






阅读文献:
(1)A Precision-Scalable Deep Neural Network Accelerator With Activation Sparsity Exploitation
这篇文章是在Bit Fusion结构的基础上进行改进的,设计出MFU加速器结构。(1)首先修改了传统融合单元(FU)的架构,使其适用于零跳方案;(2)设计了一种分割方法来解决内存访问冲突;(3)提出了一种稀疏性感知映射方法来平衡处理单元的工作负载;(4)还提出了一种比特分割策略,该策略可以利用比特级的稀疏性。这部分原文如下图所示:

1、混合精度DNN加速器种类
大多数可精确扩展的DNN加速器可以分为两类。第一个是位串行加速器,它串行处理激活和/或权重的位。对于这样的加速器,通过调整处理周期可以容易地获得精度可扩展性;第二类加速器基于乘法分解。它们的基本单元称为融合单元(FU),是可分解的乘法器。位串行加速器以额外的周期为代价获得精度可扩展性,而基于FU的加速器则以额外的硬件开销为代价。
本文和之前阅读的那篇Bit Fusion文章都是属于第二类加速器的,等下次抽空再了解一下第一类加速器。
接下来就有关这篇文章改进部分进行详细讲述。
2、基于参数稀疏性改进
由于ReLU被广泛用作现代DNN的激活函数,因此给激活带来了相当大的稀疏性。除了激活,权重也是稀疏的。据报道,DNN的稀疏性在大多数情况下很容易超过50%。利用稀疏性最直接的方法是跳过零操作数,这样可以消除无效的计算。
位串行DNN加速器天生就适合稀疏性。相反,很难直接利用基于FU的DNN加速器的稀疏性。FU被设计用于计算低精度模式下的内积。即使大多数输入操作数为零,它仍然需要为非零操作数工作。这一特性阻碍了现有的基于FU的DNN加速器利用稀疏性,从而限制了它们的计算效率。由于基于FU的DNN加速器已经提供了与位串行加速器相当的性能,因此有希望通过稀疏性利用使其更具竞争力。
本文使用的方法是:复用激活,并且MFU被设计为在一个循环中只处理一个激活,不进行卷积相加。
在8b×8b模式下,其工作方式与传统FU相同。在低精度模式下,MFU不再计算内积。相反,它计算几个独立的乘积。具体地,一个激活将与属于卷积层中的不同滤波器或FC层中的权重矩阵的不同列的不同权重相乘。下图1是传统FU的结构,图2是MFU的结构,图3是MFU的数据流结构。图2中上下的S&A是结构不同的,那是因为上方的S&A在进行8bit的运算时候要计算高位,而下方不需要这么多的移位。
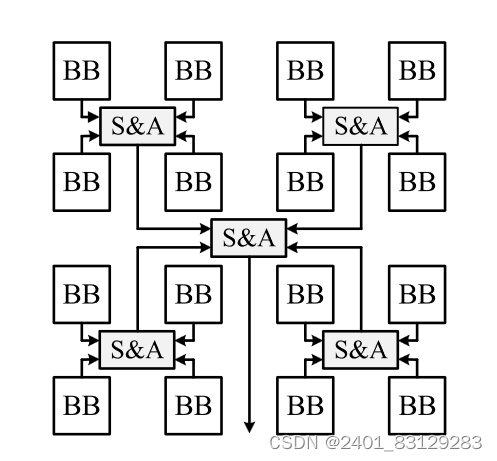

可以看到,A表示激活(输入数据),Wi表示滤波器i的权重。两个连续激活比特由一行BB共享,而两个连续权重比特由封装在每个红色虚线框中的BB共享。生成的中间结果数量等于传统FU在所有模式下生成的中间结果数量。一个明显的区别是,这些中间结果属于不同的输出激活,不会加在一起。与传统FU类似,MFU也包含16个BB,并且需要一些S&A逻辑。然而,MFU的并购逻辑比传统的并购逻辑更为复杂。每个配置模式分别对应于一个计算体系结构。MFU是一种可重新配置的硬件架构,可以配置到所有模式的计算架构中。观察所有的计算架构,可以发现为MFU设计高效的S&A逻辑并不简单,因为某些模式的计算架构并不直接兼容。可以引入多个MUX以在所有模式中正确地多路复用信号。然而,所产生的硬件开销将是复杂的。
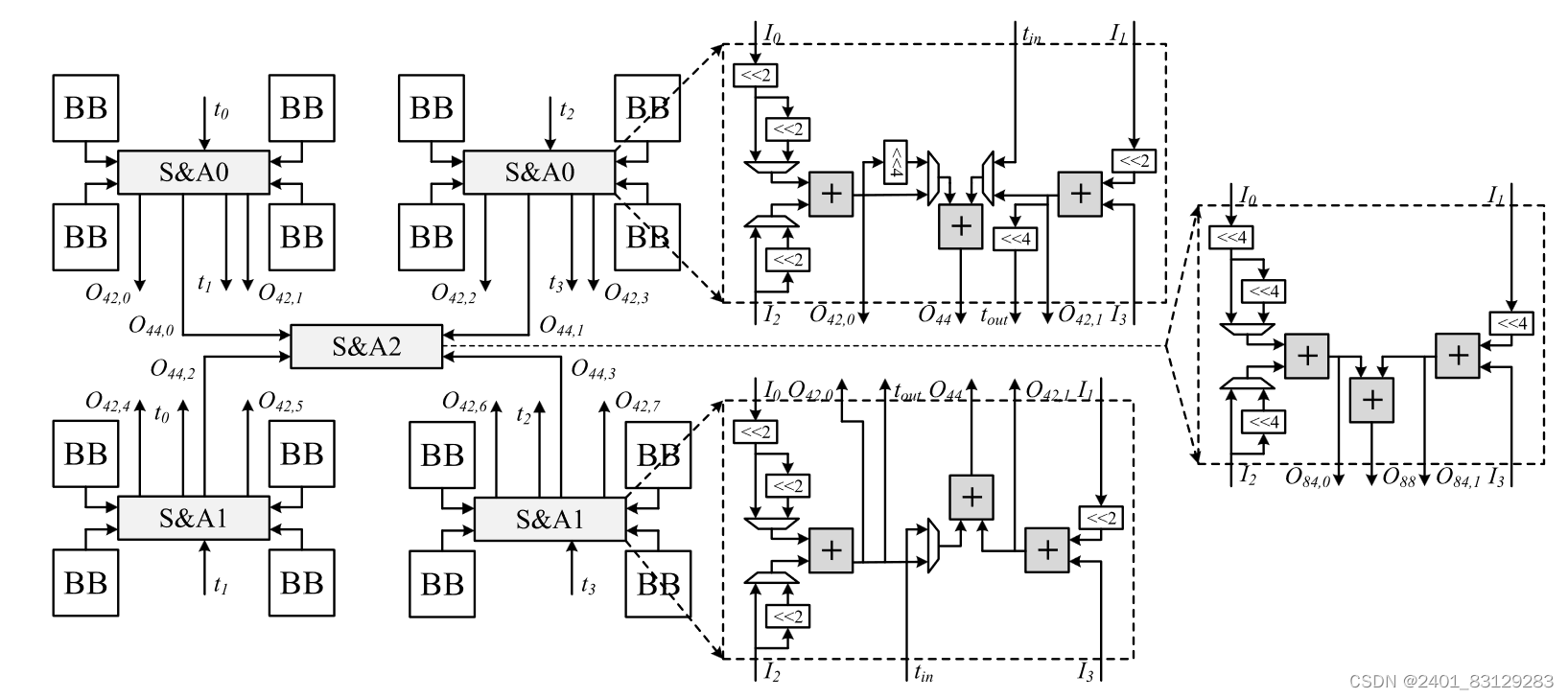
3、加速器硬件结构和优化计算方式
下图是本文所提出的基于MFU结构的DNN加速器顶层结构。乘法运算由PE阵列执行。它由n个PE组成。在一个周期中,每个PE都被分配了一个单独的激活,该激活由其所有m个MFU共享。值得注意的是,MFU结构并不进行累加计算,而是将乘法运算后的结果发送给加法树来完成累加。

为了充分利用稀疏性,MFU以完全串行的方式处理激活,并且使用简单的编码格式。对于非零输入,会直接使用其值并记录它与下一个非零输入之间的距离。
以n=4为例,读取输入数据的方式是按照输入通道从左上往右下,在第一个循环中,一个滑动窗口的前四个非零输入被发送到四个PE,而滤波器相同位置的权重也将被发送到它们。在下一个周期中,它继续读取四个非零输入及其相应的权重。

而内存访问冲突是由于非零值在特征图中位置不可预测这一点导致的。如果直接按照通道来将输入进行分块,分发给不同的PE进行计算,可能会导致两个通道由于PE处理的非零激活的数量可能不同,因此出现了同步问题,有的PE需要等待所有PE都计算完成之后才能继续下一次工作。
为了使PE的工作负载尽可能平衡,将映射粒度更改为激活级别,而不是分段级别。所提出的方法是基于不同通道中激活的平均稀疏性。具有较低平均稀疏性的通道中的激活更有可能是非零的,因此首先进行处理。对于一个通道,它在当前滑动窗口中涉及的激活将依次分配给所有PE,以平衡工作负载。具体算法实现如下图。其中,Nker卷积核大小,Nfm表示用于评估平均稀疏性的特征图的数量,n表示PE个数,nic表示输入通道数量,A表示当前滑动窗口内的激活阵列,S表示稀疏性值的序列。

以下图为例,在四个输入通道中,稀疏性1<3<2<0,因此在分配给PE的时候,通道1率先分配,然后依次为3、2、0,这样使得每个PE得到的非零运算个数基本一致。

为了进一步利用比特稀疏性,本文另外提出了一种称为比特分割策略的方法,用低bit乘法代替高bit乘法。例如,执行2b×8b乘法四次,而不是在一个循环中执行8b×8b相乘。这是由于高bit的数据由于只有一小部分有较大的数值,因此更容易出现某些位为0的数据。
下图显示了在稀疏性感知映射方法之后再使用比特分割,将4bx4b降为2bx4b,原本需要八次循环才能完成的一次卷积运算降低到5/2次。这样的分割方法需要引入另外的移位寄存器,但是在稀疏性较小的时候可以提升较多计算速度。

4、总结
这篇文章的优化还挺多的,我看完之后除了对内存访问冲突这方面没有很理解,其他几部分都大致有所了解了,尤其是关于稀疏性提出的不按照通道进行分块,还挺有代表性的。
不过感觉按本文的方法来说,对于储存空间的需求、储存非0激活值的编码、数据重排这些方面都要消耗大量的时间和空间,文章是表示和计算性能所带来的提升相比,这些可以忽略不计。但是我个人感觉,还影响蛮大的?















 1766
1766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









