






 文章介绍了内存交织技术如何通过在不同层级的内存结构中交错访问提高性能,以及解决DDR中的turnaround时间问题。特别关注了内存插法对内存访问性能的影响,给出了内存容量和rank数量一致的优化建议。
文章介绍了内存交织技术如何通过在不同层级的内存结构中交错访问提高性能,以及解决DDR中的turnaround时间问题。特别关注了内存插法对内存访问性能的影响,给出了内存容量和rank数量一致的优化建议。
“
Memory Interleaving可以翻译为内存交织,即通过在不同内存上的交错访问来提高内存访问性能的技术。
”
由于DDR的turnaround时间的存在,DRAM介质在操作的前后都有一段时间是无法进行读写操作的。
通过Memory Interleaving 和预取技术,可以在两个方面降低相关的影响,提高内存访问的性能。
内存交织的原因
在开篇引用的文章中介绍了turnaround时间的问题。为解决这个问题,很自然地想到了统筹规划和流水线作业,如下图。
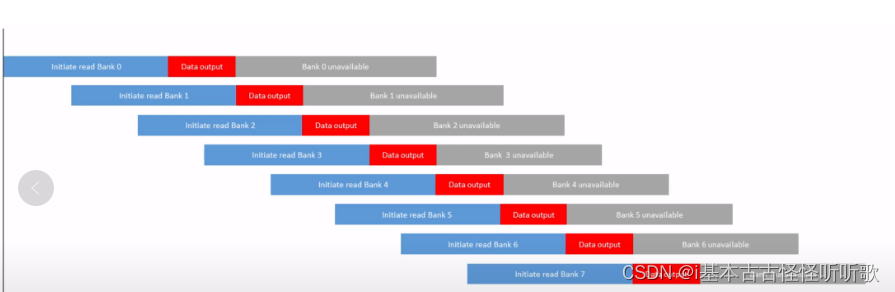
可以看到上图中,红色的区块表示数据输出,在时间这个维度上看就是连续的,不会被介质读写本身的turnaround时间所限制。
在上面的文章中,我们把Bank比作一个excel表格的tab,每次数据读写,都会将对应的一行数据,读取到sense amplifier当中。为了避免数据不可用时间,在bank级别的interleaving如下面的动图所示。

那么,是不是只在bank级别去做interleave形成这种流水线就可以了?
答案是否定的,像我们之前文章中提到的那样,turnaround时间不仅仅发生在底层的bank级别,也会发生在更高的层级,例如rank之间。
而在更高的层级上,interleaving可以允许多个DIMM的并发访问,多个独立的通道(channel)提高了数据传输速率。在多通道模式下运行时,延迟也会降低。
内存控制器以交替模式在DIMM之间分配数据,允许内存控制器访问每个DIMM来获取较小的数据位,而不是访问单个DIMM来获取整个数据块,这为内存控制器提供了更多带宽用于跨通道访问相同数量的数据,而不是遍历单个通道将所有数据存储到单个DIMM中。
因此内存访问需要分布在多个内存控制器上,多个channel上,多个rank上,多个bank上,这样交织的访问,就是memory interleaving的两个主要原因和方式。
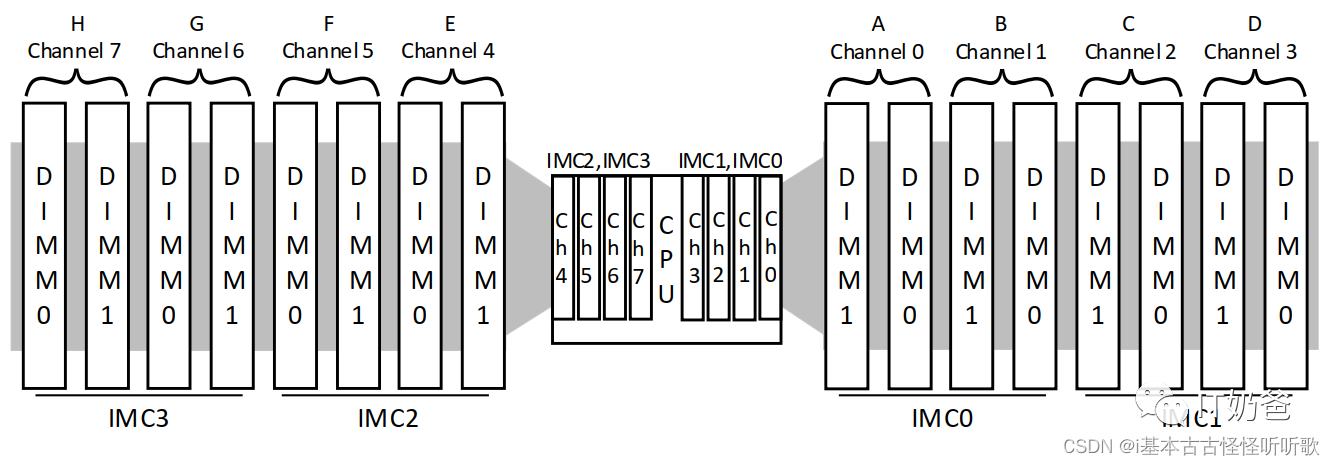
下图是Intel Sapphire Rapid这一代的CPU,每个CPU有四个内存控制器,每个内存控制器有两个channel,每个channel有2根DIMM。通过interleaving我们可以享受到四个内存控制器,两个channel的并行数据,因此单个内存访问的最大带宽理论值即为:
4800(MT/s)*64(bit)/8(bit/Byte)= 307,200 MBps
内存插法的影响
由于memory interleaving在多个DIMM的并发访问,多个独立的内存通道提高了数据传输速率。
如上所述,Intel Sapphire Rapid平台,一个socket有四个内存控制器,每个内存控制器有两个channel,每个channel可以插两个内存条。
考虑到memory interleaving,内存条的插法有什么讲究么?
在内存通道的interleaving中会有interleave group的形成,而在一个interleave group中会首先检查同样容量,同样rank数目的最大内存通道数,这个最大通道数的区域会组成一个interleave group。
而不平衡的内存插法会在第一次的遍历之后剩下一部分DIMM或者内存容量。剩下的内存容量,会按照同样的方法重复进行interleave的分组。
以此类推可能会得到不同interleave group,而每个group内部的通道数,capacity都可能存在的差异,因此内存访问的性能就会出现不同的结果。
所以出于性能考虑,有以下建议:
-
所有的内存通道建议有同样的内存容量和同样的rank数量。
-
在一个处理器上的所有内存通道建议有同样的内存配置。
结语,Interleaving在细节方面还有很多的算法可以考虑,这篇文章中介绍了引入interleave 机制的两个主要原因,并且介绍了不同的插法带来的interleave group的变化,进一步得出内存插法的建议,以避免非平衡插法对性能带来的影响

















 1534
1534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









