






文章目录
1.地平线图(Horizon Chart)
地平线图(Horizon Chart)是一种用于展示时间序列数据的可视化图表,主要用于显示时间趋势数据的变化。它通过将数据在垂直方向上进行分层,并使用不同颜色来表示数据的波动,从而提供一种简洁的方式来理解数据的趋势和波动。
特点
(1)多层显示: 地平线图通过将数据值的范围切分为多个水平层,每个层级代表不同的数值区间。这使得它能够在有限的空间内展示大量的时间序列数据。
(2)色彩编码: 数据的不同值被通过颜色进行编码,通常正值和负值会使用不同的颜色。不同的颜色和色调深浅能够有效区分不同的数据区间。
(3)压缩空间: 通过层次化和颜色编码,地平线图能够在一个图表内展示大量的数据,而不需要占用过多的空间。这使得地平线图特别适用于数据量较大、但需要紧凑展示的场景。
(4)显示趋势和异常: 由于其色彩层次的特点,地平线图不仅能有效地展示时间序列数据的趋势,还能较为直观地显示出数据的异常波动。
应用场景
(1)时间序列数据展示:展示某一变量在一段时间内的变化趋势。例如,股票价格、气温变化、销售额等。
(2)大规模数据的简洁展示:当需要展示多个时间序列的数据时(如多个传感器的数据、不同地区的销售数据等),地平线图能够在一个图表中清晰地对比多个数据系列。
(3)异常检测与趋势分析:用于快速识别时间序列中的异常波动或突变,发现潜在的问题或趋势。
(4)数据摘要:
当你需要用较少的空间展示大量的数据(例如金融、气象等领域的多维数据)时,地平线图非常适用。
python实现
用python实现地平线图的绘制,代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
# 读取数据
data = pd.read_csv('(ch-3.3.1)subscribers.csv')
# 使用正确的日期格式进行转换
data['Date'] = pd.to_datetime(data['Date'], format='%m-%d-%Y')
# 按日期排序数据
data_sorted = data.sort_values(by='Date')
# 提取 Item Views 列作为时间序列数据
item_views = data_sorted['Item Views']
# 数据归一化
min_data, max_data = np.min(item_views), np.max(item_views)
data_normalized = (item_views - min_data) / (max_data - min_data) # 归一化到0-1区间
# 创建颜色映射
cmap = plt.cm.RdYlBu # 选择一个渐变色
norm = mcolors.Normalize(vmin=0, vmax=1) # 归一化
# 设置图形尺寸
fig, ax = plt.subplots(figsize=(10, 2))
# 绘制地平线图
for i in range(6): # 使用6层进行展示
ax.fill_between(data_sorted['Date'], i, i + 1, where=(data_normalized > i/6) & (data_normalized <= (i+1)/6),
color=cmap(norm(i/6)), interpolate=True)
# 移除坐标轴
ax.set_yticks([])
ax.set_xticks([])
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False
# 添加中文标题
ax.set_title('项目点击量地平线图', fontsize=16)
# 显示图形
plt.tight_layout()
plt.show()
结果如图所示:

注意事项
(1)数据归一化: 地平线图通常用于展示数值范围较广的数据,因此需要在绘制之前对数据进行适当的归一化处理,确保不同数据系列的可比性。
(2)色彩选择: 色彩的选择对于地平线图非常重要。通常,负值和正值会用不同的色调表示,使用渐变色能够更加直观地显示数据的波动。
(3)图层数量: 根据数据的波动程度,选择合适的图层数量。层数过多可能使得图形过于复杂,层数过少可能无法精确地展示数据的细节。
(4)坐标轴设计: 地平线图通常不直接显示传统的坐标轴,而是通过颜色和位置来传达数据的趋势。你可以考虑是否需要添加简要的刻度线或标签来帮助理解数据。
(5)数据预处理: 对时间序列数据的预处理是必不可少的。特别是在数据缺失、噪声较多的情况下,合适的平滑和插值方法可以帮助提高地平线图的可读性。
变体
地平线图(Horizon Chart)是一个非常有效的时间序列数据可视化工具,尤其适合展示数据的波动和趋势。但在实际应用中,地平线图存在一些局限性,例如在数据波动非常大的情况下,图形可能变得难以阅读,颜色的过渡可能不够直观等。为了克服这些问题,以下是几种 地平线图的高级变体:
a 堆叠地平线图
在堆叠地平线图中,我们可以同时显示多个时间序列数据,每个数据系列都堆叠在一起,使用不同的颜色区分它们。
**特点:**通过堆叠多个地平线图层,展示多个时间序列数据。这对于同时展示多个数据系列(例如多个区域或多个产品的 Item Views)非常有用。
实现代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
# 读取数据
data = pd.read_csv('(ch-3.3.1)subscribers.csv')
# 使用正确的日期格式进行转换
data['Date'] = pd.to_datetime(data['Date'], format='%m-%d-%Y')
# 按日期排序数据
data_sorted = data.sort_values(by='Date')
# 提取多个时间序列数据(假设你有多个时间序列,比如 Item Views 和 Hits)
item_views = data_sorted['Item Views']
hits = data_sorted['Hits']
# 数据归一化
def normalize_data(data):
min_data, max_data = np.min(data), np.max(data)
return (data - min_data) / (max_data - min_data)
item_views_normalized = normalize_data(item_views)
hits_normalized = normalize_data(hits)
# 创建颜色映射
cmap = plt.cm.RdYlBu # 选择一个渐变色
norm = mcolors.Normalize(vmin=0, vmax=1) # 归一化
# 设置图形尺寸
fig, ax = plt.subplots(figsize=(10, 6))
# 绘制堆叠地平线图
for i in range(6): # 使用6层进行展示
ax.fill_between(data_sorted['Date'], i, i + 1, where=(item_views_normalized > i/6) & (item_views_normalized <= (i+1)/6),
color=cmap(norm(i/6)), interpolate=True)
ax.fill_between(data_sorted['Date'], i + 1, i + 2, where=(hits_normalized > i/6) & (hits_normalized <= (i+1)/6),
color=cmap(norm(i/6)), interpolate=True)
# 移除坐标轴
ax.set_yticks([])
ax.set_xticks([])
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False
# 添加中文标题
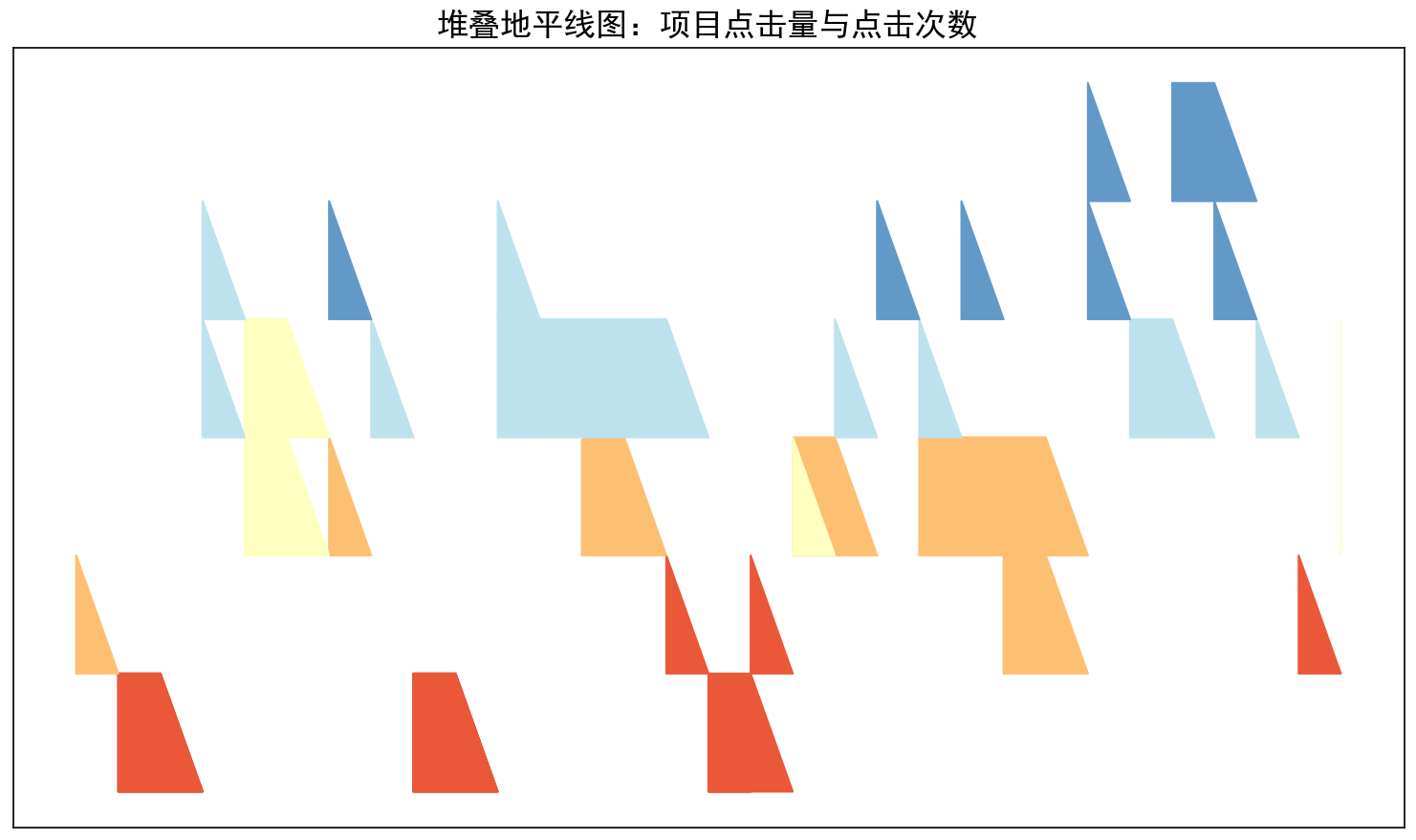
ax.set_title('堆叠地平线图:项目点击量与点击次数', fontsize=16)
# 显示图形
plt.tight_layout()
plt.show()
结果如图所示:
b 平滑地平线图
特点:在传统地平线图的基础上对数据进行平滑处理,通常使用移动平均或其他平滑算法来减少短期波动的影响,从而更加突出数据的长期趋势。
解决问题:如果原始数据波动剧烈,可以使用平滑技术来减少过多的噪音,使趋势更为清晰。
实现代码如下:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.colors as mcolors
# 读取数据
data = pd.read_csv('(ch-3.3.1)subscribers.csv')
# 使用正确的日期格式进行转换
data['Date'] = pd.to_datetime(data['Date'], format='%m-%d-%Y')
# 按日期排序数据
data_sorted = data.sort_values(by='Date')
# 提取 Item Views 列作为时间序列数据
item_views = data_sorted['Item Views']
# 使用滑动窗口进行平滑处理(例如,使用5点窗口的移动平均)
smoothed_item_views = item_views.rolling(window=5).mean()
# 数据归一化
def normalize_data(data):
min_data, max_data = np.min(data), np.max(data)
return (data - min_data) / (max_data - min_data)
item_views_normalized = normalize_data(smoothed_item_views)
# 创建颜色映射
cmap = plt.cm.RdYlBu # 选择一个渐变色
norm = mcolors.Normalize(vmin=0, vmax=1) # 归一化
# 设置图形尺寸
fig, ax = plt.subplots(figsize=(10, 2))
# 绘制平滑地平线图
for i in range(6): # 使用6层进行展示
ax.fill_between(data_sorted['Date'], i, i + 1, where=(item_views_normalized > i/6) & (item_views_normalized <= (i+1)/6),
color=cmap(norm(i/6)), interpolate=True)
# 移除坐标轴
ax.set_yticks([])
ax.set_xticks([])
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False
# 添加中文标题
ax.set_title('平滑地平线图:项目点击量', fontsize=16)
# 显示图形
plt.tight_layout()
plt.show()
结果如图所示:

c 动态地平线图
特点:使用交互式地平线图,允许用户通过缩放、拖动等操作查看不同时间范围的数据。
解决问题:适用于数据量非常大或时间跨度较长的情况,可以动态调整查看的时间段,避免一开始加载时图表过于拥挤或复杂。
实现代码如下:
import plotly.graph_objects as go
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 读取数据
data = pd.read_csv('(ch-3.3.1)subscribers.csv')
# 使用正确的日期格式进行转换
data['Date'] = pd.to_datetime(data['Date'], format='%m-%d-%Y')
# 按日期排序数据
data_sorted = data.sort_values(by='Date')
# 提取 Item Views 列作为时间序列数据
item_views = data_sorted['Item Views']
# 数据归一化
def normalize_data(data):
min_data, max_data = np.min(data), np.max(data)
return (data - min_data) / (max_data - min_data)
item_views_normalized = normalize_data(item_views)
# 创建 Plotly 图形
fig = go.Figure()
# 添加动态地平线图层
fig.add_trace(go.Scatter(x=data_sorted['Date'], y=item_views_normalized, fill='tonexty',
mode='lines', line_color='royalblue', name="项目点击量"))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
plt.rcParams['axes.unicode_minus'] = False
# 设置图标题和标签
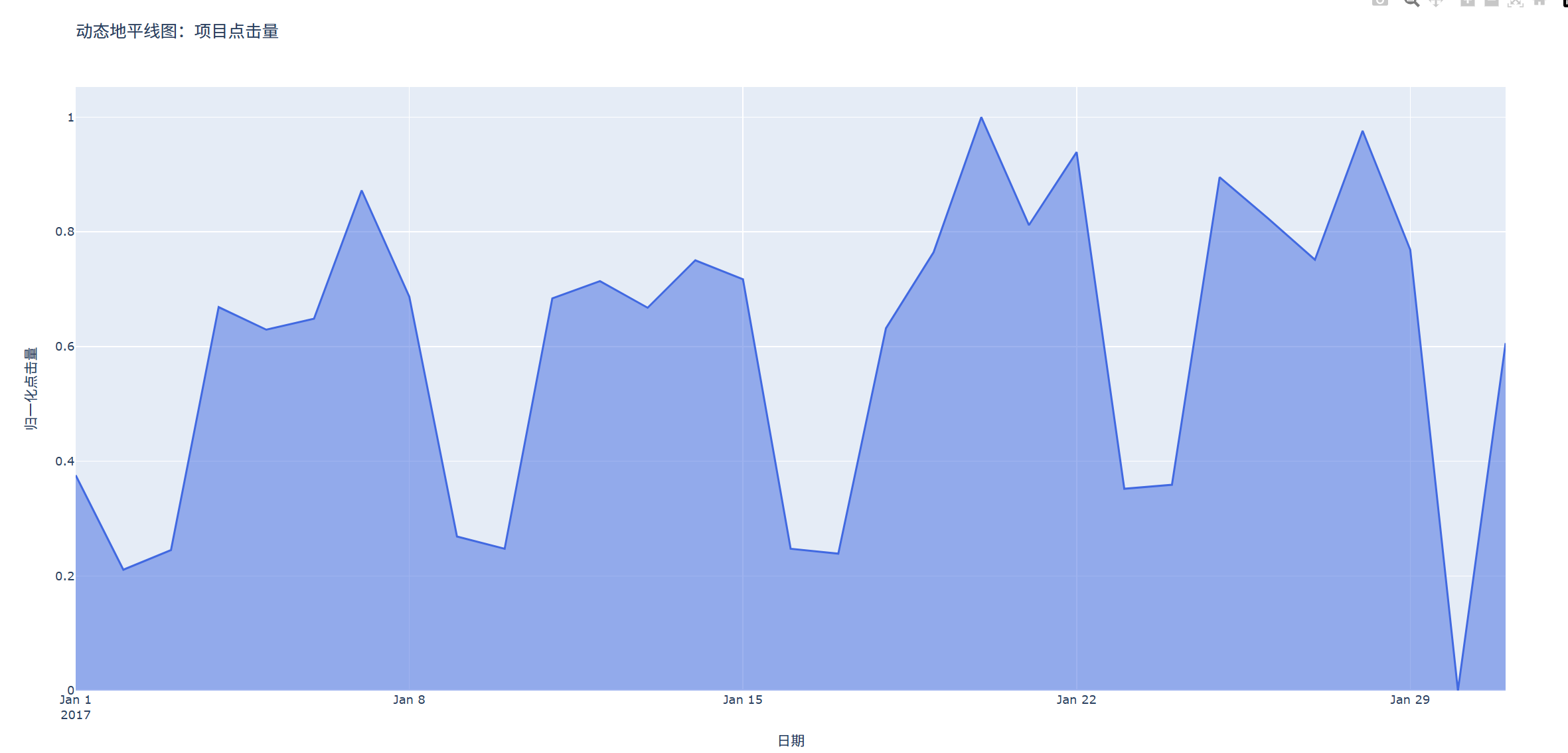
fig.update_layout(title='动态地平线图:项目点击量',
xaxis_title='日期',
yaxis_title='归一化点击量')
# 显示图形
fig.show()
绘制结果:
2.河流图
河流图(Streamgraph)是一种动态且富有表现力的时间趋势数据可视化图形,通常用于展示多个变量随时间的变化,特别是用于表现时间序列数据中的不同部分或类别的变化情况。它通过将不同的时间序列数据流通过堆叠的方式展现,使得每个时间序列的波动情况一目了然。
特点
(1)堆叠的流线:河流图的主要特点是使用堆叠的流线表示时间序列数据中的不同部分(如多个类别的相对变化)。每个流线代表一个变量或类别,它们的高度随着时间变化而变化。
(2)流线平滑:河流图的流线通常是平滑的,通过曲线连接不同时间点的数据值,而不是简单的直线或阶梯图,这使得它比普通堆叠区域图更具表现力和美感。
(3)颜色编码:每个流线(或类别)通常使用不同的颜色编码,这使得不同类别之间的变化能够直观区分。颜色的选择应具有良好的对比度,以确保不同流线的辨识度。
(4)动态性:河流图可以通过动画展示,使得观众能更好地理解数据在时间上的流动与变化。
应用场景
(1)展示类别随时间的变化:河流图非常适合用来展示类别或子类随时间变化的趋势。例如,展示社交媒体平台上不同类型话题的讨论量、网站流量来源、销售额中的不同产品类别等。
(2)市场分析与预测:用于展示不同市场或产品在时间范围内的占比变化。例如,展示市场上多个品牌的市场份额随时间的变化趋势。
(3)趋势分析与对比:当需要对比多个时间序列数据,尤其是数据之间相互影响和相对变化时,河流图可以帮助有效地呈现这些趋势。
(4)动态数据展示:河流图可以展示数据在不同时间点上的动态变化,特别适合展示时间序列中的模式或季节性变化。
python实现
实现代码如下:
import plotly.graph_objects as go
import pandas as pd
# 读取用户上传的 CSV 文件
file_path = '(ch-3.3.1)subscribers.csv'
data = pd.read_csv(file_path)
# 将日期列转换为日期类型
data['Date'] = pd.to_datetime(data['Date'], format='%m-%d-%Y')
# 按日期排序数据
data_sorted = data.sort_values(by='Date')
# 选择多个类别的数据(例如:'Subscribers', 'Reach', 'Item Views')
category1 = data_sorted['Subscribers']
# 创建分离河流图
fig = go.Figure()
# 添加流线(类别1)
fig.add_trace(go.Scatter(
x=data_sorted['Date'], y=category1,
fill='tozeroy', mode='none', name='订阅者',
fillcolor='rgba(31, 119, 180, 0.6)' # 设置颜色
))
# 设置布局
fig.update_layout(
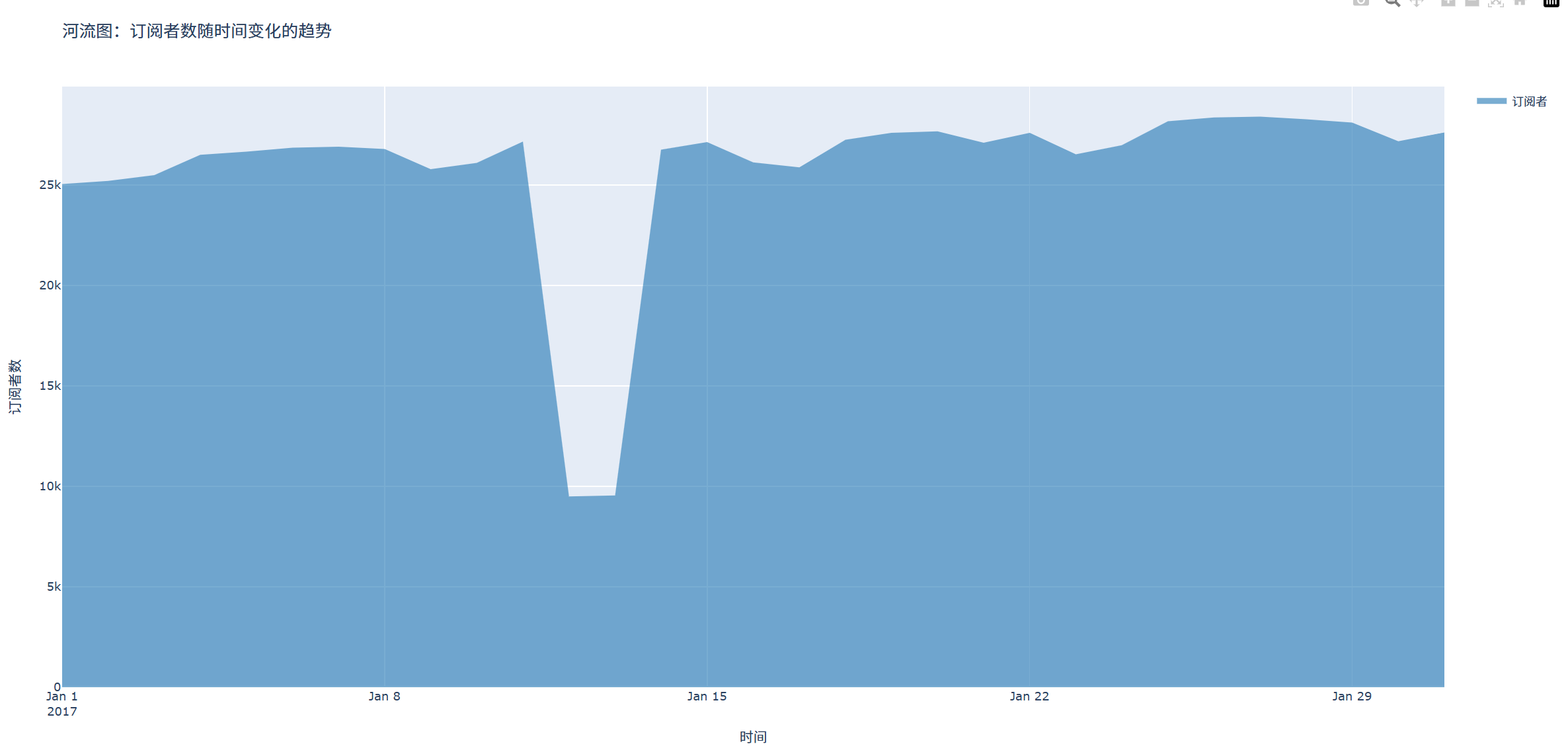
title='河流图:订阅者数随时间变化的趋势',
xaxis_title='时间',
yaxis_title='订阅者数',
showlegend=True
)
# 显示图形
fig.show()
结果如图所示:
注意事项
(1)数据准备与清洗:河流图通常需要多个时间序列数据,这些数据需要按时间排序并适当归一化。数据中的缺失值需要填补或处理,以保证图形的连贯性和流畅性。
(2)合适的流线数量:虽然河流图适合展示多个类别,但流线的数量过多可能会导致图形过于复杂和难以阅读。建议流线的数量保持在适当的范围内,通常不超过10个类别。
(3)颜色的选择:颜色在河流图中非常重要,应选择具有良好对比度的颜色以区分不同流线。同时避免使用过多相似的颜色,以免导致视觉混乱。
(4)时间粒度与范围:设置时间粒度时,选择适当的时间窗口非常重要。过长的时间跨度可能导致数据细节丢失,过短的时间跨度则可能导致图形过于杂乱。
变体
堆叠变化图
特点:与传统的河流图类似,但它通过显示每个时间点的堆叠值来突出不同类别之间的相对变化。这种变体有助于更清晰地看到各类别随时间的相对变化。
解决问题:适用于当多个类别的趋势比较重要时,可以更加明确地看到类别之间的变化,并帮助消除复杂的重叠。
实现代码:
import plotly.graph_objects as go
import pandas as pd
# 读取用户上传的 CSV 文件
file_path = '(ch-3.3.1)subscribers.csv'
data = pd.read_csv(file_path)
# 将日期列转换为日期类型
data['Date'] = pd.to_datetime(data['Date'], format='%m-%d-%Y')
# 按日期排序数据
data_sorted = data.sort_values(by='Date')
# 选择多个类别的数据(例如:'Subscribers', 'Reach', 'Item Views')
category1 = data_sorted['Subscribers']
category2 = data_sorted['Reach']
category3 = data_sorted['Item Views']
# 创建河流图
fig = go.Figure()
# 添加流线(类别1)
fig.add_trace(go.Scatter(
x=data_sorted['Date'], y=category1,
fill='tozeroy', mode='none', name='Subscribers',
fillcolor='rgba(31, 119, 180, 0.6)' # 设置颜色
))
# 添加流线(类别2)
fig.add_trace(go.Scatter(
x=data_sorted['Date'], y=category2,
fill='tonexty', mode='none', name='Reach',
fillcolor='rgba(255, 127, 14, 0.6)' # 设置颜色
))
# 添加流线(类别3)
fig.add_trace(go.Scatter(
x=data_sorted['Date'], y=category3,
fill='tonexty', mode='none', name='Item Views',
fillcolor='rgba(44, 160, 44, 0.6)' # 设置颜色
))
# plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体
# plt.rcParams['axes.unicode_minus'] = False
# 设置布局
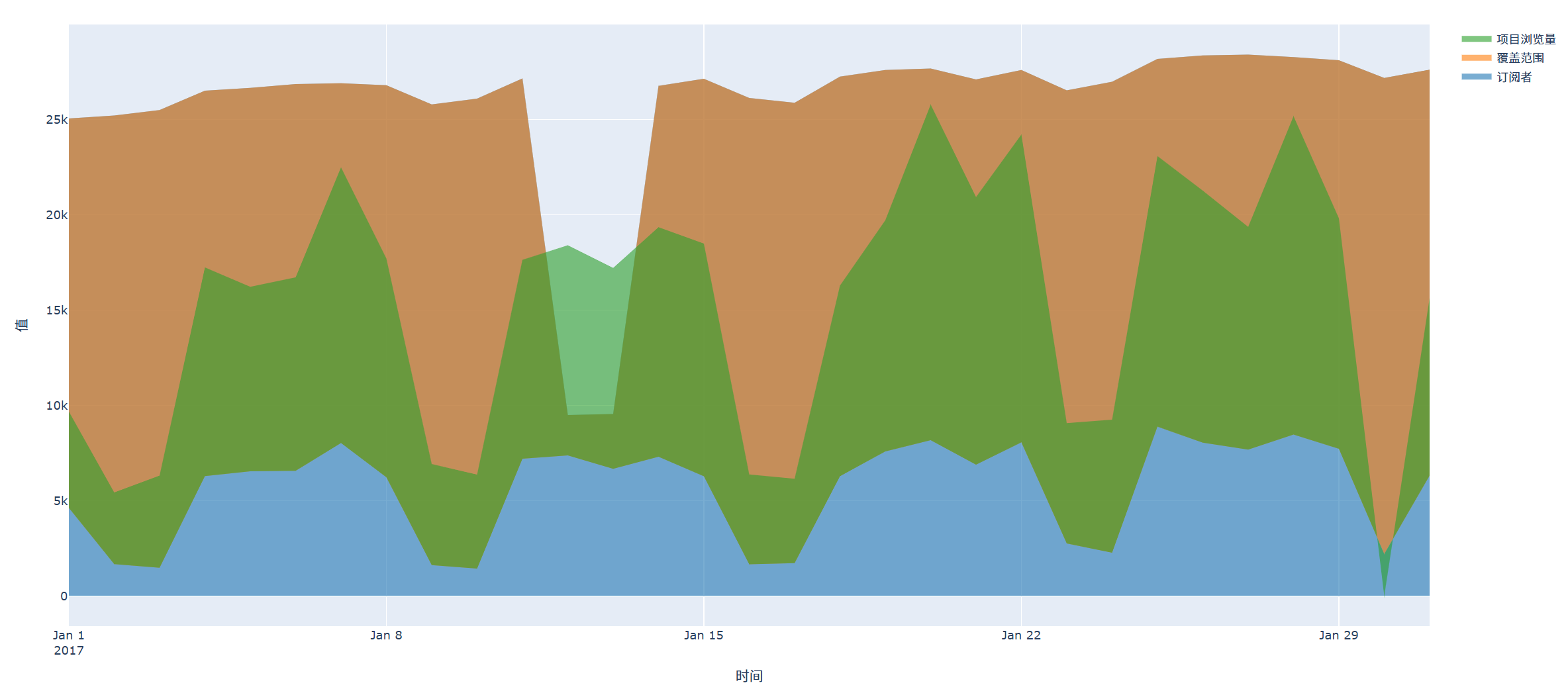
fig.update_layout(
title='河流图示例:多个类别随时间变化的趋势',
xaxis_title='时间',
yaxis_title='值',
showlegend=True
)
# 显示图形
fig.show()
结果如图所示:
3.瀑布图
瀑布图是一种常见的数据可视化图表,特别适用于展示从一个初始值开始,经过一系列增减值的变化,直到得出最终值。它通常用于展示时间趋势中的 增减变化,或者在财务分析中用来表示 收入、费用、利润等的变化。
特点
(1)展示增减变化:瀑布图能够清晰地展示数据从一个起始值到最终值之间的增减变化。每个数据点的变化(增幅或减幅)由一条柱状图表示,柱子之间的连线可以看出变化趋势。
(2)增值和减值区分明显:瀑布图通过不同的颜色区分增值(通常为绿色)和减值(通常为红色)。这有助于快速识别哪些因素推动了总值的增加,哪些因素导致了减少。
(3)动态变化的展示:瀑布图清晰地展示了数据的变化,帮助观察者快速理解数据变化的来源和趋势。它是一种逐步展开的图形,通常以时间或类别作为横坐标,纵坐标显示变化值。
(4)清晰显示起始和结束点:瀑布图在初始值和最终值处使用不同的样式或者颜色强调,帮助用户更加清楚地识别数据的起始值和终止值。
应用场景
(1)财务分析:收入、成本和利润的变化:瀑布图可以用来展示公司财务数据的变化,例如:如何从总收入逐步减去各项费用和成本,直到得出净利润。
(2)时间序列数据变化:展示某个变量在时间序列中的 增减变化。例如,每日销售额、每日网站访问量 或 每日用户增长量 的变化。
python实现
实现代码如下:
import plotly.graph_objects as go
import pandas as pd
# 读取用户上传的 CSV 文件
file_path = '(ch-3.3.1)subscribers.csv'
data = pd.read_csv(file_path)
# 将日期列转换为日期类型
data['Date'] = pd.to_datetime(data['Date'], format='%m-%d-%Y')
# 按日期排序数据
data_sorted = data.sort_values(by='Date')
# 计算增减变化(以 'Item Views' 列为例)
change = data_sorted['Item Views'].diff().fillna(0)
# 创建瀑布图
fig = go.Figure()
# 添加瀑布图数据
fig.add_trace(go.Waterfall(
x=data_sorted['Date'], # 横坐标为日期
y=change, # 纵坐标为增减变化
measure=["relative"] * len(change), # 所有变化值都为相对变化
base=0, # 设置起始点为 0
increasing={"marker": {"color": "green"}}, # 增加的部分为绿色
decreasing={"marker": {"color": "red"}}, # 减少的部分为红色
totals={"marker": {"color": "blue"}}, # 总值为蓝色
))
# 设置布局
fig.update_layout(
title='瀑布图示例:项目浏览量随时间变化',
xaxis_title='日期',
yaxis_title='变化量',
showlegend=True
)
# 显示图形
fig.show()
结果如图所示:
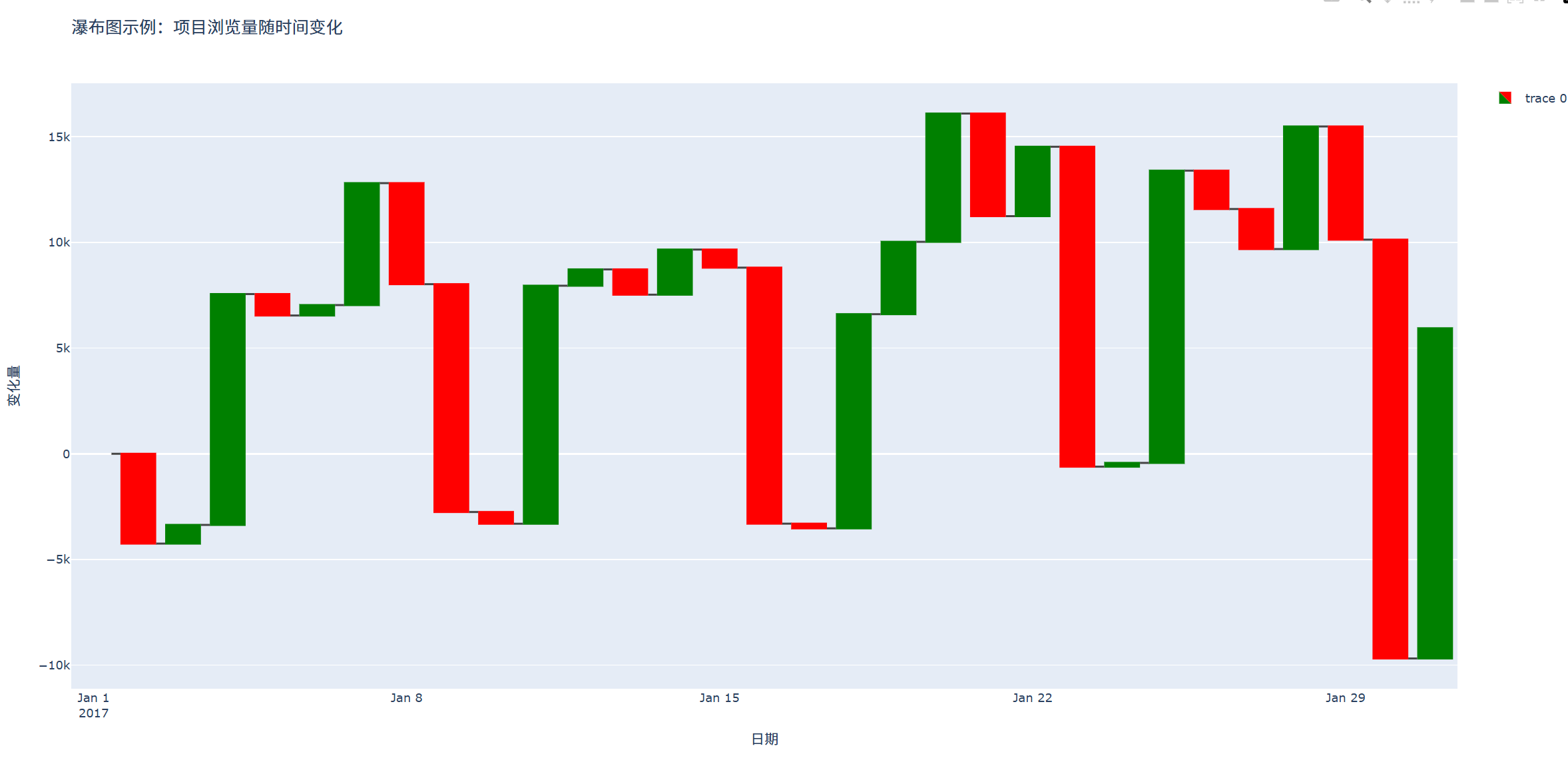
注意事项
(1)数据的顺序:瀑布图必须遵循时间顺序或某种逻辑顺序(如类别顺序)进行绘制。数据的顺序直接影响瀑布图的准确性。
(2)起始和结束值的明确标识:起始和结束点应清晰标示,可以使用不同的颜色或样式(例如虚线或较粗的边框)来突出显示这些值。
(3)合理分配增减区间:如果数据变化较大,避免每个区间过小。应根据实际变化的大小选择合适的间隔,以确保图表清晰且易于理解。
(4)颜色区分增减变化:使用不同的颜色区分增值(通常为绿色)和减值(通常为红色),以便观察者能够快速识别数据的趋势。
变体
a 堆叠瀑布图
特点: 堆叠瀑布图通过将多个类别的增减变化堆叠在一起,使得每个类别对最终结果的贡献更加明确。
解决问题: 如果有多个不同的因素(例如不同产品的销售增减),堆叠瀑布图能够帮助展示这些因素在总值变化中的贡献,并且可以更清晰地比较它们。
实现代码和结果如下:
import plotly.graph_objects as go
import pandas as pd
# 读取用户上传的 CSV 文件
file_path = '(ch-3.3.1)subscribers.csv'
data = pd.read_csv(file_path)
# 将日期列转换为日期类型
data['Date'] = pd.to_datetime(data['Date'], format='%m-%d-%Y')
# 按日期排序数据
data_sorted = data.sort_values(by='Date')
# 计算各列的增减变化
category1_change = data_sorted['Subscribers'].diff().fillna(0)
category2_change = data_sorted['Reach'].diff().fillna(0)
category3_change = data_sorted['Item Views'].diff().fillna(0)
# 创建堆叠瀑布图
fig = go.Figure()
# 添加瀑布图数据(类别1)
fig.add_trace(go.Waterfall(
x=data_sorted['Date'], y=category1_change,
measure=["relative"] * len(category1_change),
base=0,
increasing={"marker": {"color": "green"}},
decreasing={"marker": {"color": "red"}},
totals={"marker": {"color": "blue"}},
name="订阅者"
))
# 添加瀑布图数据(类别3)
fig.add_trace(go.Waterfall(
x=data_sorted['Date'], y=category3_change,
measure=["relative"] * len(category3_change),
base=category2_change.sum(),
increasing={"marker": {"color": "green"}},
decreasing={"marker": {"color": "red"}},
totals={"marker": {"color": "blue"}},
name="项目浏览量"
))
# 设置布局
fig.update_layout(
title='堆叠瀑布图:多个类别随时间变化的趋势',
xaxis_title='日期',
yaxis_title='变化量',
showlegend=True
)
# 显示图形
fig.show()
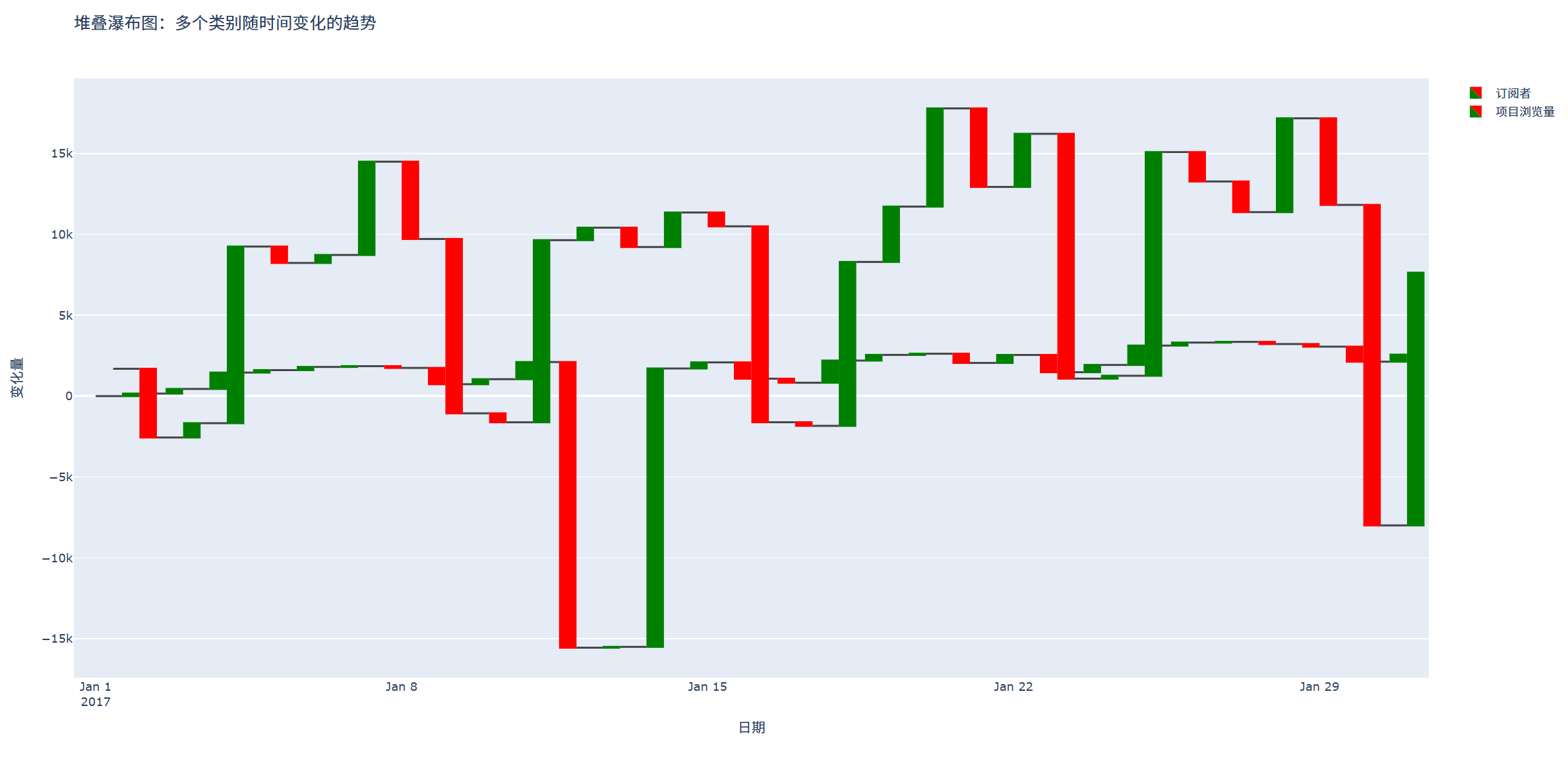
b 动态瀑布图
特点: 通过添加动态交互功能,允许用户拖动、缩放或查看不同时间段的数据变化。
解决问题: 对于数据量非常大或时间跨度很长的情况,静态瀑布图可能无法清晰展示所有变化。动态瀑布图能够帮助用户灵活查看某一特定时间段或某一部分数据。
实现代码和结果如下:
import plotly.graph_objects as go
import pandas as pd
# 读取用户上传的 CSV 文件
file_path ='(ch-3.3.1)subscribers.csv'
data = pd.read_csv(file_path)
# 将日期列转换为日期类型
data['Date'] = pd.to_datetime(data['Date'], format='%m-%d-%Y')
# 按日期排序数据
data_sorted = data.sort_values(by='Date')
# 计算各列的增减变化
category1_change = data_sorted['Subscribers'].diff().fillna(0)
category2_change = data_sorted['Reach'].diff().fillna(0)
category3_change = data_sorted['Item Views'].diff().fillna(0)
# 创建一个空的图形对象
fig = go.Figure()
# 添加第一列数据的初始堆叠瀑布图
fig.add_trace(go.Waterfall(
x=data_sorted['Date'],
y=category1_change,
measure=["relative"] * len(category1_change),
base=0,
increasing={"marker": {"color": "green"}},
decreasing={"marker": {"color": "red"}},
totals={"marker": {"color": "blue"}},
name="订阅者"
))
# 添加第二列数据
fig.add_trace(go.Waterfall(
x=data_sorted['Date'],
y=category2_change,
measure=["relative"] * len(category2_change),
base=category1_change.sum(),
increasing={"marker": {"color": "green"}},
decreasing={"marker": {"color": "red"}},
totals={"marker": {"color": "blue"}},
name="覆盖范围"
))
# 添加第三列数据
fig.add_trace(go.Waterfall(
x=data_sorted['Date'],
y=category3_change,
measure=["relative"] * len(category3_change),
base=category2_change.sum(),
increasing={"marker": {"color": "green"}},
decreasing={"marker": {"color": "red"}},
totals={"marker": {"color": "blue"}},
name="项目浏览量"
))
# 设置动画和交互性
fig.update_layout(
title='动态堆叠瀑布图:多个类别随时间变化的趋势',
xaxis_title='日期',
yaxis_title='变化量',
showlegend=True,
updatemenus=[dict(
type='buttons',
showactive=False,
buttons=[dict(label='播放',
method='animate',
args=[None, dict(frame=dict(duration=500, redraw=True), fromcurrent=True)])]
)],
sliders=[dict(
currentvalue=dict(prefix="日期: ", visible=True),
steps=[dict(label=str(data_sorted['Date'][i].date()),
method='animate',
args=[[f'Frame {i+1}'], dict(frame=dict(duration=500, redraw=True), mode='immediate')])
for i in range(len(data_sorted))]
)]
)
# 显示图形
fig.show()
结果如图:
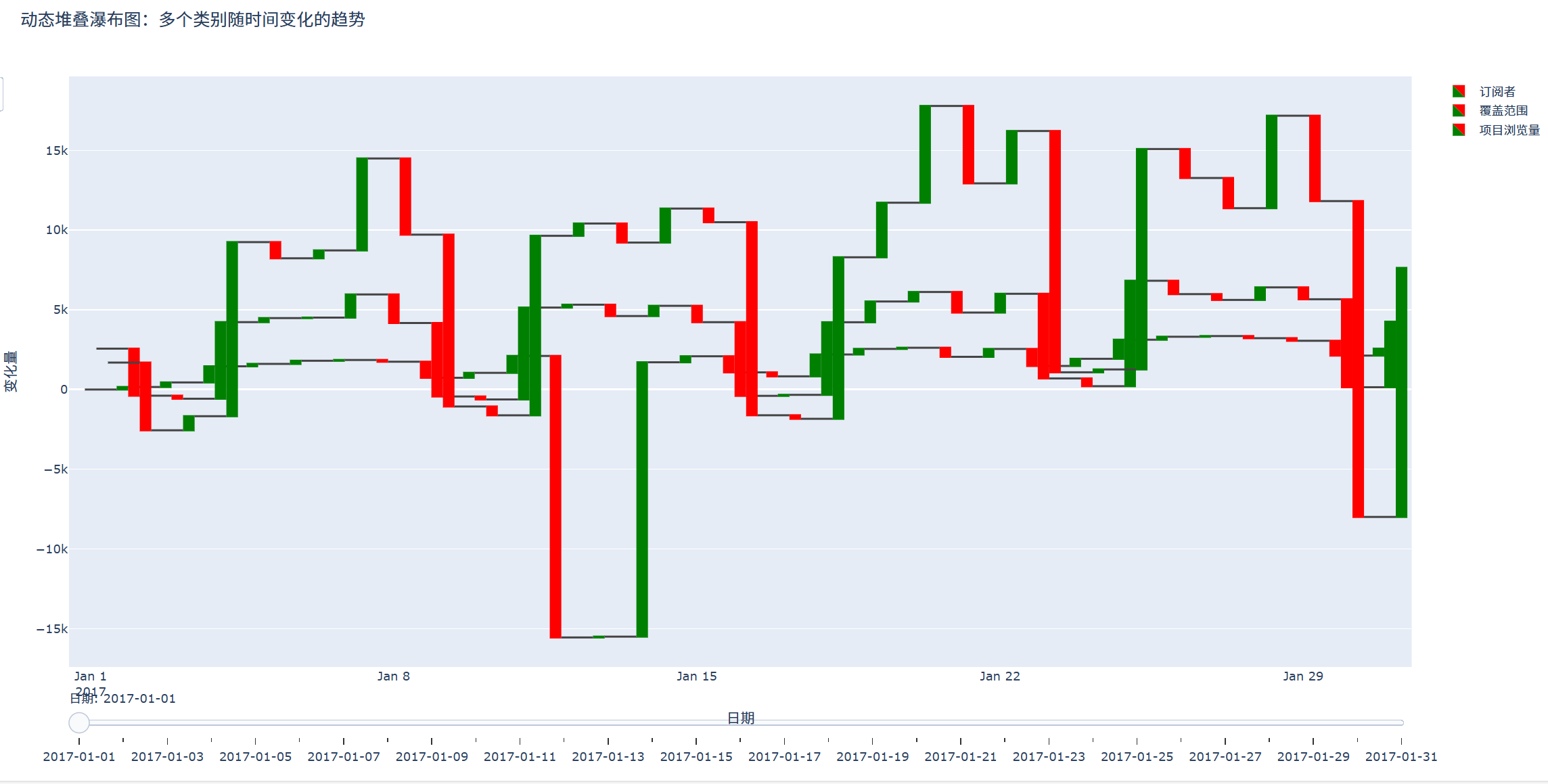
4.烛形图
特点
(1)结构:烛形图通常由一根“蜡烛”组成,每根蜡烛表示一段时间的市场价格变化(如一天、一小时等)。每根蜡烛的组成部分包括:
开盘价(Open):这段时间内的初始价格。
收盘价(Close):这段时间内的最终价格。
最高价(High):这段时间内的最高价格。
最低价(Low):这段时间内的最低价格。
(2)颜色:烛形图通常使用不同的颜色来表示价格的走势:
绿色或白色:表示收盘价高于开盘价(上涨)。
红色或黑色:表示收盘价低于开盘价(下跌)
应用场景
(1)金融市场分析:烛形图最常用于金融市场(如股票、外汇、加密货币等)的价格走势图。它可以帮助投资者判断价格的趋势和波动,识别反转信号。
(2)趋势分析:通过观察烛形图的形态,分析价格波动和市场情绪(如买入和卖出压力)。
(3)交易策略:烛形图是技术分析的基础工具之一,通常结合其他指标(如移动平均线、RSI、MACD等)用于制定交易决策。
python实现
实现代码如下:
import pandas as pd
import plotly.graph_objects as go
# 读取用户上传的 CSV 文件
file_path = '(ch-3.3.1)subscribers.csv'
data = pd.read_csv(file_path)
# 将日期列转换为日期类型
data['Date'] = pd.to_datetime(data['Date'], format='%m-%d-%Y')
# 按日期排序数据
data_sorted = data.sort_values(by='Date')
# 这里假设数据中包含开盘价(Open)、最高价(High)、最低价(Low)和收盘价(Close)
# 如果数据没有这些列,我们可以根据实际情况进行假设处理。
# 创建烛形图
fig = go.Figure(data=[go.Candlestick(
x=data_sorted['Date'],
open=data_sorted['Subscribers'], # 假设订阅者是开盘价
high=data_sorted['Reach'], # 假设覆盖范围是最高价
low=data_sorted['Item Views'], # 假设项目浏览量是最低价
close=data_sorted['Subscribers'] + data_sorted['Reach'], # 假设收盘价是某种组合
increasing_line_color='green', # 上涨时线条颜色
decreasing_line_color='red', # 下跌时线条颜色
)])
# 设置图形的标题和标签
fig.update_layout(
title='烛形图示例:时间趋势的可视化',
xaxis_title='日期',
yaxis_title='价格',
xaxis_rangeslider_visible=False, # 隐藏底部的滑块
showlegend=False
)
# 显示图形
fig.show()
结果如图所示:
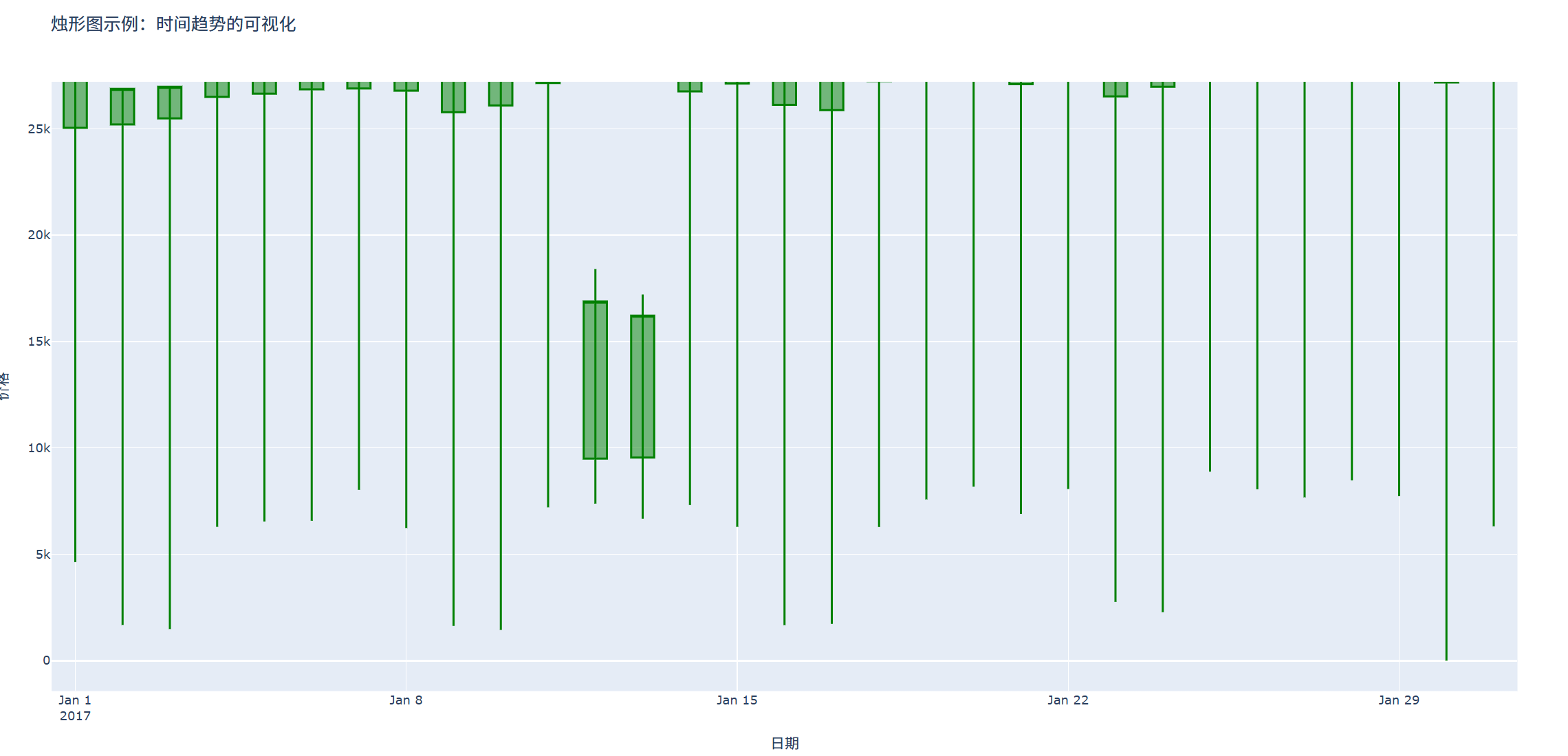
注意事项
(1)数据的时间周期:烛形图适用于具有明确时间段的价格数据。选择合适的时间间隔(如日、小时、分钟)非常重要。
(2)确保数据的完整性:烛形图的有效性依赖于数据的准确性和完整性,包括时间、开盘、最高、最低、收盘等字段。
(3)图形的清晰性:在绘制烛形图时,要确保颜色区分明显,以便用户能够清晰地识别价格的涨跌。
变体
a 增加移动平均线
单纯的蜡烛图显示价格波动有时显得杂乱,特别是在价格波动较大的情况下。添加移动平均线(如短期和长期的移动平均线)可以帮助平滑数据,便于识别整体的趋势方向。
实现代码和结果如下:
import pandas as pd
import plotly.graph_objects as go
# 读取用户上传的 CSV 文件
file_path = '(ch-3.3.1)subscribers.csv'
data = pd.read_csv(file_path)
# 将日期列转换为日期类型
data['Date'] = pd.to_datetime(data['Date'], format='%m-%d-%Y')
# 按日期排序数据
data_sorted = data.sort_values(by='Date')
# 假设数据列(可以根据实际情况调整)
# 订阅者(开盘价)、覆盖范围(最高价)、项目浏览量(最低价)
# 用来做简单的蜡烛图展示
# 创建蜡烛图
fig = go.Figure(data=[go.Candlestick(
x=data_sorted['Date'],
open=data_sorted['Subscribers'], # 假设订阅者是开盘价
high=data_sorted['Reach'], # 假设覆盖范围是最高价
low=data_sorted['Item Views'], # 假设项目浏览量是最低价
close=data_sorted['Subscribers'] + data_sorted['Reach'], # 假设收盘价是某种组合
increasing_line_color='green', # 上涨时线条颜色
decreasing_line_color='red', # 下跌时线条颜色
)])
# 增加移动平均线(MA)
data_sorted['MA20'] = data_sorted['Subscribers'].rolling(window=20).mean()
fig.add_trace(go.Scatter(
x=data_sorted['Date'],
y=data_sorted['MA20'],
mode='lines',
name='20日移动平均',
line=dict(color='blue')
))
# 设置布局和标题
fig.update_layout(
title='蜡烛图与移动平均线:时间趋势的可视化',
xaxis_title='日期',
yaxis_title='价格',
showlegend=True,
xaxis_rangeslider_visible=False, # 隐藏底部的滑块
yaxis2=dict(
title='成交量',
overlaying='y',
side='right',
showgrid=False
)
)
# 显示图形
fig.show()
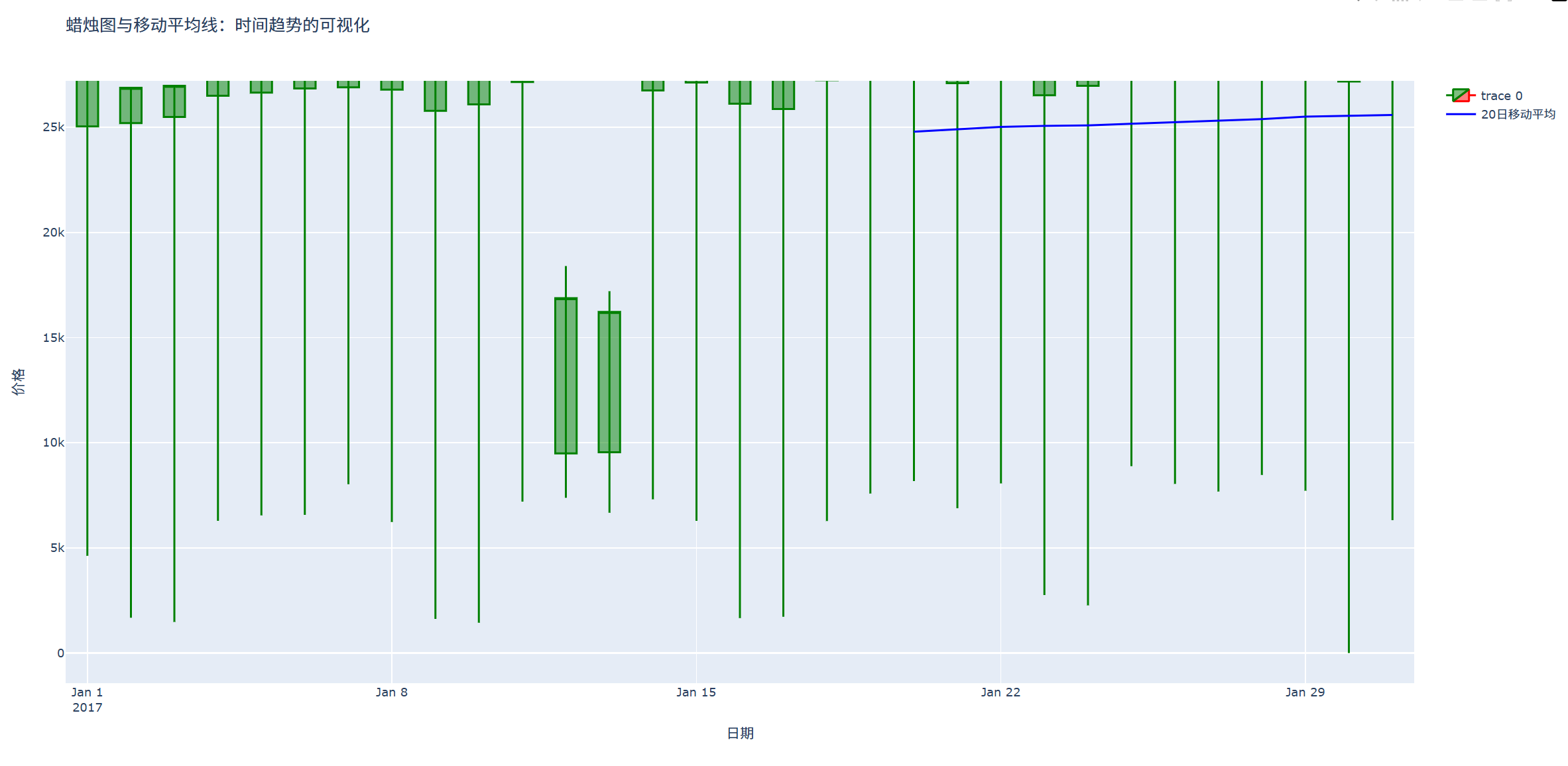
b 动态蜡烛图
特点:
动态蜡烛图提供了交互式功能,用户可以拖动、缩放并查看特定时间段的数据。
适用于大数据集和需要实时更新的数据,用户可以自由地浏览数据,查看不同时间段的市场趋势。
实现代码和结果如下:
import pandas as pd
import plotly.graph_objects as go
# 读取用户上传的 CSV 文件
file_path ='(ch-3.3.1)subscribers.csv'
data = pd.read_csv(file_path)
# 将日期列转换为日期类型
data['Date'] = pd.to_datetime(data['Date'], format='%m-%d-%Y')
# 按日期排序数据
data_sorted = data.sort_values(by='Date')
# 创建动态蜡烛图
fig = go.Figure(data=[go.Candlestick(
x=data_sorted['Date'],
open=data_sorted['Subscribers'],
high=data_sorted['Reach'],
low=data_sorted['Item Views'],
close=data_sorted['Subscribers'] + data_sorted['Reach'],
increasing_line_color='green',
decreasing_line_color='red',
)])
# 设置布局
fig.update_layout(
title='动态蜡烛图:时间趋势的可视化',
xaxis_title='日期',
yaxis_title='价格',
showlegend=False,
xaxis_rangeslider_visible=True, # 显示底部的滑块
)
# 显示图形
fig.show()
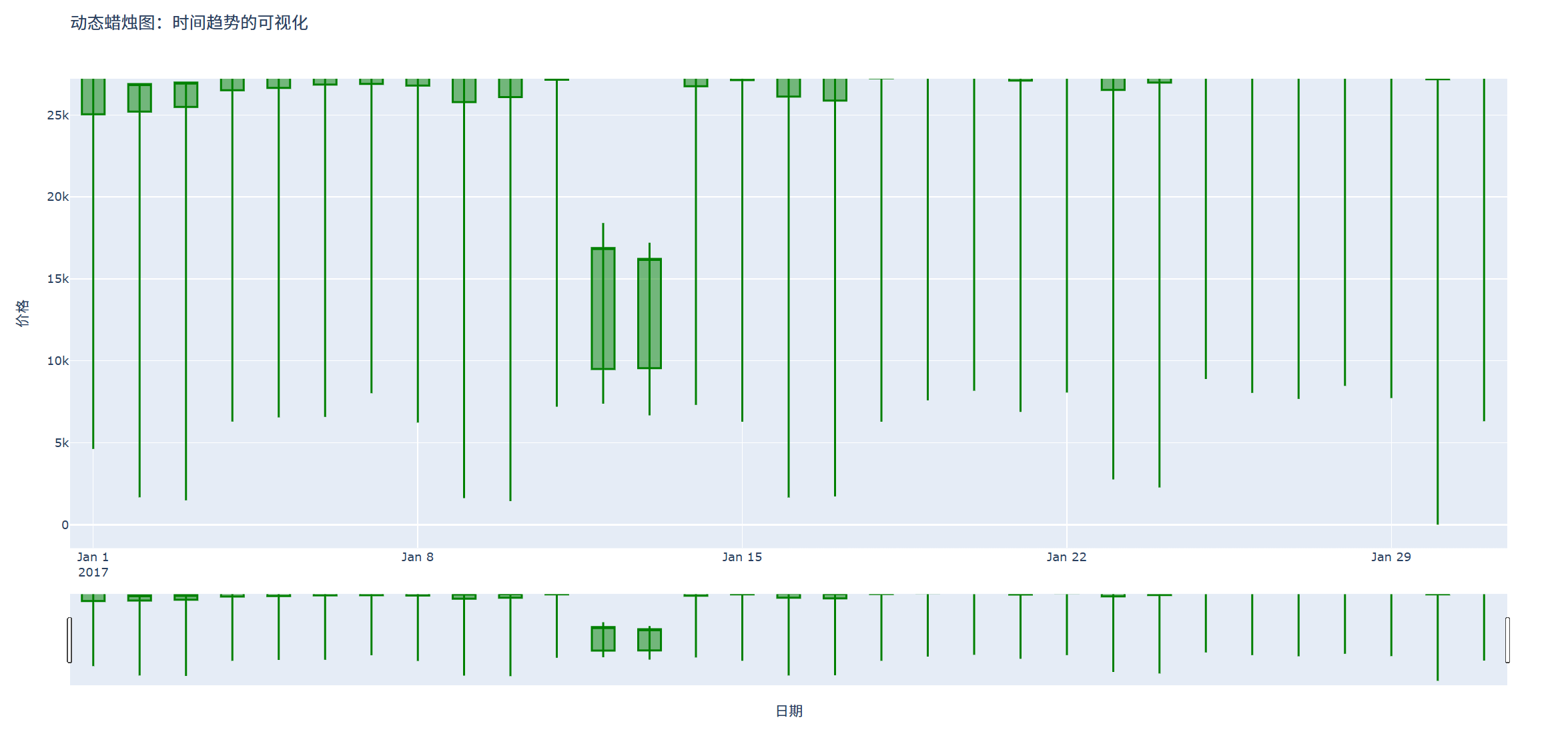

















 697
697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









