






它是Stable Diffusion的客户端 GitHub - comfyanonymous/ComfyUI: The most powerful and modular diffusion model GUI, api and backend with a graph/nodes interface. 手册:https://comfyuidoc.com/zh/
Stable Diffusion(稳定扩散模型)
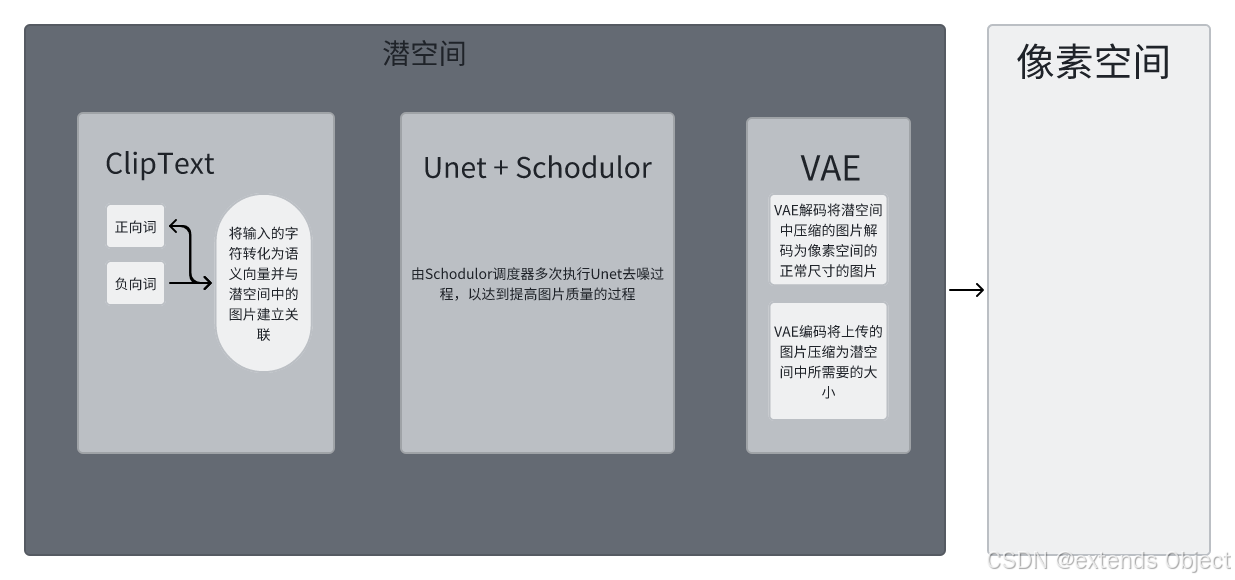
Clip,UNet,Vae
CLIP(Contrastive Language–Image Pre-training)对比语言预训练模型,由 OpenAI在2021年 提出,它能够理解并处理图像和文本,通过对它们进行对比学习(contrastive learning)来建立图像和文本之间的关联。简单来说Clip模型能把用户输入的文字需求,正确的理解成生成图片的需求
UNet是一种用于图像分割的卷积神经网络架构。可以把输入的图片分割成具有一定语义含义的区域块,识别出每个区域块语义类别,最终得到与原图像等大小具有逐像素语义标注的分割图像。还能用于提升图片的细节和质量。
VAE(Variational AutoEncoder 变分自编码器)在Stable Diffusion中对于输入的图片,会先用VAE编码器(VAE Encoder)把像素空间中的图片,压缩为潜空间数据,通过VAE编码器把512x512的图片压缩后变成了64x64的大小,最后再通过VAE解码器(VAE Decoder)把潜空间中的图片返回成像素空间的大小。


















 201
201

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









