







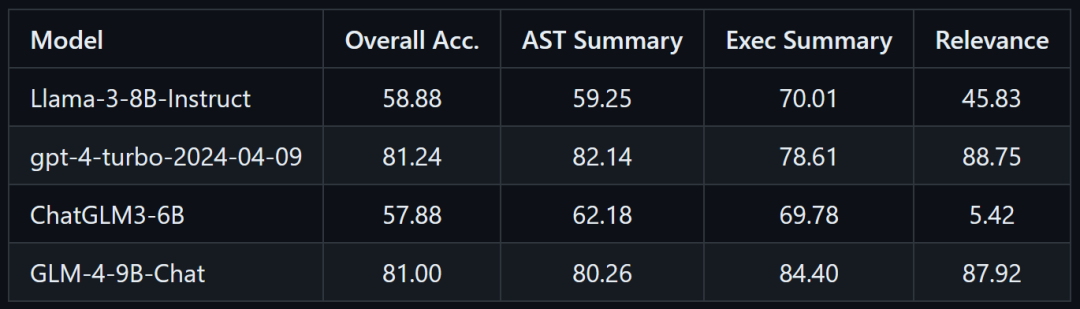
智谱公布的GLM-4-9B基于BFCL榜单的工具调用能力测试结果
©作者|格林
来源|神州问学
在智谱最新开源的GLM-4-9B-Chat中,其工具调用能力在BFCL(伯克利函数调用排行榜)榜上获得了超高的总BFCL分,和gpt-4-turbo-2024-04-09几乎不相上下。在榜单中,还提到了AST总分以及Exec总分两个得分,那么这两个得分有什么含义,又是如何计算的呢?
引言
智能体应用开发逐渐成为各大AI厂商应用开发平台不可或缺的一部分,不同平台会提供各类型的插件来拓展智能体的能力范围。随着能力的提升,模型能够完成并胜任的任务种类越发丰富,其中就包括了函数调用(Function Calling)的能力。我们可以看到,现在国内外许多模型厂商都在强化自家模型函数调用的能力,包括智谱最新发布的GLM-4-9B-Chat、百川的Baichuan4、阿里的Qwen系列、上海人工智能实验室的InternLM2等等。通过函数调用,模型能够用于作为智能体应用的核心驱动,成为自然语言到结构化工具调用之间的桥梁。然而,如何评价模型函数调用的能力,通过什么样的方法进行评测,目前业界依旧缺少相关的榜单和方法。前段时间,加州伯克利大学的研究团队公布了其评测模型函数调用能力的方法,以及对应的榜单。在这篇文章中,我们将解析这种评测方式,以及对应评测数据集的构建。
函数调用的大致工作流程
首先让我们回顾一下函数调用模型的原理:函数调用模型收到用户的提问(Query)以及函数列表(Function List),输出包含所选函数以及输入参数的JSON对象,随后在环境中执行这个JSON并获得对应函数输出参数,最终通过模型与用户提问进行整合并以自然语言的方式进行输出。
按照OpenAI的描述,函数调用的基本步骤顺序如下:
1. 基于用户问题和在“函数参数”中定义的一系列函数调用模型;
2. 模型选择调用一个或多个函数;模型将基于定义的函数输出字符串化 JSON 对象(可能会产生幻觉);
3. 在代码中将字符串解析为 JSON,并使用模型所写的参数调用该函数;
4. 通过将函数响应作为新消息附加来再次调用模型,并让模型将结果汇总回给用户;
函数调用模型最主要的是找到用户问题与选取函数+输入参数之间的对应关系,通过将用户的自然语言转换为API或者Python 函数之类的工具调用,让模型能够从外部获得对应的信息(例如从外部数据平台查询企业信息),或者是对外部环境产生影响(例如使用send_email函数发送邮件)等等。
Berkeley在函数调用方面的研究历史
在这次的AI浪潮中,加州大学伯克利分校一直在带给我们惊喜,从之前的Vicuna、Chatbot Arena、CRATE(Coding RAte reduction TransformEr)白盒大模
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 921
921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









