






Transformer再出新花样!斯坦福通过把Transformer与特征融合结合,实现了预测误差直降83.4%的显著效果!
主要在于:Transformer擅长捕捉长距离信息。而特征融合,则能够引入局部细节、不同层次的视觉特征等多样化的信息。当两者结合,模型便能同时兼顾全局和局部信息,从而提升准确性和泛化性能,并降低计算成本!
因此,其在各大顶会也备受青睐!像是CVPR上用于多光谱目标检测的CAFF-DINO模型;NeurIPS上的3D重建模型GTA……
为让大家能够紧跟领域前沿,快速get到发文精髓,我给大家准备了12篇必读论文和源码。、
论文原文+开源代码需要的同学看文末
Hybrid CNN-Transformer Feature Fusion for Single Image Deraining
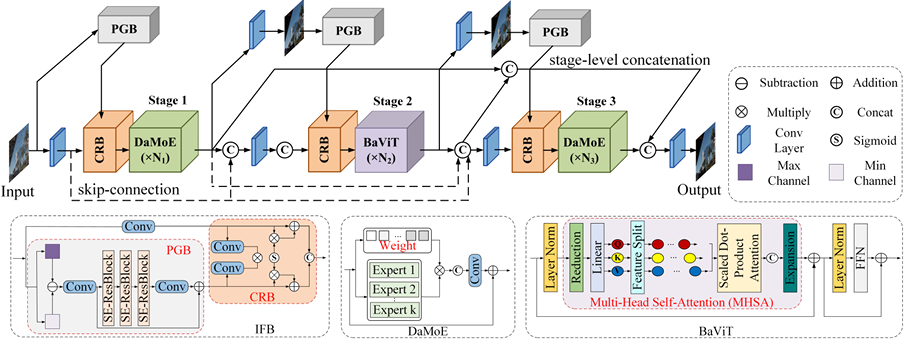
内容:文章介绍了一种新型的轻量级混合CNN-Transformer特征融合网络,用于单图像去雨。该网络通过结合CNN和Transformer架构的优势,逐步地进行特征融合,以改善图像去雨的效果。CNN阶段利用退化感知的混合专家模块强调局部雨滴分布特征,而Transformer阶段则使用背景感知的视觉Transformer模块来补充图像的全局纹理恢复和结构保持。此外,文章还提出了一个交互式融合分支来进一步优化去雨结果,并通过广泛的评估证明了HCT-FFN的有效性和扩展性。
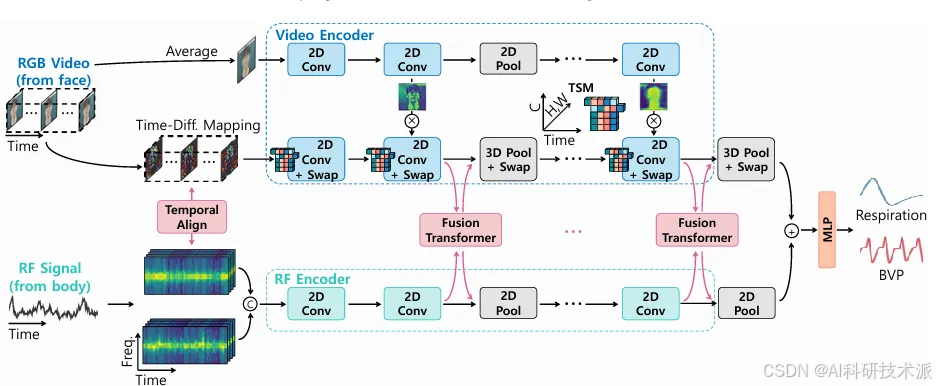
Fusion-Vital: Video-RF Fusion Transformer for Advanced Remote Physiological Measurement
内容:文章介绍了一种名为Fusion-Vital的新型生命体征监测模型,该模型通过结合视频和射频(RF)传感器捕获的深度RGB和RF特征来提高远程生理测量的性能。Fusion-Vital利用成对输入格式和基于Transformer的融合策略来有效地对齐和适应性地整合多模态特征,从而在动态场景下进行有效的特征融合。文章还基于一个新收集和发布的同步视频-RF传感器的远程生理数据集进行了全面实验,证明了融合方法在多个方面优于以往的单传感器基线。
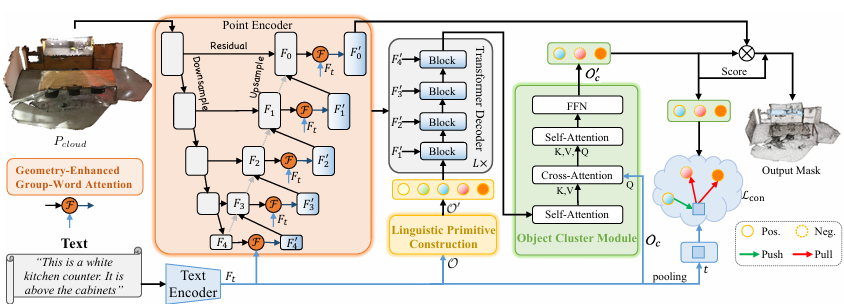
RefMask3D: Language-Guided Transformer for 3D Referring Segmentation
内容:文章介绍了一个名为RefMask3D的模型,这是一个基于Transformer的语言引导的3D分割网络,用于处理3D场景中的指代表达分割任务。该模型旨在理解自然语言描述,并将其转化为3D空间中的精确分割掩码,从而实现对3D对象或区域的语义分割。简而言之,RefMask3D利用Transformer架构来桥接自然语言描述和3D视觉数据,以实现更准确的3D对象分割。
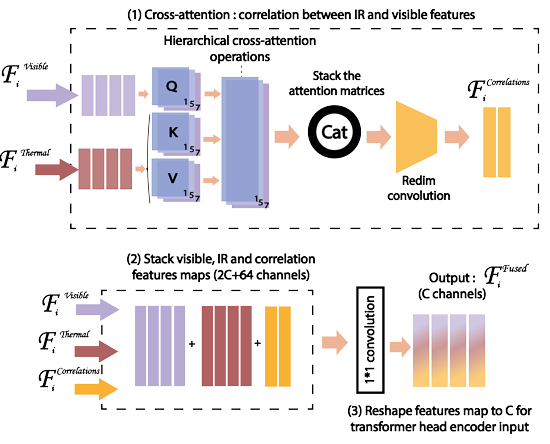
CAFF-DINO: Multi-spectral object detection transformers with cross-attention features fusion
内容:文章介绍了一种名为CAFF-DINO的多光谱目标检测Transformer模型,该模型通过交叉注意力特征融合技术,有效地结合了不同光谱数据,以提高目标检测的准确性和鲁棒性。简而言之,CAFF-DINO利用先进的Transformer架构和特征融合策略,优化了多光谱数据在目标检测任务中的性能。
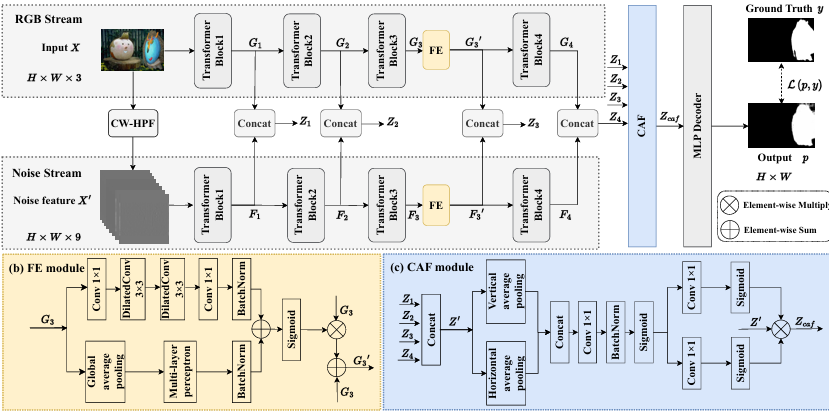
Effective Image Tampering Localization via Enhanced Transformer and Co-attention Fusion
内容:文章提出了一个名为EITLNet的有效的图像篡改定位网络,该网络基于双分支增强型Transformer编码器和基于坐标注意力的特征融合构建。EITLNet设计了特征增强模块来提升Transformer编码器的特征表示能力,并通过坐标注意力基融合模块在多尺度上有效地融合RGB和噪声流特征。广泛的实验结果验证了该方案在各种基准数据集上达到了最先进的泛化能力和鲁棒性。代码将在GitHub上公开。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【变形特征】获取完整论文
👇

















 4473
4473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









