






以下仅是一篇学习笔记,内容请辩证看待。如有错误,欢迎指出。
计算图简介:
我们首先先了解一下计算图的概念:
计算图是一种将运算过程用图形形象化表示出来的方法。其中通常用节点表示变量,用边表示数学操作/运算,与我们在自动控制原理中学过的信号流图的基本原理有异曲同工之妙。下图是一个计算图的简单例子:
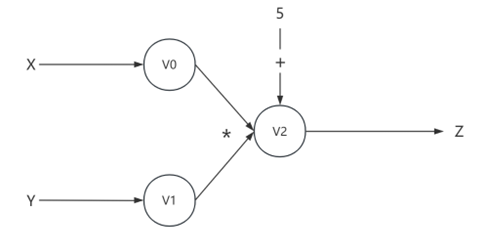 、
、
我们可以将计算机的每一个操作理解为上图的一共节点,计算机中的任何一步操作都可以使用计算图来表示,但是循环结构比较特殊:计算图是由节点到子节点依次连接的,并没有办法做到循环,所以需要对循环结构进行展开。这里不做过多介绍。
TensorFlow静态计算图
在使用TensorFlow时,我们需要在训练之前构建一个神经网络,在构建结束后才能进行训练和相关的数据读取。在神经网络训练的过程中网络或者说计算图是不会发生任何变化的,这也就是所谓的“静态计算图”。
静态计算图在调试和更改上有一定的困难,但是这也为神经网络的定向优化带来一定的方便,并且在计算的效率上有一定的优势。
经过多年的发展,TensorFlow 经历了从静态图(Graph Mode)到动态图(Eager Mode)的演进过程。可以通过@tf.function 装饰器的引入,实现动态代码向静态图的自动转换。
Pytorch动态计算图
Pytorch使用的是动态构建计算图的策略。在程序运行之前,不需要构建神经网络,我们只需要使用forward函数将网络向前推进,而具体的神经网络构建和反向传播的过程则由程序自动完成。当我们将forward函数中的内容修改后,神经网络的结构也就被相应修改了,这就是“动态计算图”。关于Pytorch是如何在代码层面上自动构建计算图的,请参考这篇文章:一文详解pytorch的“动态图”与“自动微分”技术
动态计算图为开发和调试带来了方便,但是相对的动态图难以提前优化,可能影响大规模部署效率,因为每次迭代后动态图自动释放。
动态图更符合人类思维模式,降低了认知负荷,但可能牺牲部分运行时效率。静态图通过预编译优化获得性能提升,但增加了调试复杂度。这一差异本质上反映了"开发效率"与"运行效率"的经典权衡。
TensorFlow和Pytorch的具体框架对比
除了上述的在核心的计算图构建层面有一定的差别,两者的框架设计哲学也各有侧重。
TensorFlow框架设计
TensorFlow 的架构可分为 5 个层级,从底层硬件支持到高层应用接口协同工作:
- 设备管理层(Device Layer):支持 CPU、GPU、TPU 等硬件资源调度。
- 计算图执行引擎(Graph Execution Engine):静态图优化与分布式计算。
- 自动微分与梯度计算(Gradient Tape):动态跟踪操作并计算梯度。
- 高级 API(Keras、Estimator):简化模型构建与训练流程。
- 工具链与部署(TensorFlow Lite/Serving):跨平台模型部署。
Pytorch框架设计
PyTorch 的架构可以划分为 4 个核心层级,从底层到高层协同工作:
- 底层张量库(C++层):基于高性能 C++ 实现张量计算与 GPU 加速。
- 自动求导引擎(Autograd):动态构建计算图并跟踪梯度。
- 神经网络模块(Python 接口层):通过 torch.nn 提供高级 API。
- 生态工具链:数据加载、分布式训练、部署工具等。
显式与声明式的设计
PyTorch 的面向对象范式
PyTorch 强制开发者显式定义网络结构,这种设计具有显著的教学价值:
- 参数可见性:所有可训练参数必须通过 nn.Parameter 显式声明,避免了隐式变量带来的混淆。
- 前向传播透明化:forward 方法的强制实现要求开发者清晰定义数据流动路径。
- 模块化组合:通过 nn.Sequential 或自定义模块组合,支持复杂的模型架构设计。
高级架构示例(残差连接):
class ResidualBlock(nn.Module):
def __init__(self, in_channels):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(in_channels, in_channels, kernel_size=3, padding=1)
def forward(self, x):
identity = x
out = torch.relu(self.conv1(x))
out = self.conv2(out)
out += identity # 显式的残差连接
return torch.relu(out)
TensorFlow 的多层次抽象
TensorFlow通过 Keras API 提供了不同层次的建模抽象:
- Sequential API:面向线性结构的快速建模,适合教学和原型开发。
- Functional API:支持多输入/输出等复杂拓扑,兼顾灵活性和简洁性。
- Model Subclassing:完全自定义控制,接近 PyTorch 的灵活性。
Functional API 的典型应用(多模态输入):
# 定义双输入模型
image_input = tf.keras.Input(shape=(256, 256, 3), name="image")
text_input = tf.keras.Input(shape=(100,), name="text")
# 分支处理
x1 = tf.keras.layers.Conv2D(32, 3)(image_input)
x2 = tf.keras.layers.Dense(64)(text_input)
# 特征融合
merged = tf.keras.layers.concatenate([x1, x2])
outputs = tf.keras.layers.Dense(10)(merged)
model = tf.keras.Model(inputs=[image_input, text_input], outputs=outputs)
训练流程设计:控制粒度与抽象层次的权衡
训练循环控制机制
PyTorch采用显式控制的控制机制。PyTorch的这种"完全暴露"的设计理念,将训练过程的每个环节都交由开发者直接控制。这种设计具有以下技术特性:
- 梯度管理透明化:要求显式调用zero_grad()清除历史梯度,避免梯度累积错误
- 损失计算分离:需手动实例化损失函数,明确区分前向传播与损失计算阶段
- 优化步骤可见:参数更新作为独立操作存在
这种设计虽然增加了代码量,但为以下高级场景提供了必要支持:
# 自定义梯度裁剪的复杂训练场景
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(inputs)
# 多任务损失加权求和
loss1 = criterion1(outputs, targets1)
loss2 = criterion2(outputs, targets2)
total_loss = 0.7*loss1 + 0.3*loss2
total_loss.backward()
# 手动梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
# 自定义学习率调度
scheduler.step(total_loss)
而TensorFlow采用层次化的抽象设计。通过Keras API构建了多层次的训练抽象,分为三种模式:
- 全自动模式:model.fit()封装标准训练流程,内置进度条、验证集评估等
- 半自动模式:GradientTape上下文管理器提供微分计算能力
- 完全手动模式:可结合tf.Graph实现底层控制
这种分层设计显著降低了入门门槛:
# 使用内置回调的自动化训练
callbacks = [
tf.keras.callbacks.EarlyStopping(patience=3),
tf.keras.callbacks.ModelCheckpoint('best_model.h5')
]
model.fit(
train_dataset,
validation_data=val_dataset,
epochs=100,
callbacks=callbacks # 自动化集成高级功能
)
这两种框架在设计哲学有很大区别:PyTorch的"白盒"设计赋予研究者最大控制权,适合需要定制训练逻辑的前沿研究,而TensorFlow的"渐进式暴露"设计兼顾易用性与灵活性,符合工程实践中的需求分层原则。
分布式训练实现
PyTorch通过torch.distributed模块提供多种并行策略:
- 数据并行:DistributedDataParallel实现高效参数同步
- 模型并行:原生支持将模型拆分到不同设备
- 弹性训练:torch.elasti支持动态节点调整
典型实现模式:
# 多机多卡训练初始化
torch.distributed.init_process_group(backend='nccl')
model = nn.parallel.DistributedDataParallel(model, device_ids=[local_rank])
# 自动处理数据分片
train_sampler = torch.utils.data.distributed.DistributedSampler(dataset)
dataloader = DataLoader(dataset, sampler=train_sampler)
TensorFlow通过tf.distribute模块提供更高级的抽象:
- 策略抽象:MirroredStrategy(单机多卡)、MultiWorkerMirroredStrategy(多机)等
- 无感集成:相同代码可无缝切换不同分布式模式
- 优化通信:自动选择NCCL或RING通信协议
实现示例:
# 多GPU训练只需添加策略上下文
strategy = tf.distribute.MirroredStrategy()
with strategy.scope():
model = build_model() # 模型构建在策略范围内
model.compile(optimizer='adam', loss='mse')
# 数据自动分片
train_dataset = strategy.experimental_distribute_dataset(train_dataset)
model.fit(train_dataset, epochs=10)
PyTorch与TensorFlow在训练流程设计上呈现显著差异,前者强调灵活性和控制力,后者注重易用性和抽象层次。
Mindspore架构介绍
MindSpore是华为公司于2020年3月正式开源的全场景AI计算框架。作为中国首个自主研发的产业级深度学习框架,MindSpore原生支持昇腾(Ascend)处理器,同时兼容GPU、CPU等其他硬件平台,在AI芯片国产化替代和自主可控技术生态建设中具有战略意义。
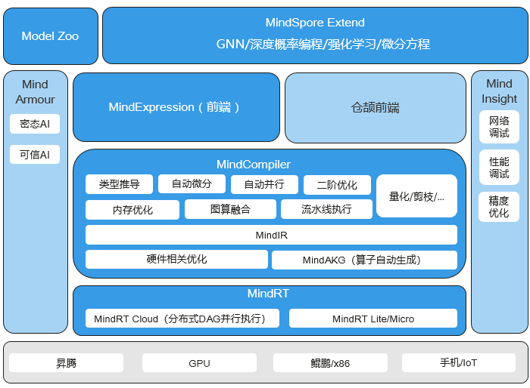
华为MindSpore架构图
MindSpore的具体架构说明可以参考华为官方的白皮书:MindSpore:一种全场景覆盖的深度学习计算框架
Mindspore区别于PyTorch和TensorFlow两者的架构的一个显著特点是,MindSpore支持动态图和静态图两种模式,并且支持使用相同的API表达。并且无论是使用动态图还是静态图,两者都具有相同的底层微分机制。这为整个架构带来了更多的灵活性,方便于适用在不同的场景之中。

Pytorch TensorFlow Mindspore各方面对比
为了更直观地表达出调查的结果,我们给出了如下表格来表示三者的区别。
| 特性 | MindSpore | PyTorch | TensorFlow |
| 执行模式 | 动静统一 | 动态图优先 | 静态图优先 |
| 自动并行 | 全自动策略 | 半自动配置 | 手动配置 |
| 部署方式 | 端云统一格式 | TorchScript | SavedModel |
| 硬件支持 | 昇腾原生优化 | CUDA生态完善 | TPU深度集成 |
| 隐私计算 | 内置联邦学习 | 依赖第三方库 | TF Privacy扩展 |
| 科学计算 | 原生支持 | 有限支持 | 通过扩展实现 |
技术特色对比
| 特性 | TensorFlow | PyTorch | MindSpore |
| 计算图优化 | 静态图全局优化 | 动态图即时执行 | 动静统一 |
| 分布式训练 | 多策略分布式 | DDP/FSDP 数据并行 | 自动并行+梯度聚合优化 |
| 硬件加速 | TPU/GPU 优化(CUDA/XLA) | GPU 优化(CUDA/cuDNN) | 昇腾 NPU 原生支持 |
| 部署优化 | TF Lite/Serving 量化与剪枝 | LibTorch/TorchServe 轻量化 | MindIR 跨平台推理 |
优化方向对比
| 应用场景 | TensorFlow | PyTorch | MindSpore |
| 应用领域 | 工业 | 学术 | 国产化环境(如昇腾芯片、华为云) |
| 项目需求 | 需要TPU加速或谷歌云生态的项目 | 需要灵活调试或社区最新模型 | 端边云协同场景(如物联网、边缘AI) |
应用场景对比

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









