






在很多的场景下,我们需要对较为密集的物体来进行计数从而得到他们的数量,有时候我们可以使用yolo模型,通过目标检测来框定每一个物体,再把他们分别加起来求出最后的和,但是对于密集场景下的目标检测和计数来说,yolo可能并不是一个很好的选择,于是在这里引入一种新的基于密集场景下的目标检测和技术方法,原文参考来自于:https://arxiv.org/abs/2104.08391
该项目的全部代码来自于:https://github.com/cvlab-stonybrook/LearningToCountEverything
出处:CVPR 2021
作者单位:石溪大学, VinAI研究院
该篇文章所提及的具体方法以及实现手段在这里就不过多阐述,大家有兴趣可以去看看原文以及相应的论文解读,但是值得一提的是,该种计数方法所需要的代码量异常小,而且是基于一种半监督的方法,在很多密集场景下的计数都有着不错的表现,下面我将开始告诉大家如何实现这种计数方法:
1.首先,我们打开上面的链接,下载关于该项目的全部源码,下载好解压后,我们可以将其导入到Pycharm中,如下图所示:(当然,别忘记了必要库的安装)
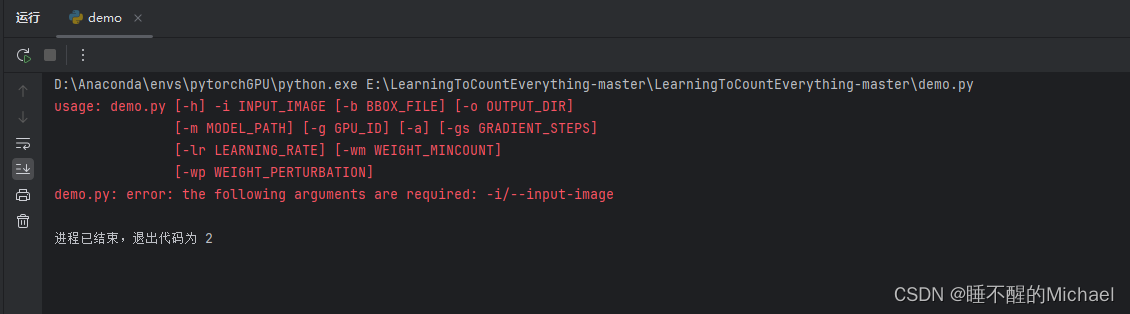
在开始我们的项目前,我们可以先实验一下它所提供的demo的样本,就是图中所打开的demo文件,注意,这时候我们直接运行是会报错的,报错如下图所示:
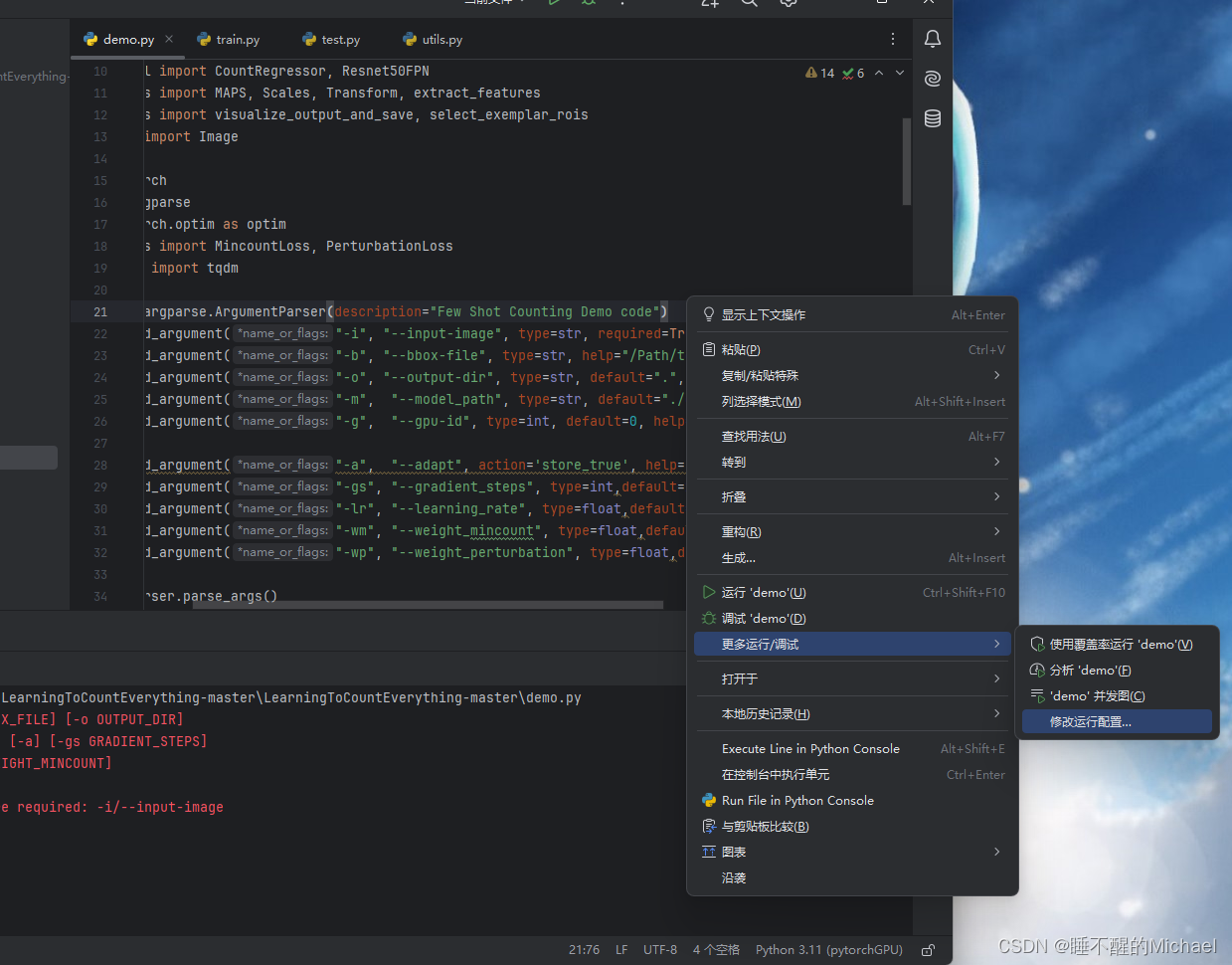
这个时候,我们需要单击右键,选择更多运行/调试,再选择修改运行配置,如下图所示:
我们在参数变量那一行加入下列参数:
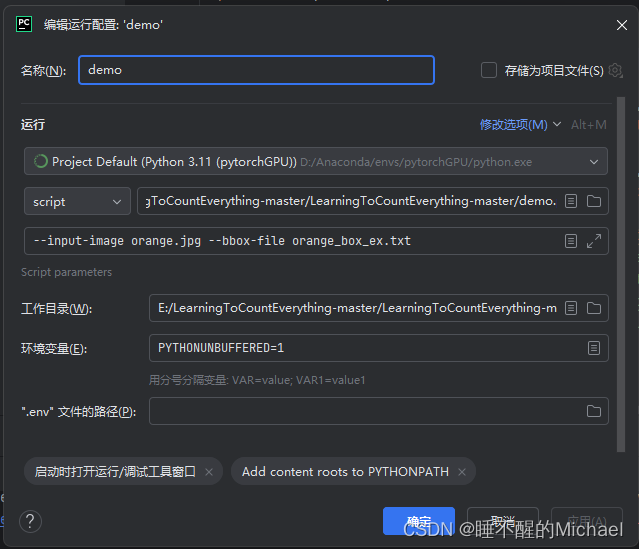
具体内容为:--input-image orange.jpg --bbox-file orange_box_ex.txt
之后,我们再返回原界面,就可以正常运行了,运行结束后的效果如图所示:
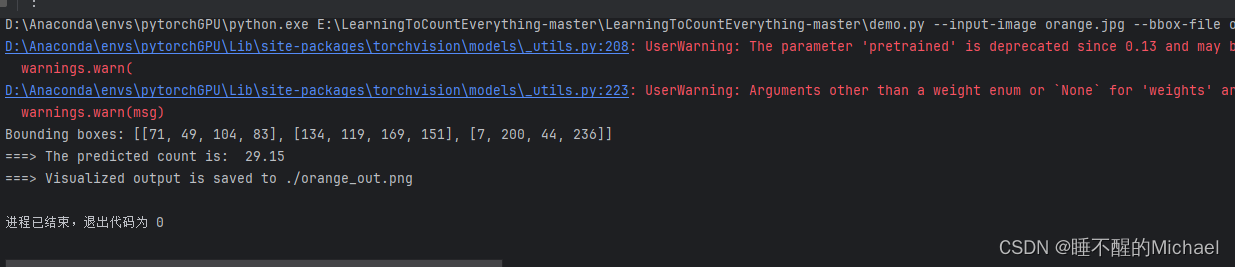
我们也可以打开最后的结果图进行查看:
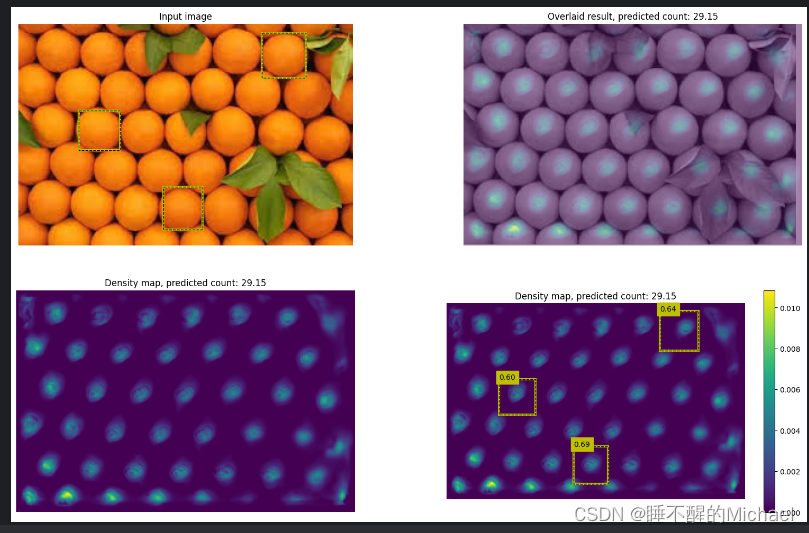
如果你想要训练和测试自己的数据集,记得在一个密集场景下标注3个框左右,然后在每个物体上的中心上标注一个点,紧接着就可以用它进行训练了!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









