







前言
前面讲了结构体的概念,定义,赋值,访问等知识,本节内容小编将讲解结构体的内存大小的计算以及通过结构体实现位段,话不多说,直接上干货!!!
1.结构体内存对齐
说到计算结构体的大小,就要了解结构体内存对齐原则。
结构体内存对齐是指在内存中存储结构体变量时,根据结构体成员的类型和大小,按照一定的规则进行内存对齐,以提高内存访问效率。
1.1对齐规则
1. 结构体的第一个成员对齐到和结构体变量起始位置偏移量为0的地址处2. 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。对齐数 = 编译器默认的一个对齐数与该成员变量大小的较小值。- VS 中默认的值为 8- Linux中 gcc 没有默认对齐数,对齐数就是成员自身的大小3. 结构体总大小为最大对齐数(结构体中每个成员变量都有一个对齐数,所有对齐数中最大的)的整数倍。4. 如果嵌套了结构体的情况,嵌套的结构体成员对齐到自己的成员中最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体中成员的对齐数)的整数倍。
举例说明
struct S1
{
char c1;//1
int i;//4
char c2;//1
};
printf("%d\n", sizeof(struct S1));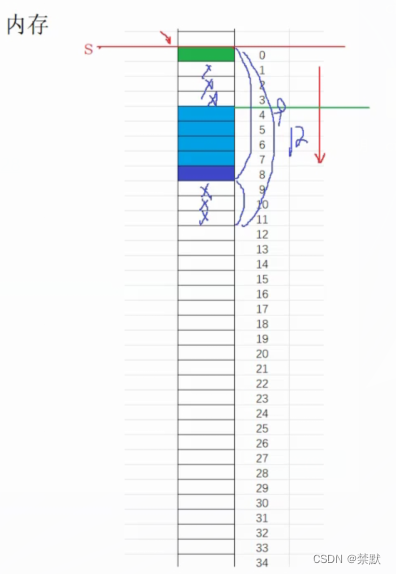 12字节为最大对齐数4的倍数,所以结构体大小为12
12字节为最大对齐数4的倍数,所以结构体大小为12
例2
struct S3
{
double d;
char c;
int i;
};
printf("%d\n", sizeof(struct S3));16个字节刚好为最大对齐数(double)的整数倍,所以结构体大小为16

例3(结构体嵌套)
struct S4
{
char c1;
struct S3 s3;
double d;
};
printf("%d\n", sizeof(struct S4));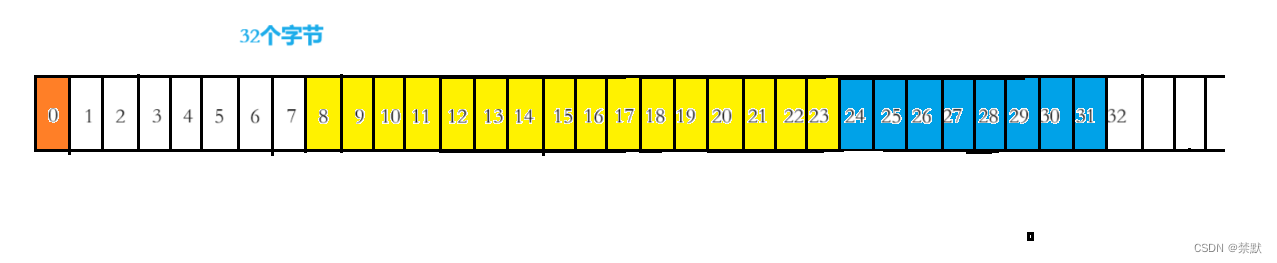
32字节为最大对齐数8的倍数,所以结构体大小为32
1.2为什么存在内存对齐
struct S1
{
char c1;//1
int i;//4
char c2;//1
};
struct S2
{
char c1;//1
char c2;//1int i;//4
};
printf("%d\n", sizeof(struct S1));printf("%d\n", sizeof(struct S2));
1.3修改默认对齐数
#pragma 这个预处理指令,可以改变编译器的默认对齐数。
#include <stdio.h>
#pragma pack(1)//设置默认对⻬数为1
struct S
{
char c1;
int i;
char c2;
};
#pragma pack()//取消设置的对⻬数,还原为默认
int main()
{
//输出的结果是什么?
printf("%d\n", sizeof(struct S));
return 0;
}2.结构体传参
#include <stdio.h>
struct S
{
int data[1000];
int num;
};
struct S s = {{1,2,3,4}, 1000};
//结构体传参
void print1(struct S s)
{
for(int i=0;i<4;i++){
printf("%d ",s.data[i]);
}
printf("\n%d\n", s.num);
}
//结构体地址传参
void print2(struct S* ps)
{
for(int i=0;i<4;i++)
printf("%d ",ps->data[i]);
printf("\n%d\n", ps->num);
}
int main()
{
print1(s); //传结构体
print2(&s); //传地址
return 0;
}
函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。如果传递一个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性能的下降。
3.结构体实现位段
3.1什么是位段
位段(Bit-fields)是一种在C语言中用于节省内存的技术,它允许程序员定义一个结构体或联合体中的成员变量,这些成员变量的大小以位为单位,而不是以字节为单位。位段可以用来表示那些只需要少量位来存储的数据,例如标志位或者状态位。
位段的定义方式是在结构体或联合体中使用冒号(:)指定成员变量所占用的位数。
位段的声明和结构是类似的,有两个不同:1. 位段的成员必须是 int、unsigned int 或signed int ,在C99中位段成员的类型也可以选择其他类型。2. 位段的成员名后边有一个冒号和一个数字。
struct A
{
int _a:2;//占2个两个bit位
int _b:5;
int _c:10;
int _d:30;
};
位段式结构中的位可以理解二进制位
在C语言中,位段的大小取决于编译器和硬件平台的具体实现。通常,位段的大小是按照字节对齐的,但是位段内部的位数是按照定义的位数来分配的。
上述位段占了47位,对齐6个字节,也就是48位,但是用sizeof测试时出来是8字节
在大多数系统中,位段会按照最接近的字节边界对齐。由于这个结构体总共占用了47位,它可能会被对齐到6个字节(48位),因为这是最接近47位的字节数,并且可以容纳所有的位段。
然而,位段的确切大小和对齐方式取决于编译器和硬件平台的具体实现。在某些系统上,如果位段不能恰好填充到一个字节,编译器可能会分配额外的位来填充到下一个字节边界。此外,如果位段的大小超过了单个整数类型(通常是32位或64位)的位数,编译器可能会将它们分割到多个整数中。
3.2位段的内存分配
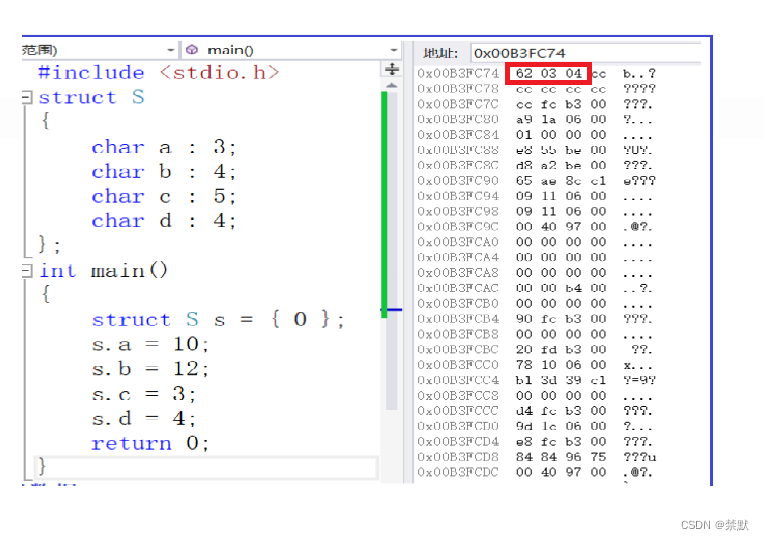
1. 位段的成员可以是 int unsigned int signed int 或者是 char 等类型2. 位段的空间上是按照需要以4个字节( int )或者1个字节( char )的方式来开辟的。3. 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段。
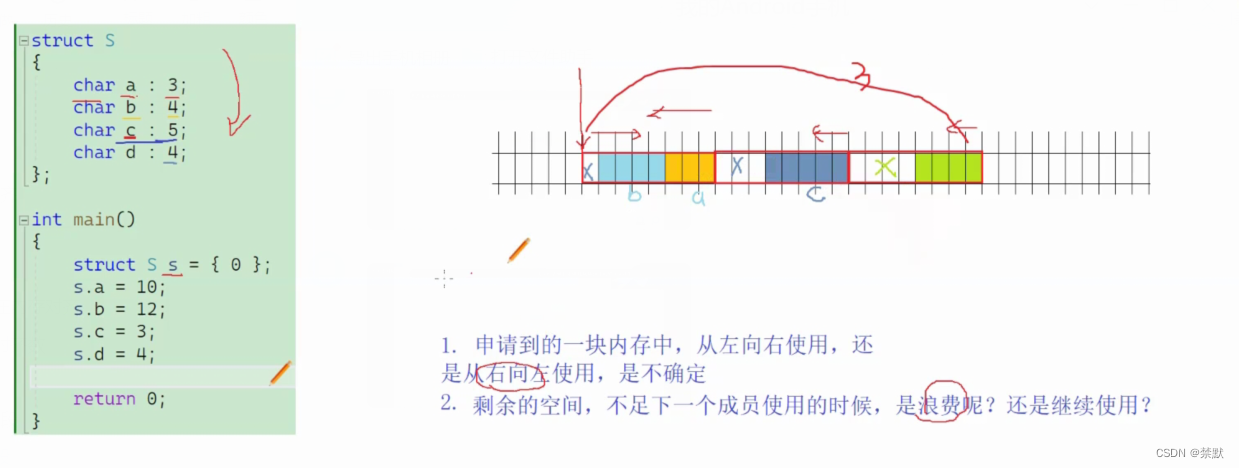
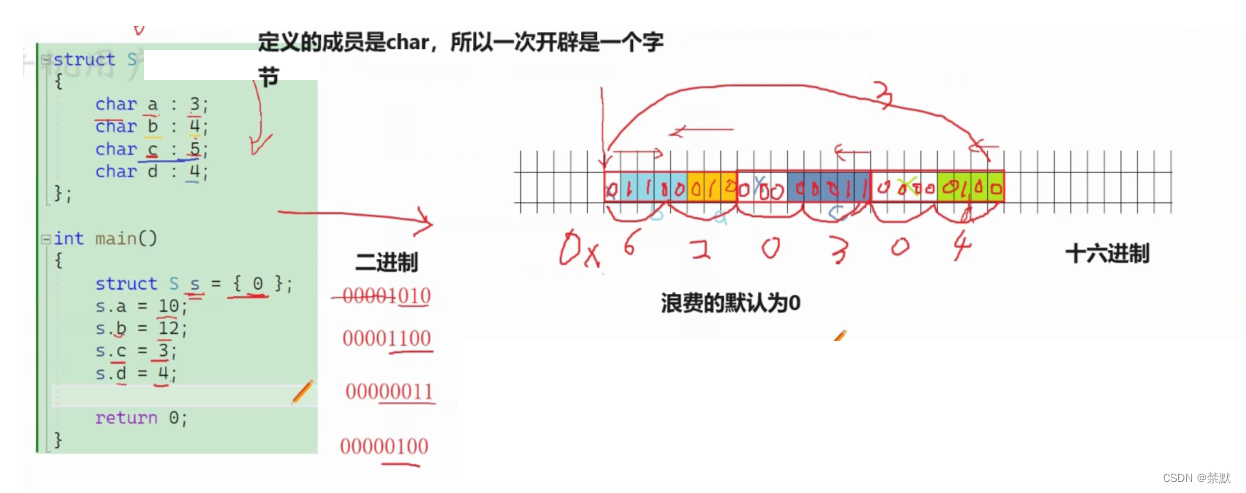
struct S
{
char a:3;
char b:4;
char c:5;
char d:4;
};
struct S s = {0};
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;接下来通过画图来看内存空间的开辟分配
1.在申请的一块内存中,bit位是从左到右,还是从右到左使用,是不确定的,VS是从右到左
2.剩余的空间,不足下一个成员使用的时候,是浪费?还是继续使用?VS采取浪费
ok,回到最上面那个位段求大小
struct A
{
int _a:2;//占2个两个bit位
int _b:5;
int _c:10;
int _d:30;
};
一次性申请4个字节,第一次用17个bit位,剩余15个不够用,根据VS的规则,采取浪费,所以再次申请4个字节存取剩下的_d数据。
即该位段大小为8

3.3位段的跨平台问题
1. int 位段被当成有符号数还是无符号数是不确定的。2. 位段中最大位的数目不能确定。(16位机器最大16,32位机器最大32,写成27,在16位机器会出问题。eg:32位或者64位int的长度占4个字节,16位int是2个字节3. 位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义。4. 当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是舍弃剩余的位还是利用,这是不确定的。
3.4位段的应用
IP数据报的格式,我们可以看到其中很多的属性只需要几个bit位就能描述,这里使用位段,能够实现想要的效果,也节省了空间,这样网络传输的数据报大小也会较小一些,对网络的畅通是有帮助的。
3.5位段使用的注意事项
struct A {
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
int main() {
struct A sa = {0};
scanf("%d", &sa._b);//这是错误的
//正确的⽰范
int b = 0;
scanf("%d", &b);
sa._b = b;
return 0;
}下面是搜集的位段注意事项的其他总结
1. 可移植性问题:位段的行为和大小可能因编译器和硬件平台而异。因此,位段不具有可移植性,应该避免在需要跨平台兼容的代码中使用位段。
2. 对齐和大小:位段的对齐方式和大小取决于编译器的实现。编译器可能会将位段对齐到字节边界,这可能导致额外的填充位。因此,不应该假设位段的确切大小,除非编译器文档明确说明了位段的行为。
3. 位段类型:位段通常使用 `unsigned int` 或 `int` 类型定义,但编译器可能会允许其他整数类型。然而,使用非标准类型可能会降低代码的可移植性。
4. 位段操作:位段的操作不如普通变量直观,因为它们涉及到位的操作。在访问和修改位段时,需要小心处理位操作,以避免错误。
5. 位段顺序:位段在内存中的存储顺序可能因编译器而异。有些编译器可能按照位段的定义顺序存储,而其他编译器可能按照相反的顺序存储。
6. 位段跨越字节边界:如果一个位段的大小超过了单个字节的位数,它将会被分割到两个字节中。这可能会导致难以预测的内存布局。
7. 位段的符号性:如果使用 `int` 类型定义位段,位段可能是带符号的。这意味着位段的最高位可能被解释为符号位,这可能会导致意外的行为。为了确保位段是无符号的,应该使用 `unsigned int` 类型。
8. 位段的访问:在某些平台上,访问位段可能比访问普通变量更慢,因为位段需要额外的位操作。
9. 位段的初始化和赋值:位段的初始化和赋值可能需要特殊的位操作,因为它们不是以字节为单位进行操作的。
10. 位段的限制:位段不能用于数组或指针,也不能用于结构体或联合体的嵌套定义。
在使用位段时,应该仔细考虑这些注意事项,并确保代码的可读性、可维护性和正确性。如果可能,应该考虑使用其他技术,如位掩码或位操作函数,来代替位段,以提高代码的可移植性和可读性。















 1456
1456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









