通过比较数据行或列的值,找出重复的数据记录。
删除重复值
对于识别出的重复数据,可以选择保留其中一条记录,或者全部删除。
根据特定条件删除重复值
在删除重复值时,可以根据特定的条件进行筛选,只删除满足条件的重复记录。
使用Pandas的duplicated()和drop_duplicates()函数
Pandas提供了专门的函数用于识别和删除重复值,可以方便地应用于数据预处理过程中。
缺失值和异常值检测
| 缺失值检测 | 使用`isnull()`或`isna()`函数检测缺失值,返回一个布尔型DataFrame,表示每个元素是否为缺失值。 |
| 异常值检测 | 可以使用统计学方法(如标准差、分位数等)或可视化方法(如箱线图)来检测异常值。Pandas提供了`describe()`函数来查看数据集的描述性统计信息,有助于发现异常值。另外,可以使用`clip()`函数对数据集进行截尾处理,将超出指定范围的值替换为指定值。
|
dropna()方法————删除法
fillna()方法————替换法
interpolate模板————插值法
1.查找缺失值
看那些列存在缺失值:
data.isnull().any()
2.定位缺失值
将含有缺失值的行筛选出来:
#筛选出任何含有缺失值的数据
data[data.isnull().values==True]
#统计某一列缺失值的数量
data['现价'].isnull().value_counts()
#筛选出某一列含有缺失值的数据
data[data['原价'].isnull().values==True]
3.删除缺失值
data.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)`
#删除月销量中的缺失值
data.dropna(axis=0,subset=["月销量"])
分组聚合函数使用场景及示例
使用场景
当需要对数据进行分组,并在每个分组上应用聚合函数(如求和、平均值、计数等)时,可以使用分组聚合函数。
示例
使用Pandas的`groupby()`函数将数据按照某个或多个列进行分组,然后使用`agg()`或聚合函数(如`sum()`、`mean()`等)对每个分组进行计算。
数据可视化展示技巧
| 柱状图 | 使用Pandas的`plot.bar()`方法绘制柱状图,展示分类数据的数量对比。通过设置参数,可以调整柱子颜色、宽度、间距等。 |
| 折线图 | 使用`plot.line()`方法绘制折线图,展示时间序列数据或连续变量的变化趋势。可以添加标记、改变线条样式和颜色等。 |
| 其他图表 | Pandas还支持绘制散点图、面积图、饼图等多种图表类型,可根据需求选择合适的图表展示数据。 |
图表风格调整和美化方法
样式调整
通过设置图表的各种属性,如标题、坐标轴标签、图例等,提升图表的可读性和美观度。Pandas提供了丰富的样式设置选项。
颜色搭配
选择合适的颜色搭配方案,使图表更加醒目和易于理解。可以使用Pandas内置的颜色或自定义颜色。
布局优化
调整图表布局,避免元素重叠和拥挤,提高图表的整体视觉效果。
知识点总结
| Pandas库的基本功能和用途 | Pandas是一个强大的Python数据处理库,提供了快速、灵活和富有表现力的数据结构,旨在使得“关系”或“标记”数据的操作既简单又直观。 |
| 数据结构 | Pandas主要提供了Series(一维数组)和DataFrame(二维表格型数据结构)两种数据结构,它们分别用于处理一维和二维数据。 |
| 数据清洗和处理 | Pandas提供了丰富的数据清洗和处理功能,如缺失值处理、重复值处理、数据类型转换、数据排序、数据筛选等。 |
| 数据重塑和合并 | Pandas提供了多种数据重塑和合并的方法,如pivot、melt、merge、concat等,这些方法可以帮助我们轻松地进行数据转换和整合。 |















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









