






方法一具体可见:点云分割体积计算方法(方法一)-CSDN博客
这里就不多赘述,直接介绍方法二,主要使用到是的pointnet点云分割的模型,具体分为以下几步:
1.数据集的制作(ColudCompare)
在这里我使用到的点云标注工具是CloudCompare,大家可以直接去官网进行下载,具体链接如下:CloudCompare - Open Source project
在下载好以后,我们打开会出现这样的界面:
打开之后,我们点击左上角的file,从里面导入我们的点云文件,
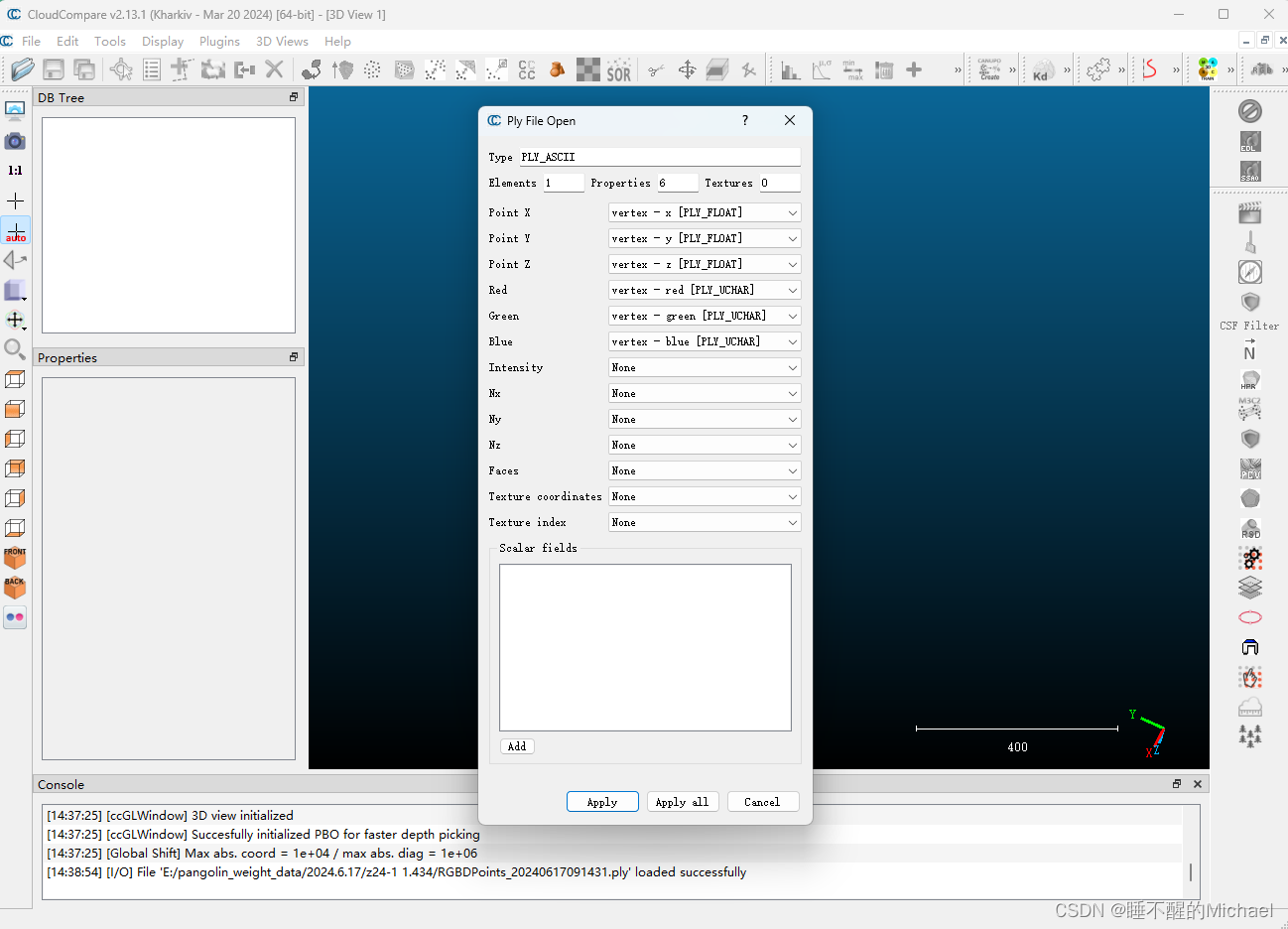
点击apply,就可以将我们的点云文件成功地导入到CloudCompare中了,在这里我以拍摄到的穿山甲点云图像作为示例,如下图所示:
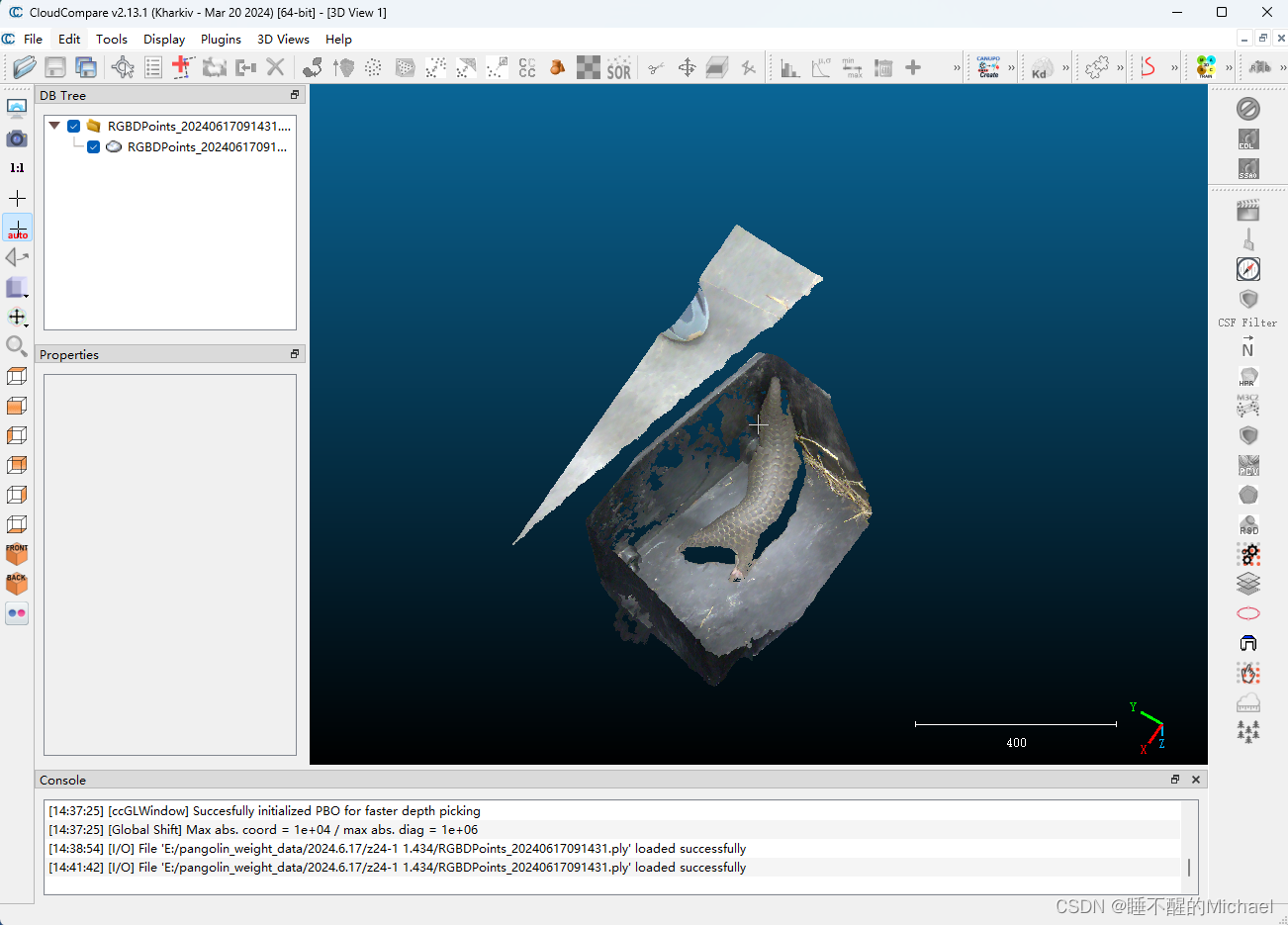
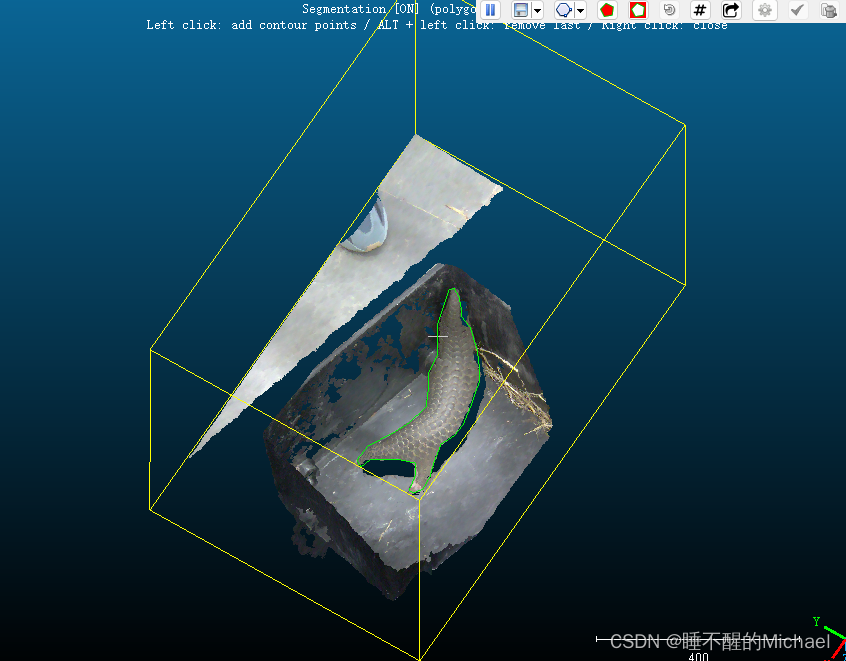
由于我们需要做的是分割任务,于是我们需要将点云图中的穿山甲单独标记出来,如下图所示:
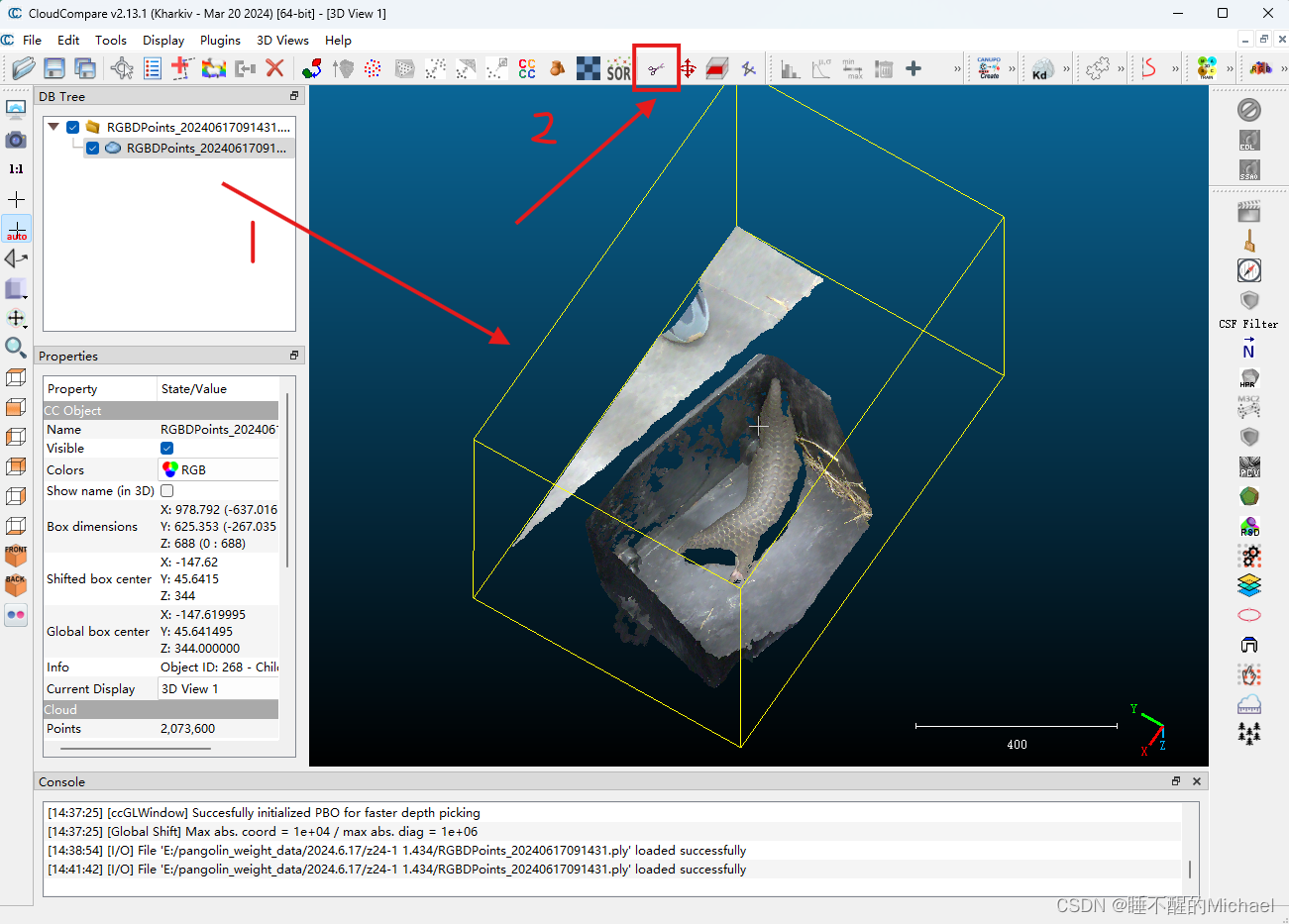
第一步,我们先点击点云图主体,会看到它出现一个黄色的立体框,接下来我们点击上方的那个小剪刀图案,来进行我们的分割,如下图所示:
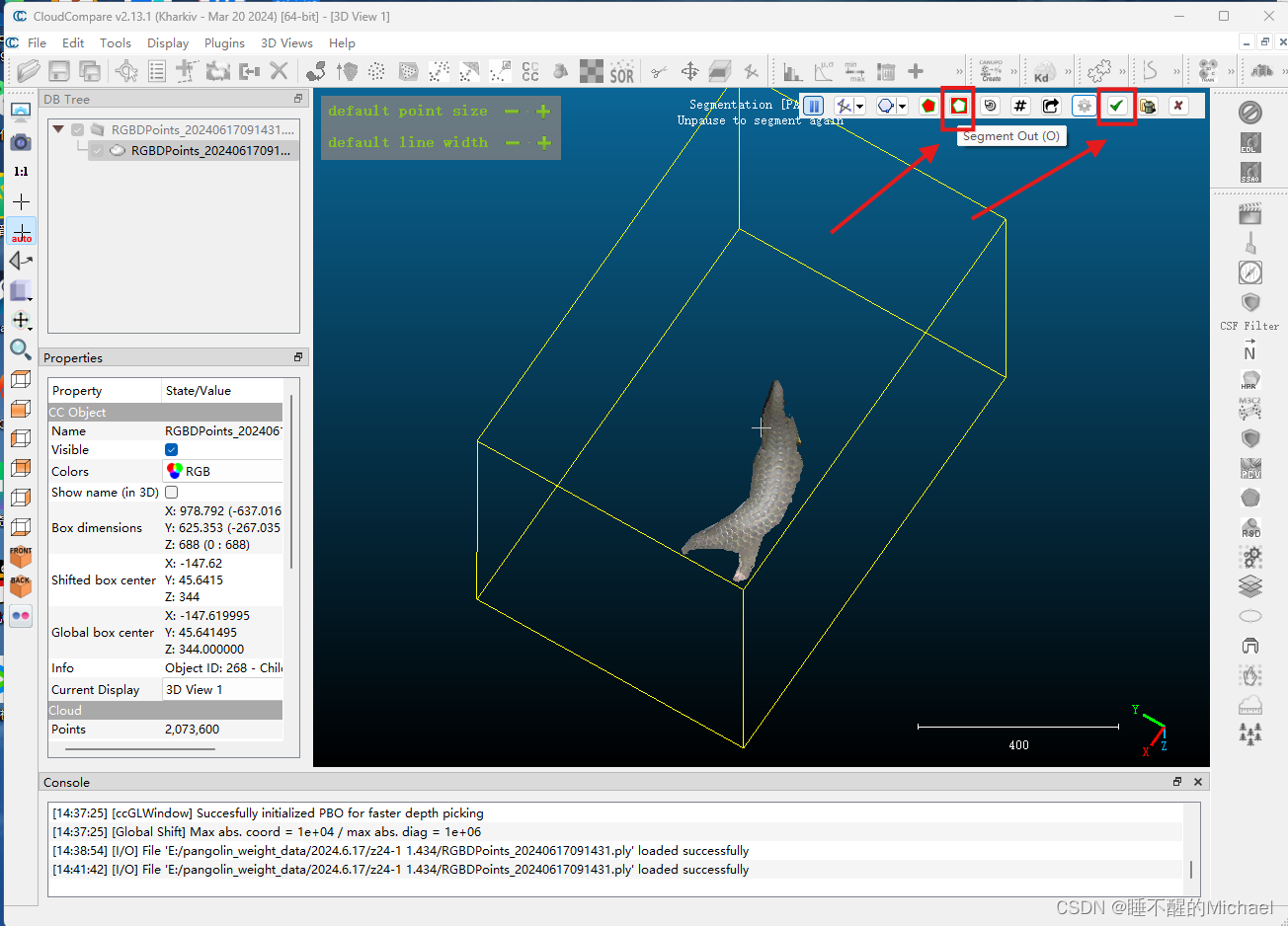
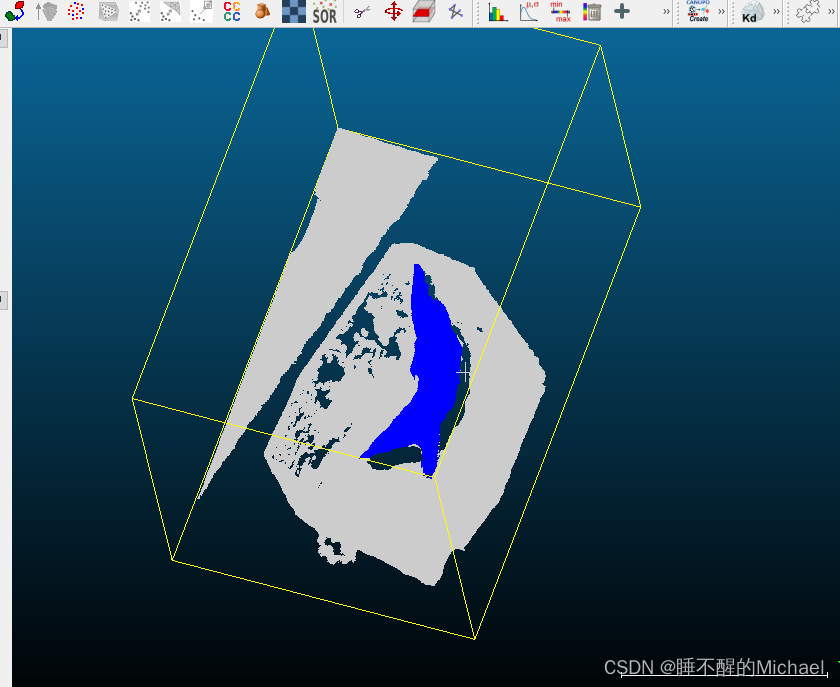
这就是我们分割完成的点云图了,接下来,我们点击右上方的那个小五边形,就可以把我们标记好的物体单独分割出来了,之后再点击确定就好了
之后,我们再点击右上角那个蓝色的加号,给我们分割出来的点云图像添加标签,如下图所示:
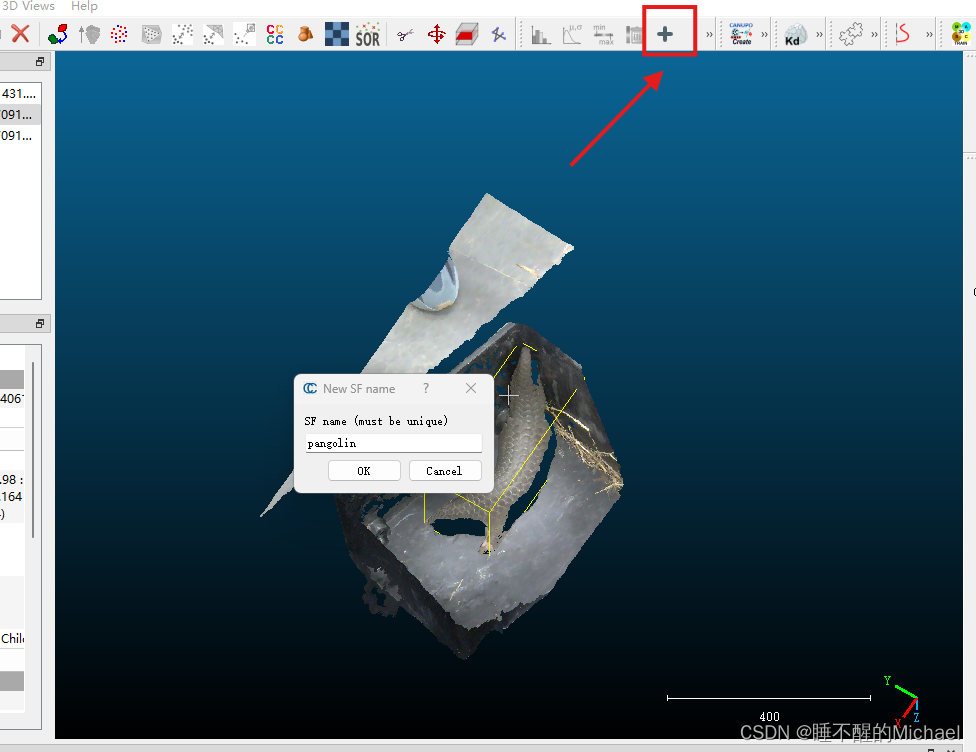
输入你的标签名字,再输入标签数字(输入1或者0或者其他数字都行,随你便),之后我们就可以看到分离出来的点云部分被渲染成了蓝色,
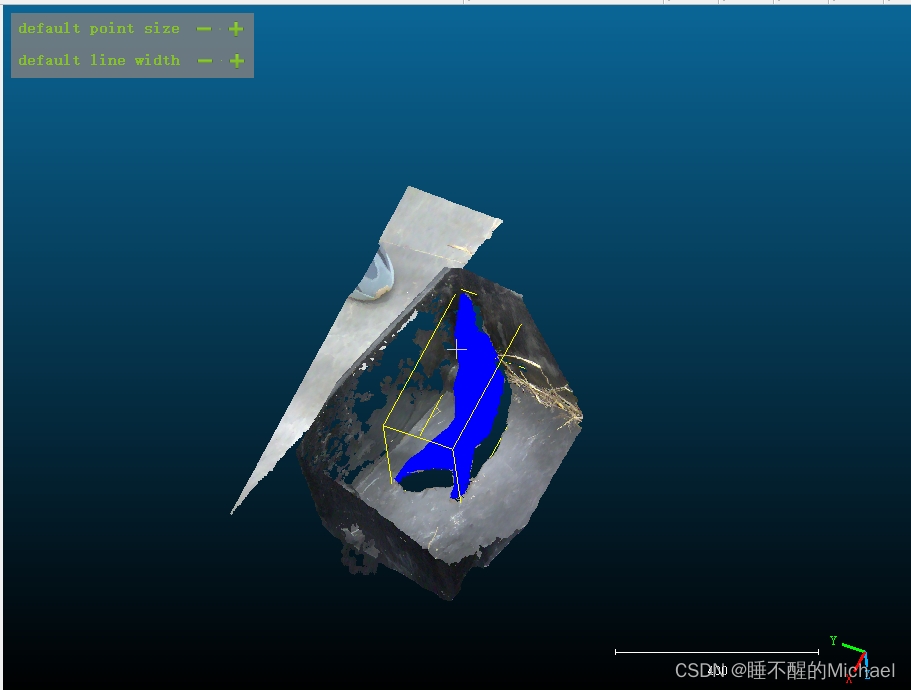
之后,我们将所选的两个点云进行合并,
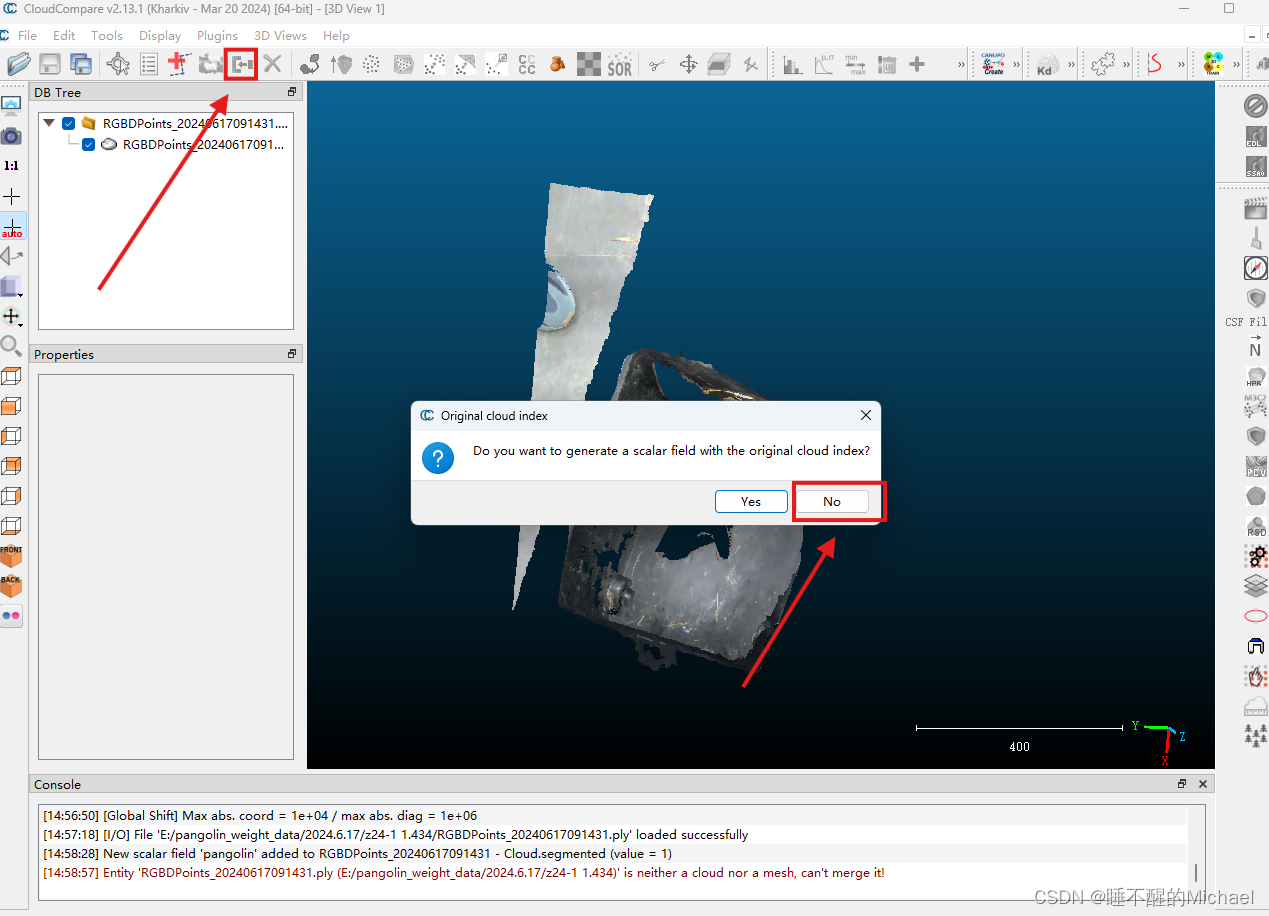
点击左上角的图标,注意,这里弹出来的选择框要选择no,合并完成后就可以得到这样的图了
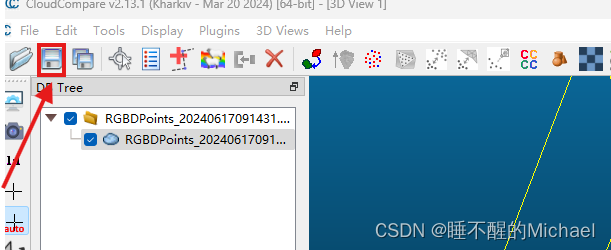
然后,我们点击保存按钮,将其保存为txt格式
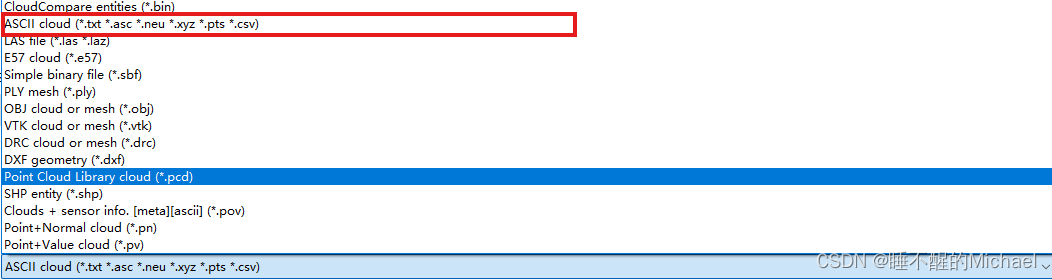
打开我们刚保存的txt格式的文本,可以看到如下所示:

到这一步,我们的数据准备环节就搞定了,接下来我们去GitHub上下载pointnet的源码文件进行解压,链接如下:GitHub - yanx27/Pointnet_Pointnet2_pytorch: PointNet and PointNet++ implemented by pytorch (pure python) and on ModelNet, ShapeNet and S3DIS.
2.准备训练
在训练之前,我们需要将我们txt格式的文件转化为h5格式,具体的代码如下所示:
import numpy as np
import h5py
def load_txt_file(file_path):
data = np.loadtxt(file_path)
points = data[:, :3].astype(np.float32) # 前三列是点的坐标
labels = data[:, 3].astype(np.int64) # 最后一列是标签
return points, labels
def normalize_point_cloud(points):
centroid = np.mean(points, axis=0)
points = points - centroid
max_distance = np.max(np.sqrt(np.sum(points**2, axis=1)))
points = points / max_distance
return points
def sample_points(points, labels, num_points):
if len(points) > num_points:
idx = np.random.choice(len(points), num_points, replace=False)
else:
idx = np.random.choice(len(points), num_points, replace=True)
return points[idx], labels[idx]
def save_to_hdf5(file_path, data, labels):
with h5py.File(file_path, 'w') as f:
f.create_dataset('data', data=data)
f.create_dataset('label', data=labels)
# 假设每个TXT文件表示一个点云数据
txt_file_path = "" #填入你的点云数据路径
points, labels = load_txt_file(txt_file_path)
points = normalize_point_cloud(points)
points, labels = sample_points(points, labels, 1024) # 采样1024个点
# 保存为HDF5格式
hdf5_file_path = "" #填入你的保存h5文件的路径
save_to_hdf5(hdf5_file_path, points[np.newaxis, ...], labels[np.newaxis, ...])
这是单个txt文件转h5文件的代码,如果需要文件夹中多个文件进行转化的话,可以稍微修改下代码,加个for循环,进行遍历。之后,我们将转化好的文件放入一个文件夹中。
之后,我们可以运行训练的代码,如下所示:
import os
import h5py
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
import torch.optim as optim
from models.pointnet import PointNetSeg
class PointCloudDataset(Dataset):
def __init__(self, folder_path, num_points=1024, num_classes=2):
self.folder_path = folder_path
self.num_points = num_points
self.num_classes = num_classes
self.files = [f for f in os.listdir(folder_path) if f.endswith('.h5')]
def __len__(self):
return len(self.files)
def __getitem__(self, idx):
file_path = os.path.join(self.folder_path, self.files[idx])
with h5py.File(file_path, 'r') as f:
data = f['data'][:]
labels = f['label'][:]
points, labels = self.sample_points(data[0], labels[0], self.num_points)
points = self.normalize_point_cloud(points)
# Ensure labels are within the expected range
labels = np.clip(labels, 0, self.num_classes - 1)
return torch.from_numpy(points).float(), torch.from_numpy(labels).long()
def normalize_point_cloud(self, points):
centroid = np.mean(points, axis=0)
points = points - centroid
max_distance = np.max(np.sqrt(np.sum(points**2, axis=1)))
points = points / max_distance
return points
def sample_points(self, points, labels, num_points):
if len(points) > num_points:
idx = np.random.choice(len(points), num_points, replace=False)
else:
idx = np.random.choice(len(points), num_points, replace=True)
return points[idx], labels[idx]
# 示例使用
folder_path = "" #输入你的h5文件所在的文件夹
num_classes = 2 # Adjust based on your dataset
dataset = PointCloudDataset(folder_path, num_classes=num_classes)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device) #测试当前所用的是GPU还是CPU
# 构建PointNet模型
in_dim = 3 # 输入维度,点云通常为3 (x, y, z)
model = PointNetSeg(in_dim=in_dim, out_dim=num_classes).to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
num_epochs = 100 #训练轮数
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
for i, (points, labels) in enumerate(dataloader):
points = points.transpose(1, 2).to(device) # 转置输入形状为 [batch_size, in_channels, num_points]
labels = labels.to(device)
optimizer.zero_grad()
outputs = model(points)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(dataloader):.4f}')
# 保存模型
torch.save(model.state_dict(), "") #输入你的模型保存地址
需要注意的是,我们要确保文件结构如下图所示:

不然在from models.pointnet import时会报错,之后我们就可以运行代码进行训练了,这是我跑了100轮的结果:
之后,我们可以用我们训练好的模型来进行预测并计算体积,预测代码如下所示:
import torch
import open3d as o3d
import numpy as np
from models.pointnet import PointNetSeg
# 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
# 加载训练好的模型
model_path = "" # 请替换为你的模型路径
num_classes = 2 # 根据你的任务设置,
in_dim = 3 # 输入维度,点云通常为3 (x, y, z)
out_dim = num_classes # 输出维度
model = PointNetSeg(in_dim=in_dim, out_dim=out_dim).to(device)
model.load_state_dict(torch.load(model_path, map_location=device))
model.eval()
# 读取点云数据
point_cloud_path = "" # 请替换为你的点云文件路径
pcd = o3d.io.read_point_cloud(point_cloud_path)
points = np.asarray(pcd.points)
# 将点云数据转换为张量并调整形状
points_tensor = torch.tensor(points, dtype=torch.float32).unsqueeze(0).transpose(1, 2).to(device)
# 进行分割预测
with torch.no_grad():
preds = model(points_tensor)
# 确认预测结果的形状
print(f"Shape of preds: {preds.shape}")
# 将预测结果转换为标签
preds = preds.squeeze().cpu().numpy()
pred_labels = np.argmax(preds, axis=0)
# 确认标签的形状
print(f"Shape of pred_labels: {pred_labels.shape}")
print(f"Shape of points: {points.shape}")
# 提取点云
pangolin_points = points[pred_labels == 1] # 假设标签1表示你的点云
# 检查是否有你的分割点云
if len(pangolin_points) == 0:
print("未检测到任何穿山甲点云。")
else:
# 使用选中的点创建新的点云
pangolin_pcd = o3d.geometry.PointCloud()
pangolin_pcd.points = o3d.utility.Vector3dVector(pangolin_points)
# 计算体积
# 使用体素化方法
voxel_size = 0.01 # 根据需要调整体素大小
voxel_grid = o3d.geometry.VoxelGrid.create_from_point_cloud(pangolin_pcd, voxel_size)
voxel_volume = len(voxel_grid.get_voxels()) * (voxel_size ** 3)
# 输出体积
print(f"Estimated Volume of Pangolin: {voxel_volume} cubic units")
# 可视化分割点云
o3d.visualization.draw_geometries([pangolin_pcd])
至此,所有步骤就完成了,但是有几点值得注意:
1.训练和预测时对于显存要求比较大,可以先尝试运行看看你的设备是否可以运行
2.数据集的要求会比较大,如果训练的数据集较小,可能会没什么效果

















 1271
1271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









