






基于多层感知机的最小二乘优化定位模型
在智能化时代,基于位置的服务逐渐成为人们关注的热点,其中室内定位技术在城市场景中应用更为广泛。基于超频宽带 (UltraWideband,UWB) 的技术通过发送纳秒级的极窄脉冲来传输数据,具有传输功耗低,带宽大,传输能力强等优点,为室内定位技术的研究热点。但在复杂的室内环境下,UWB的信号由于时间延时、多路径效应等因素不可避免地产生测量误差,因而信号干扰下的UWB精确定位成为了亟需解决的问题。
对于任务一,首先分析给定的数据文件格式,提取所需的测量值数据,并按要求转换为二维表格式。之后通过设定判定准则,重复值、缺失值、异常值、相似值等除冗余及无用数据,得到最终所需的数据,其中重复值为不同组之间四个锚点观测距离完全相同的数据值;缺失值为某一锚点观测距离缺失的数据;异常值为3σ 准则以外的数据;并依据设定的预测精度(1cm)建立相似度判定准则,通过对数据进行相似度度量及聚类,保留可信度高的数据,删除相似数据。
对于任务二,首先将“锚点定位”问题抽象建模为最小二乘拟合问题。针对正常数据的定位问题,本文提出了基于多层感知机的最小二乘优化定位模型(LSMLP),将该最小二乘问题建模为一个优化问题,并使用神经网络进行解决。
通过设计神经网络的输入、输出、损失函数以及网络结构,实现了初步的位置预测。对已生成的若干预测值,使用 Kmeans 算法进行聚类和选择,保留一致性较高的结果并进行统计学分析,进一步提高定位精度。为了衡量所提方法的定位有效性和精确性,本文使用了多维度的评价方式,在 x, y 轴上定位的相对误差为3%,3%;在XY平面上定位的RMSE为6.95cm;在三维空间中,定位的RMSE 为 37.04cm。相较于传统数值计算方法,所提方法具有不依赖于初始解、精度高、抗噪声能力强的特点。针对异常数据的定位问题,通过数据可视化分析,做出合理假设:任一时刻最多只有一个基站的信号受到干扰。基于所提假设,本文在LSMLP模型的基础上,提出了置信度赋权的联合定位模型(CECL)。
所提CECL模型通过模拟不同锚点异常的情况,对异常数据进行切片采样,使用 LSMLP 模型得到多种位置估计数据。构建基于交叉熵损失的 Softmax 分类
器,训练位置估计数据,得到其置信度水平,并对估计结果及其置信度进行带权重的聚类,以最大簇的均值和方差作为最终预测。将所提CECL模型在异常数据上进行评估,在x, y 轴的相对误差分别为7%,8%,XY平面定位的RMSE为18.24cm,三维定位的RMSE为46.21cm,在信号传输受到扰的情况下仍能保持一定的精度。![]()
对于任务三,首先分析了所提LSMLP模型的内在特性:本质为最小二乘拟合优化器,通过将实验场景信息编码到损失函数中,设计可微的损失函数来指导网络进行优化,实现了网络结构与实验场景信息的剥离。因此,在解决场景2下的定位问题时,将更新的场景信息重编码到模型中,使用更新后的损失函数对LSMLP进行训练完成任务场景的迁移。由于每个对应靶点的测量数据仅包含一组,为此无法使用任务二所提的聚类方法,因此在数据异常的情况下,提出了加权聚合方法,对不同抽样下得到的预测值,使用置信度进行加权平均,得到最终结果。
对于任务四,首先确定了任务实质为有监督分类问题。为提升分类的性能,本文采用了特征工程、优化器选择、自动机器学习、投票法等方法。在特征工程阶段,利用任务二构建的LSMLP模型,构建观测距离、预测距离、两距离平方差等共计12个维度的特征,极大地挖掘了距离信息的内在表征。选择极限梯度提升算法(XGBoost)作为分类器,并使用基于贝叶斯的自动机器学习技术优化分类器的关键参数。在模型预测阶段,利用集成学习的思想,基于多模型的输出,进行投票获得最终结果。通过以上方法,分类器在测试集精度可达99.26%。任务四所给的测试数据,对应的分类结果为:正常、异常、正常、异常、异常、正常、异常、异常、异常、正常。
对于任务五,首先分析任务二所提正常数据定位模型LS −MLP 与异常数据定位模型CE−CL的关联,对两者进行归纳统一,提出了可同时处理正常数据、异常数据的统一置信度赋权定位框架,并基于该框架得到了靶点的初步运动轨迹。由于任务五中的靶点为运动靶点,故用卡尔曼滤波,考虑靶点的运动因素,结合初步预测结果对动态靶点的运动轨迹进行联合优化。滤波后结果波动较小,轨迹较为平滑。
最后,本文对所提模型的优缺点进行评价,并提出改进建议,介绍了模型的推广前景。
| 关键字:最小二乘 | 多层感知机 | 聚类 | 模型聚合 | 卡尔曼滤波 |
1 . 1 问题背景
伴随着城市的建设和发展,基于位置的服务逐渐成为人们关注的热点。在智能化的时代,位置服务与日常生活密切相关,如车辆导航、人员定位等,这些功能为人们的生产生活提供了便利,也推动了定位技术的不断发展。
定位技术主要分为室外定位和室内定位两种。在室外定位中,卫星定位导航系统(Global Navigation Satellite Syste, GNSS),如美国的GPS、中国的北斗、欧盟的Galileo等,具备在全球范围内提供三维精确定位、授时及测速的能力,能满足大部分室外定位需求,在军事、交通、测绘等领域获得了广泛应用。但在城市场景中,大量的建筑物遮挡和复杂的电磁环境会对卫星信号产生严重干扰,导致定位精度下降或者失效。因此,对于室内定位技术的需求不断增长。
目前,已经出现了多种针对室内定位的技术,比如红外线定位、超声波、蓝牙定位、WIFI定位、射频识别定位(Radio Frequency Identification,RFID)等,但都无法满足室内定位精度高和环境适应性好的要求。而基于超频宽带 (UltraWideband, UWB)的技术通过发送纳秒级的极窄脉冲来传输数据,拥有GHz量级的带宽,具有传输功耗低(仅有几十µW),穿透力强,定位精度高(可达厘米级甚至毫米级)等特点,成为室内定位技术的研究热点。
超宽带(UWB)定位的测距方法包括:到达角方法(Angle of Arrival,AOA),接收信号强度方法(Received Signal Strength,RSS),基于飞行时间的方法(Time of Flight,TOF)等。其中,基于飞行时间的方法是最常见的定位测距方法之一。该方法主要根据信号在定位目标和基站之间的传播时间,计算定位目标和基站之间的距离。依据定位目标和多个基站之间的距离,实现定位。
但在复杂室内环境下,UWB信号在传播过程中存在遮挡、反射等情况,产生时间延时、非视距传播、多路径效应等问题,导致距离测量值不可避免地出现波动,影响定位算法性能,甚至无法完成定位。因此,研究信号干扰下的UWB精确定位成为了亟需解决的问题。
1 . 2 问题要求
本研究通过实际场景实测来解决信号干扰下的超宽带精确定位问题。在5000mm×5000mm×3000mm的测试环境中,放置锚点A0,A1,A2,A3在4个角落,向外发送信号。靶点接收到4个锚点的信号后,利用TOF定位技术,获得锚点(anchor)与靶点(tag)之间的距离,建立数学模型或者算法,使得无论测距信号是否受到干扰,都可以给出目标靶点的精确定位。问题示意图如图11。
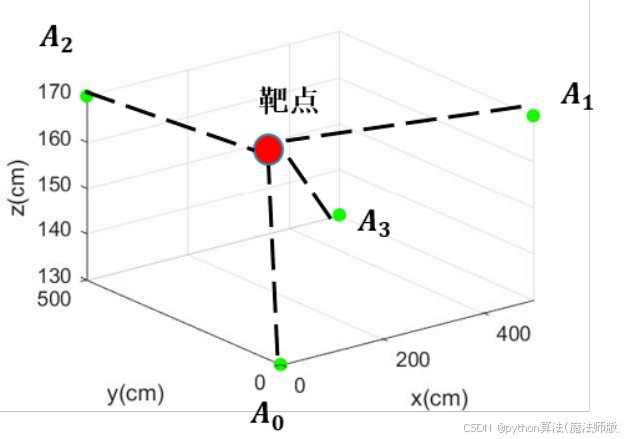
图11 问题示意图
实验采集了324个不同位置靶点的数据,每个位置个采集两次,一次在无信号干扰的情况下,一次在有信号干扰下的情况下。由于靶点在同一位置会稍作停留,而锚点与靶点之间每间隔0.20.3秒就会收发信号一次,因而在同一位置点,UWB会采集到多组数据,得到UWB数据集。现根据以上背景以及所提供数据完成以下任务:
1. 数据预处理(清洗)。针对靶点在信号正常和异常采集的数据,设计读取方式并转换成二维表(矩阵)的形式,每一行代表一组数据。对数据文件进行预
处理,删掉异常、缺失、相同或相似等“无用”数据,保留经处理后的数据,重点列出24.正常.txt,109.正常.txt,1.异常.txt,100.异常.txt四个数据文件保留下来的数据。
2. 定位模型。利用处理后的数据,分别对“正常”和“异常”数据,设计合适的数学模型,估计靶点的精确位置,所建立的定位模型定位模型必须体现实验场景信息,并说明有效性。同时利用所建立的定位模型分别对5组无信号干扰数据和5组有信号干扰数据进行精确定位,并给出定位模型的3维(x,y,z)精度、2维(x,y)精度以及1维的各自精度。
3. 在不同场景下测试所建立模型的有效性。分别用任务2中建立的“正常数据”定位模型及“异常数据”定位模型,对实验场景2下的无信号干扰数据及有干扰信号数据进行精确定位。
4. 分类模型。建立数学模型,对“正常”和“异常”数据进行区分,以判断在 UWB数据采集阶段是否受到信号干扰,并说明所建立的分类模型的有效性。
同时利用所建立的分类模型判断场景1下的10组数据是否为信号干扰数据。5. 运动轨迹定位。利用静态点的定位模型,加上靶点自身运动规律,建立运动 轨迹定位模型,对存在随机信号干扰的动态靶点的运动轨迹进行定位。对场 景1下采集的动态靶点运动轨迹进行精确定位,并画出运动轨迹图。
2. 模型假设与符号说明
3 . 2 数据预处理
3 . 2 . 1 缺失数据、相同数据处理
(1) 缺失数据判定准则:原始数据中,存在一个或多个锚点值为空的情况即判定 为缺失数据。
(2) 相同数据判定准则:原始数据中,两组数据间4个锚点值全部相同的数据即 判定为相同数据。
由于每个数据文件采集到的是同一位置下的多组冗余信息,因而对缺失数据及相同数据直接进行删除。
3 . 2 . 2 异常数据处理
由于每个数据文件为靶点在同一位置下采集到的一段连续时间内的多组数据,因而本文将每个锚点(锚点)采集到的数据看成一维时序信号,对信号进行分析。
(1) 快速傅里叶变换分析信号特征
傅里叶变换(Fourier Transform,FT)是一种线性积分变换,用于信号在时域(或空域)和频域之间的转换,是信号处理中的一种常用工具。而快速傅里叶变换(Fast Fourier Transform,FFT)是一种可在时间内完成离散傅里叶变换的高效的计算方法。
首先,本文将同一数据文件下的4个锚点数据进行可视化,得到4个一维的时序信号,如下图32所示(以142.正常.txt为例)。
可以看出信号在时域下,整体较为平稳,有轻微的波动,偶有异常值出现。接着,本文对时域下的信号进行快速傅里叶变换,分析其在频域下的特征,判断是否有周期性的噪声。对上图四个一维信号分别进行傅里叶变换得到频域下的特征,如图33所示。
可以看到信号频率集中在0,没有高频噪声,因而不需要滤波。
3 . 3 数据预处理结果
根据上述处理流程,分别对“正常数据”与“异常数据”下的324个文件进行处理,得到“正常数据”和“异常数据”文件夹下每个数据文件最后保留下来的样品组数。“正常数据”与“异常数据”文件夹下每个数据文件的数据组数如表3、表4所示,详细结果见附件。
| 表3 | “正常数据”文件夹下每个数据文件的数据组数 |
| 文件编号 数据组数 |
| ||||||||||||||||||||||||||||||
| 文件编号 数据组数 |
| ||||||||||||||||||||||||||||||
| 文件编号 数据组数 |
| ||||||||||||||||||||||||||||||
| 文件编号 |
|
| 表4 | “异常数据”文件夹下每个数据文件的数据组数 |
| 文件编号 数据组数 |
| ||||||||||||||||||||||||||||||
| 文件编号 数据组数 |
| ||||||||||||||||||||||||||||||
| 文件编号 数据组数 |
| ||||||||||||||||||||||||||||||
| 文件编号 |
|
其中,“24.正常.txt”文件经处理后保留的数据为:
![]()
其余“109.正常.txt”文件、“1.异常.txt”文件、“100.异常.txt”文件经处理后保留的数据详见附录A。
4. 任务二的分析与求解
4 . 1 任务二分析
在本题中,需要利用任务1处理后的数据,分别对“正常数据”和“异常数据”,设计合适的数学模型(或算法),预测出靶点的精确位置。模型要求能够体现实验场景的信息,并对其有效性进行评估。对于正常数据而言,任务本质为通过四个锚点到靶点之间的带噪声的观测距离,预测靶点在锚点坐标系中所处的三维空间坐标,为经典的超定方程组优化问题(通过四个方程组解三个未知量)。针对这类问题,最小二乘法及相关特定方法Chan为经典解决方案,但这类解决方案通常优化难度较大,且当噪声为非高斯分布时,预测误差较大。本文提出了一种基于多层感知机的定位模型,将该最小二乘拟合问题建模为一个优化问题,并巧妙地用神经网络进行解决。模型与传统方法相比,具有较好的抗噪能力。并通过后接聚类算法,对预测结果进行进一步的聚类,选择较好的一类作为最终结果,因而模型具有较高的精度。
针对异常数据,建立了基站异常的联合定位模型。首先,对观测数据进行可视化,并根据题中陈述,合理进行假设——任一时刻最多只有一个基站的信号受到干扰。基于本假设,对观测到的异常数据进行采样,得到五个数据集合。用采样后的得到的五个数据集合,分别输入上述正常数据下的定位模型,得到五个相应的靶点预测集合。进而建立置信度评估模型,对预测结果进行置信度评估。最后,设计基于置信度的结果聚类算法,对预测结果进行聚类,选择较好的一类作为最终的结果。
为了验证方法的有效性,使用RMSE、相对误差、绝对误差等多种精度指标,分别在三维空间、XY平面和3个坐标轴方向衡量了模型的定位精度,证明了所提方法在信号传输有干扰的情况下,仍能保持一定的定位精度。任务二的解决流程如图41所示。
代码
| # 任务1 mask_temp = distance < (mean_d mask_temp = mask_temp & (dista std_distance)) return distance[mask,:] def duplicate_samples_remove(distance): unique,ori_index = sort_index = np.argsort(ori_index) unique = unique[sort_index,:] def similar_samples_remove(distan # 计算均值,按照距离均值的距离计算可信度mu = np.mean(distance, axis=0) index = np.argsort(ddistance) reverse_index = np.arange(0,le # 按照可信度将样本进行排序,距离小的 sort_index = reverse_index[ind # 遍历搜索,优先添加可信度高的样本。 selected_distance = [] append_flag = True append_flag = False break | ce, axis=0) istance + 3 * std_distance) nce > (mean_distance 3 * temp[:, 1] & mask_temp[:, 2] & eturn_index=True) ce,margin = 20): tance mu, 2, axis=1) n(distance)) 样本可信度高 ex] # 用于恢复正常顺序 ort_index): |
if append_flag:
![]()
![]()
![]()
selected_distance.append(d)
time_index.append(i)
index = np.argsort(time_index)
return np.array(selected_distance)[index,:]
# 任务2
import numpy as np
from tqdm import tqdm
import os
from sklearn.metrics import mean_squared_error
from torch import optim
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
def read_data(file_path:str):
data = pd.read_csv(file_path,index_col=0)
return data
def preprocess_data(csv_data):
distance = csv_data[['d1', 'd2', 'd3', 'd4']].values
is_normal = csv_data['is_normal'].values[0]
tag_location = csv_data[['x','y','z']].values
tag_location = np.array(tag_location)
return distance,tag_location,is_normal
###SGNN for Maximum Independent Set###
class SimpleGCN(nn.Module):
'''
The GCN layer refers to the paper (Graph Clustering with
Graph Neural Networks)
'''
def __init__(self, in_features, out_features, bias=True): super(SimpleGCN, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.FloatTensor(in_features,
out_features))
if bias:
self.bias = Parameter(torch.FloatTensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
### Random ###
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(stdv, stdv)


















 9792
9792

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











